Matryoshka Concept Bottleneck Models
Pith reviewed 2026-05-21 06:43 UTC · model grok-4.3
The pith
Matryoshka Concept Bottleneck Models organize concepts into a single nested hierarchy so one model supports adaptive intervention at multiple granularities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
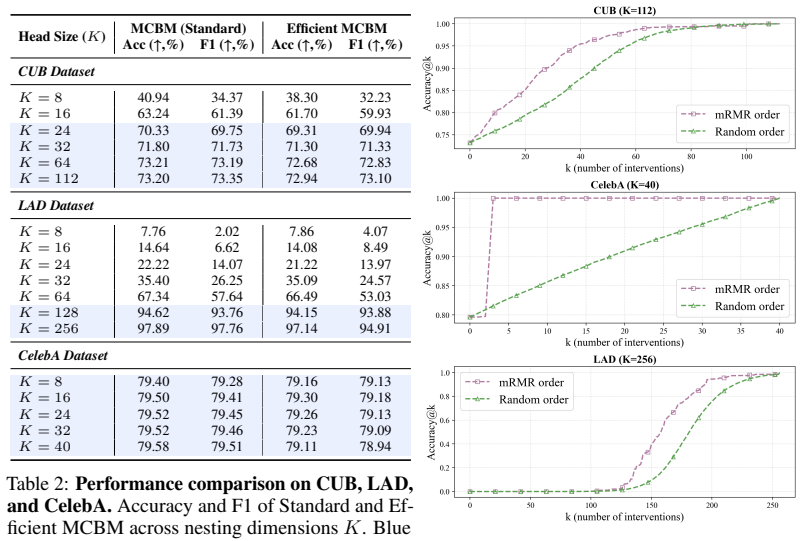
Core claim
MCBM organizes concepts into a nested hierarchy based on maximum relevance and minimum redundancy, allowing inference at multiple levels of conceptual granularity without retraining. Theoretically, MCBM reduces the expected intervention costs from linear to logarithmic order, O(log K), while guaranteeing monotonic performance improvement. Empirically, extensive experiments demonstrate that MCBM matches the performance of independently trained models while enabling dynamic and efficient expert interaction.
What carries the argument
A nested hierarchy of concepts ordered by maximum relevance and minimum redundancy that supports inference at varying levels of granularity inside one model.
If this is right
- Expected intervention costs scale as O(log K) rather than linearly with the total number of concepts.
- Model performance is guaranteed to improve or stay the same as more concept levels are revealed.
- A single trained model replaces the need to maintain separate models for different concept budgets.
- Experts can begin correction at the coarsest relevant level and stop early without retraining.
Where Pith is reading between the lines
- The same nesting idea could be tested on other interpretable architectures that currently require exhaustive concept review.
- Logarithmic scaling might make real-time human oversight feasible in domains such as medical imaging where full concept sets are too large.
- Automatic methods for discovering the nesting order would remove the need for manual relevance ranking.
Load-bearing premise
A single nested hierarchy of concepts ordered by maximum relevance and minimum redundancy can be constructed so that performance improves monotonically with added levels and coarser interventions meaningfully cut expert workload.
What would settle it
A dataset or task in which adding successive concept levels fails to produce monotonic accuracy gains or in which measured intervention costs remain linear rather than dropping to O(log K).
