A Hardware-Efficient ADMM-Based SVM Training Algorithm for Edge Computing
Pith reviewed 2026-05-24 16:58 UTC · model grok-4.3
The pith
ADMM optimizer with Nyström approximation reduces SVM training matrix dimension 32 times while enabling 153310 times higher energy efficiency on edge hardware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
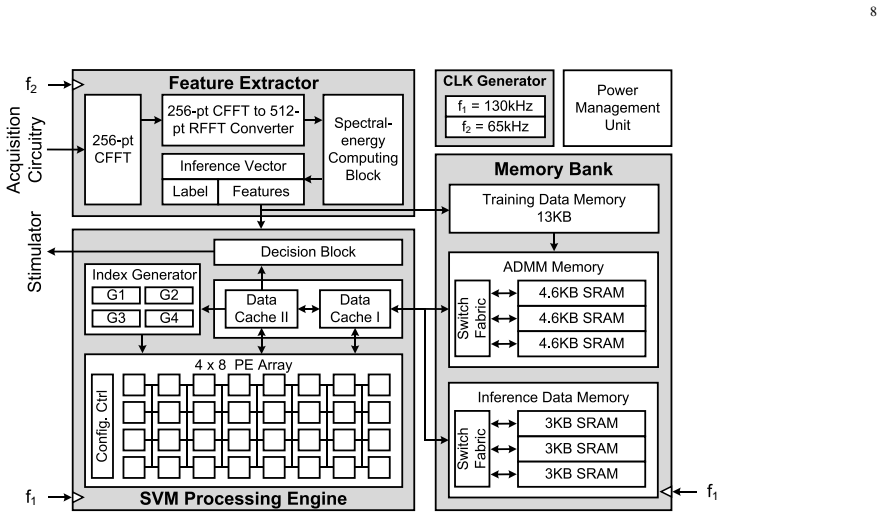
An ADMM-based formulation of the SVM dual problem, paired with Nyström low-rank kernel approximation and hardware optimizations of pre-computation plus memory sharing, produces a training procedure whose latency, energy, and area scale to the constraints of edge silicon; the resulting epileptic-seizure detector ASIC achieves a 153310 times energy-efficiency improvement and a 364 times throughput-to-area improvement over a high-end CPU while keeping inference accuracy within 2 percent of the full-rank baseline.
What carries the argument
ADMM iteration applied to the SVM dual, with Nyström low-rank kernel matrix approximation that reduces dimension by 32 times, plus pre-computation and memory-sharing hardware blocks.
If this is right
- SVM training latency for 2048 samples drops by 9.8 times 10 to the 7 relative to SMO.
- On-chip, real-time SVM retraining becomes feasible for power-constrained edge devices.
- Computational complexity falls 62 percent and memory usage falls 60 percent through the listed hardware techniques.
- Energy efficiency for SVM training reaches 153310 times that of a high-end CPU.
- Throughput-to-area ratio reaches 364 times that of a high-end CPU.
Where Pith is reading between the lines
- The same ADMM-plus-Nyström pattern could be applied to other kernel-based methods such as Gaussian processes on embedded hardware.
- Periodic on-device retraining without cloud round-trips becomes practical for privacy-sensitive or latency-critical signals.
- The memory-sharing technique may generalize to other iterative solvers that repeatedly access large symmetric matrices.
- Scaling the approach to datasets larger than a few thousand samples would require additional rank-reduction or distributed hardware steps not explored here.
Load-bearing premise
The Nyström approximation that reduces matrix dimension by 32 times preserves enough accuracy for the intended applications, as shown by only a 2 percent drop on the four tested datasets.
What would settle it
Measurement of training accuracy on a fifth, previously unseen dataset or application where the drop exceeds the 2 percent threshold or where the fabricated chip fails to reach the reported energy or throughput gains once all control overhead is included.
