Does Text Actually Help? Uncovering and Resolving Text Collapse in Multimodal Time Series Forecasting
Pith reviewed 2026-06-26 21:16 UTC · model grok-4.3
The pith
Text collapse occurs because numerical inputs dominate multimodal time series models, but exclusive residual supervision on the text branch forces it to extract genuine content from descriptions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
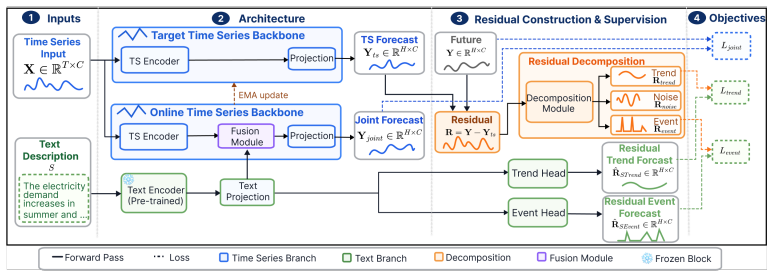
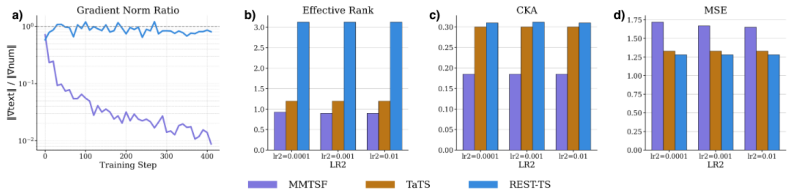
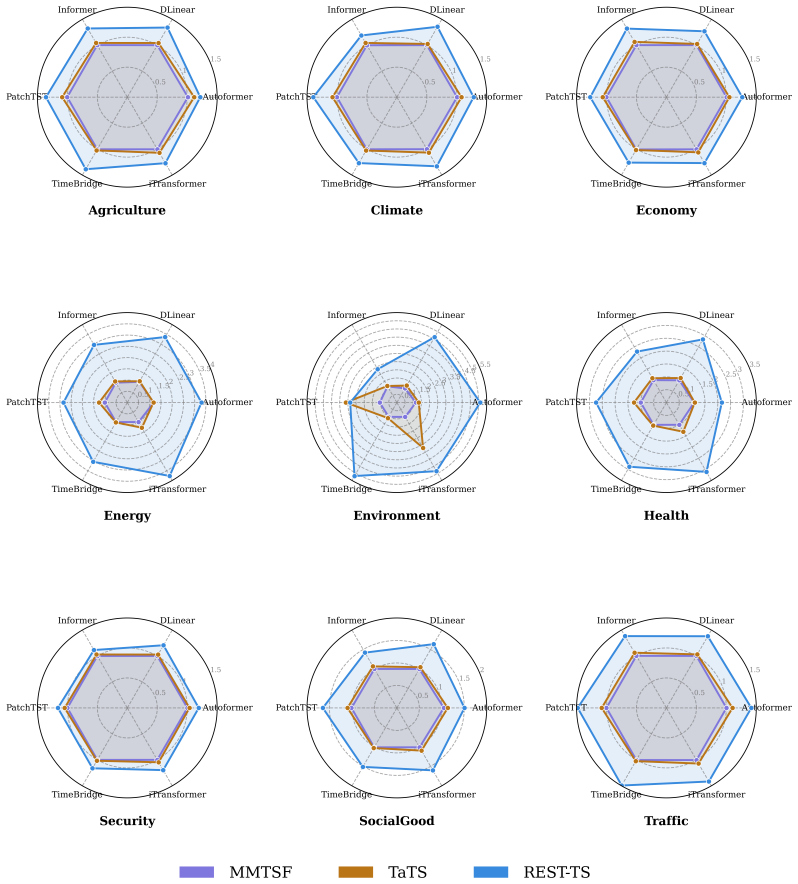
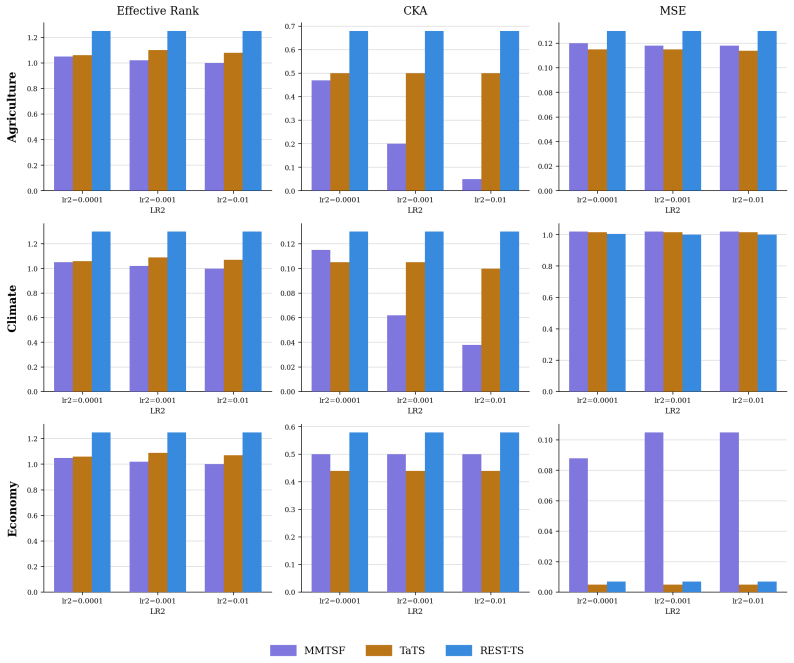
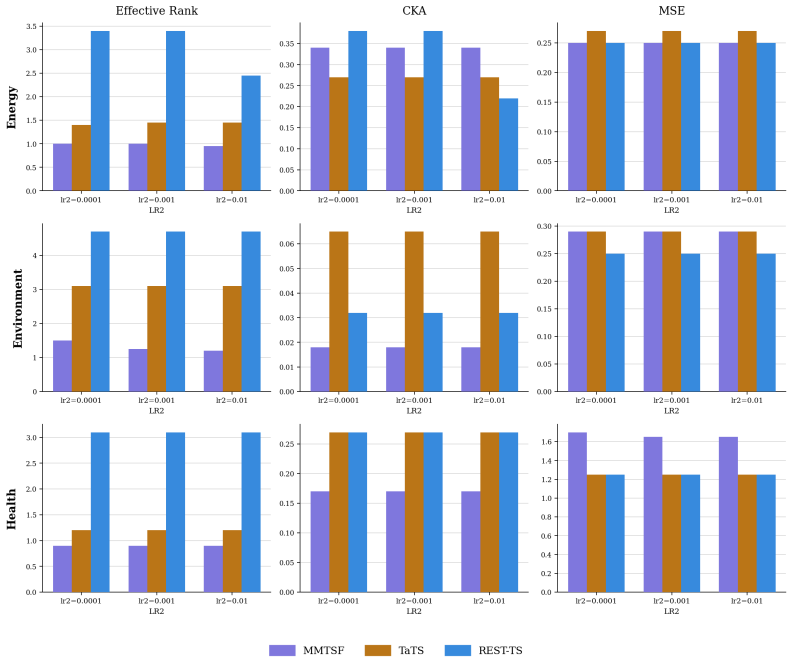
