When Does Online Imitation Learning Help in LLM Post-Training? The Role of (Non-)Realizability Beyond Horizon
Pith reviewed 2026-06-30 07:38 UTC · model grok-4.3
The pith
Offline imitation learning encounters an information-theoretic bottleneck in non-realizable settings even for H=1, while online IL achieves high performance under reward-relative misspecification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under realizability, offline IL matches expert performance. In non-realizable settings, offline IL encounters an information-theoretic bottleneck even when horizon H=1, and online IL provably achieves high performance despite a large distributional mismatch between the expert and student policies under a structural characterization of misspecification relative to the reward.
What carries the argument
Structural characterization of misspecification relative to the reward, which separates cases where online interaction overcomes the offline information limit from those where it does not.
If this is right
- Offline IL suffices to match expert performance whenever the student policy class can realize the expert.
- The information-theoretic lower bound on offline IL holds independently of horizon length in non-realizable cases.
- Online IL recovers high performance in misspecified settings by collecting on-policy data even when expert and student distributions differ substantially.
Where Pith is reading between the lines
- For LLM tasks known to have limited policy expressivity, resources may be better spent on online data collection than on enlarging offline datasets.
- The result separates the value of online interaction from horizon length, suggesting short-sequence tasks can still benefit from online methods if misspecified.
- Practical application requires identifying whether a given fine-tuning task satisfies the reward-relative misspecification structure.
Load-bearing premise
The structural characterization of misspecification relative to the reward accurately models the non-realizability encountered in the LLM post-training tasks and policy classes considered.
What would settle it
A simple H=1 task in which the policy class is misspecified according to the structural characterization yet offline IL still matches expert performance, or in which online IL fails to achieve high performance.
Figures

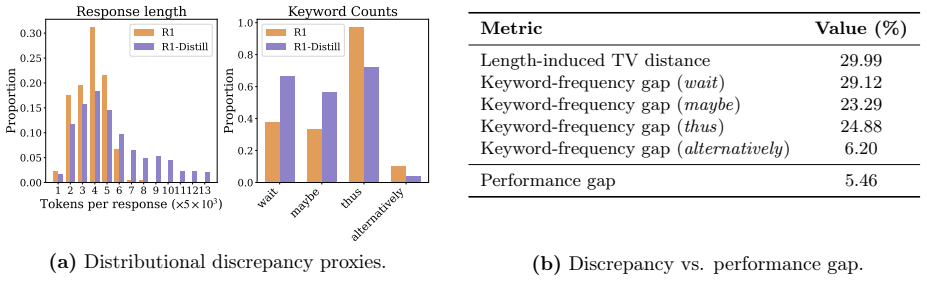
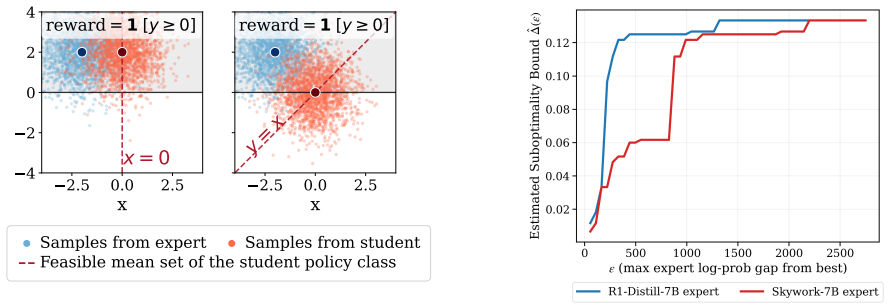


read the original abstract
Online imitation learning (IL), particularly on-policy distillation, has emerged as a strong LLM post-training approach, often outperforming offline supervised fine-tuning (SFT). Yet a principled understanding of when and why online interaction helps remains unclear. In this work, we challenge the view that error accumulation is the main source of online IL's advantage, and instead show that the benefits of online interaction depend critically on whether the setting is realizable, i.e., whether the student policy class can represent the expert policy. Under realizability, we empirically find that offline IL already matches expert performance. In contrast, in non-realizable (misspecified) settings, we prove that offline IL encounters an information-theoretic bottleneck even when horizon $H=1$, and propose a structural characterization of misspecification relative to the reward, under which online IL provably achieves high performance despite a large distributional mismatch between the expert and student policies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that online imitation learning's advantage over offline SFT in LLM post-training stems from non-realizability of the student policy class (rather than horizon-induced error accumulation). Under realizability, offline IL matches expert performance empirically. In non-realizable settings, offline IL faces an information-theoretic bottleneck even at H=1; under a proposed structural characterization of misspecification relative to the reward, online IL achieves high performance despite large expert-student policy mismatch.