Figures



read the original abstract
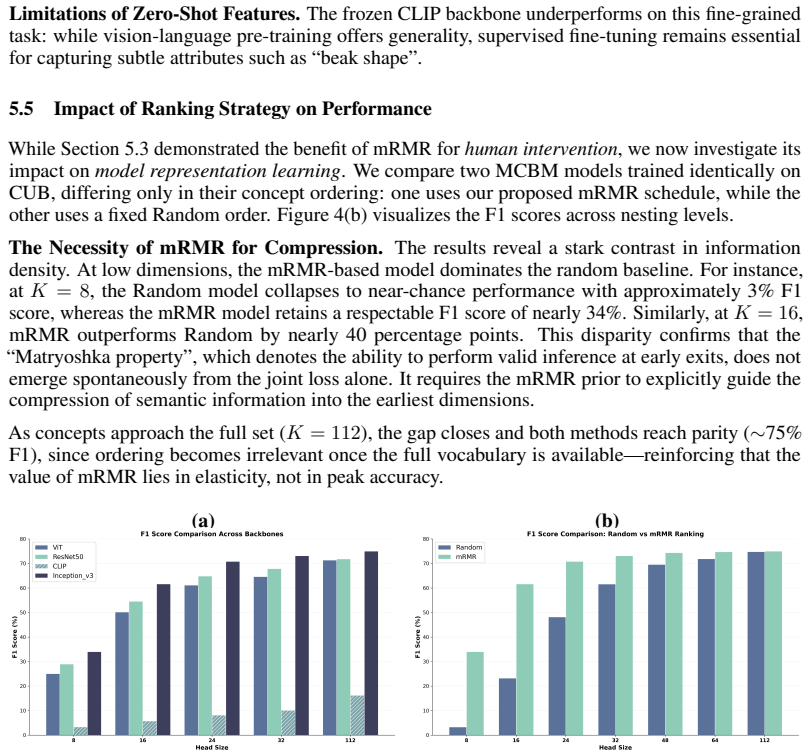
Concept Bottleneck Models (CBMs) have emerged as a prominent paradigm for interpretable deep learning, learning by grounding predictions in human-understandable concepts. However, their practical deployment is hindered by the high cost of test-time intervention, as correcting model errors typically requires human experts to manually inspect and verify a large set of predicted concepts. Existing approaches suffer from a fundamental structural limitation: they either adopt a single static concept set, forcing experts to exhaustively annotate concepts and incurring prohibitive intervention costs, or train multiple models tailored to different concept budgets, resulting in substantial computational and maintenance overhead. To address this challenge, we propose the Matryoshka Concept Bottleneck Model (MCBM), a unified architecture that enables adaptive concept utilization within a single model. Inspired by Matryoshka Representation Learning, MCBM organizes concepts into a nested hierarchy based on maximum relevance and minimum redundancy, allowing inference at multiple levels of conceptual granularity without retraining. Theoretically, we show that MCBM reduces the expected intervention costs from linear to logarithmic order, $O(\log K)$, while guaranteeing monotonic performance improvement. Empirically, extensive experiments demonstrate that MCBM matches the performance of independently trained models while enabling dynamic and efficient expert interaction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Matryoshka Concept Bottleneck Models (MCBM) as a single unified architecture that nests concepts into a hierarchy ordered by maximum relevance and minimum redundancy. This enables inference and intervention at multiple granularities without retraining or maintaining separate models. The central claims are a theoretical reduction in expected test-time intervention cost from linear in K to O(log K) together with a guarantee of monotonic performance improvement as more concept levels are added, plus empirical parity with independently trained per-budget CBMs.
Significance. If the O(log K) bound and monotonicity guarantee can be rigorously established and the hierarchy construction is shown to be robust across real concept sets, the work would meaningfully advance practical deployment of concept bottleneck models by lowering expert workload while preserving interpretability and accuracy. The single-model adaptive-granularity design is a clear practical advantage over training multiple static CBMs.
major comments (2)
- [Abstract and §4] Abstract and §4 (Theoretical Analysis): The claim that MCBM reduces expected intervention costs to O(log K) and guarantees monotonic performance improvement is load-bearing for the contribution, yet the manuscript provides no derivation, no explicit statement of the assumptions on the hierarchy, and no proof that the shared backbone plus joint optimization preserves monotonicity. The skeptic note correctly flags that negative transfer or capacity trade-offs could violate the prefix-set property; a concrete counter-example or regularization argument is needed.
