Simplifying Flow Matching Transformations with Low-Rank Mixture Models
Pith reviewed 2026-06-30 07:40 UTC · model grok-4.3
The pith
Mixtures of probabilistic principal component analyzers simplify the transformations learned by normalizing flows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
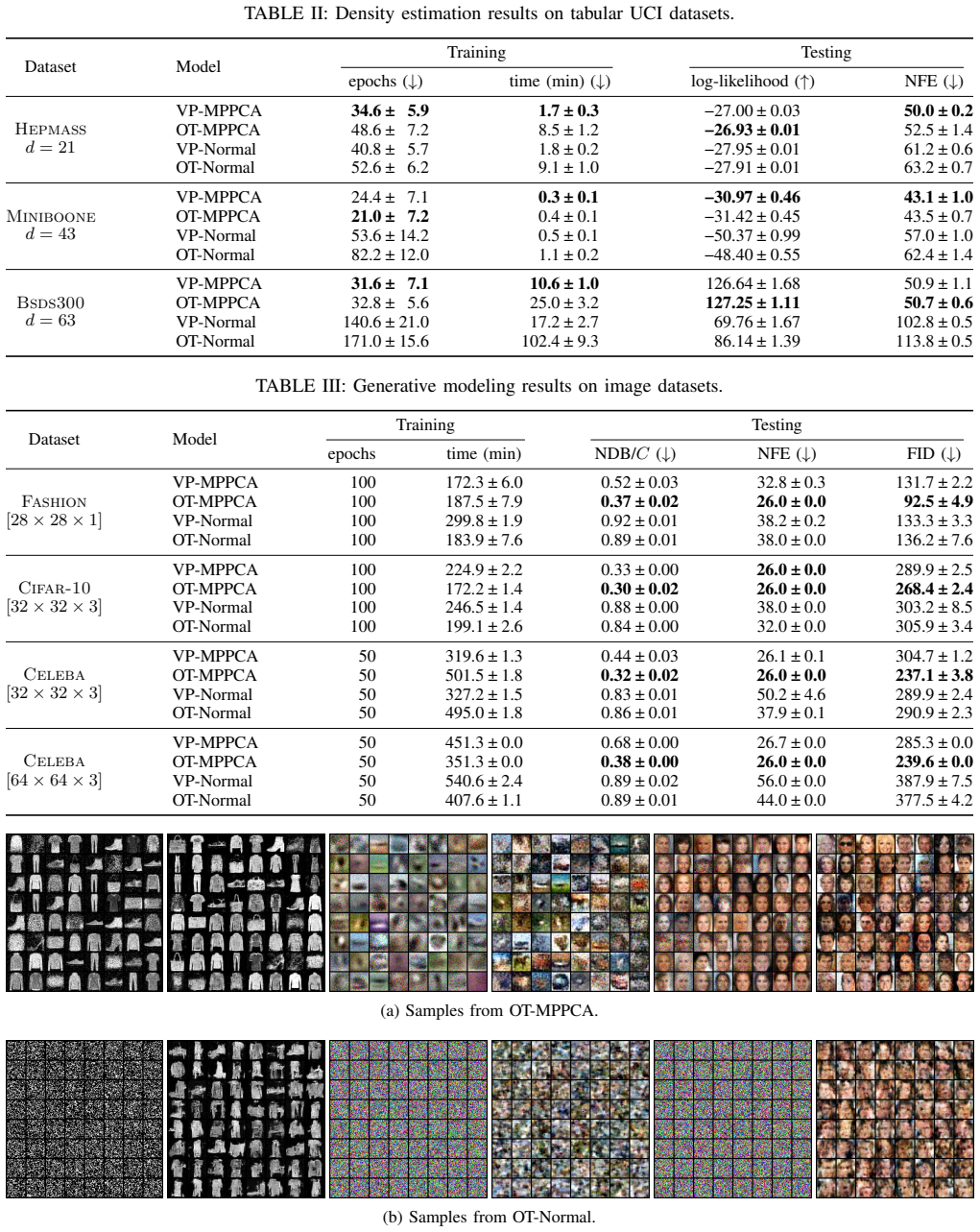
The authors propose replacing the standard Gaussian base distribution in normalizing flows with a mixture of probabilistic principal component analyzers. This choice reduces the KL divergence between the latent and data distributions, which in turn simplifies the invertible transformation the flow must learn. Because the mixture components are low-rank and can be estimated quickly via the EM algorithm, the method provides a computationally cheap way to initialize a more data-aligned latent density.