Significance. If the structural characterization of misspecification is the relevant one for LLM policy classes and rewards, the result supplies a principled account of when online interaction helps, shifting emphasis from horizon length to realizability and offering guidance for post-training design.
major comments (2)
- [Section introducing the structural characterization (and associated theorems)] The information-theoretic lower bound for offline IL (even at H=1) and the online-IL guarantee both rest on the proposed structural characterization of misspecification w.r.t. the reward; the manuscript does not supply evidence that this form (as opposed to token-level mismatch or optimization-induced misspecification) is the operative one in the LLM tasks considered.
- [Empirical evaluation section] The realizability experiments claim offline IL already matches expert performance, but the policy class, reward structure, and data-exclusion rules used to enforce realizability are not stated with sufficient precision to confirm that the empirical regime matches the theoretical assumptions.
minor comments (2)
- [Notation and preliminaries] Notation for the structural misspecification parameters should be introduced once and used consistently across theorems and experiments.
- [Abstract] The abstract paragraph on non-realizable settings could explicitly name the reward-relative characterization so readers immediately see the scope of the claimed online-IL advantage.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope of our contributions on realizability in online vs. offline IL for LLM post-training. We address each major comment below with targeted revisions where appropriate.
read point-by-point responses
-
Referee: [Section introducing the structural characterization (and associated theorems)] The information-theoretic lower bound for offline IL (even at H=1) and the online-IL guarantee both rest on the proposed structural characterization of misspecification w.r.t. the reward; the manuscript does not supply evidence that this form (as opposed to token-level mismatch or optimization-induced misspecification) is the operative one in the LLM tasks considered.
Authors: We acknowledge that the manuscript introduces the reward-relative structural characterization primarily as a sufficient condition enabling the information-theoretic lower bound for offline IL (even at H=1) and the corresponding online IL guarantee, without direct empirical evidence that this specific form dominates over token-level or optimization-induced misspecification in the LLM tasks studied. The characterization is derived directly from the reward structure in post-training, where misspecification is defined relative to the expert's optimal policy under the reward rather than per-token. In the revision we will add a dedicated discussion subsection with concrete examples from common LLM reward models (e.g., how preference-based rewards induce reward-relative rather than token-level mismatch) and explicitly note that we do not claim exclusivity but that the condition supplies a principled account when it applies. This addresses the concern without altering the theorems. revision: partial
-
Referee: [Empirical evaluation section] The realizability experiments claim offline IL already matches expert performance, but the policy class, reward structure, and data-exclusion rules used to enforce realizability are not stated with sufficient precision to confirm that the empirical regime matches the theoretical assumptions.
Authors: We agree that the empirical section requires greater precision to confirm alignment with the theoretical realizability assumptions. In the revised manuscript we will explicitly state: (i) the policy class parameterization (model architecture, size, and fine-tuning procedure), (ii) the reward structure or simulation method defining the expert policy, and (iii) the exact data-exclusion rules used to enforce that the expert lies within the student class. These additions will allow direct verification that the experiments operate under the realizable regime assumed in the theory. revision: yes
Circularity Check
No circularity: results rest on stated proofs and proposed characterization
full rationale
The paper derives its claims via an empirical observation that offline IL matches expert performance under realizability, an information-theoretic lower bound proof for offline IL even at H=1 in non-realizable settings, and a proposed structural characterization of misspecification relative to the reward under which online IL is shown to succeed. These steps are presented as independent theoretical derivations and do not reduce by construction to fitted inputs, self-definitions, or self-citation chains. The analysis is self-contained against its own proofs and observations.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions in imitation learning theory such as bounded rewards and Markov decision process properties.
