Fast and effective algorithms for fair clustering at scale
Pith reviewed 2026-05-14 19:35 UTC · model grok-4.3
pith:FM357X3Y Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{FM357X3Y}
Prints a linked pith:FM357X3Y badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
Heuristics achieve scalable fair k-means clustering by enforcing group representation targets while minimizing sum of squared distances.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
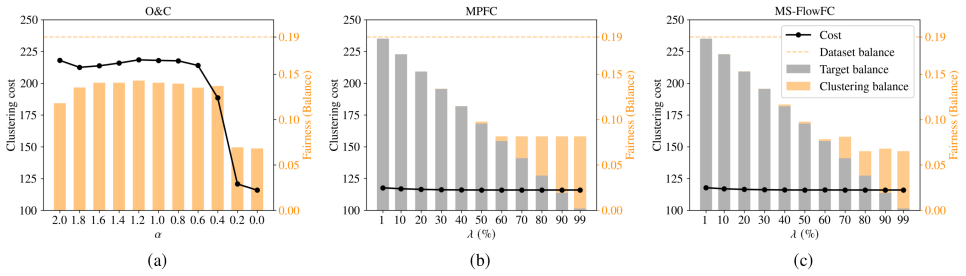
We propose a general framework for fair clustering that provides precise control over the cost-fairness trade-off and introduce three heuristics based on it. The first heuristic focuses on solution quality and the flexibility to incorporate additional constraints, the second improves scalability while retaining high solution quality, and the third is designed for maximum scalability, producing solutions for instances with millions of objects in seconds. The proposed heuristics outperform existing approaches in comprehensive numerical experiments on benchmark datasets.
What carries the argument
A general fair-clustering framework whose core mechanism adds explicit representation constraints for protected groups and solves the resulting trade-off via local-search or relaxation heuristics that adjust cluster assignments to meet fairness targets while reducing sum-of-squared-distance cost.
If this is right
- Users can set an exact target fairness level and obtain a clustering whose cost is competitive with unconstrained k-means.
- Datasets containing millions of points become practical for fair clustering because runtimes drop to seconds.
- The same framework supports additional side constraints without losing the ability to control the cost-fairness balance.
- Quality and scalability can be traded off by selecting among the three heuristics depending on data size.
Where Pith is reading between the lines
- The approach may transfer to other partitioning tasks such as facility location or community detection when group-balance requirements are added.
- In streaming or online settings the third heuristic could serve as a fast warm-start for incremental re-clustering under fairness rules.
- Empirical success on Euclidean data raises the question whether similar constraint-handling ideas work for non-Euclidean distances or kernelized clustering.
Load-bearing premise
That fairness constraints requiring minimum group representation in each cluster can be satisfied without destroying the geometric structure that makes the sum of squared distances a meaningful clustering objective.
What would settle it
On a moderate-sized benchmark instance whose globally optimal fair clustering solution is known by exhaustive search, the heuristics would return assignments whose total cost exceeds the optimum by more than a few percent or that violate the stated fairness targets.
Figures







read the original abstract
Clustering is an unsupervised machine learning task that consists of identifying groups of similar objects. It has numerous applications and is increasingly used in fairness-sensitive domains where objects represent individuals, such as customers, employees, or students. We address a fair clustering problem in which objects belong to protected groups. The problem consists of partitioning the objects into a predefined number of clusters while attaining a user-defined target level of fairness, meaning that each protected group is sufficiently represented in each cluster. The objective is to minimize the clustering cost, defined as the sum of squared Euclidean distances between the objects and the centers of their clusters. Since clustering cost and fairness are generally in conflict, managing the trade-off between them is essential in practical applications. Existing methods provide limited control over this trade-off and either fail to scale to large datasets or, when they scale, produce low-quality solutions. We propose a general framework for fair clustering that provides precise control over the cost-fairness trade-off and introduce three heuristics based on it. The first heuristic focuses on solution quality and the flexibility to incorporate additional constraints, the second improves scalability while retaining high solution quality, and the third is designed for maximum scalability, producing solutions for instances with millions of objects in seconds. The proposed heuristics outperform existing approaches in comprehensive numerical experiments on benchmark datasets. The source code of our heuristics and instructions for reproducing the experiments are publicly available on GitHub.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a general framework for fair k-means clustering that enforces a user-specified minimum representation of protected groups in each cluster while minimizing the sum of squared Euclidean distances to cluster centers. It proposes three heuristics (quality-focused local search, a scalable variant, and a maximum-scalability version) that are claimed to provide precise control over the cost-fairness trade-off, outperform prior methods on benchmark datasets, and scale to instances with millions of points in seconds, with publicly available code.