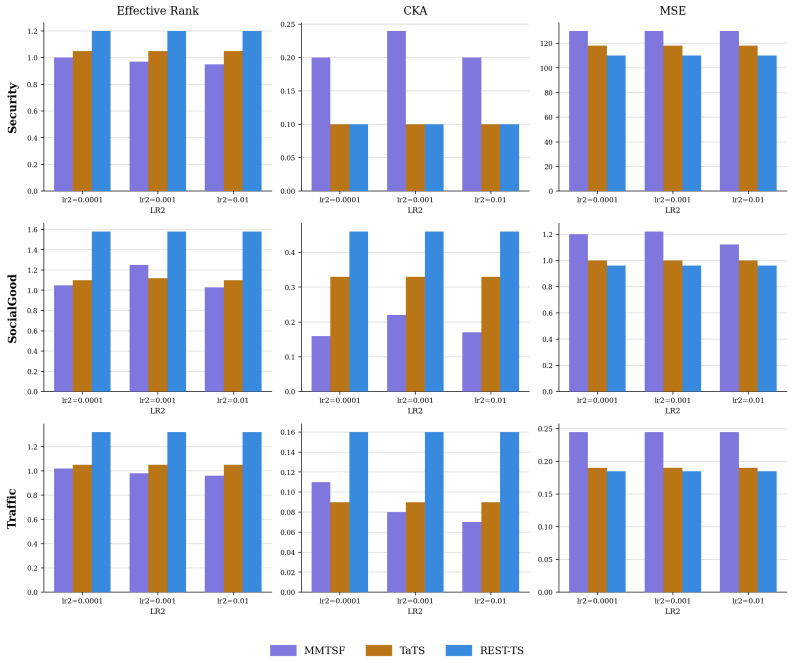
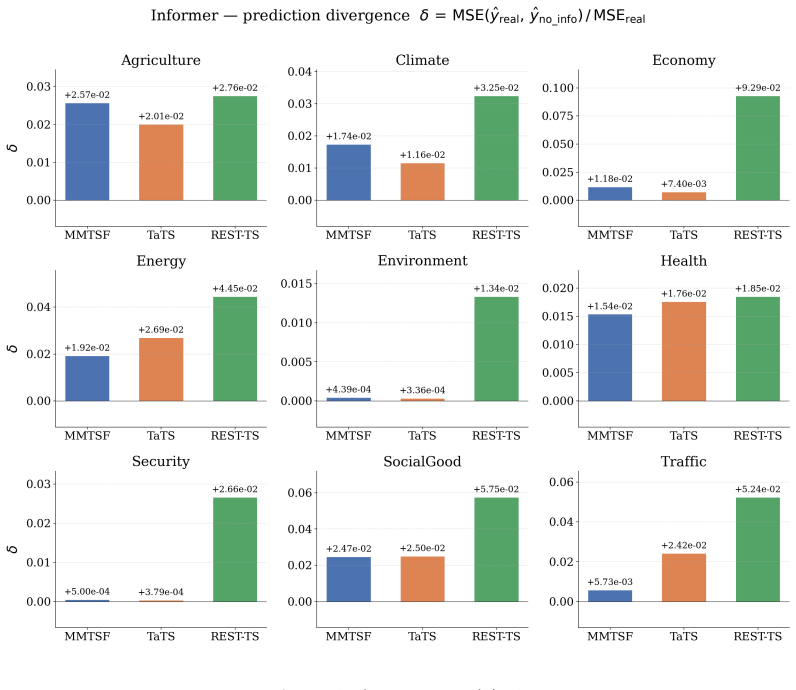
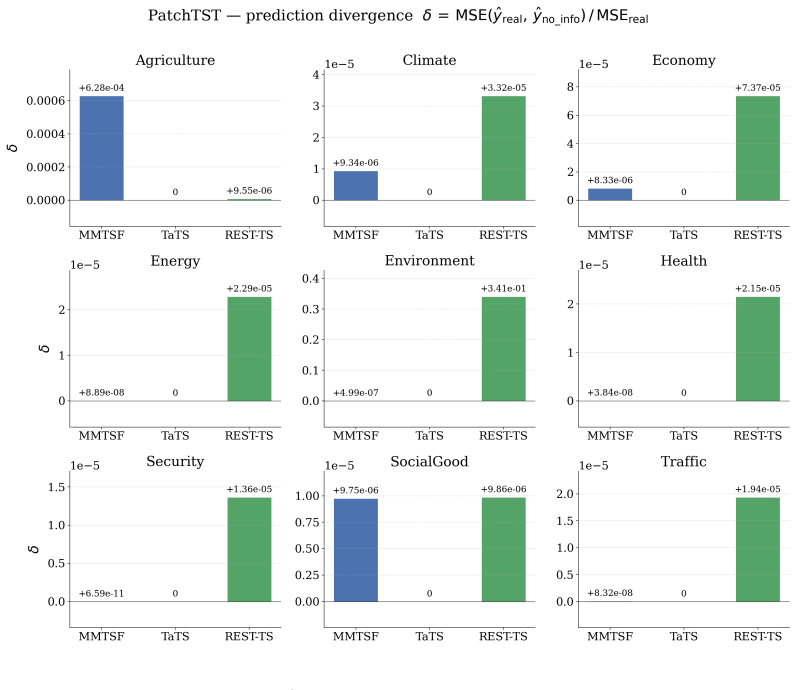
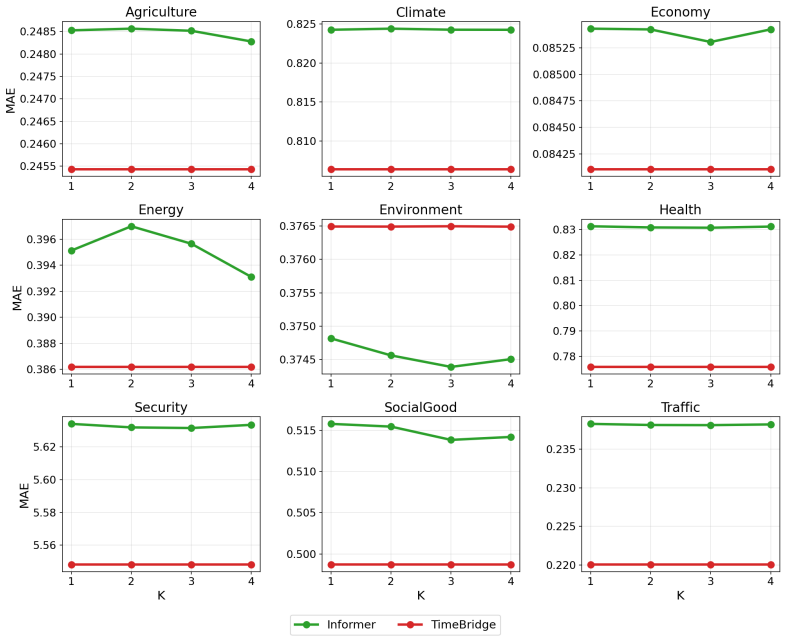
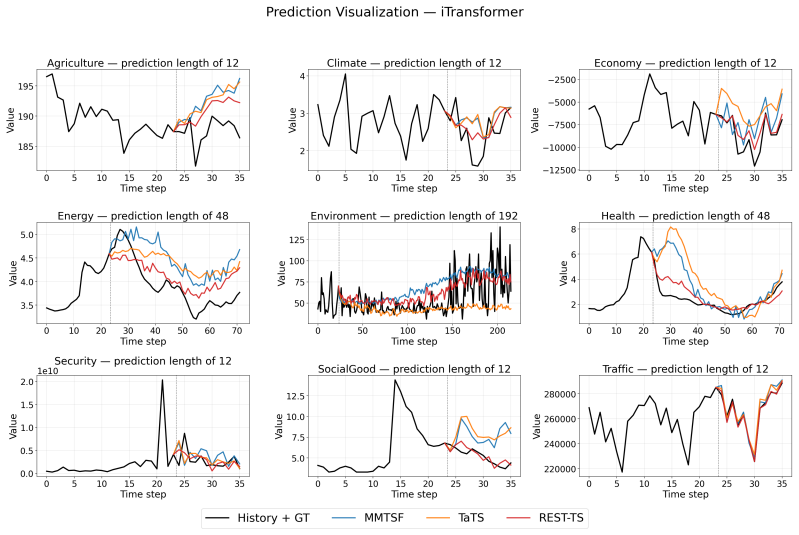
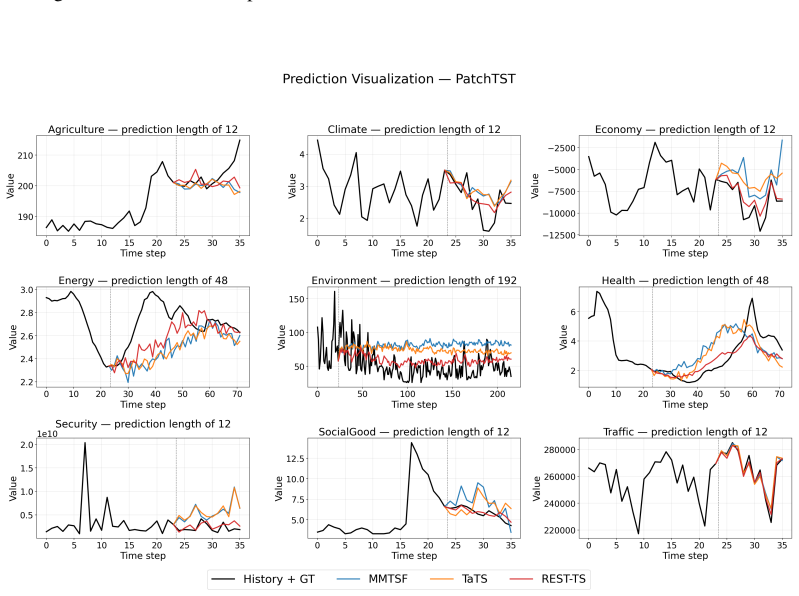
Existing multimodal time series forecasting frameworks exhibit text collapse, in which the text branch converges to a content-independent transformation and contributes negligible signal. REST-TS resolves the underlying asymmetry by letting the numerical backbone produce its own independent forecast while exclusively supervising the text branch to predict