Reference graph
Works this paper leans on
-
[1]
and Ng, A
Abbeel, P. and Ng, A. Y. Apprenticeship learning via inverse reinforcement learning. InProceedings of the twenty-first international conference on Machine learning, pp. 1, 2004
2004
-
[2]
R., Geist, M., and Bachem, O
Agarwal, R., Vieillard, N., Zhou, Y., Stanczyk, P., Garea, S. R., Geist, M., and Bachem, O. On-policy distillation of language models: Learning from self-generated mistakes. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[3]
D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[4]
Mitigating covariate shift in imitation learning via offline data with partial coverage.Advances in Neural Information Processing Systems, 34: 965–979, 2021
Chang, J., Uehara, M., Sreenivas, D., Kidambi, R., and Sun, W. Mitigating covariate shift in imitation learning via offline data with partial coverage.Advances in Neural Information Processing Systems, 34: 965–979, 2021
2021
-
[5]
Retaining by Doing: The Role of On-Policy Data in Mitigating Forgetting
Chen, H., Razin, N., Narasimhan, K., and Chen, D. Retaining by doing: The role of on-policy data in mitigating forgetting.arXiv preprint arXiv:2510.18874, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
and Jiang, N
Chen, J. and Jiang, N. Information-theoretic considerations in batch reinforcement learning. In International conference on machine learning, pp. 1042–1051. PMLR, 2019
2019
-
[7]
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
Chu, T., Zhai, Y., Yang, J., Tong, S., Xie, S., Schuurmans, D., Le, Q. V., Levine, S., and Ma, Y. Sft memorizes, rl generalizes: A comparative study of foundation model post-training.arXiv preprint arXiv:2501.17161, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., and Schulman, J. Training verifiers to solve math word problems.arXiv preprint arXiv: 2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025. URLhttps://arxiv.org/abs/2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Efficient imitation under misspecification
Espinosa-Dice, N., Choudhury, S., Sun, W., and Swamy, G. Efficient imitation under misspecification. arXiv preprint arXiv:2503.13162, 2025
-
[11]
Open r1: A fully open reproduction of deepseek-r1, 2025
Face, H. Open r1: A fully open reproduction of deepseek-r1, 2025
2025
-
[12]
and Rakhlin, A
Foster, D. and Rakhlin, A. Beyond ucb: Optimal and efficient contextual bandits with regression oracles. InInternational conference on machine learning, pp. 3199–3210. PMLR, 2020. 13
2020
-
[13]
Practical contextual bandits with regression oracles
Foster, D., Agarwal, A., Dudík, M., Luo, H., and Schapire, R. Practical contextual bandits with regression oracles. InInternational Conference on Machine Learning, pp. 1539–1548. PMLR, 2018
2018
- [14]
-
[15]
J., Block, A., and Misra, D
Foster, D. J., Block, A., and Misra, D. Is behavior cloning all you need? understanding horizon in imitation learning.Advances in Neural Information Processing Systems, 37:120602–120666, 2024
2024
-
[16]
J., Mhammedi, Z., and Rohatgi, D
Foster, D. J., Mhammedi, Z., and Rohatgi, D. Is a good foundation necessary for efficient reinforcement learning? the computational role of the base model in exploration.arXiv preprint arXiv:2503.07453, 2025
-
[17]
Importance-weighted offline learning done right
Gabbianelli, G., Neu, G., and Papini, M. Importance-weighted offline learning done right. InInternational Conference on Algorithmic Learning Theory, pp. 614–634. PMLR, 2024
2024
-
[18]
Gandhi, K., Chakravarthy, A., Singh, A., Lile, N., and Goodman, N. D. Cognitive behaviors that enable self-improving reasoners, or, four habits of highly effective stars.arXiv preprint arXiv:2503.01307, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Minillm: Knowledge distillation of large language models
Gu, Y., Dong, L., Wei, F., and Huang, M. Minillm: Knowledge distillation of large language models. In The Twelfth International Conference on Learning Representations, 2024
2024
-
[21]
The false promise of imitating proprietary language models
Gudibande, A., Wallace, E., Snell, C., Geng, X., Liu, H., Abbeel, P., Levine, S., and Song, D. The false promise of imitating proprietary language models. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openreview.net/forum?id=Kz3yckpCN5
2024
-
[22]
Skywork Open Reasoner 1 Technical Report
He, J., Liu, J., Liu, C. Y., Yan, R., Wang, C., Cheng, P., Zhang, X., Zhang, F., Xu, J., Shen, W., et al. Skywork open reasoner 1 technical report.arXiv preprint arXiv:2505.22312, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations (ICLR), 2021