Significance. If the reported empirical dominance and scalability hold under rigorous validation, the framework and open-source implementation would offer a practical advance for deploying clustering in fairness-sensitive applications such as customer segmentation or educational grouping, where explicit trade-off control is needed.
major comments (2)
- [Experiments] The central claim of outperformance rests on the numerical experiments, yet the manuscript provides no statistical significance tests, no comparison against exact solvers on small instances, and no Pareto-front coverage metrics; this is load-bearing because the heuristics lack approximation guarantees and their local-search/repair steps have no proven bound on deviation from globally optimal trade-offs.
- [§4] The exact definition of the fairness metric, data-exclusion rules, and interaction between the fairness relaxation/repair steps and the squared-Euclidean objective are not fully specified, preventing verification that reported wins are not artifacts of favorable instance selection or local-optima bias.
minor comments (1)
- [Framework] Notation for the fairness target parameter and the precise form of the relaxed objective could be clarified with an explicit equation in the framework section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below and will revise the manuscript to incorporate the suggested improvements for stronger empirical validation and clarity.
read point-by-point responses
-
Referee: [Experiments] The central claim of outperformance rests on the numerical experiments, yet the manuscript provides no statistical significance tests, no comparison against exact solvers on small instances, and no Pareto-front coverage metrics; this is load-bearing because the heuristics lack approximation guarantees and their local-search/repair steps have no proven bound on deviation from globally optimal trade-offs.
Authors: We agree that statistical significance tests, comparisons to exact solvers on small instances, and Pareto-front coverage metrics would strengthen the presentation. In the revised manuscript we will add Wilcoxon signed-rank tests (or paired t-tests where appropriate) across repeated runs and datasets to assess significance of the reported improvements. We will also include a new subsection with experiments on small instances (n ≤ 500) solved to optimality via an ILP formulation using a commercial solver, reporting optimality gaps for our heuristics. Finally, we will report Pareto-front coverage metrics such as the fraction of the cost-fairness curve dominated by each method. While the heuristics are not accompanied by approximation guarantees, the new experiments will provide direct evidence of their practical performance relative to optima on small cases and will be discussed explicitly in the text. revision: yes
-
Referee: [§4] The exact definition of the fairness metric, data-exclusion rules, and interaction between the fairness relaxation/repair steps and the squared-Euclidean objective are not fully specified, preventing verification that reported wins are not artifacts of favorable instance selection or local-optima bias.
Authors: We apologize for the insufficient detail in §4. In the revision we will provide a complete mathematical definition of the fairness metric (including the precise minimum-representation thresholds per group and cluster), explicitly list all data-exclusion or preprocessing rules applied to the benchmark datasets, and add a formal description (with pseudocode) of how the relaxation and repair steps interact with the squared-Euclidean objective. These additions will enable independent verification and will clarify that the reported results are not driven by instance selection or local-optima artifacts. revision: yes
Circularity Check
No circularity: framework and heuristics are defined independently of results
full rationale
The paper introduces a fair clustering framework parameterized by an explicit user-supplied fairness target and the standard k-means objective (sum of squared Euclidean distances). The three heuristics are constructed via local-search, relaxation, and repair steps whose definitions do not presuppose the claimed performance outcomes. No equation or claim reduces a derived quantity to a fitted parameter or self-citation by construction. Self-citations, if present, are not load-bearing for the central algorithmic definitions or the empirical comparison. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Euclidean distance is an appropriate measure of dissimilarity for the objects being clustered.