What carries the argument
Mixtures of probabilistic principal component analyzers (MPPCA) fitted by expectation-maximization, serving as a structured latent density that approximates the data manifold with low-rank Gaussians.
If this is right
- The flow requires fewer training steps to achieve good performance.
- Generation quality improves on tabular and image datasets compared to standard normal baselines.
- The method adds little computational cost because MPPCA fitting uses the fast EM algorithm.
- The approach is architecture-agnostic and can be used with various flow models.
Where Pith is reading between the lines
- Low-rank mixture models could replace standard bases in related models like continuous normalizing flows or diffusion models.
- Pre-fitting the latent density might generalize to other density estimation tasks where distribution mismatch slows learning.
- Testing the method on very large scale image datasets would reveal if the gains hold when dimensionality increases further.
Load-bearing premise
MPPCA models can be fit quickly and cheaply using the expectation-maximization algorithm even in high-dimensional settings.
What would settle it
Observing no improvement in training speed or generation quality when using MPPCA instead of standard normal as the latent density on the paper's tabular and image datasets would falsify the central claim.
Figures



read the original abstract
Normalizing flows are powerful generative models that learn an invertible mapping between complex data distributions and simple latent distributions, typically a standard normal density. However, this choice of latent density can impose unnecessary complexity on the learned flow transformation due to the topological mismatch between the latent and data densities, leading to slower training and suboptimal performance. In this work, we propose using mixtures of probabilistic principal component analyzers (MPPCA) as the latent density for normalizing flows. We simplify the learned flow transformation by learning a latent distribution that more closely aligns with the data distribution in terms of KL divergence, thus enabling faster convergence and improved generative performance. Critically, MPPCA models can be fit quickly and cheaply using the expectation-maximization algorithm, making them a practical choice for initializing latent distributions even in high-dimensional generative tasks. We validate our method on both tabular and image datasets, demonstrating consistent gains in training efficiency and generation quality compared to baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes replacing the standard normal base density in normalizing flows with a mixture of probabilistic principal component analyzers (MPPCA) fitted once via the expectation-maximization (EM) algorithm. The central claim is that the resulting tighter KL alignment between latent and data distributions reduces the complexity of the learned invertible map, yielding faster convergence and improved generative performance; the approach is validated on tabular and image datasets with claims of consistent gains over baselines.
Significance. If the empirical gains are reproducible and the MPPCA base remains tractable at scale, the method supplies a practical, closed-form initialization for the latent density that directly addresses the topological mismatch problem in flow training without altering the core flow architecture or requiring new optimization machinery.
major comments (1)
- [Abstract] Abstract: the assertion of 'consistent gains in training efficiency and generation quality' is unsupported by any reported metrics, baselines, error bars, dataset sizes, or exclusion criteria; without these the central empirical claim cannot be evaluated and must be substantiated in the results section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address the single major comment below and will revise the manuscript accordingly to strengthen the presentation of our empirical results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion of 'consistent gains in training efficiency and generation quality' is unsupported by any reported metrics, baselines, error bars, dataset sizes, or exclusion criteria; without these the central empirical claim cannot be evaluated and must be substantiated in the results section.