the structured components of the residual, the prediction gap that numerical inputs cannot reduce.
What carries the argument
REST-TS (Residual-Exclusive Supervision for Text in Time Series), which decouples numerical forecasting from residual prediction and assigns the text branch only to the latter.
If this is right
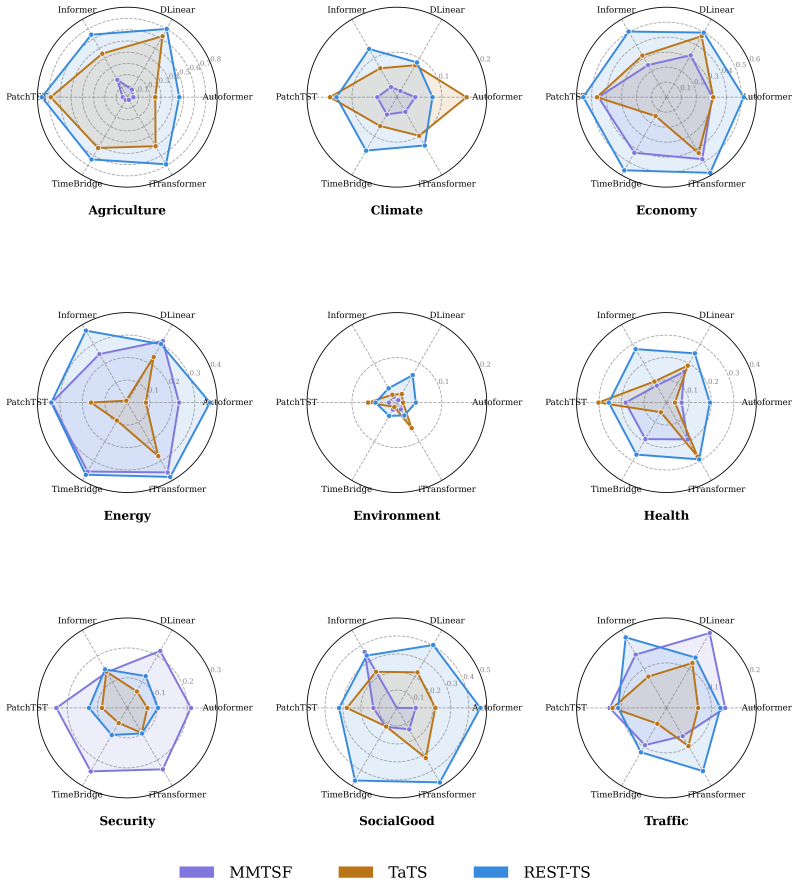
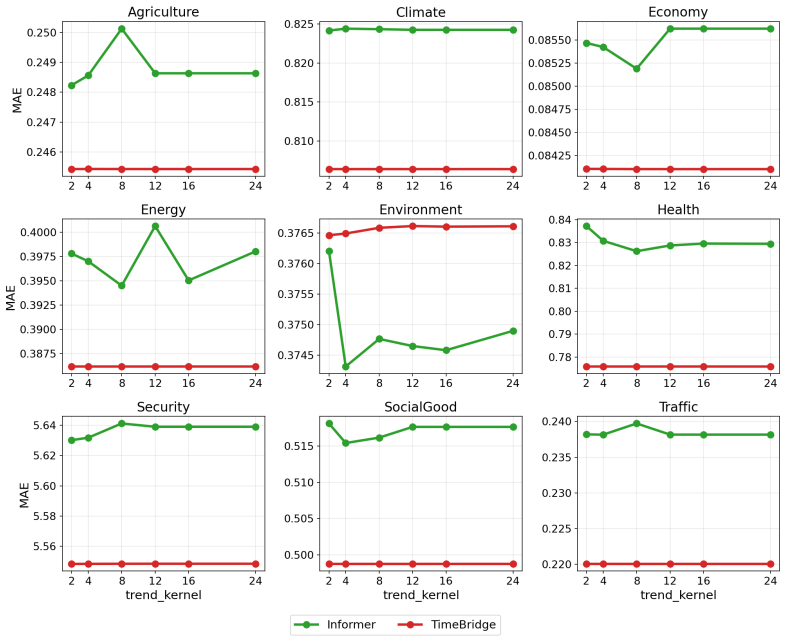
- REST-TS achieves state-of-the-art performance across diverse real-world domains and backbone architectures.
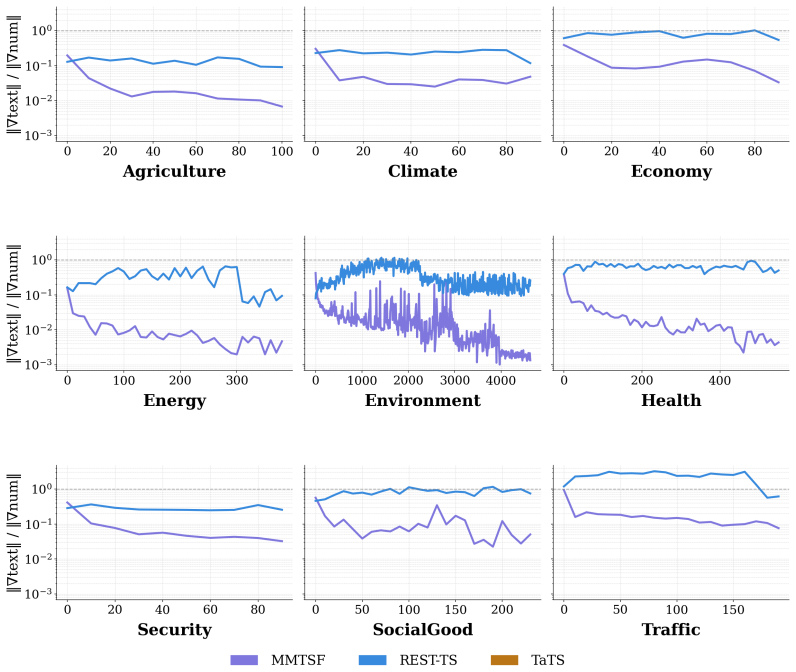
- Text branches demonstrate measurably greater utilization of input descriptions than in prior frameworks.
- Supervision on residuals prevents the text branch from relying on numerical pathways.
- The design principle applies consistently when swapping numerical backbones or forecasting tasks.
Where Pith is reading between the lines
- The same residual-exclusive principle could be tested in other multimodal settings such as vision-augmented forecasting to check whether modality collapse is likewise asymmetry-driven.
- Applying REST-TS at longer horizons might show whether text contributes more when numerical autocorrelation weakens.
- One could measure whether the learned residual components align with the semantic elements explicitly mentioned in the text reports.
- Synthetic experiments that inject known predictive text signals would directly test whether residual supervision recovers them.
Load-bearing premise
No numerical pathway can reduce the residual losses, so the text branch must extract genuine content from the input description.
What would settle it
A controlled run of REST-TS in which the text branch outputs remain statistically independent of the input text content, or where end-to-end performance fails to exceed a numerical-only baseline.