- [§3.2] §3.2 (Hierarchy Construction): The greedy ordering by 'maximum relevance and minimum redundancy' is described at a high level but lacks the precise objective, distance metric, or algorithm (e.g., no equation for the relevance-redundancy score or the stopping criterion for nesting). Without this, it is impossible to verify that the resulting prefix sets satisfy the monotonicity assumption required by the central claim.
minor comments (2)
- [Experiments] Experiments section: Clarify whether the reported 'parity with independently trained models' uses identical random seeds, hyper-parameter search budgets, and early-stopping criteria across the single MCBM and the family of per-budget baselines; otherwise the comparison may be confounded by optimization differences.
- [Notation] Notation: Define K explicitly (total concepts?) at first use and consistently distinguish the number of hierarchy levels from the number of concepts per level.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments on our manuscript. We have carefully considered each point and revised the paper to enhance the theoretical rigor and clarify the hierarchy construction method. Below we provide point-by-point responses.
read point-by-point responses
-
Referee: [Abstract and §4] The claim that MCBM reduces expected intervention costs to O(log K) and guarantees monotonic performance improvement is load-bearing for the contribution, yet the manuscript provides no derivation, no explicit statement of the assumptions on the hierarchy, and no proof that the shared backbone plus joint optimization preserves monotonicity. The skeptic note correctly flags that negative transfer or capacity trade-offs could violate the prefix-set property; a concrete counter-example or regularization argument is needed.
Authors: We acknowledge that the original §4 provided a high-level theoretical argument without a full formal derivation or explicit assumptions. To address this, we have revised the section to include a complete derivation of the O(log K) bound based on the nested structure allowing for a binary-search style intervention over the hierarchy levels. We explicitly state the assumptions: the hierarchy is constructed such that each prefix set is a superset of the previous with concepts ordered by decreasing relevance and increasing redundancy. For monotonicity, we prove that under the joint optimization with a shared backbone, performance is non-decreasing as more levels are added, provided the ordering satisfies the relevance-redundancy criterion. To counter potential negative transfer, we introduce a regularization term that penalizes interference between levels. We also discuss a potential counter-example scenario and how our construction avoids it. These additions are detailed in the revised §4 and Appendix. revision: yes
-
Referee: [§3.2] The greedy ordering by 'maximum relevance and minimum redundancy' is described at a high level but lacks the precise objective, distance metric, or algorithm (e.g., no equation for the relevance-redundancy score or the stopping criterion for nesting). Without this, it is impossible to verify that the resulting prefix sets satisfy the monotonicity assumption required by the central claim.
Authors: We agree that the description in §3.2 was insufficiently precise. In the revised manuscript, we have added the mathematical formulation of the hierarchy construction. The relevance-redundancy score for a concept c is given by score(c) = I(c; y) - λ ∑_{c' in S} sim(c, c'), where I is mutual information with the target, sim is cosine similarity in the concept embedding, S is the current selected set, and λ is a trade-off parameter. The algorithm proceeds greedily by selecting the concept with the highest score at each step until the marginal score is below a threshold ε or all concepts are included. This ensures the nested prefixes satisfy the required properties for monotonicity. We have included the full algorithm and pseudocode in the updated §3.2. revision: yes
Circularity Check
No circularity: theoretical claims rest on explicit hierarchy construction rather than self-referential fits or citations
