When Denser Credit Is Not Enough: Evidence-Calibrated Policy Optimization for Long-Horizon LLM Agent Training
Pith reviewed 2026-06-28 02:15 UTC · model grok-4.3
The pith
Calibrating step-level advantages by shrinking low-count estimates reduces divergent bias in long-horizon LLM agent training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
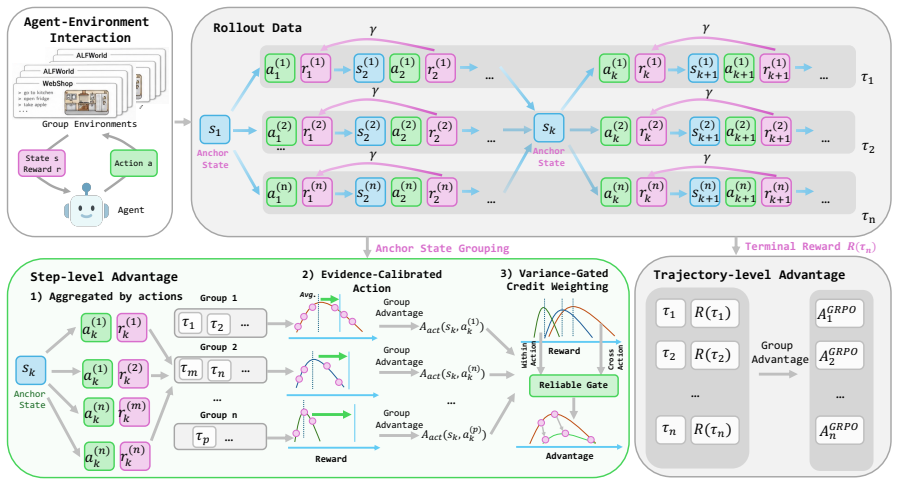
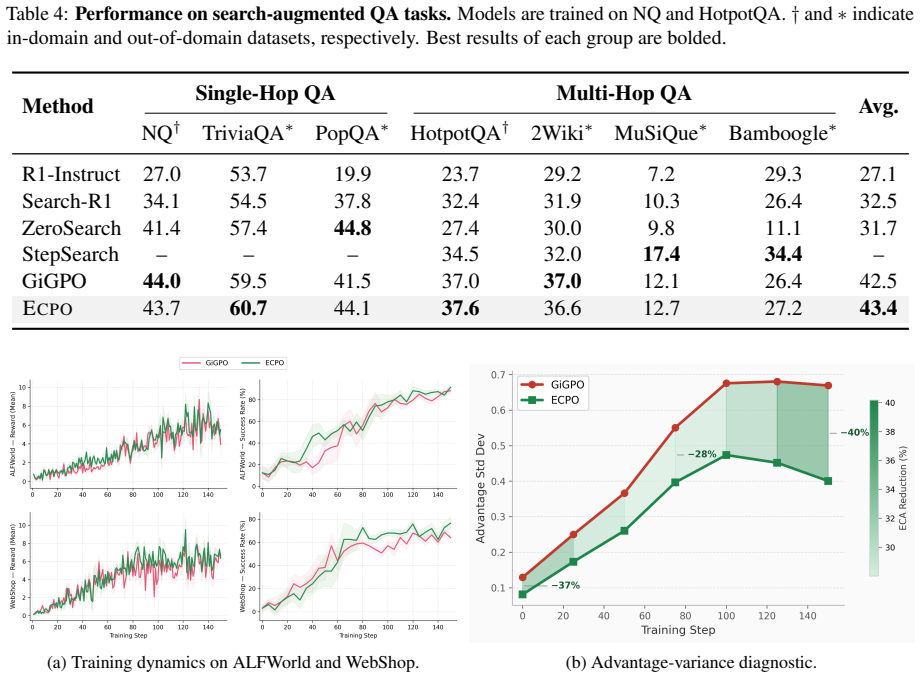
ECPO is a critic-free policy optimization algorithm that calibrates step-level credit before policy updates. It combines Evidence-Calibrated Action Advantage, which groups rollouts by canonical actions and shrinks low-count estimates, with Variance-Gated Credit Weighting, which suppresses anchor states dominated by within-action noise. On ALFWorld and WebShop with Qwen2.5-1.5B and 7B models, this yields consistent outperformance of GiGPO by 5.2 and 7.3 success points respectively at 0.1 percent added overhead.