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations (ICLR), 2021
2021
-
[24]
Measuring Mathematical Problem Solving With the MATH Dataset
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[25]
J., Rohatgi, D., Zhang, C., Simchowitz, M., Ash, J
Huang, A., Block, A., Foster, D. J., Rohatgi, D., Zhang, C., Simchowitz, M., Ash, J. T., and Krish- namurthy, A. Self-improvement in language models: The sharpening mechanism. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[26]
D., Sun, W., Krishnamurthy, A., and Foster, D
Huang, A., Zhan, W., Xie, T., Lee, J. D., Sun, W., Krishnamurthy, A., and Foster, D. J. Correcting the mythos of kl-regularization: Direct alignment without overoptimization via chi-squared preference optimization. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[27]
Teach small models to reason by curriculum distillation
Jiang, W., Lu, Y., Lin, H., Han, X., and Sun, L. Teach small models to reason by curriculum distillation. In Christodoulopoulos, C., Chakraborty, T., Rose, C., and Peng, V. (eds.),Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 7412–7422, Suzhou, China, November 2025. Association for Computational Linguistics. I...
-
[28]
Kim, J., Yun, J., Lee, J. D., and Jun, K.-S. Coverage improvement and fast convergence of on-policy preference learning.arXiv preprint arXiv:2601.08421, 2026
-
[29]
and Rush, A
Kim, Y. and Rush, A. M. Sequence-level knowledge distillation. InProceedings of the 2016 conference on empirical methods in natural language processing, pp. 1317–1327, 2016. 14
2016
-
[30]
M., Ma, T., and Liang, P
Kumar, A., Raghunathan, A., Jones, R. M., Ma, T., and Liang, P. Fine-tuning can distort pretrained features and underperform out-of-distribution. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022. URLhttps: //openreview.net/forum?id=UYneFzXSJWh
2022
-
[31]
H., Gonzalez, J
Kwon, W., Li, Z., Zhuang, S., Sheng, Y., Zheng, L., Yu, C. H., Gonzalez, J. E., Zhang, H., and Stoica, I. Efficient memory management for large language model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[32]
Y., Ramasubramanian, B., and Poovendran, R
Li, Y., Yue, X., Xu, Z., Jiang, F., Niu, L., Lin, B. Y., Ramasubramanian, B., and Poovendran, R. Small models struggle to learn from strong reasoners.arXiv preprint arXiv:2502.12143, 2025
-
[33]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Li, Y., Zuo, Y., He, B., Zhang, J., Xiao, C., Qian, C., Yu, T., Gao, H.-a., Yang, W., Liu, Z., et al. Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe. arXiv preprint arXiv:2604.13016, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Lu, K. and Lab, T. M. On-policy distillation.Thinking Machines Lab: Connectionism, 2025. doi: 10.64434/tml.20251026. https://thinkingmachines.ai/blog/on-policy-distillation
-
[36]
Y., Roongta, M., Cai, C., Luo, J., Zhang, T., Li, L
Luo, M., Tan, S., Wong, J., Shi, X., Tang, W. Y., Roongta, M., Cai, C., Luo, J., Zhang, T., Li, L. E., et al. Deepscaler: Surpassing o1-preview with a 1.5 b model by scaling rl.Notion Blog, 2025
2025
-
[37]
Error bounds for approximate policy iteration
Munos, R. Error bounds for approximate policy iteration. InProceedings of the Twentieth International Conference on International Conference on Machine Learning, pp. 560–567, 2003
2003
-
[38]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[39]
Tinyzero
Pan, J., Zhang, J., Wang, X., Yuan, L., Peng, H., and Suhr, A. Tinyzero. https://github.com/Jiayi- Pan/TinyZero, 2025. Accessed: 2025-01-24
2025
-
[40]
W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pp. 8748–8763. PmLR, 2021
2021
-
[41]
D., Ermon, S., and Finn, C
Rafailov, R., Sharma, A., Mitchell, E., Manning, C. D., Ermon, S., and Finn, C. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[42]
Toward the fundamental limits of imitation learning.Advances in Neural Information Processing Systems, 33:2914–2924, 2020
Rajaraman, N., Yang, L., Jiao, J., and Ramchandran, K. Toward the fundamental limits of imitation learning.Advances in Neural Information Processing Systems, 33:2914–2924, 2020
2020
-
[43]
On the value of interaction and function approximation in imitation learning
Rajaraman, N., Han, Y., Yang, L., Liu, J., Jiao, J., and Ramchandran, K. On the value of interaction and function approximation in imitation learning. In Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., and Vaughan, J. W. (eds.),Advances in Neural Information Processing Systems, volume 34, pp. 1325–1336. Curran Associates, Inc., 2021. URLhttps://proc...