- domain assumption The fairness requirement can be expressed as a set of linear or convex constraints on cluster membership proportions.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The assignment step is formulated as a binary linear program (BLP) that includes fairness constraints... controlled by a single tolerance parameter
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
multi-stage minimum-cost flow-based fair clustering (MS-FlowFC)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Applied Soft Computing , volume=
Credit rating by hybrid machine learning techniques , author=. Applied Soft Computing , volume=. 2010 , publisher=
work page 2010
-
[2]
Journal of the Operational Research Society , volume=
Identification of credit risk based on cluster analysis of account behaviours , author=. Journal of the Operational Research Society , volume=. 2020 , publisher=
work page 2020
-
[3]
Socio-Economic Planning Sciences , volume=
Cluster Analysis for mixed data: An application to credit risk evaluation , author=. Socio-Economic Planning Sciences , volume=. 2021 , publisher=
work page 2021
-
[4]
Expert Systems with Applications , volume=
Credit risk evaluation using clustering based fuzzy classification method , author=. Expert Systems with Applications , volume=. 2023 , publisher=
work page 2023
-
[5]
Journal of Mathematics , volume=
Optimization of Human Resource Performance Management System Based on Improved R-Means Clustering Algorithm , author=. Journal of Mathematics , volume=. 2022 , publisher=
work page 2022
-
[6]
International Journal of Computer Applications , volume=
Applicability of clustering and classification algorithms for recruitment data mining , author=. International Journal of Computer Applications , volume=. 2010 , doi=
work page 2010
-
[7]
International Journal of Computer Applications , volume=
Cluster based ranking index for enhancing recruitment process using text mining and machine learning , author=. International Journal of Computer Applications , volume=. 2017 , publisher=
work page 2017
-
[8]
Clustering analysis for classifying student academic performance in higher education , author=. Applied Sciences , volume=. 2022 , publisher=
work page 2022
-
[9]
A review of clustering models in educational data science toward fairness-aware learning , author=. Educational Data Science: Essentials, Approaches, and Tendencies: Proactive Education based on Empirical Big Data Evidence , pages=. 2023 , publisher=
work page 2023
-
[10]
Clustering of students admission data using k-means, hierarchical, and
Cahapin, Erwin Lanceta and Malabag, Beverly Ambagan and Santiago Jr, Cereneo Sailog and Reyes, Jocelyn L and Legaspi, Gemma S and Adrales, Karl Louise , journal=. Clustering of students admission data using k-means, hierarchical, and. 2023 , doi=
work page 2023
-
[11]
arXiv preprint arXiv:2407.11199 , year=
Algorithms for college admissions decision support: Impacts of policy change and inherent variability , author=. arXiv preprint arXiv:2407.11199 , year=
-
[12]
An overview of fairness in clustering , author=. IEEE Access , volume=. 2021 , publisher=
work page 2021
-
[13]
Advances in Neural Information Processing Systems , volume=
Fair clustering through fairlets , author=. Advances in Neural Information Processing Systems , volume=. 2017 , doi=
work page 2017
-
[14]
Advances in Neural Information Processing Systems , volume=
Fair clustering under a bounded cost , author=. Advances in Neural Information Processing Systems , volume=. 2021 , doi=
work page 2021
-
[15]
arXiv preprint arXiv:1910.05113 , year=
Fairness in clustering with multiple sensitive attributes , author=. arXiv preprint arXiv:1910.05113 , year=
-
[16]
European Journal of Operational Research , volume=
A mixed-integer programming approach to the clustering problem with an application in customer segmentation , author=. European Journal of Operational Research , volume=. 2006 , publisher=
work page 2006
-
[17]
European Journal of Operational Research , volume=
Heuristic search to the capacitated clustering problem , author=. European Journal of Operational Research , volume=. 2019 , publisher=
work page 2019
-
[18]
Fleszar, Krzysztof and Hindi, Khalil S , journal=. An effective. 2008 , publisher=
work page 2008
-
[19]
Computational Optimization and Applications , pages=
A mathematical programming approach to hierarchical clustering , author=. Computational Optimization and Applications , pages=. 2026 , publisher=
work page 2026
-
[20]
Handbook of Big Data Analytics and Forensics , pages=
Evaluating performance of scalable fair clustering machine learning techniques in detecting cyber attacks in industrial control systems , author=. Handbook of Big Data Analytics and Forensics , pages=. 2022 , publisher=
work page 2022
-
[21]
Handbook of Big Data Analytics and Forensics , pages=
Evaluation of scalable fair clustering machine learning methods for threat hunting in cyber-physical systems , author=. Handbook of Big Data Analytics and Forensics , pages=. 2022 , publisher=
work page 2022
-
[22]
Handbook of Big Data Analytics and Forensics , pages=
Scalable fair clustering algorithm for Internet of Things malware classification , author=. Handbook of Big Data Analytics and Forensics , pages=. 2022 , publisher=
work page 2022
-
[23]
Handbook of Big Data Analytics and Forensics , pages=
Security of industrial cyberspace: Fair clustering with linear time approximation , author=. Handbook of Big Data Analytics and Forensics , pages=. 2022 , publisher=