Figures
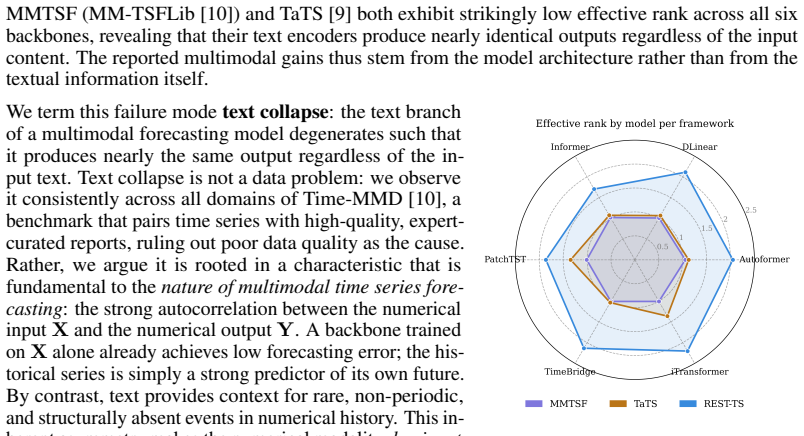

read the original abstract
Multimodal time series forecasting, which pairs numerical sequences with domain-relevant textual reports, promises to inject world knowledge into forecasting pipelines. However, we uncover a critical failure mode in existing frameworks that we term text collapse: the text branch converges to a content-independent transformation, contributing negligible discriminative signal regardless of the input description. We argue that text collapse is a consequence of a fundamental asymmetry in time series forecasting: the numerical input is strongly autocorrelated with the output, making the numerical backbone inherently dominant, while the text branch, despite carrying complementary and often critical information, is insufficiently utilized, leading to its systematic underexploitation. To address this, we propose \textbf{REST-TS} (\textbf{R}esidual-\textbf{E}xclusive \textbf{S}upervision for \textbf{T}ext in \textbf{T}ime \textbf{S}eries), which turns the asymmetry into a design principle: the numerical backbone produces its own independent numerical forecast, and the text branch is exclusively supervised to predict the structured components of the residual, the prediction gap that numbers cannot explain. Because no numerical pathway can reduce these losses, the text branch must extract genuine content from the input description. Evaluated across diverse real-world domains and backbone architectures, REST-TS achieves state-of-the-art performance and consistently demonstrates greater text-branch utilization than existing frameworks, providing strong empirical evidence that supervising the text branch on the residual compels it to extract genuine content from the input.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that multimodal time series forecasting suffers from 'text collapse,' where the text branch converges to a content-independent transformation due to the dominance of autocorrelated numerical inputs. It proposes REST-TS, which uses residual-exclusive supervision: the numerical backbone makes an independent forecast, and the text branch is supervised only on the residual components that numbers cannot explain, forcing it to extract genuine content from text. Experiments across domains and backbones show SOTA performance and greater text utilization.
Significance. If the results hold, this work identifies a previously unrecognized failure mode in multimodal forecasting and offers a design principle to resolve it by leveraging the inherent asymmetry. The cross-domain and cross-backbone evaluation, along with demonstrations of improved text-branch utilization, provides empirical support. Strengths include the focus on a falsifiable prediction about text utilization.
major comments (1)
- [Abstract (REST-TS design principle)] Abstract (paragraph describing REST-TS design principle): The claim that 'Because no numerical pathway can reduce these losses, the text branch must extract genuine content from the input description' is load-bearing for the central contribution but rests on an assumption of complete independence between branches. If the architecture permits any information flow (concatenated features, cross-attention, shared layers, or joint optimization), gradients from the combined output could allow the text branch to collapse while the numerical backbone absorbs adjustments. The manuscript must provide explicit equations or a diagram (likely in §3) confirming no such pathway exists during training.
minor comments (2)
- [§3] The term 'structured components of the residual' is used without a precise definition or equation; add a formal decomposition (e.g., in §3.2) to clarify what the text branch is supervised to predict.
- [Experiments section] Ensure all tables reporting SOTA results include statistical significance tests and full baseline details for reproducibility.
Simulated Author's Rebuttal
We thank the referee for highlighting the need to rigorously substantiate the independence assumption underlying the REST-TS design principle. The concern is well-taken, and we will strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract (REST-TS design principle)] Abstract (paragraph describing REST-TS design principle): The claim that 'Because no numerical pathway can reduce these losses, the text branch must extract genuine content from the input description' is load-bearing for the central contribution but rests on an assumption of complete independence between branches. If the architecture permits any information flow (concatenated features, cross-attention, shared layers, or joint optimization), gradients from the combined output could allow the text branch to collapse while the numerical backbone absorbs adjustments. The manuscript must provide explicit equations or a diagram (likely in §3) confirming no such pathway exists during training.