Authors: We agree that the abstract summarizes the empirical findings at a high level without quantitative details. The full manuscript's results section reports the supporting evidence, including specific metrics for training efficiency and sample quality, direct comparisons to standard normal baselines, error bars from multiple independent runs, exact dataset sizes and preprocessing details for both tabular and image experiments, and the experimental protocol. To address the concern directly, we will revise the abstract to incorporate a small number of key quantitative results (e.g., relative improvements in convergence iterations and generation metrics) while retaining its brevity, thereby making the central claim self-contained and explicitly tied to the results section. revision: yes
Circularity Check
No significant circularity
full rationale
The proposal replaces the standard normal base density with an MPPCA density fitted once via the external EM algorithm to the data. This changes the flow objective from log p_N to log p_MPPCA but introduces no self-referential fitting, no parameter that is both input and output of the same optimization, and no load-bearing self-citation. The claimed benefit (tighter KL alignment reducing required flow complexity) follows directly from the modeling choice without reducing to a quantity defined by the flow parameters themselves. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MPPCA models can be fit quickly and cheaply using the expectation-maximization algorithm even in high-dimensional settings
Reference graph
Works this paper leans on
-
[1]
Variational inference with normal- izing flows,
D. Rezende and S. Mohamed, “Variational inference with normal- izing flows,” inInternational Conference on Machine Learning (ICML), 2015, pp. 1530–1538
2015
-
[2]
Neural ordinary differential equations,
R. T. Chen, Y . Rubanova, J. Bettencourt, and D. K. Duvenaud, “Neural ordinary differential equations,”Advances in Neural Infor- mation Processing Systems (NeurIPS), vol. 31, 2018
2018
-
[3]
FFJORD: Free-form continuous dynamics for scal- able reversible generative models,
W. Grathwohl, R. T. Chen, J. Bettencourt, I. Sutskever, and D. Duvenaud, “FFJORD: Free-form continuous dynamics for scal- able reversible generative models,” inInternational Conference on Learning Representations (ICLR), 2018
2018
-
[4]
Flow matching for generative modeling,
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,” inInternational Conference on Learning Representations (ICLR), 2023
2023
-
[5]
Improving and generalizing flow-based generative models with minibatch optimal transport,
A. Tong et al., “Improving and generalizing flow-based generative models with minibatch optimal transport,”Transactions on Machine Learning Research, 2024
2024
-
[6]
How to train your neural ode: The world of Jacobian and kinetic regularization,
C. Finlay, J.-H. Jacobsen, L. Nurbekyan, and A. Oberman, “How to train your neural ode: The world of Jacobian and kinetic regularization,” inInternational Conference on Machine Learning (ICML), 2020, pp. 3154–3164
2020
-
[7]
Flow straight and fast: Learning to generate and transfer data with rectified flow,
X. Liu, C. Gong, et al., “Flow straight and fast: Learning to generate and transfer data with rectified flow,” inInternational Conference on Learning Representations (ICLR), 2023
2023
-
[8]
Multisample flow matching: Straightening flows with minibatch couplings,
A.-A. Pooladian, H. Ben-Hamu, C. Domingo-Enrich, B. Amos, Y . Lipman, and R. T. Chen, “Multisample flow matching: Straightening flows with minibatch couplings,” inInternational Conference on Machine Learning (ICML), 2023, pp. 28 100–28 127
2023
-
[9]
Mixtures of probabilistic prin- cipal component analyzers,
M. E. Tipping and C. M. Bishop, “Mixtures of probabilistic prin- cipal component analyzers,”Neural Computation, vol. 11, no. 2, pp. 443–482, 1999
1999
-
[10]
Masked autoregres- sive flow for density estimation,
G. Papamakarios, T. Pavlakou, and I. Murray, “Masked autoregres- sive flow for density estimation,”Advances in Neural Information Processing Systems (NIPS), vol. 30, 2017
2017
-
[11]
Made: Masked autoencoder for distribution estimation,
M. Germain, K. Gregor, I. Murray, and H. Larochelle, “Made: Masked autoencoder for distribution estimation,” inInternational Conference on Machine Learning (ICML), 2015, pp. 881–889
2015
-
[12]
Training normalizing flows with the information bottleneck for competitive generative classification,