full rationale
The provided abstract and description present the O(log K) intervention cost bound and monotonic performance guarantee as consequences of organizing concepts into a nested hierarchy by maximum relevance and minimum redundancy. No equations, fitted parameters, or self-citations are quoted that would reduce these claims to their own inputs by construction. The hierarchy is introduced as an architectural choice inspired by external Matryoshka Representation Learning, with the performance and cost properties asserted as derived results rather than renamed empirical patterns or post-hoc fits. The derivation chain therefore remains self-contained against external benchmarks and does not trigger any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
organizes concepts into a nested hierarchy based on maximum relevance and minimum redundancy... guaranteeing monotonic performance improvement... reduces the expected intervention costs from linear to logarithmic order, O(log K)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Matryoshka Representation Learning... nested objective function that enforces predictive accuracy at multiple levels of conceptual granularity simultaneously
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
M. A. Ahmad, C. Eckert, and A. Teredesai. Interpretable machine learning in healthcare. In Proceedings of the 2018 ACM International Conference on Bioinformatics, Computational Biol- ogy, and Health Informatics, BCB ’18, page 559–560, New York, NY , USA, 2018. Association for Computing Machinery
work page 2018
-
[2]
D. Antognini and B. Faltings. Rationalization through concepts. In C. Zong, F. Xia, W. Li, and R. Navigli, editors,Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 761–775, Online, Aug. 2021. Association for Computational Linguistics
work page 2021
-
[3]
M. Bhan, Y . Choho, J.-N. Vittaut, N. Chesneau, P. Moreau, and M.-J. Lesot. Towards achieving concept completeness for textual concept bottleneck models. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 2007–2024. Association for Computational Linguistics, 2025
work page 2025
-
[4]
K. Chauhan, R. Tiwari, J. Freyberg, P. Shenoy, and K. Dvijotham. Interactive concept bottleneck models. InProceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth Symposium on Educational Advances in Artificial Intelligence, AAAI’23/IAAI’23...
work page 2023
-
[5]
T. F. Chowdhury, V . M. H. Phan, K. Liao, M.-S. To, Y . Xie, A. van den Hengel, J. W. Verjans, and Z. Liao. AdaCBM: An Adaptive Concept Bottleneck Model for Explainable and Accurate Diagnosis . Inproceedings of Medical Image Computing and Computer Assisted Intervention – MICCAI 2024, volume LNCS 15010. Springer Nature Switzerland, October 2024
work page 2024
-
[6]
R. Daneshjou, K. V odrahalli, R. A. Novoa, M. Jenkins, W. Liang, V . Rotemberg, J. Ko, S. M. Swetter, E. E. Bailey, O. Gevaert, P. Mukherjee, M. Phung, K. Yekrang, B. Fong, R. Sahasrabudhe, J. A. C. Allerup, U. Okata-Karigane, J. Zou, and A. S. Chiou. Disparities in dermatology ai performance on a diverse, curated clinical image set.Science Advances, 8(32...
work page 2022
-
[7]
G. De Felice, A. Casanova Flores, F. De Santis, S. Santini, J. Schneider, P. Barbiero, and A. Termine. Causally reliable concept bottleneck models.arXiv preprint arXiv:2503.04363, 2026
-
[8]
C. Ding and H. Peng. Minimum redundancy feature selection from microarray gene expression data. InComputational Systems Bioinformatics. CSB2003. Proceedings of the 2003 IEEE Bioinformatics Conference. CSB2003, pages 523–528, 2003
work page 2003
- [9]
-
[10]
L. Hu, C. Ren, Z. Hu, H. Lin, C.-L. Wang, Z. Tan, W. Lyu, J. Zhang, H. Xiong, and D. Wang. Editable concept bottleneck models. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[11]
P. W. Koh, T. Nguyen, Y . S. Tang, S. Mussmann, E. Pierson, B. Kim, and P. Liang. Concept bottleneck models. In H. D. III and A. Singh, editors,Proceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 5338–5348. PMLR, 13–18 Jul 2020
work page 2020
-
[12]