Authors: We agree that the independence claim is central and requires explicit architectural clarification. In REST-TS, the numerical backbone is trained to convergence on its own forecast loss using only the numerical input; the text branch receives gradients exclusively from a separate residual loss computed on the prediction gap after the numerical forecast is fixed. No shared layers, cross-attention, or feature concatenation occurs between the branches during this residual-supervision stage, and the numerical backbone parameters are not updated by the residual loss. To make this fully transparent, we will add (i) a detailed diagram in §3 illustrating the two-stage training flow with separate loss paths and (ii) the corresponding equations showing the numerical loss L_num and the residual loss L_res with their respective gradient flows. This revision will directly address the possibility of indirect information leakage. revision: yes
Circularity Check
No significant circularity; REST-TS is an explicit design objective motivated by observed asymmetry
full rationale
The paper identifies text collapse empirically, attributes it to numerical dominance in autocorrelated series, and defines REST-TS as residual-exclusive supervision on the text branch. The statement that this forces genuine content extraction follows directly from the supervision choice by construction and is presented as the intended mechanism, not as a first-principles prediction or fitted result that reduces to the inputs. No self-citations, uniqueness theorems, ansatzes smuggled via prior work, or renamings of known patterns appear in the abstract or described derivation. The central claim remains an implemented training principle evaluated on external data rather than a self-referential reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Numerical input is strongly autocorrelated with the output in time series forecasting tasks.
invented entities (2)
-
text collapse
no independent evidence
-
REST-TS
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Exploring simple siamese representation learning
Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15750–15758, June 2021
2021
-
[2]
Zihan Dong, Xinyu Fan, and Zhiyuan Peng. Fnspid: A comprehensive financial news dataset in time series. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD ’24, page 4918–4927, New York, NY , USA, 2024. Association for Computing Machinery. ISBN 9798400704901. doi: 10.1145/3637528.3671629. URL https: //doi.org/10.114...
-
[3]
Pmr: Prototypical modal rebalance for multimodal learning
Yunfeng Fan, Wenchao Xu, Haozhao Wang, Junxiao Wang, and Song Guo. Pmr: Prototypical modal rebalance for multimodal learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 20029–20038, June 2023
2023
-
[4]
Classifier-guided gradient modulation for enhanced multimodal learning
Zirun Guo, Tao Jin, Jingyuan Chen, and Zhou Zhao. Classifier-guided gradient modulation for enhanced multimodal learning. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URLhttps://openreview.net/forum?id=oe5ZEqTOaz
2024
-
[5]
Modality competition: What makes joint training of multi-modal network fail in deep learning? (Provably)
Yu Huang, Junyang Lin, Chang Zhou, Hongxia Yang, and Longbo Huang. Modality competition: What makes joint training of multi-modal network fail in deep learning? (Provably). In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato, editors,Proceedings of the 39th International Conference on Machine Learning, volume 162...
2022
-
[6]
Multi-modal time series analysis: A tutorial and survey
Yushan Jiang, Kanghui Ning, Zijie Pan, Xuyang Shen, Jingchao Ni, Wenchao Yu, Anderson Schneider, Haifeng Chen, Yuriy Nevmyvaka, and Dongjin Song. Multi-modal time series analysis: A tutorial and survey. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V .2, KDD ’25, page 6043–6053, New York, NY , USA,
-
[7]
Association for Computing Machinery. ISBN 9798400714542. doi: 10.1145/3711896. 3736567. URLhttps://doi.org/10.1145/3711896.3736567
-
[8]
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InInterna- tional Conference on Learning Representations (ICLR), 2015. URL https://arxiv.org/ abs/1412.6980
Pith/arXiv arXiv 2015
-
[9]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors,Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 3519–3529. PMLR, 09–15 Jun 2019. URL https://...
2019
-
[10]
Language in the flow of time: Time- series-paired texts weaved into a unified temporal narrative
Zihao Li, Xiao Lin, Zhining Liu, Jiaru Zou, Ziwei Wu, Lecheng Zheng, Dongqi Fu, Yada Zhu, Hendrik Hamann, Hanghang Tong, and Jingrui He. Language in the flow of time: Time- series-paired texts weaved into a unified temporal narrative. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum? id=a1zBg9cBvt
2026
-
[11]
Sasanur, Megha Sharma, Jiaming Cui, Qingsong Wen, Chao Zhang, and B
Haoxin Liu, Shangqing Xu, Zhiyuan Zhao, Lingkai Kong, Harshavardhan Kamarthi, Aditya B. Sasanur, Megha Sharma, Jiaming Cui, Qingsong Wen, Chao Zhang, and B. Aditya Prakash. Time-MMD: Multi-domain multimodal dataset for time series analysis. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024. URLhttps...
