Physics-Informed Neural Network with Squeeze-Excitation-like Attention
Pith reviewed 2026-06-26 18:00 UTC · model grok-4.3
The pith
A squeeze-excitation attention module added to physics-informed neural networks yields stable initialization and competitive accuracy on 17 of 20 benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
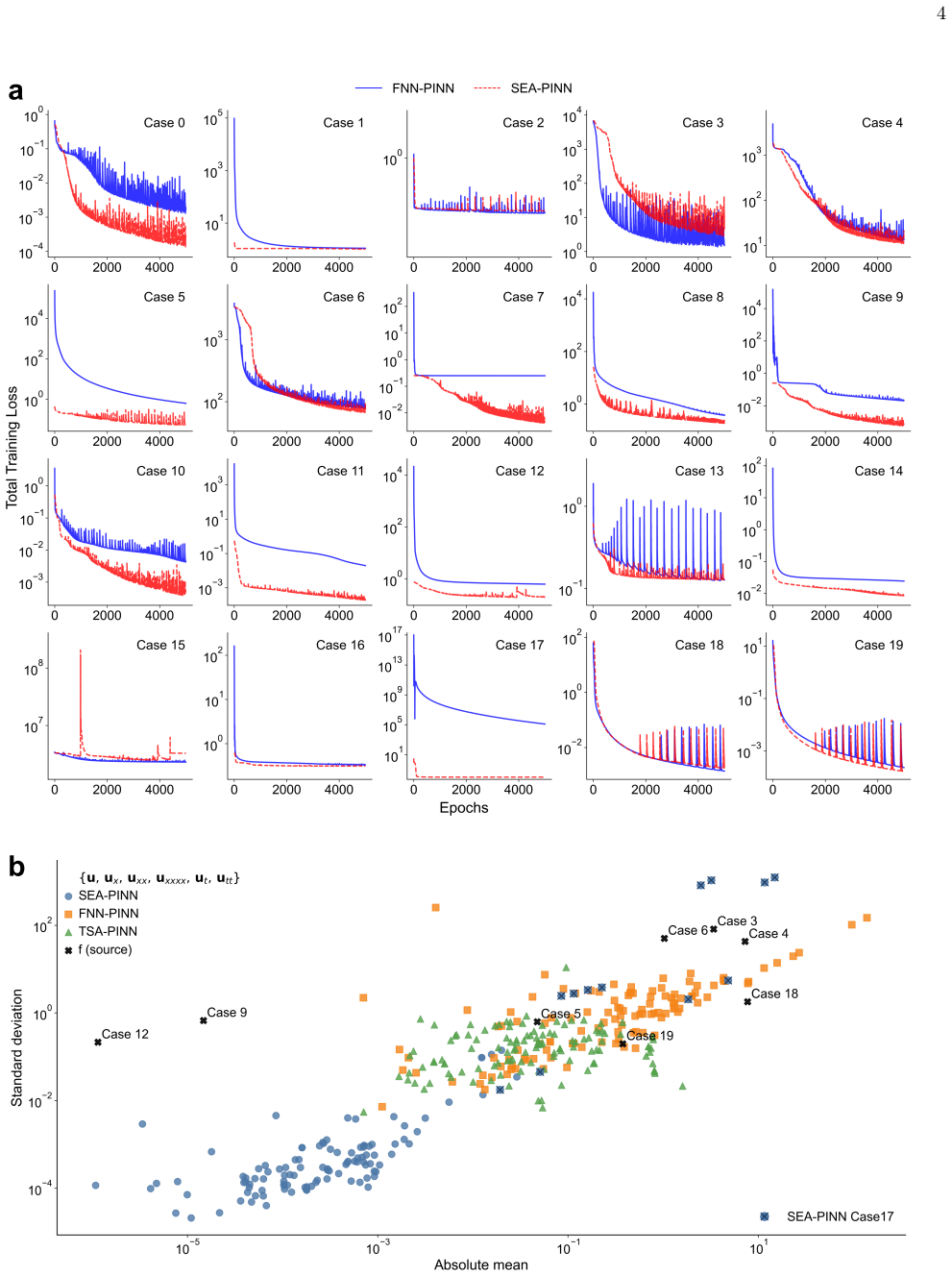
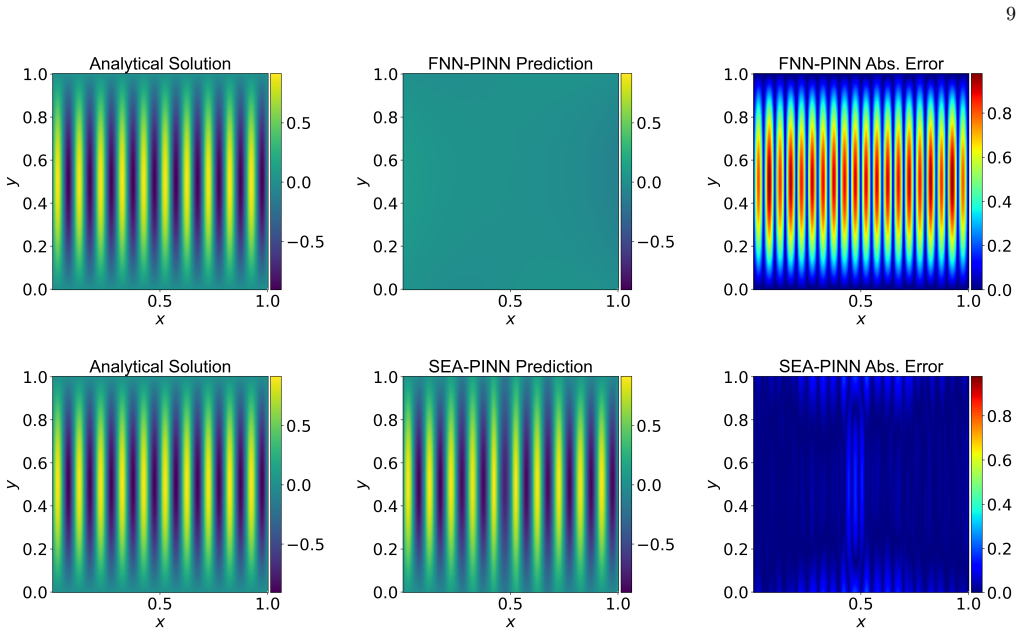
SEA-PINN incorporates a Squeeze-Excitation-like attention mechanism into physics-informed neural networks to dynamically recalibrate the importance of neurons across layers. On 17 out of 20 benchmark problems, SEA-PINN exhibits nearly negligible variance and significantly reduced initial loss, establishing a quasi-deterministic and favorable starting point for optimization. Without employing Fourier feature embeddings or periodic activation functions, SEA-PINN attains competitive accuracy compared with TSA-PINN, and integrating SEA-PINN into TSA-PINN boosts performance by 42.49 percent.
What carries the argument
The squeeze-excitation-like attention mechanism that dynamically recalibrates neuron importance across layers in the PINN architecture.
If this is right
- SEA-PINN functions as a lightweight plug-in module that enhances nonlinear representation power in physics-informed networks.
- The architecture promotes more robust and efficient convergence during optimization.
- SEA-PINN strengthens the overall reliability of physics-informed learning across the tested benchmarks.
- Integration of the module into specialized models such as TSA-PINN produces measurable performance gains.
Where Pith is reading between the lines
- The stable initialization property could reduce the computational cost of repeated random restarts when applying PINNs to new problems.
- The attention recalibration might interact differently with other common PINN enhancements such as adaptive weighting or domain decomposition.
- Extending the benchmarks to include time-dependent or multi-scale problems would test whether the observed stability holds beyond the current set.
Load-bearing premise
The 20 benchmark problems and evaluation protocol represent the distribution of physics problems that practitioners solve, and the attention mechanism does not systematically bias the physics residual terms outside these cases.
What would settle it
Training SEA-PINN on a new high-frequency PDE problem outside the given 20 benchmarks and measuring high variance in initial loss or accuracy below that of TSA-PINN would falsify the stability and competitiveness claims.