2021
-
[44]
Bridging offline reinforcement learning and imitation learning: A tale of pessimism.Advances in Neural Information Processing Systems, 34: 11702–11716, 2021
Rashidinejad, P., Zhu, B., Ma, C., Jiao, J., and Russell, S. Bridging offline reinforcement learning and imitation learning: A tale of pessimism.Advances in Neural Information Processing Systems, 34: 11702–11716, 2021
2021
- [45]
-
[46]
and Bagnell, D
Ross, S. and Bagnell, D. Efficient reductions for imitation learning. InProceedings of the thirteenth international conference on artificial intelligence and statistics, pp. 661–668. JMLR Workshop and Conference Proceedings, 2010
2010
-
[47]
Reinforcement and Imitation Learning via Interactive No-Regret Learning
Ross, S. and Bagnell, J. A. Reinforcement and imitation learning via interactive no-regret learning. arXiv preprint arXiv:1406.5979, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[48]
A reduction of imitation learning and structured prediction to no-regret online learning
Ross, S., Gordon, G., and Bagnell, D. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the fourteenth international conference on artificial intelligence and statistics, pp. 627–635. JMLR Workshop and Conference Proceedings, 2011
2011
-
[49]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y. K., Wu, Y., and Guo, D. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv: 2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
RL's Razor: Why Online Reinforcement Learning Forgets Less
Shenfeld, I., Pari, J., and Agrawal, P. Rl’s razor: Why online reinforcement learning forgets less.arXiv preprint arXiv:2509.04259, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
HybridFlow: A Flexible and Efficient RLHF Framework
Sheng, G., Zhang, C., Ye, Z., Wu, X., Zhang, W., Zhang, R., Peng, Y., Lin, H., and Wu, C. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
and Xu, Y
Simchi-Levi, D. and Xu, Y. Bypassing the monster: A faster and simpler optimal algorithm for contextual bandits under realizability.Mathematics of Operations Research, 47(3):1904–1931, 2022
1904
- [53]
-
[54]
and Joachims, T
Swaminathan, A. and Joachims, T. The self-normalized estimator for counterfactual learning.advances in neural information processing systems, 28, 2015
2015
-
[55]
A., Wu, S., Jiao, J., and Ramchandran, K
Swamy, G., Rajaraman, N., Peng, M., Choudhury, S., Bagnell, J. A., Wu, S., Jiao, J., and Ramchandran, K. Minimax optimal online imitation learning via replay estimation. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A. (eds.),Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing ...
