Device Passport: Enabling Spatio-Temporal Pretrained Models to Generalize Across Input Layouts
Pith reviewed 2026-07-02 19:30 UTC · model grok-4.3
The pith
Device Passport embeds each channel with both its activity and metadata so pretrained biosignal models can transfer across differing sensor layouts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
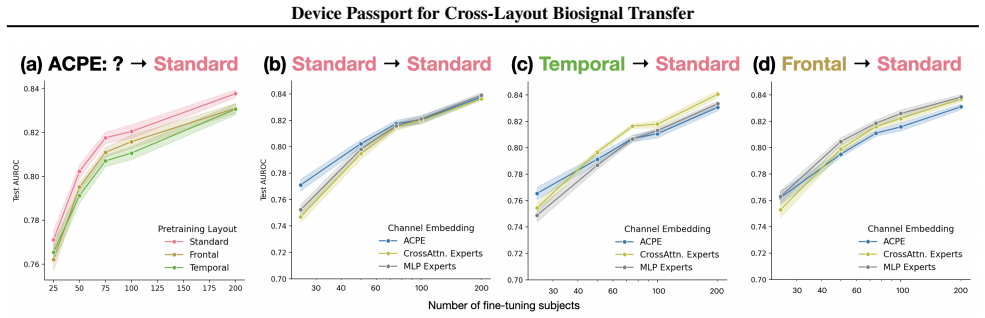
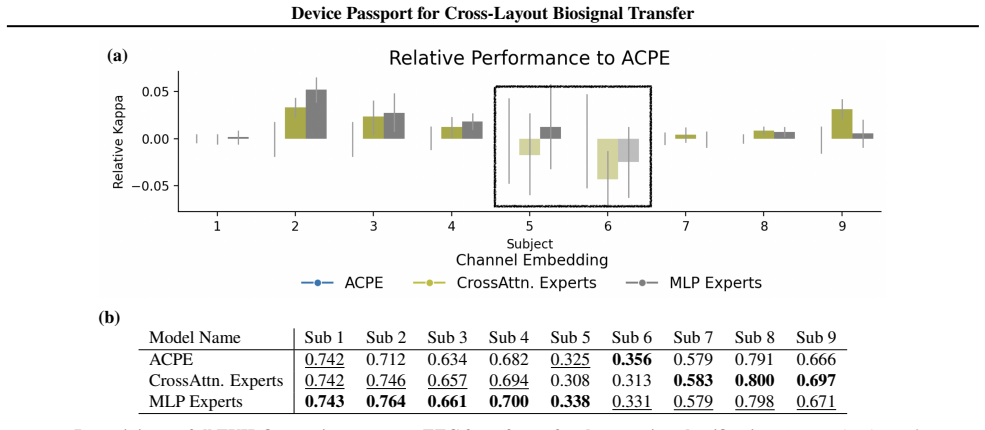
Device Passport learns experts and mixture models that take each channel's functional activity and metadata as input; when pretraining layouts differ substantially from the downstream layout, this embedding produces competitive overall performance and improves over the strongest learned baseline in the motivating transfer regimes.
What carries the argument
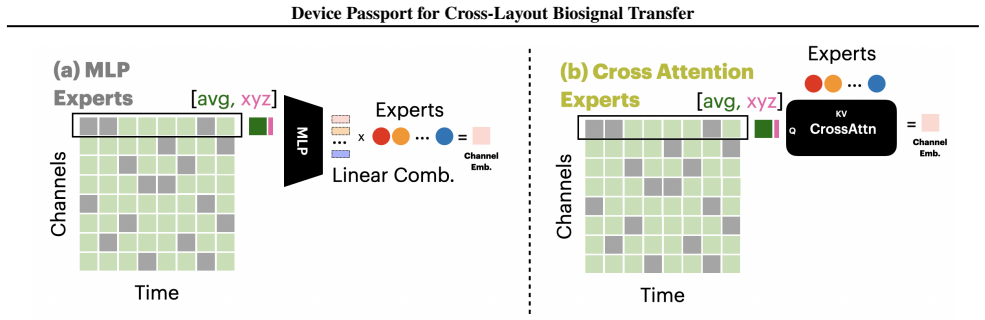
Device Passport: a channel embedding that routes each sensor through expert mixture models conditioned on both functional activity and metadata.