Figures


read the original abstract
We introduce SEA-PINN, a novel architecture that incorporates a Squeeze-Excitation-like attention mechanism into physics-informed neural networks to dynamically recalibrate the importance of neurons across layers. A key feature of SEA-PINN is its highly stable initialization. On 17 out of 20 benchmark problems, SEA-PINN exhibit nearly negligible variance and significantly reduced initial loss, establishing a quasi-deterministic and favorable starting point for optimization. Notably, without employing Fourier feature embeddings or periodic activation functions, SEA-PINN attained competitive accuracy (83\% vs. 90\% improvement relative to FNN-PINN on the high-frequency case 7) as compared with TSA-PINN-a model specifically engineered for high-frequency problems via learnable frequencies in sinusoidal activations. Furthermore, integrating SEA-PINN into TSA-PINN boosted performance by 42.49\%. These results underscore SEA-PINN as a lightweight plug-in module that enhances nonlinear representation power, promotes more robust and efficient convergence, and strengthens the overall reliability of physics-informed learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SEA-PINN, a PINN variant that inserts a Squeeze-Excitation-like attention block to dynamically recalibrate channel-wise neuron importance across layers. The central empirical claims are that the architecture yields quasi-deterministic initialization (negligible variance and markedly lower initial loss on 17 of 20 benchmark PDEs), achieves competitive accuracy on high-frequency problems without Fourier features or periodic activations (83 % improvement relative to FNN-PINN on case 7, versus 90 % for TSA-PINN), and delivers an additional 42.49 % gain when the same attention module is grafted onto TSA-PINN.
Significance. If the reported stability and accuracy gains are reproducible under standard experimental controls, the work would supply a lightweight, architecture-agnostic module that improves training reliability for PINNs without requiring specialized activations or feature mappings. Such a module could be adopted as a default component in PINN pipelines, particularly for problems where initialization variance currently forces extensive hyper-parameter search.
major comments (2)
- [Results paragraph] Results paragraph (and any accompanying tables/figures): the headline claims of “nearly negligible variance” and “significantly reduced initial loss” on 17/20 problems are presented without network widths, depth, loss-term weights, optimizer settings, number of independent runs, or statistical tests. These omissions make it impossible to assess whether the reported stability is an artifact of the chosen experimental protocol rather than a property of the attention mechanism.
- [Abstract / Results paragraph] Abstract and results paragraph: the assertion that SEA-PINN is a “reliable plug-in” for arbitrary physics problems rests on a fixed suite of 20 benchmarks. No analysis is supplied showing that the collocation-point distributions or PDE types are representative of the broader distribution of problems encountered in practice, nor is there a test demonstrating that the channel-wise recalibration does not systematically alter gradient flow through the physics residual on problems outside this suite.
minor comments (1)
- [Abstract] The sentence “SEA-PINN exhibit nearly negligible variance” contains a subject-verb agreement error.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [Results paragraph] Results paragraph (and any accompanying tables/figures): the headline claims of “nearly negligible variance” and “significantly reduced initial loss” on 17/20 problems are presented without network widths, depth, loss-term weights, optimizer settings, number of independent runs, or statistical tests. These omissions make it impossible to assess whether the reported stability is an artifact of the chosen experimental protocol rather than a property of the attention mechanism.
Authors: We agree that these details were insufficiently specified. In the revised manuscript we will add an experimental setup section reporting network widths and depths, loss-term weights, optimizer settings, the number of independent runs performed (five), and standard deviations with basic statistical comparisons. This will allow readers to evaluate whether the observed stability arises from the attention mechanism. revision: yes
-
Referee: [Abstract / Results paragraph] Abstract and results paragraph: the assertion that SEA-PINN is a “reliable plug-in” for arbitrary physics problems rests on a fixed suite of 20 benchmarks. No analysis is supplied showing that the collocation-point distributions or PDE types are representative of the broader distribution of problems encountered in practice, nor is there a test demonstrating that the channel-wise recalibration does not systematically alter gradient flow through the physics residual on problems outside this suite.
