Finding Needles in the Haystack: Transductive Active Labeling in Ecology
Pith reviewed 2026-07-01 07:45 UTC · model grok-4.3
The pith
Transductive active learning in ecology prioritizes discovery of rare classes over predictive accuracy
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
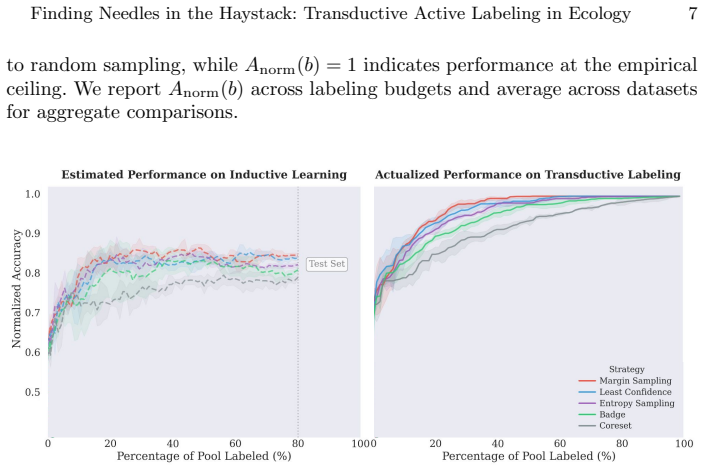
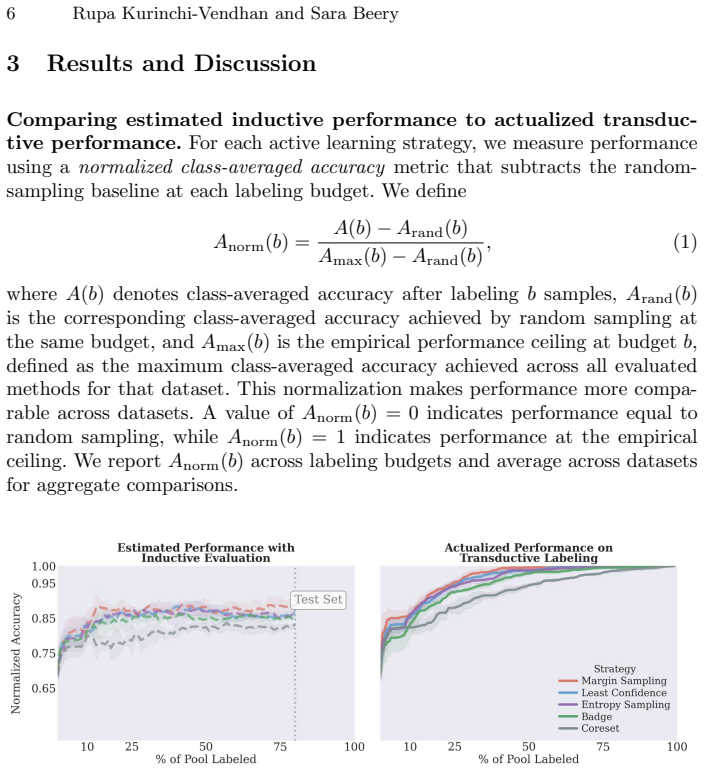
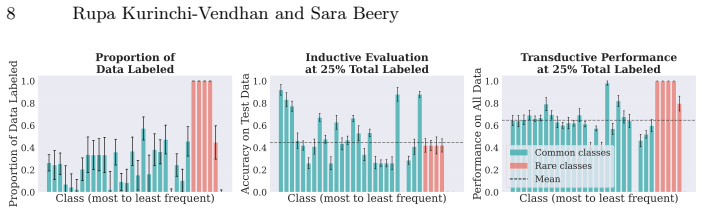
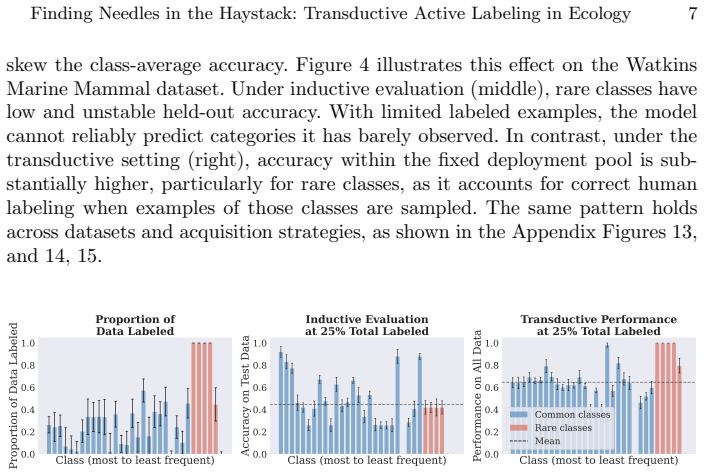
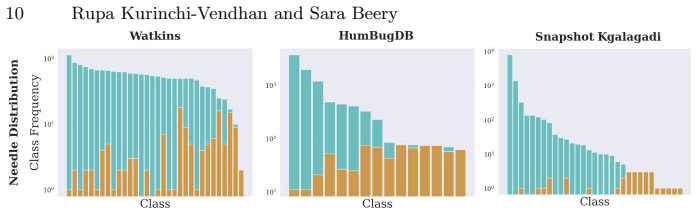
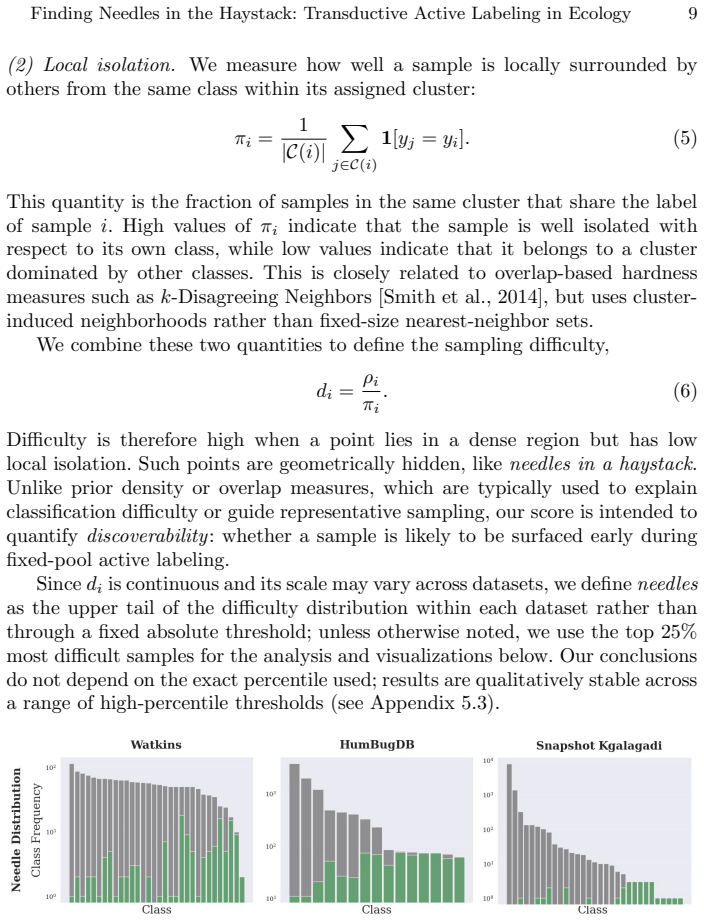