If this is right
- Pretrained models can be reused on new devices without collecting large matched datasets for every layout.
- Mixture models that condition on both activity and metadata outperform embeddings that use only one of those signals in layout-transfer settings.
- Performance gains appear in both synthetic subset-transfer tests and real ear-EEG recordings.
- Channel embedding choice becomes a first-order design decision for any spatio-temporal biosignal foundation model.
Where Pith is reading between the lines
- The same metadata-plus-activity conditioning could be tested on non-EEG biosignals such as ECG or EMG arrays whose sensor counts vary across products.
- If metadata includes physical coordinates, the method might also reduce the need for explicit spatial alignment steps before decoding.
- A natural next measurement is whether the expert mixture weights themselves become interpretable as soft assignments of channels to functional roles across devices.
Load-bearing premise
Incorporating each channel's functional activity and metadata into expert mixture models will enable effective generalization when pretraining layouts differ substantially from the downstream decoding layout.
What would settle it
A controlled transfer experiment in which Device Passport shows no improvement or clear degradation relative to the strongest learned baseline on a new layout whose sensors differ substantially in number and placement from the pretraining set.
Figures


read the original abstract
New device layouts pose a challenging modeling problem due to the lack of large datasets for each specific layout. Biosignal foundation models offer a plausible solution if they are able to generalize to new layouts effectively. To improve cross-layout transfer, we study how different channel embedding techniques behave when pretraining layouts differ substantially from the downstream decoding layout. We propose Device Passport, a new channel embedding technique that learns experts and mixture models that take each channel's functional activity and metadata as input. This contrasts with prior embedding methods, which typically use only functional information or only metadata to look up learned or fixed positional embeddings. Across controlled subset-transfer experiments and realistic transfer to ear-EEG, Device Passport is competitive overall and improves over the strongest learned baseline in the layout-transfer regimes that motivate this work. These results suggest that channel embedding design is a key consideration when reusing large-scale pretrained biosignal models on new devices.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Device Passport, a channel embedding technique for biosignal foundation models that uses expert mixture models taking each channel's functional activity and metadata as input. This is proposed to improve generalization when pretraining layouts differ from downstream decoding layouts. The method is evaluated on controlled subset-transfer experiments and realistic transfer to ear-EEG, where it is reported to be competitive overall and to improve over the strongest learned baseline in layout-transfer regimes.
Significance. If the results hold, this work could have significant impact by enabling the reuse of large-scale pretrained biosignal models across different device layouts, which is a practical challenge in the field. The approach of conditioning expert mixtures on both activity statistics and metadata offers a novel way to handle layout variability compared to prior methods that use only functional information or only metadata.
major comments (2)
- [Abstract] The abstract asserts competitive performance and specific improvements but supplies no quantitative results, error bars, dataset sizes, or experimental details, making it challenging to evaluate the claims without referring to the full experimental sections.
- [Experiments] The manuscript does not appear to include a section that isolates the routing behavior of the expert mixture models on a deliberately out-of-distribution layout pair while holding other factors fixed. This leaves the central claim that the routing produces layout-robust channel embeddings vulnerable to alternative explanations based on dataset idiosyncrasies.
minor comments (1)
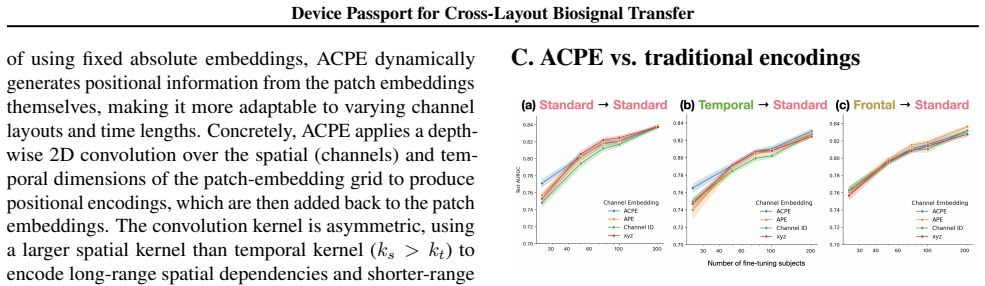
- [Methods] Clarify the exact architecture of the expert mixture models and how metadata is encoded, as this is central to reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the potential impact of Device Passport. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] The abstract asserts competitive performance and specific improvements but supplies no quantitative results, error bars, dataset sizes, or experimental details, making it challenging to evaluate the claims without referring to the full experimental sections.