Authors: We accept that the original wording overstated generality. We will revise the abstract and results text to qualify the claims as applying to the evaluated benchmark suite. We will also add a short gradient-flow analysis for the attention module and a limitations paragraph discussing the scope of the 20 benchmarks. A full representativeness study across all possible PDEs lies outside the present scope. revision: partial
Circularity Check
No circularity; empirical architecture proposal with external benchmarks
full rationale
The paper proposes SEA-PINN as an architectural modification (Squeeze-Excitation-like attention inserted into PINNs) and evaluates it empirically on a fixed suite of 20 benchmark PDE problems. No derivation chain, uniqueness theorem, ansatz, or prediction is presented that reduces by construction to quantities defined or fitted inside the paper itself. Claims rest on reported loss curves, variance statistics, and accuracy deltas versus external baselines (FNN-PINN, TSA-PINN), none of which are shown to be self-referential or forced by the authors' own prior definitions. The evaluation protocol is external to any internal fitting loop, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Linear Transformation: z(l) =W (l)h(l−1) +b (l) (3)
-
[2]
Nonlinear Activation: a(l) =σ (l)(z(l)) wherea (l) ∈R Nl
-
[3]
6: Architecture of SEA-PINN within PINNs: The complete set of outputs from thenth hidden layer is taken as input to the weight generator, producing a weight vector
Weight Generation (WG): The activationa (l) is processed by a lightweight squeeze-excitation block to 11 𝜕𝑡 𝑛 𝜕𝑥 𝑛 ℒ = ℒ𝑃𝐷𝐸 + ℒ𝐼𝐶 + ℒ𝐵𝐶 < 𝜖? End N Y 𝜕ℒ 𝜕𝛩Update 𝛩 AD Loss Squeeze-Excitation like Attention× n Output Input … … … … … FIG. 6: Architecture of SEA-PINN within PINNs: The complete set of outputs from thenth hidden layer is taken as input to the w...
-
[4]