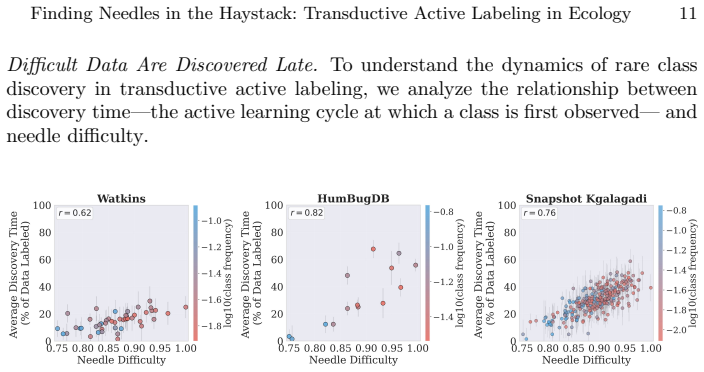
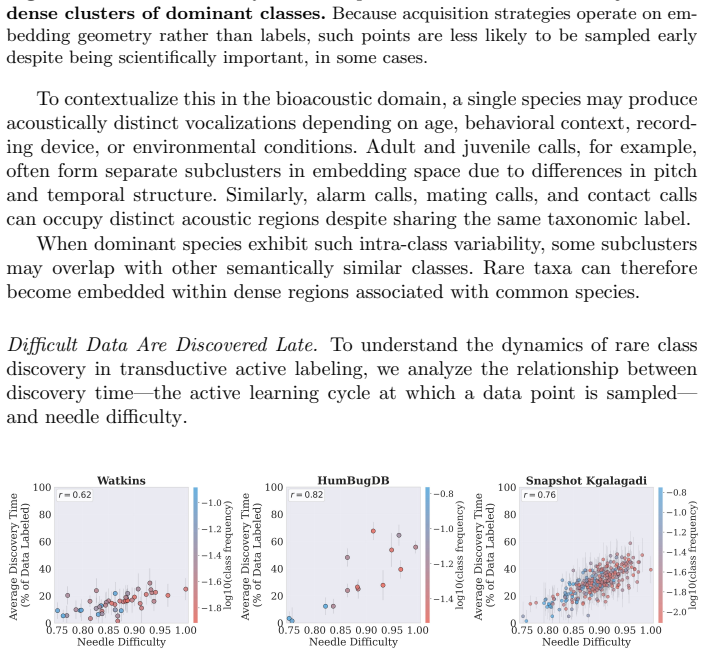
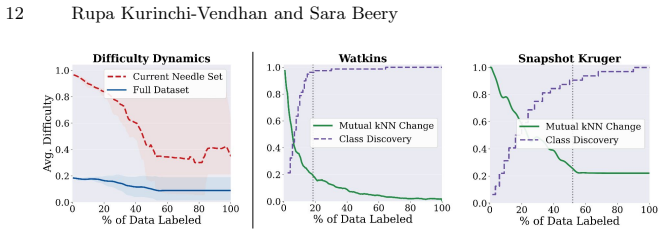
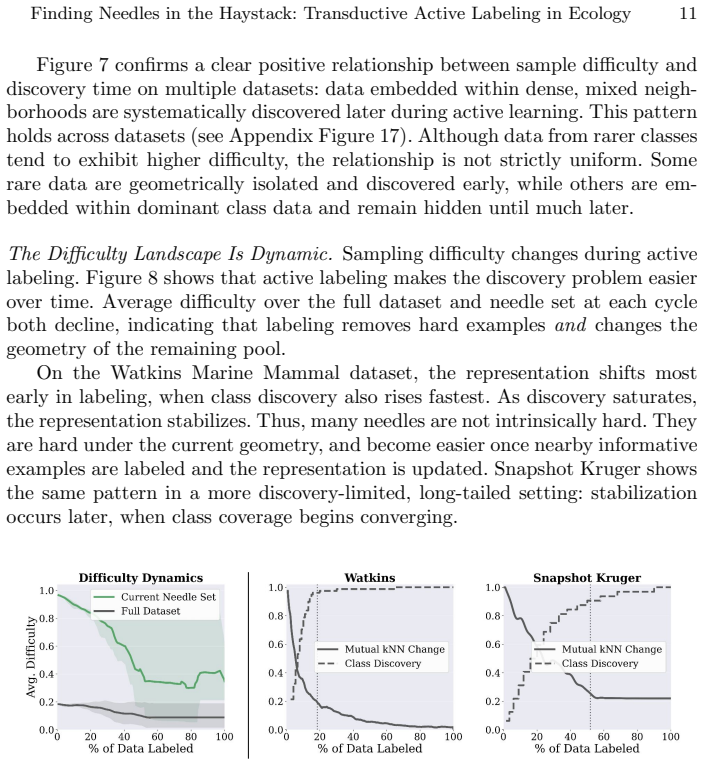
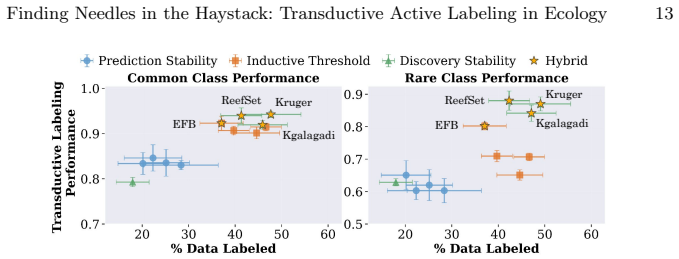
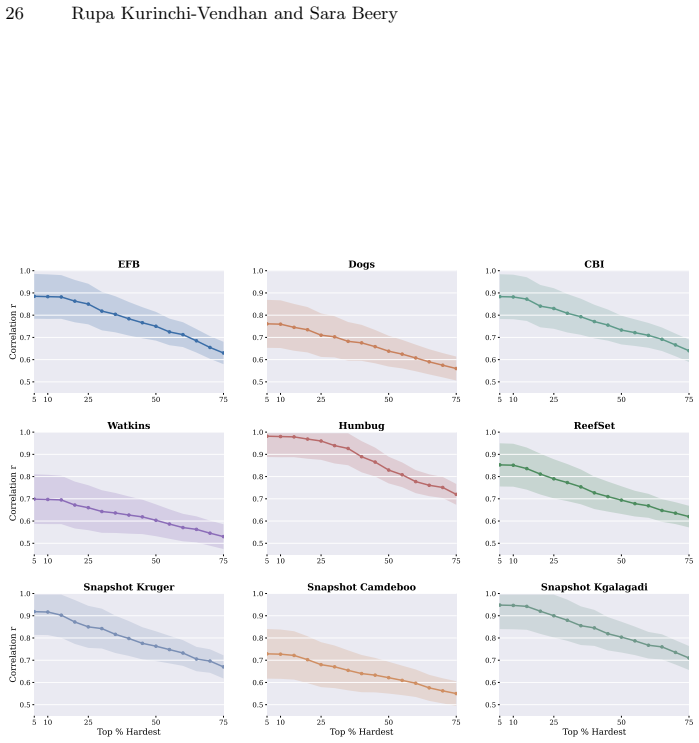
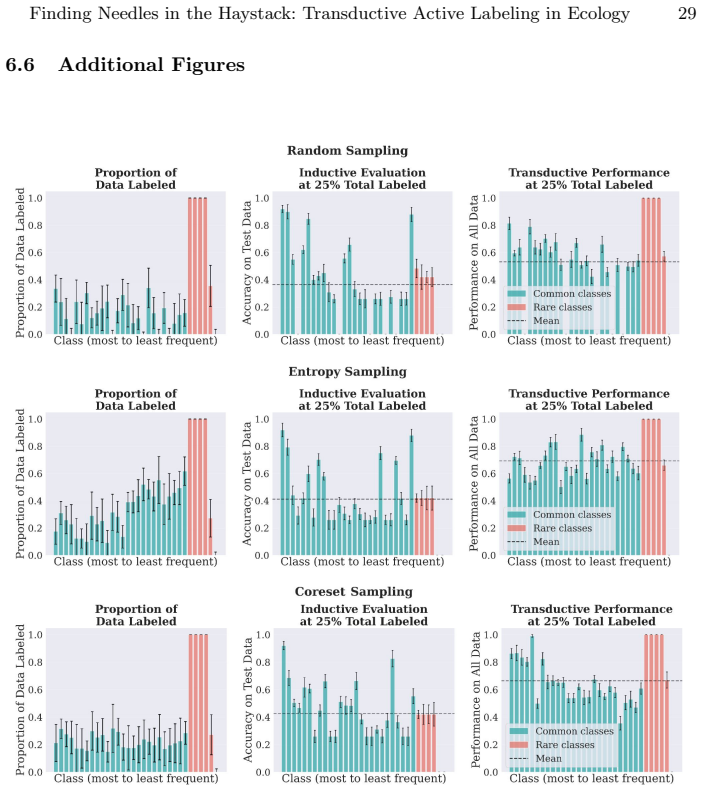
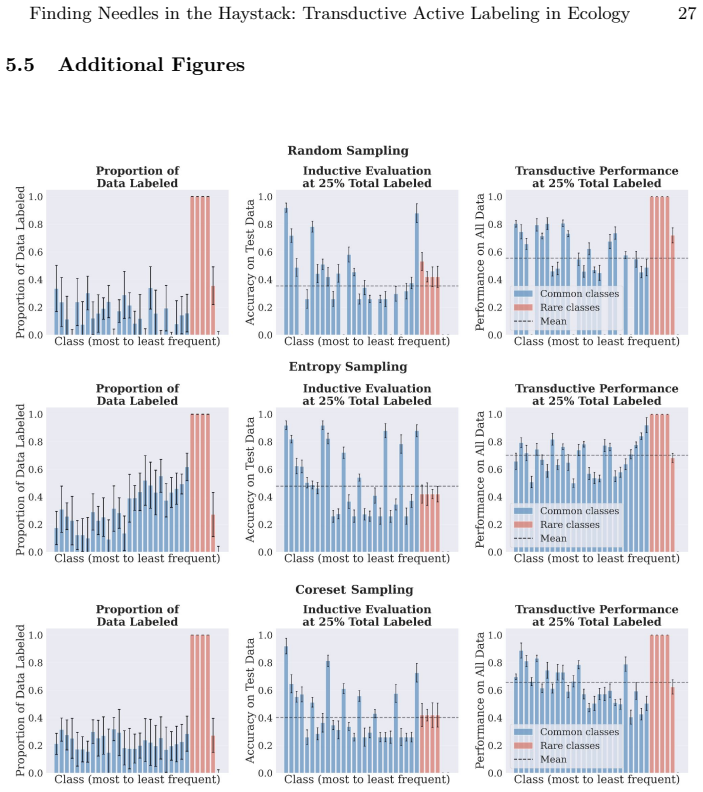
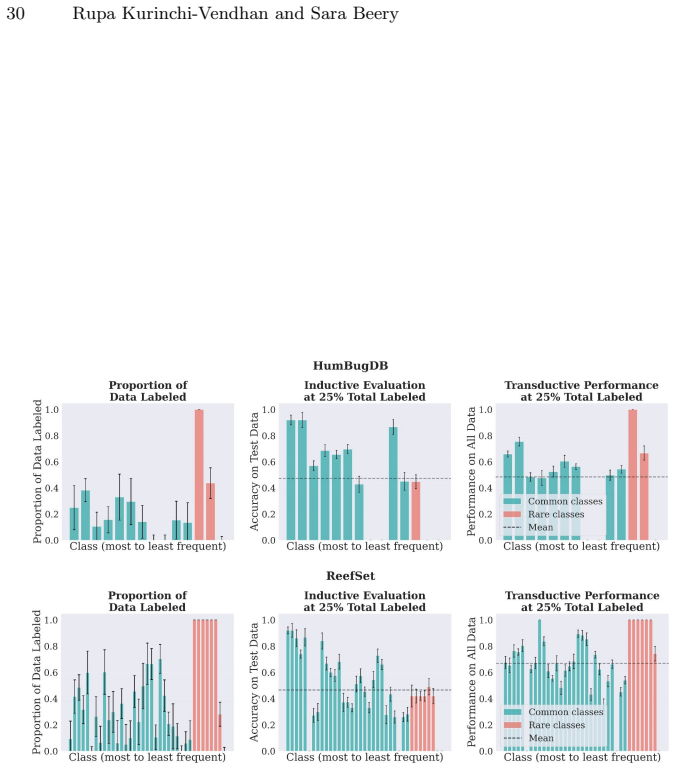
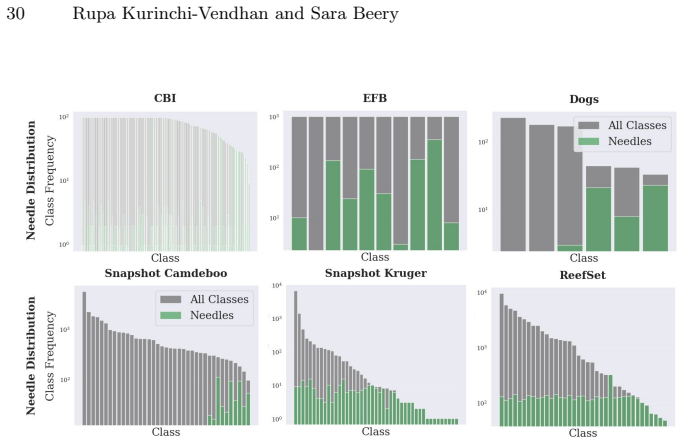
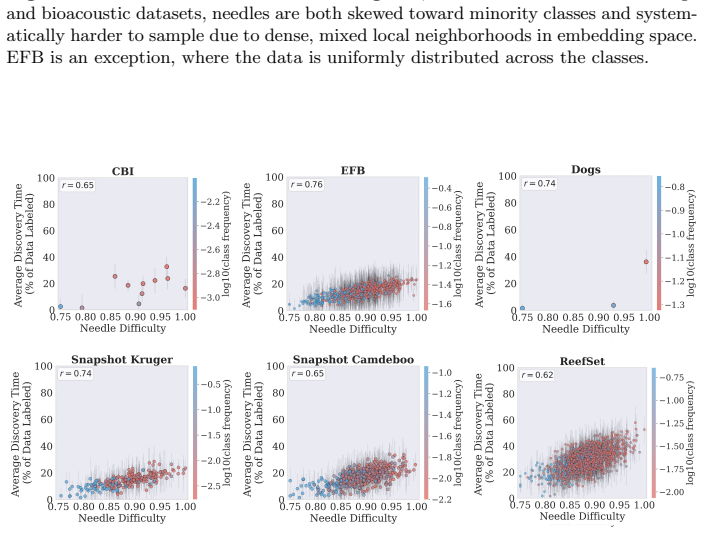
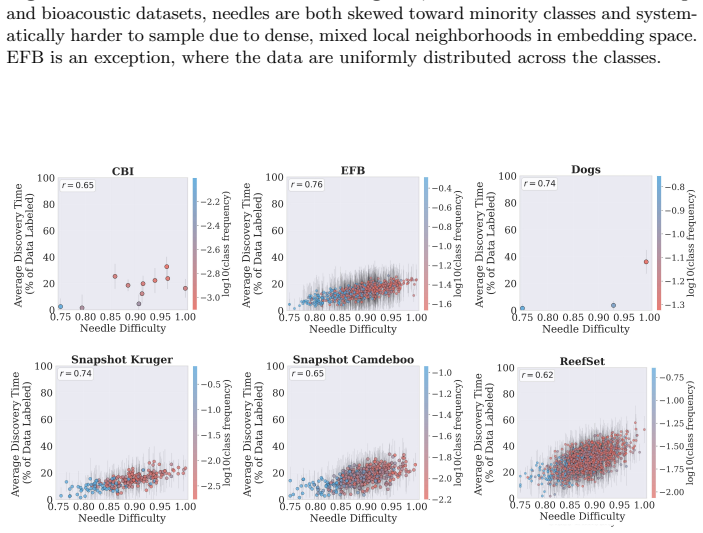
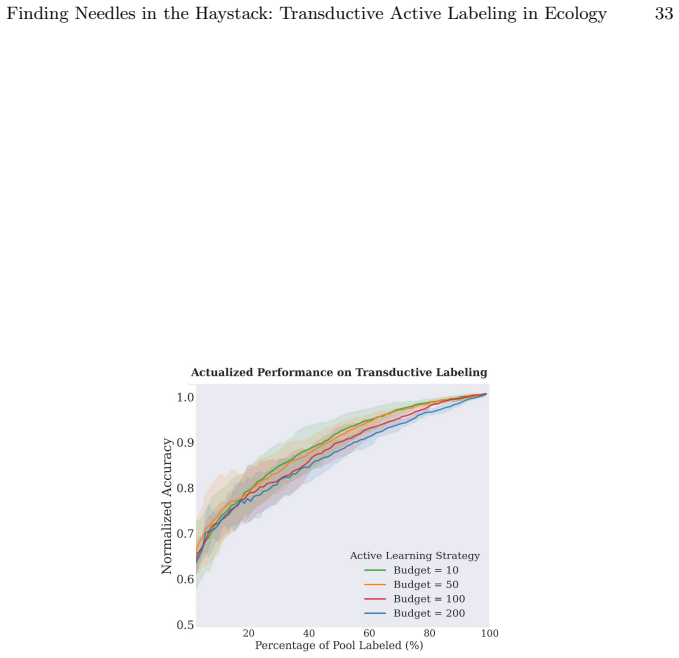
For most ecological labeling tasks the goal is to transductively label the entire pool of data efficiently rather than to build an inductive predictor for future data. When this transductive view is taken, the long tail of rare classes becomes the limiting factor, shifting the problem from prediction accuracy to discovery of needles in the haystack. The authors quantify the embedding of rare classes in dense common-class regions with a sampling difficulty metric and propose a conservative hybrid stopping criterion that combines prediction with discovery to improve rare-class recovery.
