Ask the Right Comparison:Bias-Aware Bayesian Active Top-k Ranking with LLM Judges
Pith reviewed 2026-07-03 17:16 UTC · model grok-4.3
The pith
Bayesian modeling of per-judge biases plus top-k focused selection recovers true rankings from biased LLM comparisons.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
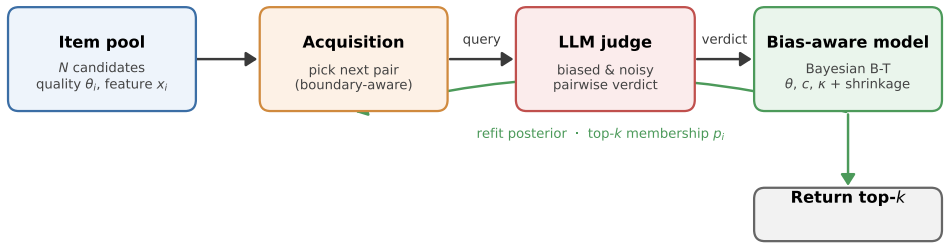
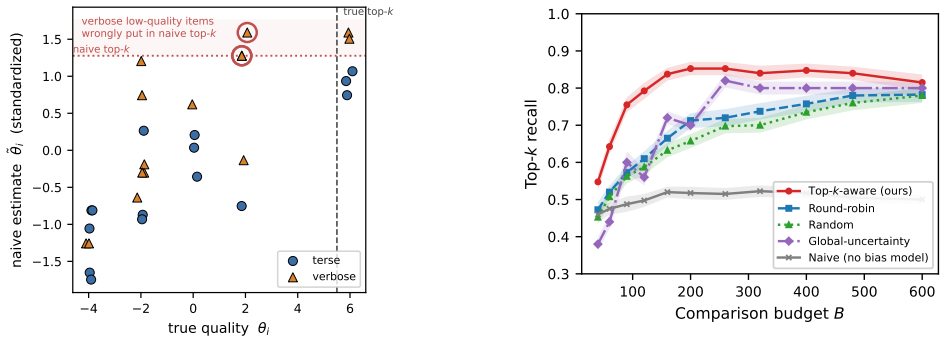
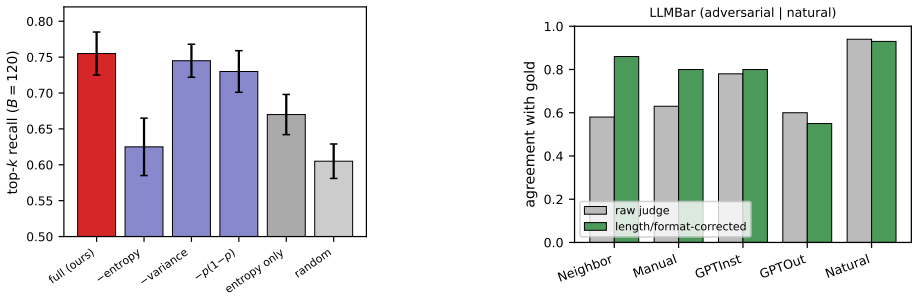
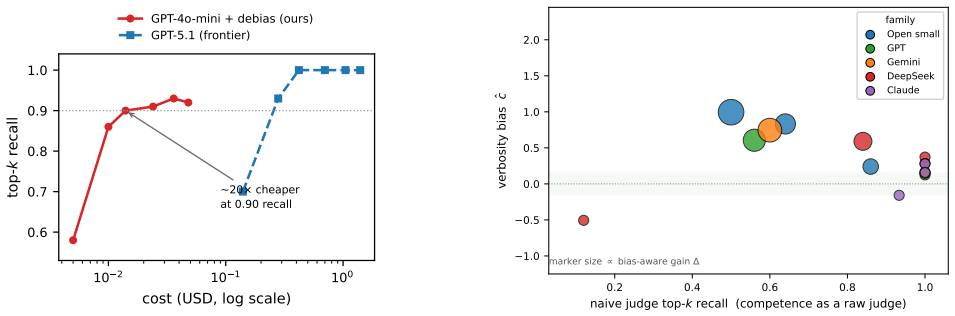
Casting pairwise LLM judgments as Bayesian inference over latent item qualities, with judge-specific bias covariates for verbosity and position under a shrinkage prior, combined with an acquisition function that selects comparisons to reduce uncertainty in top-k membership, recovers the ground-truth top-k set even when judges are biased; naive aggregation plateaus at the wrong set regardless of budget, and the top-k-aware rule reaches the recovered ceiling with substantially fewer comparisons than round-robin or global-uncertainty baselines.