Weighted Output: h(l) =λ (l) ⊙a (l) (7) This mechanism enables SEA-PINN to dynamically adjust the contribution of each neuron. If a neuron’s ac- tivation is less relevant for a specific input region in the current task, the weight generator can assign a smaller weight to suppress its influence; conversely, a larger weight can be assigned to enhance its ro...
-
[5]
reduces to the usual activation a(l) FNN =σ (l) z(l) ,(8) wherez (l) is given by Eq. (3). Since the nonlinearity is applied element-wise, the local Jacobian ofa (l) FNN with respect toz (l) is diagonal: D(l) FNN = ∂a(l) FNN ∂z(l) = diag σ(l)′ (z(l)) .(9) The output layer is purely linear, fFNN =W (L)a(L−1) +b (L),(10) so the Jacobian of the network output...
-
[6]
This ensures a compre- hensive assessment of model performance
Benchmark Suite and Evaluation Metrics We evaluated the proposed models on 20 challenging PDE problems selected from a recognized PINNs bench- mark suite, covering diverse domains including heat con- duction, fluid dynamics, biology, electromagnetics, and high-dimensional problems [41]. This ensures a compre- hensive assessment of model performance. As al...
-
[7]
Unless otherwise specified, all weights are initialized using He uniform initialization and biases are set to zero
Network Configuration and Training For a fair comparison, all neural network mod- els (FNN-PINN, SEA-PINN, TSA-PINN, TSA_SEA- PINN) share the same backbone architecture, consist- ing of 9 hidden layers with 32 neurons per layer. Unless otherwise specified, all weights are initialized using He uniform initialization and biases are set to zero. Activation F...
-
[8]
Advanced Detection and Artificial Intelligence at the Frontiers of Physics
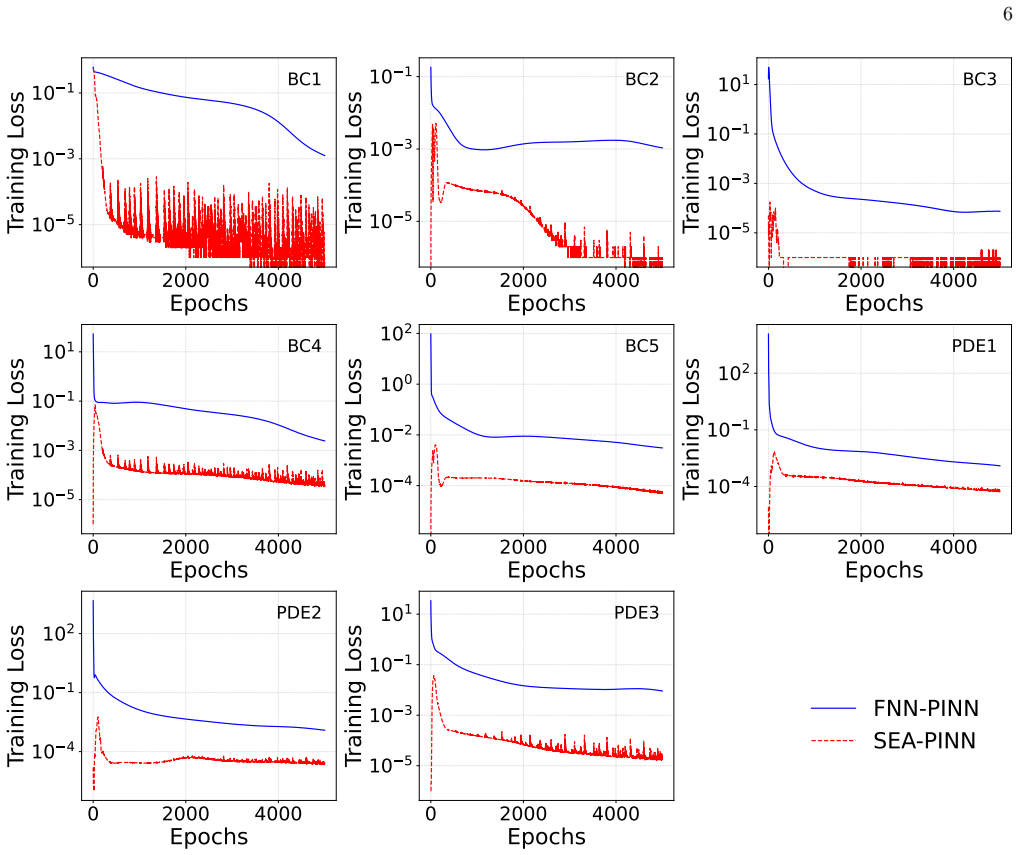
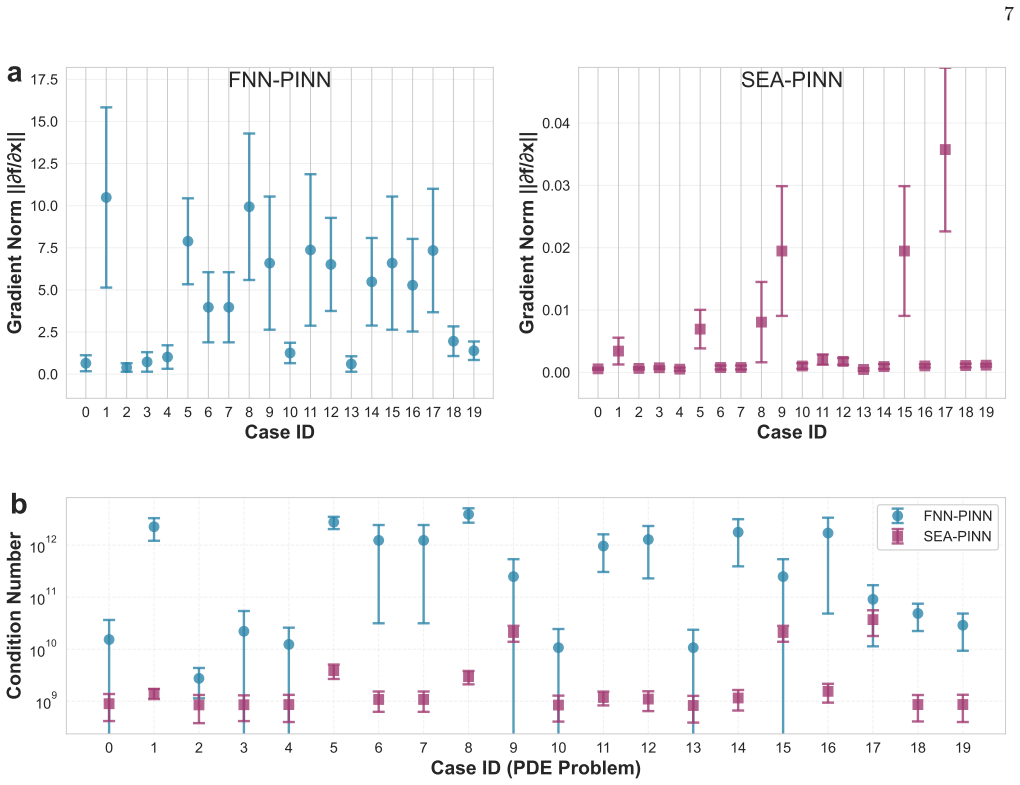
for chaotic problems. These settings are kept consistent across all models to ensure that any performance difference arises from the architectural innovations rather than training hyperpa- rameters. Supplementary Information: detailed training loss analysis, total training loss comparison, individual loss component comparison, initial loss behavior of SEA...