2022
-
[56]
and Schapire, R
Syed, U. and Schapire, R. E. A game-theoretic approach to apprenticeship learning.Advances in neural information processing systems, 20, 2007
2007
-
[57]
Team, Q. Qwen2. 5: A party of foundation models, september 2024.URL https://qwenlm. github. io/blog/qwen2, 5(4), 2024
2024
-
[58]
TRL: Transformers Reinforcement Learning, 2020
von Werra, L., Belkada, Y., Tunstall, L., Beeching, E., Thrush, T., Lambert, N., Huang, S., Rasul, K., and Gallouédec, Q. TRL: Transformers Reinforcement Learning, 2020. URLhttps://github.com/ huggingface/trl
2020
-
[59]
Oracle-efficient pessimism: Offline policy optimization in contextual bandits
Wang, L., Krishnamurthy, A., and Slivkins, A. Oracle-efficient pessimism: Offline policy optimization in contextual bandits. InInternational Conference on Artificial Intelligence and Statistics, pp. 766–774. PMLR, 2024
2024
-
[60]
MiMo-V2-Flash Technical Report
Xiao, B., Xia, B., Yang, B., Gao, B., Shen, B., Zhang, C., He, C., Lou, C., Luo, F., Wang, G., et al. Mimo-v2-flash technical report.arXiv preprint arXiv:2601.02780, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[61]
J., Krishnamurthy, A., Rosset, C., Awadallah, A
Xie, T., Foster, D. J., Krishnamurthy, A., Rosset, C., Awadallah, A. H., and Rakhlin, A. Exploratory preference optimization: Harnessing implicit q*-approximation for sample-efficient rlhf. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[62]
Xiong, W., Dong, H., Ye, C., Wang, Z., Zhong, H., Ji, H., Jiang, N., and Zhang, T. Iterative preference learning from human feedback: Bridging theory and practice for rlhf under kl-constraint.arXiv preprint arXiv:2312.11456, 2023. 16
-
[63]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Learning beyond Teacher: Generalized On-Policy Distillation with Reward Extrapolation
Yang, W., Liu, W., Xie, R., Yang, K., Yang, S., and Lin, Y. Learning beyond teacher: Generalized on-policy distillation with reward extrapolation.arXiv preprint arXiv:2602.12125, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[65]
Black-box on-policy distillation of large language models.CoRR, abs/2511.10643, 2025
Ye, T., Dong, L., Chi, Z., Wu, X., Huang, S., and Wei, F. Black-box on-policy distillation of large language models.CoRR, abs/2511.10643, 2025. doi: 10.48550/ARXIV.2511.10643. URL https: //doi.org/10.48550/arXiv.2511.10643
-
[66]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Yu, Q., Zhang, Z., Zhu, R., Yuan, Y., Zuo, X., Yue, Y., Dai, W., Fan, T., Liu, G., Liu, L., et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
Zeng, W., Huang, Y., Liu, Q., Liu, W., He, K., Ma, Z., and He, J. Simplerl-zoo: Investigating and taming zero reinforcement learning for open base models in the wild.arXiv preprint arXiv:2503.18892, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[68]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Zhao, S., Xie, Z., Liu, M., Huang, J., Pang, G., Chen, F., and Grover, A. Self-distilled reasoner: On-policy self-distillationforlargelanguagemodels.CoRR,abs/2601.18734, 2026. doi: 10.48550/ARXIV.2601.18734. URLhttps://doi.org/10.48550/arXiv.2601.18734
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.18734 2026
-
[69]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
Zheng, Y., Zhang, R., Zhang, J., Ye, Y., Luo, Z., Feng, Z., and Ma, Y. Llamafactory: Unified efficient fine-tuning of 100+ language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), Bangkok, Thailand, 2024. Association for Computational Linguistics. URLhttp://arxiv.org/abs/...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[70]
ζ 2 l−1X i=1 1[i̸∈ X(D)] # ≥ 1 2 E
Ziebart, B. D., Maas, A. L., Bagnell, J. A., Dey, A. K., et al. Maximum entropy inverse reinforcement learning. InAaai, volume 8, pp. 1433–1438. Chicago, IL, USA, 2008. 17 A Proofs and Additional Results A.1 Proof of Theorem 1 Without loss of generality, assume thatK := |Π| = 2l for some l∈N ∗. If not, letK ′ = 2⌊log2 K⌋ ≤K . We construct the hard instanc...
2008
-
[71]
Warmup Supervised Fine-Tuning.To enable RL training, we first perform supervised fine-tuning on the OpenR1 dataset [11] to strengthen the model’s reasoning capabilities
as the base model. Warmup Supervised Fine-Tuning.To enable RL training, we first perform supervised fine-tuning on the OpenR1 dataset [11] to strengthen the model’s reasoning capabilities. We use the LlamaFactory [69] framework and train for3,064steps with batch size64and learning rate10 −5 using the AdamW optimizer. RL Training Details.We then perform RL...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.