L. Ardizzone, R. Mackowiak, C. Rother, and U. K ¨othe, “Training normalizing flows with the information bottleneck for competitive generative classification,”Advances in Neural Information Process- ing Systems (NeurIPS), vol. 33, pp. 7828–7840, 2020
2020
-
[13]
Semi- supervised learning with normalizing flows,
P. Izmailov, P. Kirichenko, M. Finzi, and A. G. Wilson, “Semi- supervised learning with normalizing flows,” inInternational Con- ference on Machine Learning (ICML), 2020, pp. 4615–4630
2020
-
[14]
Stabilizing invertible neural net- works using mixture models,
P. Hagemann and S. Neumayer, “Stabilizing invertible neural net- works using mixture models,”Inverse Problems, vol. 37, no. 8, 2021
2021
-
[15]
Resam- pling base distributions of normalizing flows,
V . Stimper, B. Sch ¨olkopf, and J. M. Hern ´andez-Lobato, “Resam- pling base distributions of normalizing flows,” inInternational Conference on Artificial Intelligence and Statistics (AISTATS), 2022, pp. 4915–4936
2022
-
[16]
OT-Flow: Fast and accurate continuous normalizing flows via optimal transport,
D. Onken, S. W. Fung, X. Li, and L. Ruthotto, “OT-Flow: Fast and accurate continuous normalizing flows via optimal transport,” inAAAI Conference on Artificial Intelligence (AAAI), vol. 35, 2021, pp. 9223–9232
2021
-
[17]
A well-conditioned estimator for large- dimensional covariance matrices,
O. Ledoit and M. Wolf, “A well-conditioned estimator for large- dimensional covariance matrices,”Journal of Multivariate Analysis, vol. 88, no. 2, pp. 365–411, 2004
2004
-
[18]
The EM algorithm for mixtures of factor analyzers,
Z. Ghahramani, G. E. Hinton, et al., “The EM algorithm for mixtures of factor analyzers,” University of Toronto, Tech. Rep. CRG-TR-96-1, 1996
1996
-
[19]
On GANs and GMMs,
E. Richardson and Y . Weiss, “On GANs and GMMs,”Advances in Neural Information Processing Systems (NeurIPS), vol. 31, 2018
2018
-
[20]
The CMA Evolution Strategy: A Tutorial
N. Hansen, “The CMA evolution strategy: A tutorial,”arXiv preprint arXiv:1604.00772, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[21]
M. J. Kochenderfer and T. A. Wheeler,Algorithms for Optimization. MIT Press, 2019
2019
-
[22]
Normalizing flows for probabilistic modeling and inference,
G. Papamakarios, E. Nalisnick, D. J. Rezende, S. Mohamed, and B. Lakshminarayanan, “Normalizing flows for probabilistic modeling and inference,”Journal of Machine Learning Research, vol. 22, no. 57, pp. 1–64, 2021
2021
-
[23]
Stochastic Interpolants: A Unifying Framework for Flows and Diffusions
M. S. Albergo, N. M. Boffi, and E. Vanden-Eijnden, “Stochastic interpolants: A unifying framework for flows and diffusions,”arXiv preprint arXiv:2303.08797, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Action matching: Learning stochastic dynamics from samples,
K. Neklyudov, R. Brekelmans, D. Severo, and A. Makhzani, “Action matching: Learning stochastic dynamics from samples,” inInternational Conference on Machine Learning (ICML), 2023, pp. 25 858–25 889
2023
-
[25]
Neural spline flows,
C. Durkan, A. Bekasov, I. Murray, and G. Papamakarios, “Neural spline flows,”Advances in Neural Information Processing Systems (NeurIPS), vol. 32, 2019
2019
-
[26]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
H. Xiao, K. Rasul, and R. V ollgraf, “Fashion-MNIST: A novel image dataset for benchmarking machine learning algorithms,” arXiv preprint arXiv:1708.07747, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Deep learning face attributes in the wild,
Z. Liu, P. Luo, X. Wang, and X. Tang, “Deep learning face attributes in the wild,” inInternational Conference on Computer Vision (ICCV), 2015, pp. 3730–3738
2015
-
[28]
Learning multiple layers of features from tiny images,
A. Krizhevsky and G. Hinton, “Learning multiple layers of features from tiny images,” Tech. Rep., 2009
2009
-
[29]
GANstrained by a two time-scale update rule converge to a local Nash equilibrium,
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochre- iter, “GANstrained by a two time-scale update rule converge to a local Nash equilibrium,”Advances in Neural Information Process- ing Systems (NIPS), vol. 30, 2017
2017
-
[30]
U-net: Convolutional net- works for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional net- works for biomedical image segmentation,” inMedical Image Com- puting and Computer-Assisted Intervention (MICCAI), Springer, 2015, pp. 234–241
2015
-
[31]
Improved denoising diffusion prob- abilistic models,
A. Q. Nichol and P. Dhariwal, “Improved denoising diffusion prob- abilistic models,” inInternational Conference on Machine Learning (ICML), 2021, pp. 8162–8171
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.