Figures







read the original abstract
This work demonstrates a hardware-efficient support vector machine (SVM) training algorithm via the alternative direction method of multipliers (ADMM) optimizer. Low-rank approximation is exploited to reduce the dimension of the kernel matrix by employing the Nystr\"{o}m method. Verified in four datasets, the proposed ADMM-based training algorithm with rank approximation reduces 32$\times$ of matrix dimension with only 2% drop in inference accuracy. Compared to the conventional sequential minimal optimization (SMO) algorithm, the ADMM-based training algorithm is able to achieve a 9.8$\times$10$^7$ shorter latency for training 2048 samples. Hardware design techniques, including pre-computation and memory sharing, are proposed to reduce the computational complexity by 62% and the memory usage by 60%. As a proof of concept, an epileptic seizure detector chip is designed to demonstrate the effectiveness of the proposed hardware-efficient training algorithm. The chip achieves a 153,310$\times$ higher energy efficiency and a 364$\times$ higher throughput-to-area ratio for SVM training than a high-end CPU. This work provides a promising solution for edge devices which require low-power and real-time training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an ADMM-based SVM training algorithm that incorporates the Nyström method for low-rank kernel matrix approximation, reducing matrix dimension by 32× with a claimed 2% inference accuracy drop verified on four datasets. Hardware optimizations including pre-computation and memory sharing are introduced to cut complexity and memory usage. As a proof-of-concept, the approach is implemented in a fabricated epileptic seizure detector chip that reports 153,310× higher energy efficiency and 364× higher throughput-to-area ratio for training versus a high-end CPU, along with a 9.8×10^7 latency reduction versus SMO for 2048 samples.
Significance. If the empirical claims hold under more detailed validation, the work would offer a concrete path toward on-device SVM training for latency- and power-constrained edge applications such as real-time biomedical monitoring. The combination of algorithmic approximation, hardware co-design, and a fabricated chip demonstration provides a rare end-to-end evaluation that could influence future low-power ML accelerators.
major comments (3)
- [Abstract] Abstract: the 2% accuracy drop after 32× Nyström reduction is stated to have been verified on four datasets, yet the manuscript does not identify those datasets or report the accuracy delta specifically on the epileptic seizure data used for the chip. Because the headline efficiency numbers rest on the chip whose training pipeline includes this approximation, the transferability of the accuracy claim is load-bearing and must be shown explicitly.
- [Abstract] Abstract: the reported gains (153,310× energy efficiency, 364× throughput-to-area ratio, 9.8×10^7 latency reduction) are presented without error bars, multiple-run statistics, or a full description of the CPU baseline configuration and SMO implementation. These omissions prevent assessment of whether the observed differences are robust or sensitive to implementation details.
- [Abstract] Abstract: the hardware pre-computation and memory-sharing steps are claimed to reduce complexity by 62% and memory by 60%, but no breakdown is given showing how these savings interact with the Nyström approximation error or whether the reduced-rank kernel still satisfies the convergence assumptions of the ADMM solver.
minor comments (1)
- [Abstract] Abstract: 'alternative direction method of multipliers' is a typographical error and should read 'alternating direction method of multipliers'.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the 2% accuracy drop after 32× Nyström reduction is stated to have been verified on four datasets, yet the manuscript does not identify those datasets or report the accuracy delta specifically on the epileptic seizure data used for the chip. Because the headline efficiency numbers rest on the chip whose training pipeline includes this approximation, the transferability of the accuracy claim is load-bearing and must be shown explicitly.
Authors: We agree that explicit identification of the datasets and the accuracy delta on the epileptic seizure data is necessary to support the chip results. In the revised manuscript we will name the four datasets and add a table reporting inference accuracy before and after the 32× reduction for each, including the seizure-detection dataset used in the fabricated chip. revision: yes
-
Referee: [Abstract] Abstract: the reported gains (153,310× energy efficiency, 364× throughput-to-area ratio, 9.8×10^7 latency reduction) are presented without error bars, multiple-run statistics, or a full description of the CPU baseline configuration and SMO implementation. These omissions prevent assessment of whether the observed differences are robust or sensitive to implementation details.
Authors: We acknowledge the value of statistical detail and baseline transparency. The revised version will include error bars from repeated measurements where feasible, together with a complete specification of the CPU platform, compiler settings, and the exact SMO implementation used for the latency comparison. revision: yes
-
Referee: [Abstract] Abstract: the hardware pre-computation and memory-sharing steps are claimed to reduce complexity by 62% and memory by 60%, but no breakdown is given showing how these savings interact with the Nyström approximation error or whether the reduced-rank kernel still satisfies the convergence assumptions of the ADMM solver.
Authors: The pre-computation and memory-sharing optimizations are hardware realizations of the identical arithmetic operations performed on the already-reduced-rank kernel; they introduce no additional numerical error and leave the mathematical convergence conditions of ADMM unchanged. We will insert a short explanatory paragraph and a resource-breakdown table in the hardware section to make this separation explicit. revision: yes
Circularity Check
No circularity; empirical claims rest on direct measurements and standard algorithms
full rationale
The paper's core contributions—an ADMM optimizer for SVM, Nyström low-rank kernel approximation, hardware optimizations, and chip implementation—are presented through algorithmic descriptions and empirical benchmarks against SMO and CPU baselines. Latency, accuracy, energy, and area metrics are reported as measured outcomes on specific datasets and fabricated hardware, without any derivation step that reduces by construction to a fitted parameter, self-defined quantity, or self-citation chain. The 2% accuracy claim is an explicit verification result rather than a prediction derived from the approximation itself.