What carries the argument
Bayesian posterior over latent qualities with per-judge bias covariates (verbosity, position) under shrinkage prior, paired with a top-k membership uncertainty reduction acquisition rule.
If this is right
- Naive aggregation of LLM judgments plateaus at an incorrect top-k regardless of budget when judges carry stable biases.
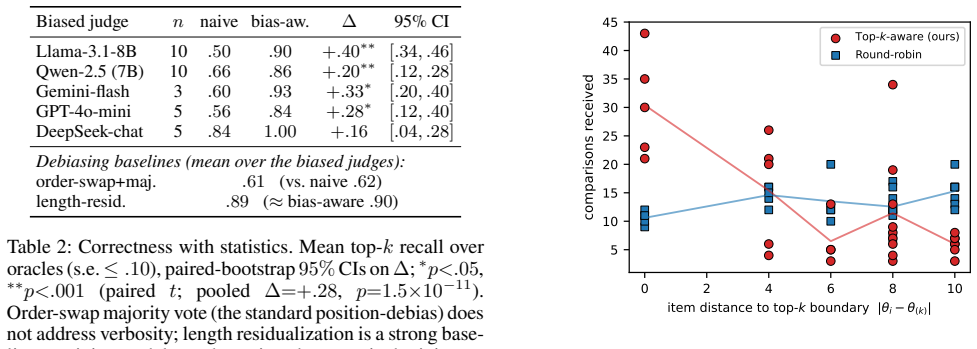
- The bias-aware model corrects recall on true top-k membership from approximately 0.5-0.6 to 0.84-1.0 for biased judges.
- Top-k-aware acquisition reaches the performance ceiling with far fewer comparisons than round-robin or D-optimal rules.
- Frontier models exhibit little measurable bias so the modeling adds little value, while cheaper and mid-tier models show large gains from explicit correction.
Where Pith is reading between the lines
- The same bias-modeling structure could be reused on human preference data if position and length effects are recorded.
- Adding further covariates such as formatting or content length would test whether the shrinkage prior continues to select the relevant biases automatically.
- Running the method on repeated judgments of the same items would check whether the estimated bias parameters remain stable enough for long-running ranking tasks.
Load-bearing premise
The chosen covariates for verbosity and position together with the shrinkage prior are sufficient to capture the judge biases that distort top-k membership, and those biases remain stable enough to be estimated reliably from the data.
What would settle it
Apply the bias-aware model and top-k acquisition to a new set of items and judges where ground-truth top-k is known but biases arise from factors other than verbosity or position, then measure whether top-k recall stays below the naive baseline.
Figures
read the original abstract
Large language models (LLMs) are increasingly used as cheap, scalable judges that compare candidate outputs pairwise -- to rank responses, select models, or triage papers. Yet LLM judges are both noisy and systematically biased: they favor verbose or well-formatted answers and exhibit position effects, so simply aggregating their votes recovers a ranking of presentation, not of true quality. We study the practical goal of identifying the \topk{} items under a fixed comparison budget, and make two contributions. First, we cast judging as Bayesian inference over latent quality with explicit, judge-specific bias covariates (verbosity, position), regularized by a shrinkage prior so that the data decide which biases a given judge actually exhibits. Second, we introduce a \topk-aware active acquisition rule that chooses the next comparison to maximally reduce uncertainty about \topk{} \emph{membership}, rather than about the full ranking. On a controlled benchmark with known ground-truth quality, judged by sixteen real LLMs spanning open and proprietary families (Llama, Qwen, Phi-4, GPT-4o-mini/5.1/5.5, Gemini, DeepSeek, and Claude Haiku/Sonnet/Opus), naive aggregation plateaus at a wrong \topk{} on biased judges regardless of budget, while our bias-aware model recovers it; \topk-aware acquisition reaches this ceiling with far fewer comparisons than round-robin or a global-uncertainty (D-optimal) rule. Bias is real but heterogeneous and capability-dependent: cheap and mid-tier judges carry a strong verbosity bias that our model corrects (lifting recall from $\sim$$0.5$--$0.6$ to $0.84$--$1.0$), whereas the frontier judges we tested show little bias and already rank accurately, so bias-aware modeling changes little there.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes casting LLM pairwise judging as Bayesian inference over latent item quality, with judge-specific bias covariates for verbosity and position regularized by a shrinkage prior. It introduces a top-k-aware acquisition function that selects comparisons to reduce uncertainty in top-k membership rather than global ranking uncertainty. Controlled experiments across 16 real LLMs with known ground-truth quality show that naive vote aggregation plateaus at an incorrect top-k on biased judges, while the bias-aware model recovers the true top-k and the proposed acquisition reaches this performance with substantially fewer comparisons than round-robin or D-optimal baselines. Bias strength is reported as heterogeneous across model families.