What carries the argument
The transductive objective combined with a novel metric of sampling difficulty that identifies how rare classes are embedded within abundant classes in the latent space
If this is right
- Ignoring the human-in-the-loop underestimates the value of continued labeling for long-tail classes
- The transductive objective makes discovery the central challenge for rare ecological classes
- A hybrid stopping criterion reduces premature stopping on long-tailed data pools
- Combining predictive performance with discovery criteria improves recovery of rare classes when discovery is limiting
Where Pith is reading between the lines
- Similar transductive approaches could benefit other fields with imbalanced data such as medical diagnostics for rare conditions
- Algorithms could be designed to explicitly optimize for the sampling difficulty metric rather than uncertainty or diversity alone
- Analysis of latent geometry might reveal general patterns in how rare events cluster in high-dimensional data from sensors or cameras
Load-bearing premise
Most ecological labeling tasks aim at exhaustive transductive coverage of the collected data rather than inductive generalization to unseen future data
What would settle it
A comparison on real ecological datasets where an inductive stopping rule achieves equivalent rare-class coverage to the proposed transductive hybrid rule would falsify the claim of misalignment
Figures


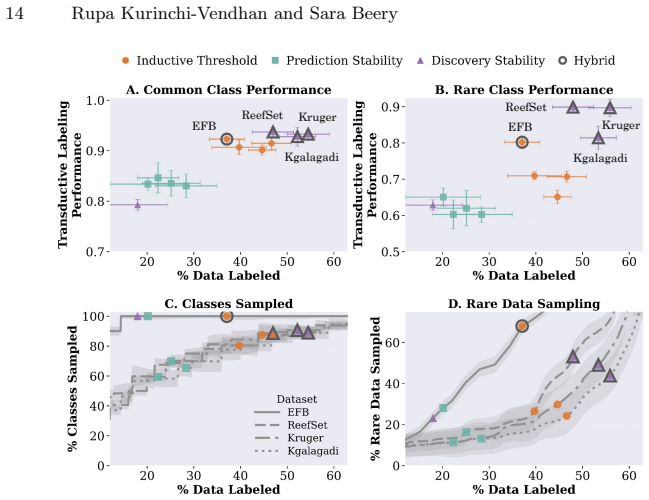
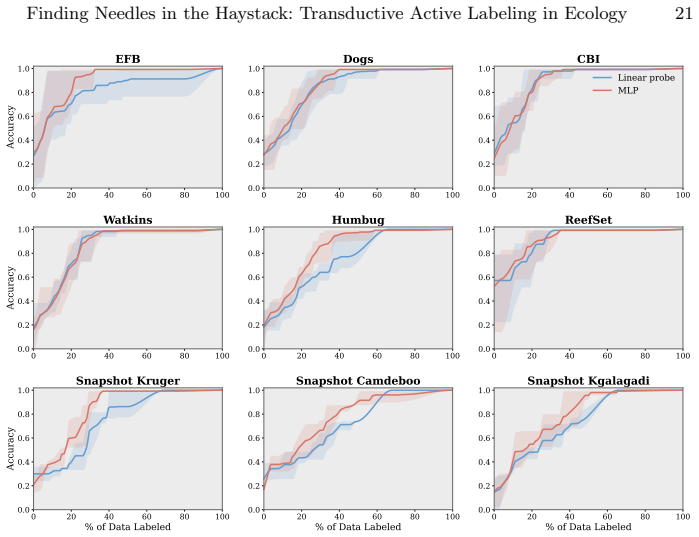
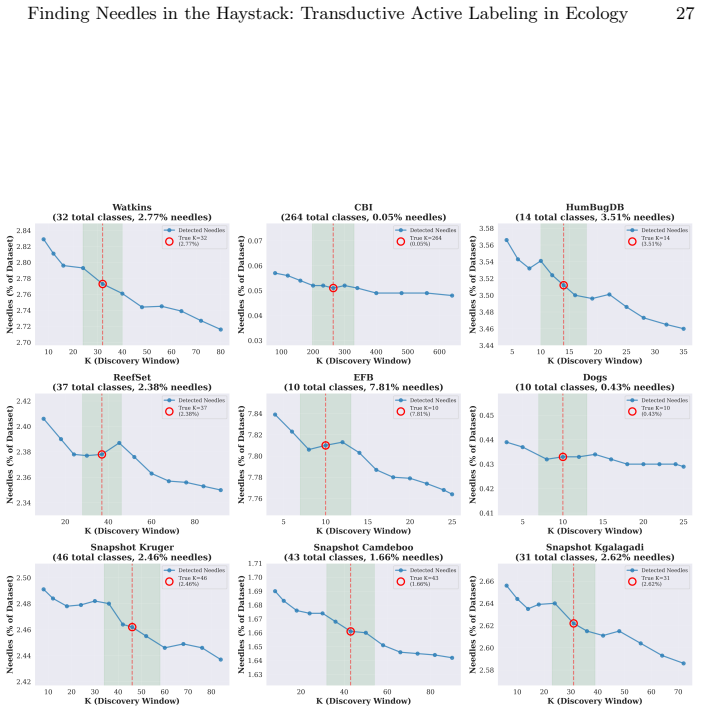

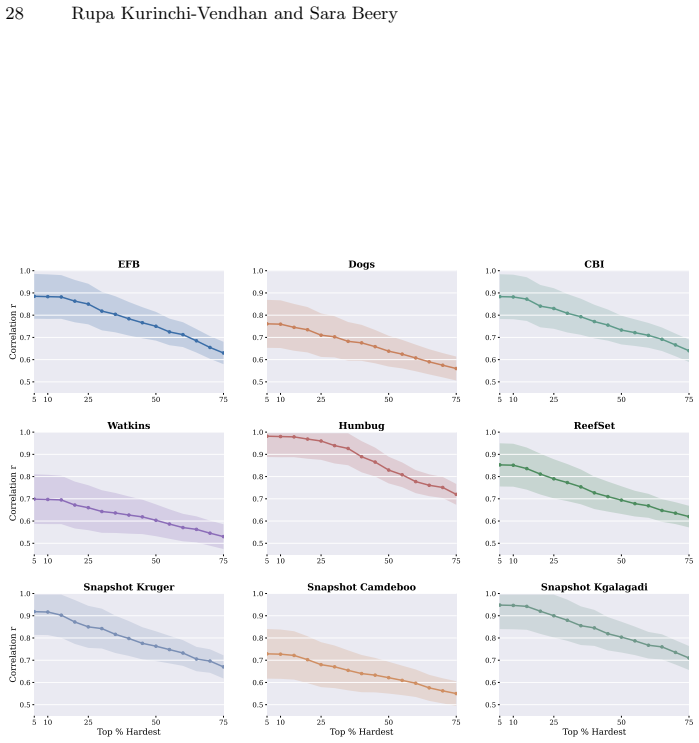
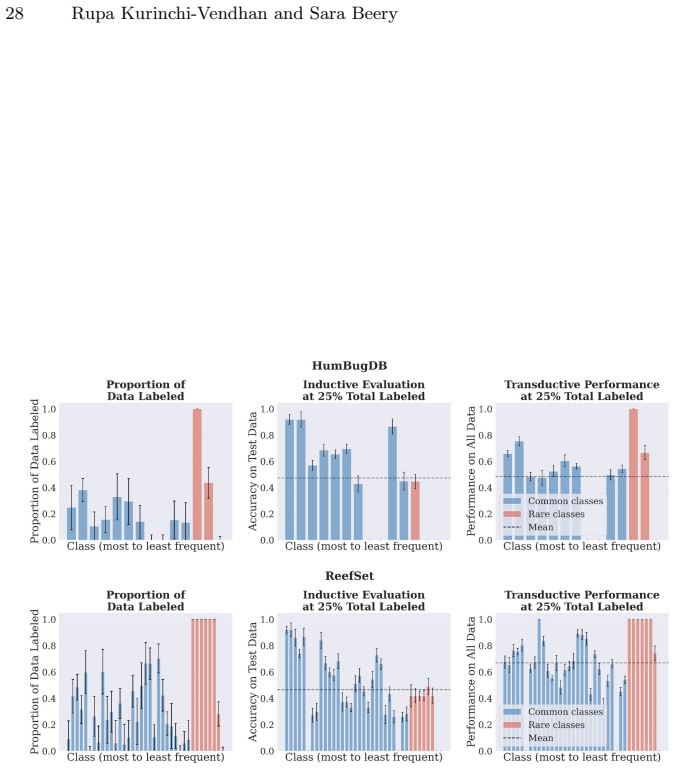
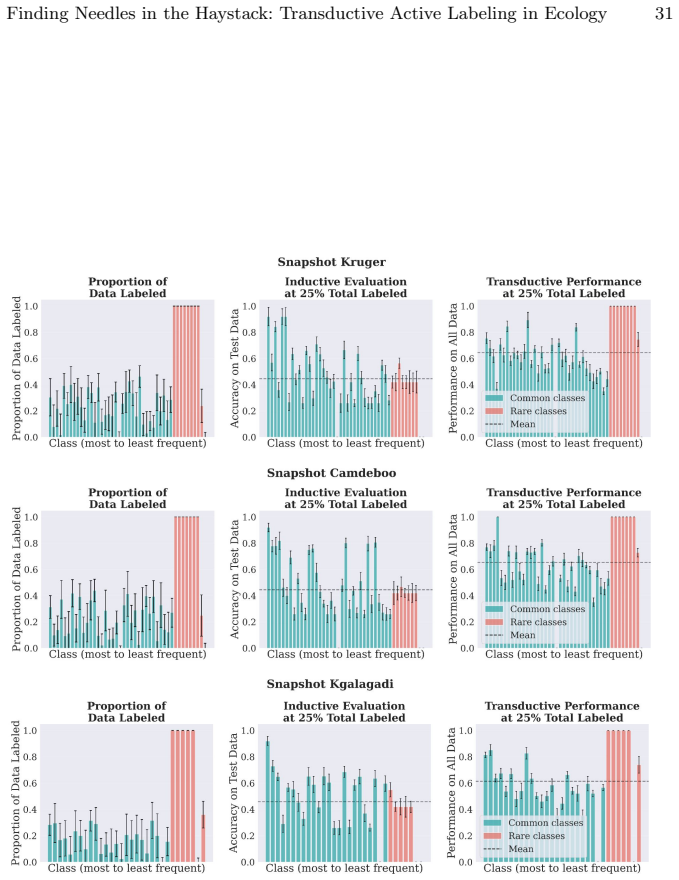
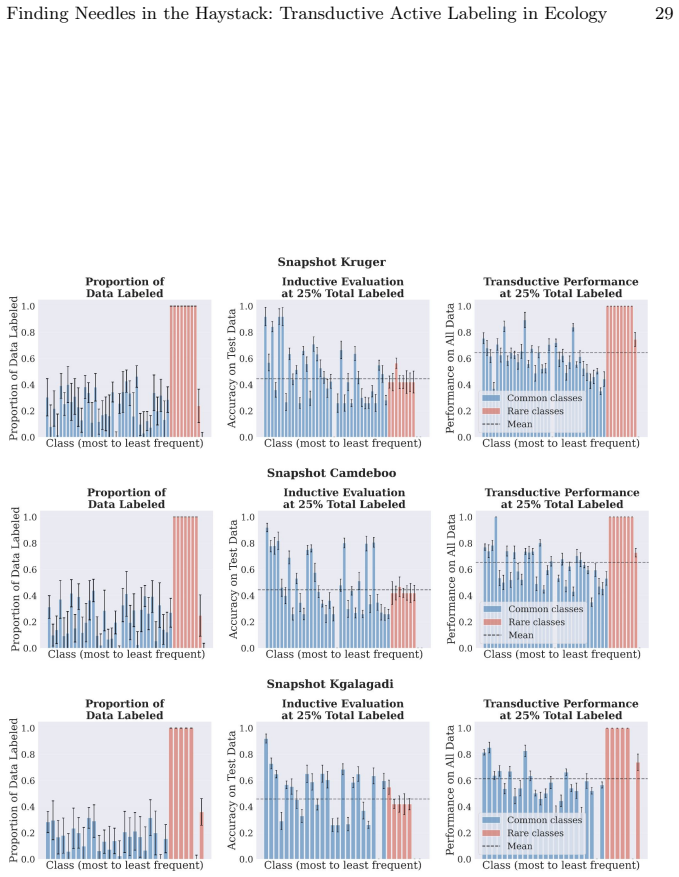
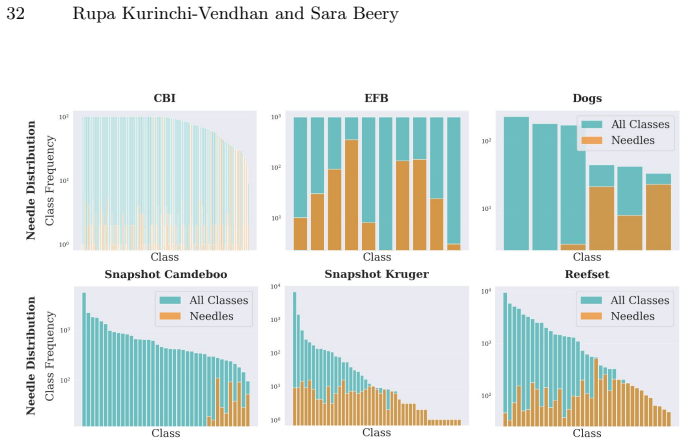
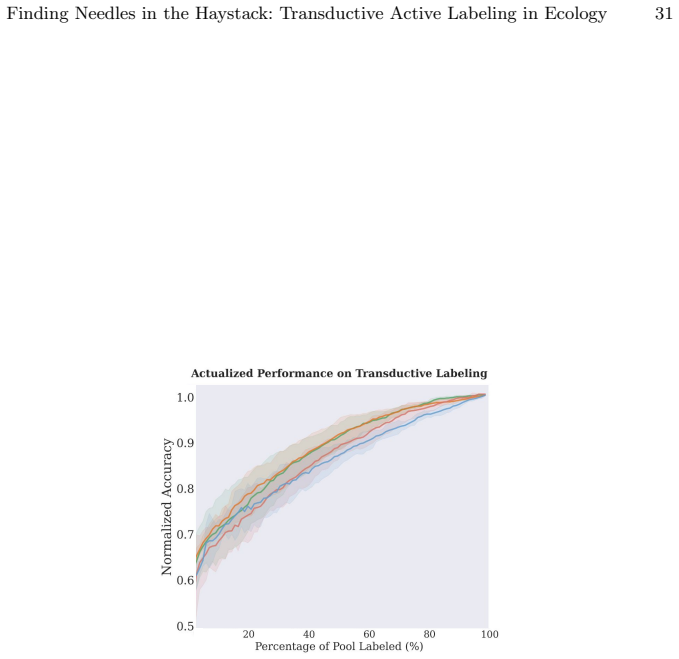
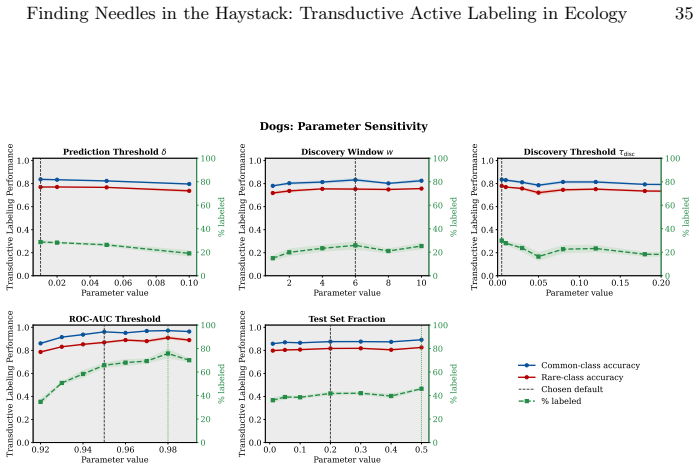
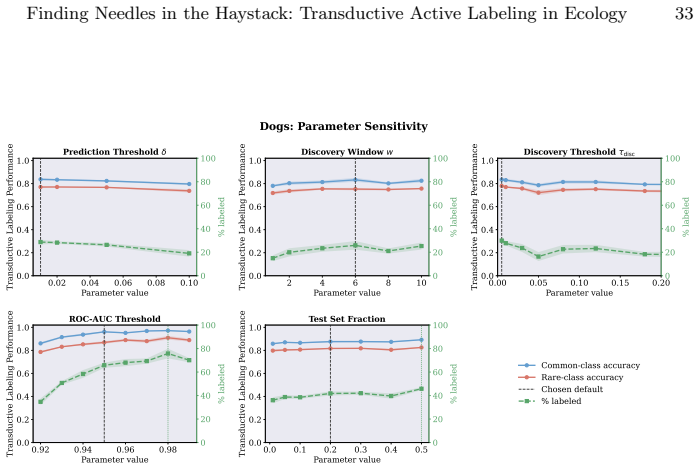
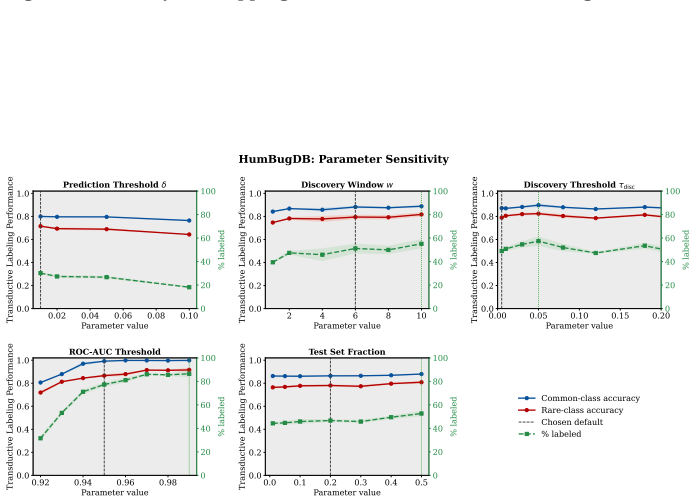
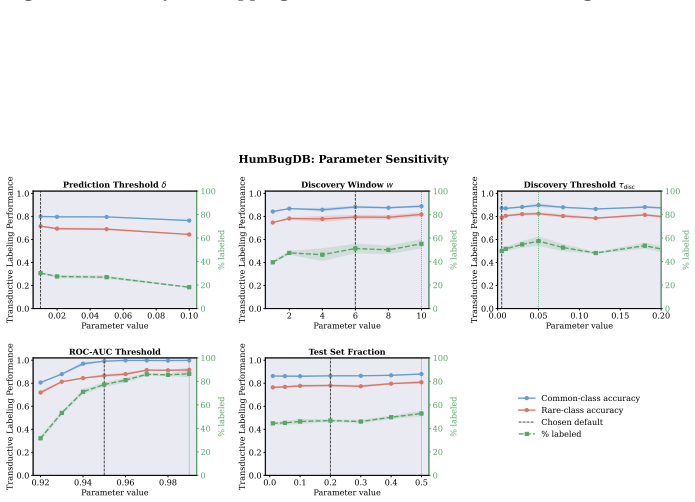
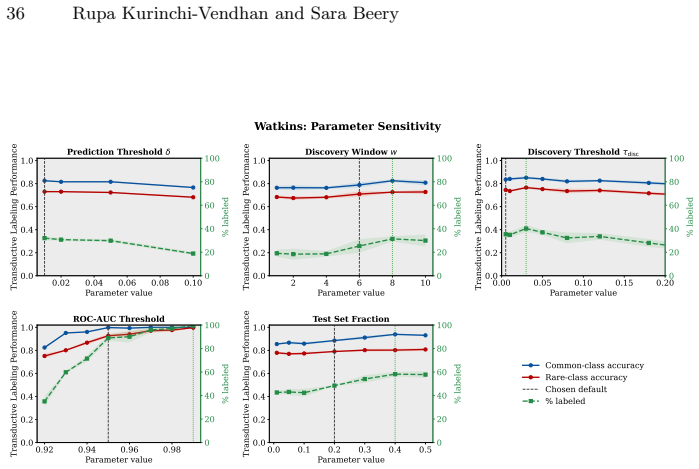
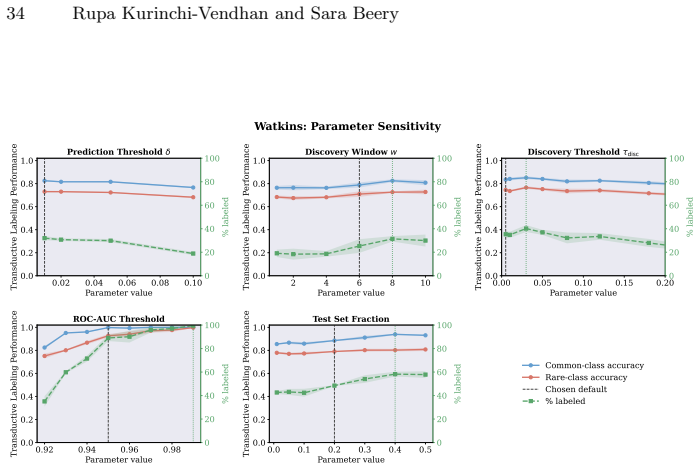
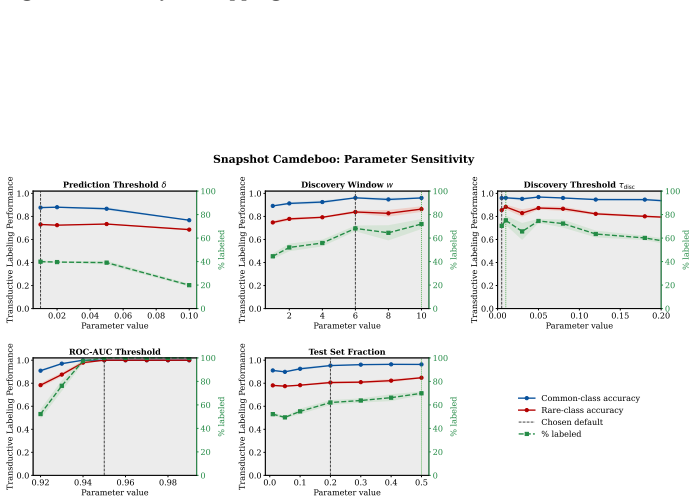
read the original abstract
Active learning is now standard practice in labeling ecological data, enabling ecologists to quickly process large volumes of field data to understand and monitor natural environments. Current practices evaluate active learning inductively, estimating predictive performance on a held-out test set. We argue that this evaluation is misaligned with most ecological tasks, where the goal is to transductively label an entire pool of data as efficiently as possible. We demonstrate that ignoring the human-in-the-loop underestimates the importance of continuing to label, particularly for classes in the long tail which may be of disproportionate ecological importance (rare species, uncommon behaviors, etc.). Our analysis shows that, for this long tail, the transductive objective shifts importance from prediction to discovery: the true challenge becomes finding "needles in the haystack," examples of rare classes that are embedded within dense regions of abundant classes in the latent geometry, which we quantify with a novel metric of sampling difficulty. Finally, to translate these insights to practical ecological workflows, we propose a conservative hybrid stopping criterion inspired by ecological rarefaction curves, and show that combining predictive performance with discovery criteria reduces premature stopping on long-tailed pools, improving rare-class recovery when discovery, not classification, is the limiting factor.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that active learning evaluation in ecology is misaligned when performed inductively on held-out test sets, because the true goal of most tasks is transductive labeling of an entire fixed pool of data. It claims that this misalignment causes underestimation of the value of continued labeling for long-tail classes, reframes the problem as discovery of rare examples embedded in dense regions of common classes (quantified via a novel sampling-difficulty metric), and proposes a conservative hybrid stopping criterion inspired by ecological rarefaction curves that combines predictive performance with discovery criteria to reduce premature stopping and improve rare-class recovery.