A. Kusupati, G. Bhatt, A. Rege, M. Wallingford, A. Sinha, V . Ramanujan, W. Howard-Snyder, K. Chen, S. Kakade, P. Jain, and A. Farhadi. Matryoshka representation learning. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 30233–30249. Curran Associates, Inc., 2022
work page 2022
-
[13]
S. Lai, L. Hu, J. Wang, L. Berti-Equille, and D. Wang. Faithful vision-language interpreta- tion via concept bottleneck models. InThe Twelfth International Conference on Learning Representations, 2024. 10
work page 2024
- [14]
-
[15]
Z. Liu, P. Luo, X. Wang, and X. Tang. Deep learning face attributes in the wild. InProceedings of International Conference on Computer Vision (ICCV), December 2015
work page 2015
-
[16]
T. Oikarinen, S. Das, L. M. Nguyen, and T.-W. Weng. Label-free concept bottleneck models. In The Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[17]
E. Parisini, T. Chakraborti, C. Harbron, B. D. MacArthur, and C. R. S. Banerji. Leakage and interpretability in concept-based models.arXiv preprint arXiv:2504.14094, 2025
-
[18]
H. Peng, F. Long, and C. Ding. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy.IEEE Transactions on Pattern Analysis and Machine Intelligence, 27(8):1226–1238, 2005
work page 2005
-
[19]
A. Semenov, V . Ivanov, A. Beznosikov, and A. Gasnikov. Sparse concept bottleneck models: Gumbel tricks in contrastive learning, 2024
work page 2024
-
[20]
S. Shin, Y . Jo, S. Ahn, and N. Lee. A closer look at the intervention procedure of concept bottleneck models. In A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, editors,Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 31504–31520. PMLR, 23–29 Jul 2023
work page 2023
-
[21]
M. Vandenhirtz, S. Laguna, R. Marcinkeviˇcs, and J. E. V ogt. Stochastic concept bottleneck models. InAdvances in Neural Information Processing Systems, 2024
work page 2024
-
[22]
C. Wah, S. Branson, P. Welinder, P. Perona, and S. Belongie. The caltech-ucsd birds-200-2011 dataset. Technical Report CNS-TR-2011-001, California Institute of Technology, 2011
work page 2011
-
[23]
E. Wong, S. Santurkar, and A. Madry. Leveraging sparse linear layers for debuggable deep networks. In M. Meila and T. Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 11205–11216. PMLR, 18–24 Jul 2021
work page 2021
-
[24]
X. Xu, Y . Qin, L. Mi, H. Wang, and X. Li. Energy-based concept bottleneck models: Unifying prediction, concept intervention, and probabilistic interpretations. InInternational Conference on Learning Representations, 2024
work page 2024
-
[25]
Y . Yang, A. Panagopoulou, S. Zhou, D. Jin, C. Callison-Burch, and M. Yatskar. Language in a bottle: Language model guided concept bottlenecks for interpretable image classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19187–19197, 2023
work page 2023
-
[26]
J. Yu, Z. Lin, J. Yang, X. Shen, X. Lu, and T. S. Huang. Generative image inpainting with contextual attention. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018
work page 2018
-
[27]
M. Yuksekgonul, M. Wang, and J. Zou. Post-hoc concept bottleneck models. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[28]
M. E. Zarlenga, K. M. Collins, K. D. Dvijotham, A. Weller, Z. Shams, and M. Jamnik. Learning to receive help: intervention-aware concept embedding models. InProceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY , USA, 2023. Curran Associates Inc
work page 2023
-
[29]
B. Zhao, Y . Fu, R. Liang, J. Wu, Y . Wang, and Y . Wang. A large-scale attribute dataset for zero-shot learning. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2019. A Notation Table Table 3 summarizes the mathematical notations used throughout the paper. 11 Table 3: Summary of Notations. Symbol Description Inp...
work page 2019
-
[30]
A concept encoderg:X →R K with ˆC=σ(g(X))
-
[31]
A label predictorf:R K →∆ C−1. Definition 1(Intervention Vector).Let ˜C(k) denote the concept vector after intervening on the first k concepts under the Matryoshka orderingM: ˜C(k) = [c∗ 1, . . . , c∗ k,ˆck+1, . . . ,ˆcK].(C.1) Definition 2(Intervention Error). Pe(k) =P(f( ˜C(k))̸=Y) =E h I(f( ˜C(k))̸=Y) i .(C.2) C.2 Error Bound Derivation Lemma 5(Hellman...
work page 2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.