2024
-
[12]
Time- bridge: Non-stationarity matters for long-term time series forecasting.International Conference on Machine Learning, 2025
Peiyuan Liu, Beiliang Wu, Yifan Hu, Naiqi Li, Tao Dai, Jigang Bao, and Shu-Tao Xia. Time- bridge: Non-stationarity matters for long-term time series forecasting.International Conference on Machine Learning, 2025
2025
-
[13]
itransformer: Inverted transformers are effective for time series forecasting
Yong Liu, Tengge Hu, Haoran Zhang, Haixu Wu, Shiyu Wang, Lintao Ma, and Mingsheng Long. itransformer: Inverted transformers are effective for time series forecasting. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview. net/forum?id=JePfAI8fah. 10
2024
-
[14]
Are multimodal transformers robust to missing modality? InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18177–18186, June 2022
Mengmeng Ma, Jian Ren, Long Zhao, Davide Testuggine, and Xi Peng. Are multimodal transformers robust to missing modality? InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18177–18186, June 2022
2022
-
[15]
Spectral text fusion: A frequency-aware approach to multimodal time-series forecasting
Huu Hiep Nguyen, Minh Hoang Nguyen, Dung Nguyen, and Hung Le. Spectral text fusion: A frequency-aware approach to multimodal time-series forecasting. InThe 29th International Conference on Artificial Intelligence and Statistics, 2026. URL https://openreview.net/ forum?id=w4yjJc06zt
2026
-
[16]
A time series is worth 64 words: Long-term forecasting with transformers
Yuqi Nie, Nam H Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. A time series is worth 64 words: Long-term forecasting with transformers. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum? id=Jbdc0vTOcol
2023
-
[17]
Balanced multimodal learning via on-the-fly gradient modulation
Xiaokang Peng, Yake Wei, Andong Deng, Dong Wang, and Di Hu. Balanced multimodal learning via on-the-fly gradient modulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
2022
-
[18]
Language models are unsupervised multitask learners
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. 2019
2019
-
[19]
The effective rank: A measure of effective dimensionality
Olivier Roy and Martin Vetterli. The effective rank: A measure of effective dimensionality. In 2007 15th European Signal Processing Conference, pages 606–610, 2007
2007
-
[20]
Timemixer: Decomposable multiscale mixing for time series forecasting
Shiyu Wang, Haixu Wu, Xiaoming Shi, Tengge Hu, Huakun Luo, Lintao Ma, James Y Zhang, and JUN ZHOU. Timemixer: Decomposable multiscale mixing for time series forecasting. In International Conference on Learning Representations (ICLR), 2024
2024
-
[21]
Tailornet: Predict- ing clothing in 3d as a function of human pose, shape and garment style
Weiyao Wang, Du Tran, and Matt Feiszli. What makes training multi-modal classification networks hard? In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12692–12702, 2020. doi: 10.1109/CVPR42600.2020.01271
-
[22]
From news to forecast: Integrating event analysis in LLM-based time series forecasting with reflection
Xinlei Wang, Maike Feng, Jing Qiu, Jinjin Gu, and Junhua Zhao. From news to forecast: Integrating event analysis in LLM-based time series forecasting with reflection. InThe Thirty- eighth Annual Conference on Neural Information Processing Systems, 2024. URL https: //openreview.net/forum?id=tj8nsfxi5r
2024
-
[23]
Mmpareto: boosting multimodal learning with innocent unimodal assistance
Yake Wei and Di Hu. Mmpareto: boosting multimodal learning with innocent unimodal assistance. InInternational Conference on Machine Learning, 2024
2024
-
[24]
Autoformer: Decomposition transformers with Auto-Correlation for long-term series forecasting
Haixu Wu, Jiehui Xu, Jianmin Wang, and Mingsheng Long. Autoformer: Decomposition transformers with Auto-Correlation for long-term series forecasting. InAdvances in Neural Information Processing Systems, 2021
2021
-
[25]
Ailing Zeng, Muxi Chen, Lei Zhang, and Qiang Xu. Are transformers effective for time series forecasting?Proceedings of the AAAI Conference on Artificial Intelligence, 37(9):11121–11128, Jun. 2023. doi: 10.1609/aaai.v37i9.26317
-
[26]
Multimodal representation learning by alternating unimodal adaptation
Xiaohui Zhang, Jaehong Yoon, Mohit Bansal, and Huaxiu Yao. Multimodal representation learning by alternating unimodal adaptation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 27456–27466, June 2024
2024
-
[27]
Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting
Yunhao Zhang and Junchi Yan. Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting. InThe Eleventh International Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=vSVLM2j9eie
2023
-
[28]
Informer: Beyond efficient transformer for long sequence time-series forecasting
Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. Informer: Beyond efficient transformer for long sequence time-series forecasting. In The Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Virtual Conference, volume 35, pages 11106–11115. AAAI Press, 2021
2021
-
[29]
FEDformer: Frequency enhanced decomposed transformer for long-term series forecasting
Tian Zhou, Ziqing Ma, Qingsong Wen, Xue Wang, Liang Sun, and Rong Jin. FEDformer: Frequency enhanced decomposed transformer for long-term series forecasting. InProc. 39th International Conference on Machine Learning (ICML 2022), 2022. 11 Appendix for Does Text Actually Help? Uncovering and Resolving Text Collapse in Multimodal Time Series Forecasting A Im...
arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.