Authors: We agree that including a small number of quantitative highlights in the abstract would help readers assess the claims more readily. We will revise the abstract to incorporate key metrics (e.g., relative improvement over the strongest baseline in layout-transfer settings) while remaining within typical length limits. revision: yes
-
Referee: [Experiments] The manuscript does not appear to include a section that isolates the routing behavior of the expert mixture models on a deliberately out-of-distribution layout pair while holding other factors fixed. This leaves the central claim that the routing produces layout-robust channel embeddings vulnerable to alternative explanations based on dataset idiosyncrasies.
Authors: The controlled subset-transfer experiments (Section 4.2) deliberately vary only the channel layout while drawing pretraining and downstream data from the same underlying dataset distribution, thereby holding dataset-specific factors fixed. These experiments therefore isolate the contribution of the routing mechanism to layout robustness. We will add an explicit paragraph in the experimental section clarifying this design choice and its relation to the routing behavior. revision: partial
Circularity Check
No circularity; empirical claims rest on experimental comparisons.
full rationale
The manuscript proposes Device Passport as a channel embedding method using expert mixture models conditioned on per-channel functional activity and metadata. Its headline results (competitive performance and gains over baselines in layout-transfer regimes) are presented as outcomes of controlled subset-transfer experiments and ear-EEG transfer evaluations. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the text. The argument chain is therefore self-contained against external benchmarks and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year =
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers , author =. International Conference on Learning Representations , year =
-
[2]
International Conference on Learning Representations (2025)
Cbramod: A criss-cross brain foundation model for eeg decoding , author=. arXiv preprint arXiv:2412.07236 , year=
-
[3]
Journal of neural engineering , volume=
EEGNet: a compact convolutional neural network for EEG-based brain--computer interfaces , author=. Journal of neural engineering , volume=. 2018 , publisher=
2018
-
[4]
Conditional positional encodings for vision transformers
Conditional positional encodings for vision transformers , author=. arXiv preprint arXiv:2102.10882 , year=
-
[5]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[6]
Advances in Neural Information Processing Systems , volume=
A unified, scalable framework for neural population decoding , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
Large brain model for learning generic representations with tremendous EEG data in BCI , author=. arXiv preprint arXiv:2405.18765 , year=
-
[8]
ArXiv , pages=
Population transformer: Learning population-level representations of neural activity , author=. ArXiv , pages=
-
[9]
Frontiers in Neuroinformatics , volume=
MEG and EEG data analysis with MNE-Python , author=. Frontiers in Neuroinformatics , volume=. 2013 , publisher=
2013
-
[10]
Frontiers in neuroscience , volume=
The temple university hospital EEG data corpus , author=. Frontiers in neuroscience , volume=. 2016 , publisher=
2016
-
[11]
Biomedical engineering online , volume=
Automatic sleep staging using ear-EEG , author=. Biomedical engineering online , volume=. 2017 , publisher=
2017
-
[12]
2018 Computing in Cardiology Conference (CinC) , volume=
You snooze, you win: the physionet/computing in cardiology challenge 2018 , author=. 2018 Computing in Cardiology Conference (CinC) , volume=. 2018 , organization=
2018
-
[13]
circulation , volume=
PhysioBank, PhysioToolkit, and PhysioNet: components of a new research resource for complex physiologic signals , author=. circulation , volume=. 2000 , publisher=
2000
-
[14]
IEEE Transactions on biomedical engineering , volume=
BCI2000: a general-purpose brain-computer interface (BCI) system , author=. IEEE Transactions on biomedical engineering , volume=. 2004 , publisher=
2004
-
[15]
Nature , volume=
A generic non-invasive neuromotor interface for human-computer interaction , author=. Nature , volume=. 2025 , publisher=
2025
-
[16]
Large-scale training of foundation models for wearable biosignals
Large-scale training of foundation models for wearable biosignals , author=. arXiv preprint arXiv:2312.05409 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.