Axiom & Free-Parameter Ledger
free parameters (1)
- Nystrom approximation rank
axioms (2)
- domain assumption ADMM converges reliably for the SVM dual optimization problem under the chosen penalty parameters
- domain assumption Nystrom low-rank approximation preserves sufficient kernel structure for downstream SVM accuracy
Reference graph
Works this paper leans on
-
[1]
On a class of pattern- recognition learning algorithms,
V . N. Vapnik and A. Ya. Chervonenkis, “On a class of pattern- recognition learning algorithms,” Automation and Remote Control, vol. 25, no. 6, pp. 838-845, 1964
work page 1964
-
[2]
A training algorithm for optimal margin classifiers,
B. E. Boser, I. M. Guyon, and V . N. Vapnik, “A training algorithm for optimal margin classifiers,” Proceedings of the fifth annual workshop on Computational Learning Theory, ACM, pp. 144-152, July. 1992
work page 1992
-
[3]
A comparison of methods for multiclass support vector machines,
C.-W. Hsu and C.-J. Lin, “A comparison of methods for multiclass support vector machines,” IEEE Transactions on Neural Networks, vol. 13, no. 2, pp. 415-425, Mar. 2002
work page 2002
-
[4]
Effect of small sample size on text categorization with support vector machines,
P. Matykiewicz and J. Pestian, “Effect of small sample size on text categorization with support vector machines,” Proceedings of the 2012 Workshop on Biomedical Natural Language Processing , pp. 193-201, June 2012
work page 2012
-
[5]
M. A. B. Altaf, J. Tillak, Y . Kifle, and J. Yoo, “A 1.83 µJ/classification nonlinear support-vector-machine-based patient-specific seizure classifi- cation SoC,” Int. Solid-State Circuits Conf. (ISSCC) Digest of Technical Papers, pp. 100–101, Feb. 2013
work page 2013
-
[6]
C. E. Lee, T. Chen, and Z. Zhang, “A 127mW 1.63 TOPS sparse spatio- temporal cognitive SoC for action classification and motion tracking in videos,” Symposia on VLSI Technology and Circuits , pp. C226-C227, June 2017
work page 2017
-
[7]
S. Jeong, Y . Chen, T. Jang, J. Tsai, D. Blaauw, H.-S. Kim, D. Sylvester, “A 12nW always-on acoustic sensing and object recognition microsys- tem using frequency-domain feature extraction and SVM classification,” IEEE International Solid-State Circuits Conference (ISSCC) , pp. 362- 363, Feb. 2017
work page 2017
-
[8]
K. H. Lee, and N. Verma, “A low-power processor with configurable embedded machine-learning accelerators for high-order and adaptive analysis of medical-sensor signals,” IEEE Journal of Solid-State Circuits, vol. 48, no. 7, pp. 1625–1637, Apr. 2013
work page 2013
-
[9]
Security of IoT systems: Design challenges and opportunities,
T. Xu, J. B. Wendt, and M. Potkonjak, “Security of IoT systems: Design challenges and opportunities,” IEEE/ACM International Conference on Computer-Aided Design (ICCAD), pp. 417–423, Nov. 2014
work page 2014
-
[10]
A 1.9mW SVM Processor with On-chip Active Learning for Epileptic Seizure Control,
S.-A. Huang, K.-C. Chang, H.-H. Liou, and C.-H. Yang, “A 1.9mW SVM Processor with On-chip Active Learning for Epileptic Seizure Control,” Proc. Int. Symposium on VLSI Circuits (VLSI) , pp. 259- 260, June 2018
work page 2018
-
[11]
Fast training of support vector machines using sequential minimal optimization,
J. Platt, “Fast training of support vector machines using sequential minimal optimization,” Advances in Kernel Methods Support Vector Learning, MIT Press, pp. 185-208, 1999
work page 1999
-
[12]
LIBSVM: A library for support vector machines,
C.-C. Chang and C.-J. Lin, “LIBSVM: A library for support vector machines,” ACM Transactions on Intelligent Systems and Technology , vol. 2, no. 3, pp. 27:1–27:27, Apr. 2011
work page 2011
-
[13]
Cutting-plane training of structural SVMs,
T. Joachims, T. Finley, and C.-N. J. Yu, “Cutting-plane training of structural SVMs,” Machine Learning , vol. 77, no. 1, pp. 27–59, Oct. 2009
work page 2009
-
[14]
S. Boyd, N. Parikh, E. Chu, B. Peleato, and J. Eckstein, “Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers,” Foundations and Trends in Machine Learning , vol. 3, no. 1, pp. 1–122, Nov. 2011