work page 2022
-
[24]
International Conference on Machine Learning , pages=
Scalable fair clustering , author=. International Conference on Machine Learning , pages=. 2019 , organization=
work page 2019
-
[25]
International Workshop on Approximation and Online Algorithms , pages=
Fair coresets and streaming algorithms for fair k-means , author=. International Workshop on Approximation and Online Algorithms , pages=. 2019 , organization=
work page 2019
-
[26]
Advances in Neural Information Processing Systems , volume=
Coresets for clustering with fairness constraints , author=. Advances in Neural Information Processing Systems , volume=. 2019 , doi=
work page 2019
-
[27]
On coresets for fair clustering in metric and
Bandyapadhyay, Sayan and Fomin, Fedor V and Simonov, Kirill , journal=. On coresets for fair clustering in metric and. 2024 , publisher=
work page 2024
-
[28]
Privacy preserving clustering with constraints
Privacy preserving clustering with constraints , author=. arXiv preprint arXiv:1802.02497 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
On the cost of essentially fair clusterings
On the cost of essentially fair clusterings , author=. arXiv preprint arXiv:1811.10319 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Advances in Neural Information Processing Systems , volume=
Fair algorithms for clustering , author=. Advances in Neural Information Processing Systems , volume=. 2019 , doi=
work page 2019
-
[31]
Clustering without over-representation , author=. Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages=. 2019 , doi=
work page 2019
-
[32]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Variational fair clustering , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=. 2021 , doi=
work page 2021
-
[33]
International Conference on Learning and Intelligent Optimization , pages=
A stochastic alternating balance k-means algorithm for fair clustering , author=. International Conference on Learning and Intelligent Optimization , pages=. 2022 , organization=
work page 2022
-
[34]
INFORMS Journal on Data Science , volume=
An Optimization-Based Order-and-Cut Approach for Fair Clustering of Data Sets , author=. INFORMS Journal on Data Science , volume=. 2024 , publisher=
work page 2024
-
[35]
Advances in Neural Information Processing Systems , volume=
The Fairness-Quality Tradeoff in Clustering , author=. Advances in Neural Information Processing Systems , volume=. 2024 , doi=
work page 2024
-
[36]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Towards fairer centroids in k-means clustering , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=. 2024 , doi=
work page 2024
-
[37]
arXiv preprint arXiv:2104.12116 , year=
Fair-capacitated clustering , author=. arXiv preprint arXiv:2104.12116 , year=
-
[38]
Tran, Vanessa and Kammermann, Manuel and Baumann, Philipp , booktitle=. The. 2023 , organization=
work page 2023
-
[39]
Lloyd, Stuart , journal=. Least squares quantization in. 1982 , publisher=
work page 1982
-
[40]
arXiv preprint arXiv:2409.02963 , year=
Fair minimum representation clustering via integer programming , author=. arXiv preprint arXiv:2409.02963 , year=
-
[41]
Proceedings of the 18th Annual ACM-SIAM Symposium on Discrete Algorithms , volume=
k-means++: The advantages of careful seeding , author=. Proceedings of the 18th Annual ACM-SIAM Symposium on Discrete Algorithms , volume=. 2007 , doi=
work page 2007
-
[42]
Piccialli, Veronica and Sudoso, Antonio M and Wiegele, Angelika , journal=. 2022 , publisher=
work page 2022
- [43]
-
[44]
Kelly, Markelle and Longjohn, Rachel and Nottingham, Kolby , year=
-
[45]
A Dataset to Support Research in the Design of Secure Water Treatment Systems , doi=
Goh, Jonathan and Adepu, Sridhar and Junejo, Khurum and Mathur, Aditya , year=. A Dataset to Support Research in the Design of Secure Water Treatment Systems , doi=
- [46]
- [47]
- [48]
- [49]
-
[50]
Meek, Chris and Thiesson, Bo and Heckerman, David , title=. 2001 , howpublished=
work page 2001
-
[51]
Certifying and removing disparate impact , author=. Proceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages=. 2015 , doi=
work page 2015
-
[52]
Aloise, Daniel and Deshpande, Amit and Hansen, Pierre and Popat, Preyas , journal=. 2009 , publisher=
work page 2009
-
[53]
INFORMS Journal on Computing , volume=
An algorithm for clustering with confidence-based must-link and cannot-link constraints , author=. INFORMS Journal on Computing , volume=. 2025 , publisher=
work page 2025
-
[54]
A binary linear programming-based k-means approach for the capacitated centered clustering problem , author=. 2019 IEEE International Conference on Industrial Engineering and Engineering Management (IEEM) , pages=. 2019 , organization=
work page 2019
-
[55]
International Conference on Machine Learning , pages=
Fair k-center clustering for data summarization , author=. International Conference on Machine Learning , pages=. 2019 , organization=
work page 2019
-
[56]
A binary linear programming-based k-means algorithm for clustering with must-link and cannot-link constraints , author=. 2020 IEEE international conference on industrial engineering and engineering management (IEEM) , pages=. 2020 , organization=
work page 2020
-
[57]
Douze, Matthijs and Guzhva, Alexandr and Deng, Chengqi and Johnson, Jeff and Szilvasy, Gergely and Mazaré, Pierre-Emmanuel and Lomeli, Maria and Hosseini, Lucas and Jégou, Hervé , journal=. The. 2026 , volume=
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.