2025
-
[9]
G. E. Karniadakis, I. G. Kevrekidis, L. Lu, P. Perdikaris, S. Wang, and L. Yang, Nature Reviews Physics3, 422 (2021)
2021
-
[10]
A. G. Baydin, B. A. Pearlmutter, A. A. Radul, and J. M. Siskind, Journal of machine learning research18, 1 (2018)
2018
-
[11]
Lee and I
H. Lee and I. S. Kang, Journal of Computational Physics 91, 110 (1990)
1990
-
[12]
A. J. Meade Jr and A. A. Fernandez, Mathematical and Computer Modelling20, 19 (1994)
1994
-
[13]
M. G. Dissanayake and N. Phan-Thien, communications in Numerical Methods in Engineering10, 195 (1994)
1994
-
[14]
Lagaris, A
I. Lagaris, A. Likas, and D. Fotiadis, IEEE Transactions on Neural Networks9, 987 (1998)
1998
-
[15]
G. E. Hinton and R. R. Salakhutdinov, science313, 504 (2006)
2006
-
[16]
Raissi, P
M. Raissi, P. Perdikaris, and G. Karniadakis, Journal of Computational Physics378, 686 (2019)
2019
-
[17]
L. Lu, X. Meng, Z. Mao, and G. E. Karniadakis, SIAM review63, 208 (2021)
2021
-
[18]
X. Jin, S. Cai, H. Li, and G. E. Karniadakis, Journal of Computational Physics426, 109951 (2021)
2021
-
[19]
R. Qiu, R. Huang, Y. Xiao, J. Wang, Z. Zhang, J. Yue, Z. Zeng, and Y. Wang, Physics of Fluids34(2022)
2022
-
[20]
Y. Wang, J. Sun, W. Li, Z. Lu, and Y. Liu, Com- puter Methods in Applied Mechanics and Engineering 400, 115491 (2022)
2022
-
[21]
Z. Wu, H. Zhang, H. Ye, H. Zhang, Y. Zheng, and X. Guo, Acta Mechanica235, 4895 (2024)
2024
-
[22]
Y. Chen, L. Lu, G. E. Karniadakis, and L. Dal Negro, Optics express28, 11618 (2020)
2020
-
[23]
Fang and J
Z. Fang and J. Zhan, Ieee Access8, 24506 (2019)
2019
-
[24]
P.Ren, C.Rao, S.Chen, J.-X.Wang, H.Sun, andY.Liu, Computer Physics Communications295, 109010 (2024)
2024
-
[25]
L. Lu, P. Jin, G. Pang, Z. Zhang, and G. E. Karniadakis, Nature machine intelligence3, 218 (2021)
2021
-
[26]
S. Wang, H. Wang, and P. Perdikaris, Science advances 7, eabi8605 (2021)
2021
-
[27]
L. Lu, X. Meng, S. Cai, Z. Mao, S. Goswami, Z. Zhang, and G. E. Karniadakis, Computer Methods in Applied Mechanics and Engineering393, 114778 (2022)
2022
-
[28]
P. Jin, S. Meng, and L. Lu, SIAM Journal on Scientific Computing44, A3490 (2022)
2022
-
[29]
M. Zhu, S. Feng, Y. Lin, and L. Lu, Computer Meth- ods in Applied Mechanics and Engineering416, 116300 (2023)
2023
-
[30]
Jiang, M
Z. Jiang, M. Zhu, and L. Lu, Reliability Engineering & System Safety251, 110392 (2024)
2024
-
[31]
M.Zhu, H.Zhang, A.Jiao, G.E.Karniadakis, andL.Lu, Computer Methods in Applied Mechanics and Engineer- ing412, 116064 (2023)
2023
-
[32]
Z. Li, N. B. Kovachki, K. Azizzadenesheli, B. liu, K. Bhattacharya, A. Stuart, and A. Anandkumar, in International Conference on Learning Representations (2021)
2021
-
[33]
A. Jiao, H. He, R. Ranade, J. Pathak, and L. Lu, Nature Communications16, 8386 (2025)
2025
-
[34]
Rahaman, A
N. Rahaman, A. Baratin, D. Arpit, F. Draxler, M. Lin, F. Hamprecht, Y. Bengio, and A. Courville, inProceed- ings of the 36th International Conference on Machine Learning, Proceedings of Machine Learning Research, Vol. 97, edited by K. Chaudhuri and R. Salakhutdinov (PMLR, 2019) pp. 5301–5310
2019
-
[35]
Tancik, P
M. Tancik, P. Srinivasan, B. Mildenhall, S. Fridovich- Keil, N. Raghavan, U. Singhal, R. Ramamoorthi, J. Bar- ron, and R. Ng, Advances in neural information process- ing systems33, 7537 (2020)