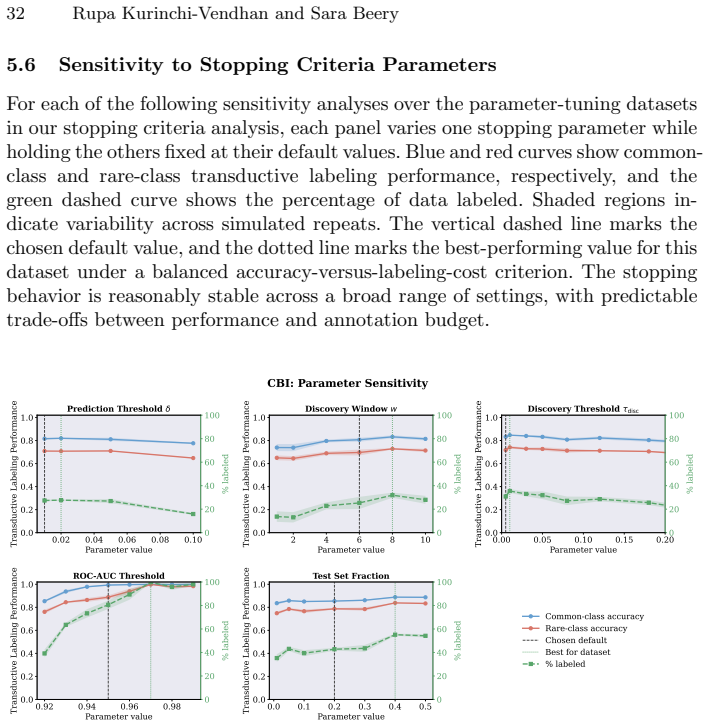
Significance. If the central premise about task objectives holds and the proposed hybrid criterion is shown to improve rare-class recovery, the work could usefully shift evaluation practices in ecological active learning toward discovery-oriented metrics. The conceptual emphasis on the human-in-the-loop and long-tail discovery is a strength, as is the attempt to import rarefaction ideas from ecology into stopping rules. However, the manuscript currently offers only a conceptual argument and metric proposal without quantitative results, error bars, or ablations, so its practical significance remains prospective.
major comments (3)
- [Abstract] Abstract (second sentence): the claim that 'the goal is to transductively label an entire pool of data as efficiently as possible' and that this is true for 'most ecological tasks' is presented without citations, case studies, or domain references establishing that exhaustive pool coverage (rather than building a deployable inductive classifier for ongoing monitoring) is the dominant objective. This premise is load-bearing for the misalignment argument, the shift to discovery, and the justification for the hybrid stopping rule.
- [Abstract] Abstract (final sentence): the statement that 'combining predictive performance with discovery criteria reduces premature stopping on long-tailed pools, improving rare-class recovery' is asserted, yet the provided text contains no quantitative results, ablation studies, error bars, or comparisons on real ecological data demonstrating this improvement. Without such evidence the empirical claim cannot be assessed.
- [Abstract] The novel metric of sampling difficulty is introduced to quantify the challenge of finding rare-class needles in dense common-class regions, but no derivation, formula, or validation against existing density or uncertainty measures is supplied in the visible text, leaving its added value over standard active-learning acquisition functions unverified.
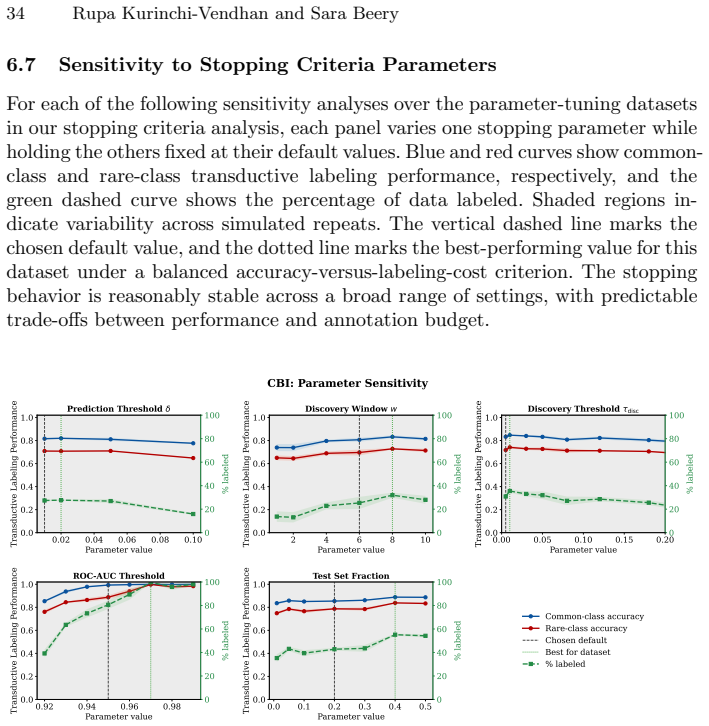
minor comments (1)
- [Abstract] The abstract refers to 'our analysis shows' and 'we propose' without indicating the corresponding sections or figures in the full manuscript where the metric, stopping rule, and any supporting experiments appear.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger empirical grounding and domain citations. We address each major comment below and outline planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract (second sentence): the claim that 'the goal is to transductively label an entire pool of data as efficiently as possible' and that this is true for 'most ecological tasks' is presented without citations, case studies, or domain references establishing that exhaustive pool coverage (rather than building a deployable inductive classifier for ongoing monitoring) is the dominant objective. This premise is load-bearing for the misalignment argument, the shift to discovery, and the justification for the hybrid stopping rule.
Authors: We agree that the transductive premise requires explicit support from the ecological literature. In revision we will add citations to biodiversity inventory studies and monitoring programs (e.g., species accumulation surveys and camera-trap datasets) where the explicit goal is exhaustive labeling of a fixed pool rather than training a generalizable classifier for future data. These references will be integrated into the introduction and abstract to strengthen the load-bearing claim. revision: yes
-
Referee: [Abstract] Abstract (final sentence): the statement that 'combining predictive performance with discovery criteria reduces premature stopping on long-tailed pools, improving rare-class recovery' is asserted, yet the provided text contains no quantitative results, ablation studies, error bars, or comparisons on real ecological data demonstrating this improvement. Without such evidence the empirical claim cannot be assessed.
Authors: The current manuscript is primarily conceptual and proposes the hybrid criterion without full-scale empirical validation. We accept that this is a limitation. In the revised version we will include experiments on real ecological datasets (e.g., camera-trap and acoustic monitoring collections) with ablations of the hybrid rule versus pure predictive stopping, reporting error bars across multiple runs and showing improved rare-class recovery rates. revision: yes
-
Referee: [Abstract] The novel metric of sampling difficulty is introduced to quantify the challenge of finding rare-class needles in dense common-class regions, but no derivation, formula, or validation against existing density or uncertainty measures is supplied in the visible text, leaving its added value over standard active-learning acquisition functions unverified.