Significance. If the empirical recovery holds under the stated modeling assumptions, the work provides a practical, budget-efficient method for reliable top-k selection when using LLM judges, directly addressing a common failure mode in current evaluation pipelines. The scale of the benchmark (16 LLMs spanning open and proprietary families) and the explicit separation between naive and bias-aware performance are strengths that would make the result useful to practitioners.
major comments (1)
- [Methods and Experiments] The central empirical claim—that bias-aware modeling recovers the correct top-k where naive aggregation fails—depends on the chosen covariates (verbosity, position) plus the shrinkage prior being sufficient to capture the systematic distortions that actually alter top-k membership. The abstract and experimental description supply no residual diagnostics, ablation removing individual covariates, or checks on whether unmodeled effects (content-style interactions, pair-dependent biases) remain after fitting. This is load-bearing for the recovery result on the controlled benchmark.
minor comments (2)
- [Experiments] Error bars, standard deviations, or statistical significance measures for the reported recall lifts (e.g., ~0.5–0.6 to 0.84–1.0) and for the acquisition-function comparisons are not mentioned; adding them would allow readers to assess variability across the 16 LLMs and random seeds.
- [Results] The abstract states that frontier models show little bias while cheaper models exhibit strong verbosity bias, but does not report the fitted bias coefficient magnitudes or their posterior intervals; including these values would make the heterogeneity claim more concrete.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The major comment concerns the sufficiency of our chosen covariates and prior, along with the absence of residual diagnostics and ablations. We address this point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Methods and Experiments] The central empirical claim—that bias-aware modeling recovers the correct top-k where naive aggregation fails—depends on the chosen covariates (verbosity, position) plus the shrinkage prior being sufficient to capture the systematic distortions that actually alter top-k membership. The abstract and experimental description supply no residual diagnostics, ablation removing individual covariates, or checks on whether unmodeled effects (content-style interactions, pair-dependent biases) remain after fitting. This is load-bearing for the recovery result on the controlled benchmark.
Authors: We agree that explicit residual diagnostics, covariate ablations, and checks for unmodeled effects would strengthen the validation of the modeling assumptions. The current results rely on the controlled benchmark with known ground-truth quality, where the bias-aware model demonstrably recovers the true top-k while naive aggregation does not, across 16 LLMs. The shrinkage prior is intended to let the data determine judge-specific bias strength. To directly address the concern, we will add in revision: (i) ablation experiments removing verbosity and position covariates individually and reporting the resulting change in top-k recovery, (ii) posterior predictive checks and residual analysis stratified by judge to assess remaining systematic errors, and (iii) a discussion of potential content-style or pair-dependent biases with suggestions for future extensions. These additions will clarify the scope of the current covariates. revision: yes
Circularity Check
No significant circularity; empirical recovery of ground-truth top-k
full rationale
The paper presents a Bayesian model for latent quality with judge-specific bias covariates (verbosity, position) plus shrinkage prior, plus a top-k membership acquisition rule. All load-bearing claims are evaluated by recovery of known ground-truth rankings on a held-out benchmark of 16 real LLMs; naive aggregation fails while the bias-aware model succeeds, and the acquisition rule reaches the same ceiling faster. No equation reduces a prediction to a fitted parameter by construction, no uniqueness theorem is imported via self-citation, and no ansatz is smuggled. The derivation chain is self-contained against external ground-truth and does not rely on quantities defined in terms of its own outputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- judge-specific bias coefficients
axioms (1)
- domain assumption LLM pairwise judgments can be modeled as noisy observations of latent quality plus additive judge-specific bias terms for verbosity and position.