2020
-
[36]
A. D. Jagtap, K. Kawaguchi, and G. Em Karni- adakis,ProceedingsoftheRoyalSocietyA476,20200334 (2020)
2020
-
[37]
H. Gao, L. Sun, and J.-X. Wang, Journal of Computa- tional Physics428, 110079 (2021)
2021
-
[38]
Pfaff, M
T. Pfaff, M. Fortunato, A. Sanchez-Gonzalez, and P. Battaglia, inInternational conference on learning rep- 15 resentations(2020)
2020
- [39]
-
[40]
A. D. Jagtap, E. Kharazmi, and G. E. Karniadakis, Computer Methods in Applied Mechanics and Engineer- ing365, 113028 (2020)
2020
-
[41]
A. D. Jagtap and G. E. Karniadakis, Communications in Computational Physics28(2020)
2020
-
[42]
C. Wu, M. Zhu, Q. Tan, Y. Kartha, and L. Lu, Com- puter Methods in Applied Mechanics and Engineering 403, 115671 (2023)
2023
-
[43]
Respecting causality is all you need for training physics-informed neural networks,
S. Wang, S. Sankaran, and P. Perdikaris, “Respecting causality is all you need for training physics-informed neural networks,” (2022), arXiv:2203.07404 [cs.LG]
-
[44]
S. Wang, X. Yu, and P. Perdikaris, Journal of Compu- tational Physics449, 110768 (2022)
2022
-
[45]
L. D. McClenny and U. M. Braga-Neto, Journal of Com- putational Physics474, 111722 (2023)
2023
-
[46]
S. Wang, Y. Teng, and P. Perdikaris, SIAM Journal on Scientific Computing43, A3055 (2021), https://doi.org/10.1137/20M1318043
-
[47]
C. Xu, D. Liu, A. Nassereldine, and J. Xiong, “Fp64 is all you need: Rethinking failure modes in physics-informed neural networks,” (2025), arXiv:2505.10949 [cs.LG]
-
[48]
J. Hu, L. Shen, S. Albanie, G. Sun, and E. Wu, arXiv e-prints , arXiv:1709.01507 (2017), arXiv:1709.01507 [cs.CV]
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[49]
Zhang, S
H.Zhongkai, J.Yao, C.Su, H.Su, Z.Wang, F.Lu, Z.Xia, Y. Zhang, S. Liu, L. Lu,et al., Advances in Neural In- formation Processing Systems37, 76721 (2024)
2024
-
[50]
Intriguing properties of neural networks
C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Er- han, I. Goodfellow, and R. Fergus, arXiv preprint arXiv:1312.6199 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[51]
S. S. Schoenholz, J. Gilmer, S. Ganguli, and J. Sohl- Dickstein, arXiv preprint arXiv:1611.01232 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[52]
Pennington, S
J. Pennington, S. Schoenholz, and S. Ganguli, Advances in neural information processing systems30(2017)
2017
-
[53]
Sensitivity and Generalization in Neural Networks: an Empirical Study
R. Novak, Y. Bahri, D. A. Abolafia, J. Pennington, and J. Sohl-Dickstein, arXiv preprint arXiv:1802.08760 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[54]
Ross and F
A. Ross and F. Doshi-Velez, inProceedings of the AAAI conference on artificial intelligence, Vol. 32 (2018)
2018
-
[55]
Pennington, S
J. Pennington, S. Schoenholz, and S. Ganguli, inInter- national Conference on Artificial Intelligence and Statis- tics(PMLR, 2018) pp. 1924–1932
2018
-
[56]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, Advances in neural information processing systems30 (2017)
2017
- [57]
-
[58]
Y. Sun, L. Dong, S. Huang, S. Ma, Y. Xia, J. Xue, J. Wang, and F. Wei, arXiv preprint arXiv:2307.08621 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[59]