work page 2011
-
[15]
G.-B. Ye, Y . Chen, and X. Xie, “Efficient variable selection in support vector machines via the alternating direction method of multipliers,” Artificial Intelligence and Statistics (AISTATS) , vol. 15, pp. 832–840, Apr. 2011
work page 2011
-
[16]
P. Drineas, and M. W. Mahoney, “On the Nystr ¨om method for approx- imating a gram matrix for improved kernel-based learning, Journal of Machine Learning Research,” Journal of Machine Learning Research , vol. 6, pp. 2153-2175, Dec. 2005
work page 2005
-
[17]
Kernel methods in machine learning,
T. Hofmann, B. Schlkopf, and A. J. Smola, “Kernel methods in machine learning,” The Annals of Statistics, vol. 36, no. 3, pp. 1171-1220, June, 2008
work page 2008
-
[18]
The CORDIC trigonometric computing technique,
J. V older, “The CORDIC trigonometric computing technique,” IRE Trans. Elect. Comp., vol. EC–8, pp. 330–334, Sep. 1959
work page 1959
-
[19]
50 years of CORDIC: algorithms, architectures, and applications,
P. K. Meher, J. Valls, T.-B. Juang, K. Sridharan, and K. Maharatna, “50 years of CORDIC: algorithms, architectures, and applications,” IEEE Trans. Circuits Syst.I Reg. Papers, vol. 56, pp. 1893–1907, Sep. 2009
work page 1907
-
[20]
Christopher M. Bishop, Pattern Recognition and Machine Learning (Information Science and Statistics), Springer-Verlag, 2006. 10
work page 2006
-
[21]
H. W. Kuhn and A. W. Tucker “Nonlinear programming,” Proceedings of 2nd Berkeley Symposium. Berkeley: University of California Press , pp. 481–492, 1951
work page 1951
-
[22]
Split Bregman method for large scale fused Lasso
G.B. Ye and X. Xie, “Split Bregman method for large scale fused Lasso,” Arxiv preprint, arXiv:1006.5086, 2010
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[23]
Methods of Conjugate Gradients for Solving Linear Systems,
M. R. Hestenes and E. Stiefel, “Methods of Conjugate Gradients for Solving Linear Systems,” Journal of Research of the National Bureau of Standards, vol. 49, no. 6, pp. 409-436, Dec. 1952
work page 1952
-
[24]
Sparse nonlinear support vector machines via stochastic approximation,
S. Lee, and S. J. Wright, “Sparse nonlinear support vector machines via stochastic approximation,” Technical Report of Univ. of Wisconsin, 2010
work page 2010
-
[25]
Hardware and software design for QR Decomposition Recursive Least Square algorithm,
S. Niu, Wang, S., S. Aslan, and J. Saniie, “Hardware and software design for QR Decomposition Recursive Least Square algorithm,” International Midwest Symposium on Circuits and Systems (MWSCAS, pp. 117–120, Aug. 2013
work page 2013
-
[26]
An 81.6 µW FastICA Processor for Epileptic Seizure Detection,
C.-H. Yang, Y .-H. Shih, and H. Chiueh “An 81.6 µW FastICA Processor for Epileptic Seizure Detection,” IEEE Transactions on Biomedical Circuits and Systems, vol. 9, no. 1, pp. 60–71, Feb. 2015
work page 2015
-
[27]
Shoeb, Application of Machine Learning to Epileptic Seizure Onset Detection and Treatment , Ph
A. Shoeb, Application of Machine Learning to Epileptic Seizure Onset Detection and Treatment , Ph. D. Thesis, Massachusetts Institute of Technology, Sep. 2009
work page 2009
-
[28]
A. Goldberger et al. , “PhysioBank, PhysioToolkit, and PhysioNet: Components of a New Research Resource for Complex Physiologic Signals,” Circulation, vol. 101, no. 23, pp. 215–220, June 2000
work page 2000
- [29]
-
[30]
Yann LeCun and Corinna Cortes, MNIST handwritten digit database [http://yann.lecun.com/exdb/mnist/], June, 2010
work page 2010
-
[31]
https://github.com/LamaHamadeh/Pima-Indians-Diabetes-DataSet-UCI
-
[32]
An efficient Jacobi-like algorithm for parallel eigenvalue computation,
J. Gotze, S. Paul, and M. Sauer, “An efficient Jacobi-like algorithm for parallel eigenvalue computation,” IEEE Trans. Computers, vol. 42, no. 9, pp. 1058–1065, Sep. 1993
work page 1993
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.