Reference graph
Works this paper leans on
-
[1]
Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education
Clancey, William J. Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education. Proceedings of the Eighth International Joint Conference on Artificial Intelligence (IJCAI-83)
-
[2]
Classification Problem Solving
Clancey, William J. Classification Problem Solving. Proceedings of the Fourth National Conference on Artificial Intelligence
-
[3]
, title =
Robinson, Arthur L. , title =. 1980 , doi =. https://science.sciencemag.org/content/208/4447/1019.full.pdf , journal =
1980
-
[4]
New Ways to Make Microcircuits Smaller---Duplicate Entry
Robinson, Arthur L. New Ways to Make Microcircuits Smaller---Duplicate Entry. Science
-
[5]
Clancey and Glenn Rennels , abstract =
Diane Warner Hasling and William J. Clancey and Glenn Rennels , abstract =. Strategic explanations for a diagnostic consultation system , journal =. 1984 , issn =. doi:https://doi.org/10.1016/S0020-7373(84)80003-6 , url =
-
[6]
and Rennels, Glenn R
Hasling, Diane Warner and Clancey, William J. and Rennels, Glenn R. and Test, Thomas. Strategic Explanations in Consultation---Duplicate. The International Journal of Man-Machine Studies
-
[7]
Poligon: A System for Parallel Problem Solving
Rice, James. Poligon: A System for Parallel Problem Solving
-
[8]
Transfer of Rule-Based Expertise through a Tutorial Dialogue
Clancey, William J. Transfer of Rule-Based Expertise through a Tutorial Dialogue
-
[9]
The Engineering of Qualitative Models
Clancey, William J. The Engineering of Qualitative Models
-
[10]
2023 , eprint=
Attention Is All You Need , author=. 2023 , eprint=
2023
-
[11]
Pluto: The 'Other' Red Planet
NASA. Pluto: The 'Other' Red Planet
-
[12]
The Method of Paired Comparisons , author=
Rank Analysis of Incomplete Block Designs: I. The Method of Paired Comparisons , author=. Biometrika , volume=
-
[13]
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and others , booktitle=. Judging
-
[14]
Proceedings of the Association for Computational Linguistics (ACL) , year=
Large Language Models are not Fair Evaluators , author=. Proceedings of the Association for Computational Linguistics (ACL) , year=
-
[15]
International Conference on Learning Representations (ICLR) , year=
Evaluating Large Language Models at Evaluating Instruction Following , author=. International Conference on Learning Representations (ICLR) , year=
-
[16]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Dubois, Yann and Galambosi, Bal. Length-Controlled. arXiv preprint arXiv:2404.04475 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Verbosity bias in preference labeling by large language models.arXiv preprint arXiv:2310.10076,
Verbosity Bias in Preference Labeling by Large Language Models , author=. arXiv preprint arXiv:2310.10076 , year=
-
[18]
From Generation to Judgment: Opportunities and Challenges of
Li, Dawei and Jiang, Bohan and Huang, Liangjie and others , journal=. From Generation to Judgment: Opportunities and Challenges of
-
[19]
Findings of the Association for Computational Linguistics (ACL) , year=
Bayesian Prompt Ensembles: Model Uncertainty Estimation for Black-Box Large Language Models , author=. Findings of the Association for Computational Linguistics (ACL) , year=
-
[20]
Ross, Brendan Leigh and Vouitsis, No. Textual. arXiv preprint arXiv:2506.10060 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Huang, Hang and others , journal=
-
[22]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Deep Bayesian Active Learning for Preference Modeling in Large Language Models , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[23]
Bayesian Active Learning for Classification and Preference Learning
Bayesian Active Learning for Classification and Preference Learning , author=. arXiv preprint arXiv:1112.5745 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Online Rank Elicitation for
Sz. Online Rank Elicitation for. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[25]
The Annals of Statistics , volume=
Active Ranking from Pairwise Comparisons and When Parametric Assumptions Do Not Help , author=. The Annals of Statistics , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.