Z. Qiu, Z. Wang, B. Zheng, Z. Huang, K. Wen, S. Yang, R. Men, L. Yu, F. Huang, S. Huang,et al., arXiv preprint arXiv:2505.06708 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [60]
-
[61]
M. E. Larkum, W. Senn, and H.-R. Lüscher, Cerebral cortex14, 1059 (2004)
2004
-
[62]
Gidon, T
A. Gidon, T. A. Zolnik, P. Fidzinski, F. Bolduan, A. Pa- poutsi, P. Poirazi, M. Holtkamp, I. Vida, and M. E. Larkum, Science367, 83 (2020)
2020
-
[63]
D. P. Kingma, arXiv preprint arXiv:1412.6980 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[64]
Chebfun guide,
T. A. Driscoll, N. Hale, and L. N. Trefethen, “Chebfun guide,” (2014). 16 Supplementary Information S1. DETAILED TRAINING LOSS ANALYSIS This document provides supplementary results to support the claims made in the main text, demonstrating the consistentandsignificantadvantagesoftheSEA-PINNoverthestandardFNN-PINN.Wepresentdetailedtrainingloss comparisons ...
2014
-
[65]
In the top two plots, SEA-PINN’s average prediction (orange line) stays closer to the true function (dashed black line) in the extrapolation regions ( x<0 and x>1 ). Furthermore, its uncertainty band (orange shading) is significantly smaller than the FNN-PINN’s (blue shading), indicating that SEA-PINN’s predictions are not only more accurate but also more...
-
[66]
The bottom two plots, which feature a sharp peak and a sudden jump, highlight this difference even more clearly. While both models learn the difficult features inside the training domain, the FNN-PINN produces highly unstable and incorrect predictions outside of it. In contrast, SEA-PINN defaults to a simple, flat prediction in these unknown regions, main...
-
[67]
a(k) N = ζ1 sin f (k) 1 z(k) 1 +ζ 2 cos f (k) 1 z(k) 1 ζ1 sin f (k) 2 z(k) 2 +ζ 2 cos f (k) 2 z(k) 2
Trainable Sine Activation (TSA) where the final output of thek-th layer is: a(k) = a(k) 1 a(k) 2 ... a(k) N = ζ1 sin f (k) 1 z(k) 1 +ζ 2 cos f (k) 1 z(k) 1 ζ1 sin f (k) 2 z(k) 2 +ζ 2 cos f (k) 2 z(k) 2 ... ζ1 sin f (k) N z(k) N +ζ 2 cos f (k) N z(k) N (S1) where: •z (k) i is the output of thei-th neuron in thek-th layer...
-
[68]
S(a) = 1 1 L−1 PL−1 k=1 exp 1 Nk PNk i=1 f (k) i (S2) where: •Lis the total number of layers, •N k is the number of neurons in thek-th layer
Slope Recovery Mechanism The slope recovery termS(a)dynamically adjusts the slope of the activation function, maintaining active and effective gradient propagation throughout the network. S(a) = 1 1 L−1 PL−1 k=1 exp 1 Nk PNk i=1 f (k) i (S2) where: •Lis the total number of layers, •N k is the number of neurons in thek-th layer. This slope recovery term is...
-
[69]
Compute the standard TSA-PINN activation outputa(l): a(l) i =ζ 1 sin(f (l) i z(l) i ) +ζ 2 cos(f (l) i z(l) i )(S4) wherez (l) i =w (l) i ·ˆ a(l−1) +b (l) i
-
[70]
Use the activation outputa(l) as input to the weight generator to compute the weight vectorλ(l): λ(l) =Sigmoid(W 2σ(W1a(l) +b 1) +b 2)(S5)
-
[71]
Element-wise multiply the weight vector with the activation output to obtain the final layer output: ˆ a(l) =λ (l) ⊙a (l) (S6) By combining TSA-PINN with our weighting module, the TSA_SEA-PINN model explores whether the adaptive weighting mechanism can serve as a general enhancement module, further improving the performance of existing advanced PINN archi...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.