Authors: The sampling-difficulty metric is defined in the methods section as a local-density ratio that captures the embedding of rare examples inside dense common-class regions. We will ensure the derivation, explicit formula, and direct comparisons to uncertainty sampling and density-based baselines are clearly presented with validation results in the revision so that its incremental value is verifiable. revision: yes
Circularity Check
No circularity: central claim is an explicit argument about task goals, not a derived prediction or self-referential definition.
full rationale
The paper's load-bearing premise—that most ecological labeling tasks aim at exhaustive transductive coverage of a fixed pool rather than inductive generalization—is stated directly in the abstract and introduction as an argument about evaluation alignment. No mathematical derivations, predictions, or first-principles results are presented that reduce to their own inputs by construction. There are no fitted parameters renamed as predictions, no self-definitional loops, no uniqueness theorems imported from the authors' prior work, and no ansatzes smuggled via self-citation. The proposed sampling-difficulty metric and hybrid stopping criterion are motivated by the stated premise but do not circularly derive from it or from any fitted values. The paper is self-contained as a position paper on evaluation practices; the absence of supporting citations for the premise is a question of evidence strength, not circularity in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Ecological labeling tasks aim to label the entire collected pool rather than generalize to future unseen data.
- domain assumption Rare classes are embedded within dense regions of abundant classes in the latent geometry.
invented entities (1)
-
novel metric of sampling difficulty
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jordan T Ash, Chicheng Zhang, Akshay Krishnamurthy, John Langford, and Alekh Agarwal. Deep batch active learning by diverse, uncertain gradient lower bounds.arXiv preprint arXiv:1906.03671,
-
[2]
A method for stopping active learning based on stabilizing predictions and the need for user-adjustable stopping
Michael Bloodgood and K Vijay-Shanker. A method for stopping active learning based on stabilizing predictions and the need for user-adjustable stopping. In Proceedings of the Thirteenth Conference on Computational Natural Language Learning (CoNLL-2009), pages 39–47,
2009
-
[3]
Perch 2.0 transfers ’whale’ to underwater tasks.arXiv preprint arXiv:2512.03219, 2025
Andrea Burns, Lauren Harrell, Bart van Merri¨ enboer, Vincent Dumoulin, Jenny Hamer, and Tom Denton. Perch 2.0 transfers ’whale’ to underwater tasks. arXiv preprint arXiv:2512.03219,
-
[4]
Beats: Audio pre-training with acoustic tokenizers,
Sanyuan Chen, Yu Wu, Chengyi Wang, Shujie Liu, Daniel Tompkins, Zhuo Chen, and Furu Wei. BEATs: Audio pre-training with acoustic tokenizers.arXiv preprint arXiv:2212.09058,
-
[5]
The search for squawk: Agile modeling in bioa- coustics.arXiv preprint arXiv:2505.03071, 2025
Vincent Dumoulin, Otilia Stretcu, Jenny Hamer, Lauren Harrell, Rob Laber, Hugo Larochelle, Bart van Merri¨ enboer, Amanda Navine, Patrick Hart, Ben Williams, et al. The search for squawk: Agile modeling in bioacoustics.arXiv preprint arXiv:2505.03071,
-
[6]
Zalan Fabian, Zhongqi Miao, Chunyuan Li, Yuanhan Zhang, Ziwei Liu, Andr´ es Hern´ andez, Andr´ es Montes-Rojas, Rafael Escucha, Laura Siabatto, Andr´ es Link, et al. Multimodal foundation models for zero-shot animal species recog- nition in camera trap images.arXiv preprint arXiv:2311.01064,
-
[7]
Using variance as a stopping criterion for active learning of frame assignment
Masood Ghayoomi. Using variance as a stopping criterion for active learning of frame assignment. InProceedings of the NAACL HLT 2010 Workshop on Active Learning for Natural Language Processing, pages 1–9,
2010
-
[8]
BEANS: The benchmark of animal sounds
Masato Hagiwara, Benjamin Hoffman, Jen-Yu Liu, Maddie Cusimano, Felix Ef- fenberger, and Katie Zacarian. BEANS: The benchmark of animal sounds. In ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE,
2023
-
[9]
Jenny Hamer, Eleni Triantafillou, Bart Van Merri¨ enboer, Stefan Kahl, Hol- ger Klinck, Tom Denton, and Vincent Dumoulin. BIRB: A generaliza- tion benchmark for information retrieval in bioacoustics.arXiv preprint arXiv:2312.07439,
-
[10]
HumBugDB: A large-scale acoustic mosquito dataset
Ivan Kiskin, Marianne Sinka, Adam D Cobb, Waqas Rafique, Lawrence Wang, Davide Zilli, Benjamin Gutteridge, Rinita Dam, Theodoros Marinos, Yunpeng Li, et al. HumBugDB: A large-scale acoustic mosquito dataset.arXiv preprint arXiv:2110.07607,
-
[11]
Hugo Markoff, Stefan Hein Bengtson, and Michael Ørsted. Vision transformers for zero-shot clustering of animal images: A comparative benchmarking study. arXiv preprint arXiv:2602.03894,
-
[12]
A comprehensive benchmark framework for active learning methods in entity matching
Venkata Vamsikrishna Meduri, Lucian Popa, Prithviraj Sen, and Mohamed Sar- wat. A comprehensive benchmark framework for active learning methods in entity matching. InProceedings of the 2020 ACM SIGMOD International Conference on Management of Data, pages 1133–1147,
2020
-
[13]
Lukas Rauch, Raphael Schwinger, Moritz Wirth, Ren´ e Heinrich, Denis Huseljic, Marek Herde, Jonas Lange, Stefan Kahl, Bernhard Sick, Sven Tomforde, et al. BirdSet: A large-scale dataset for audio classification in avian bioacoustics. arXiv preprint arXiv:2403.10380,
-
[14]
Evalua- tion methods for unsupervised word embeddings
Tobias Schnabel, Igor Labutov, David Mimno, and Thorsten Joachims. Evalua- tion methods for unsupervised word embeddings. InProceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 298– 307,
2015
-
[15]
Active Learning for Convolutional Neural Networks: A Core-Set Approach
Ozan Sener and Silvio Savarese. Active learning for convolutional neural net- works: A core-set approach.arXiv preprint arXiv:1708.00489,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Oriane Sim´ eoni, Huy V Vo, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha¨ el Ramamonjisoa, et al. DINOv3.arXiv preprint arXiv:2508.10104,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Perch 2.0: The bittern lesson for bioa- coustics.arXiv preprint arXiv:2508.04665, 2025
Bart van Merri¨ enboer, Vincent Dumoulin, Jenny Hamer, Lauren Harrell, Andrea Burns, and Tom Denton. Perch 2.0: The bittern lesson for bioacoustics.arXiv preprint arXiv:2508.04665,
-
[18]
Berry Weinstein, Shai Fine, and Yacov Hel-Or. Selective sampling for accel- erating training of deep neural networks.arXiv preprint arXiv:1911.06996,
-
[19]
Ben Williams, Bart Van Merri¨ enboer, Vincent Dumoulin, Jenny Hamer, Abram B Fleishman, Matthew McKown, Jill Munger, Aaron N Rice, Ashlee Lillis, Clemency White, et al. Using tropical reef, bird and unrelated sounds for superior transfer learning in marine bioacoustics.Philosophical Transactions of the Royal Society B: Biological Sciences, 380(1928),
1928
-
[20]
Active learn- ing with sampling by uncertainty and density for word sense disambiguation and text classification
Jingbo Zhu, Huizhen Wang, Tianshun Yao, and Benjamin K Tsou. Active learn- ing with sampling by uncertainty and density for word sense disambiguation and text classification. InProceedings of the 22nd International Conference on Computational Linguistics (COLING 2008), pages 1137–1144,
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.