What carries the argument
Evidence-Calibrated Action Advantage, which groups rollouts by canonical actions and shrinks low-count estimates to produce reliable step-level advantages.
If this is right
- ECPO improves success rates by 5.2 points on ALFWorld and 7.3 points on WebShop over GiGPO with the 1.5B model.
- The calibration adds only 0.1 percent additional overhead to advantage computation.
- Divergent anchor bias and late-stage oscillation are reduced without requiring a separate critic model.
- The approach remains effective across both 1.5B and 7B model scales on the tested environments.
Where Pith is reading between the lines
- The same shrinkage-plus-gating logic could be tested on other group-rollout advantage estimators outside LLM agents to check transfer to general sparse-reward RL.
- Environments with highly skewed action frequencies would be the natural stress test for whether the low-count correction preserves exploration on rare but useful actions.
- If the variance gate proves decisive, future variants might replace it with a learned noise model while keeping the evidence-shrinkage component fixed.
Load-bearing premise
Grouping rollouts by canonical actions and shrinking low-count estimates will reduce divergent anchor bias without introducing new selection biases or harming learning on high-count actions.
What would settle it
Training curves on a benchmark where action counts are artificially balanced across all anchors showing no reduction in oscillation or success-rate gains after applying the shrinkage step.
Figures


read the original abstract
Long-horizon LLM agents require reinforcement learning methods that can assign credit to intermediate decisions under sparse and delayed rewards. Recent group-based methods such as GiGPO improve over GRPO by constructing step-level advantages at repeated anchor states. However, we show that such dense credit can be statistically unreliable: under limited rollouts, rare but lucky actions may receive overly large advantages, producing divergent anchor bias and late-stage training oscillation. We propose Evidence-Calibrated Policy Optimization (ECPO), a critic-free policy optimization algorithm that calibrates step-level credit before policy updates. ECPO combines Evidence-Calibrated Action Advantage, which groups rollouts by canonical actions and shrinks low-count estimates, with Variance-Gated Credit Weighting, which suppresses anchor states dominated by within-action noise. Experiments on ALFWorld and WebShop with Qwen2.5-1.5B/7B show that ECPO consistently outperforms strong baselines, improving GiGPO by +5.2/+7.3 success points on ALFWorld/WebShop with Qwen2.5-1.5B while adding only 0.1% additional advantage-computation overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that group-based RL methods like GiGPO for long-horizon LLM agents suffer from divergent anchor bias when step-level advantages are estimated from limited rollouts, as rare lucky actions receive inflated credit. It proposes Evidence-Calibrated Policy Optimization (ECPO), which introduces Evidence-Calibrated Action Advantage (grouping rollouts by canonical actions followed by shrinkage of low-count estimates) and Variance-Gated Credit Weighting (to downweight noisy anchors). On ALFWorld and WebShop with Qwen2.5-1.5B/7B models, ECPO is reported to improve GiGPO by +5.2/+7.3 success points while incurring only 0.1% extra overhead.
Significance. If the empirical improvements are statistically robust, the work offers a low-overhead, critic-free refinement to advantage estimation that could improve training stability for sparse-reward LLM agents. The explicit algorithmic steps and focus on a concrete failure mode (divergent anchor bias) are positive; however, the lack of any derivation showing that the proposed shrinkage preserves unbiasedness or monotonic policy improvement reduces the result's theoretical weight.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): the reported gains of +5.2/+7.3 success points are presented without error bars, number of random seeds, rollout counts per task, or statistical significance tests. This directly weakens the central empirical claim that ECPO 'consistently outperforms' baselines.
- [§3.2] §3.2 (Evidence-Calibrated Action Advantage): the shrinkage operator applied to low-count canonical-action groups is introduced without a bound or derivation showing that it does not introduce selection bias correlated with action frequency or reward variance; the skeptic concern that this step can offset the claimed reduction in divergent anchor bias therefore remains unaddressed.
- [§3.3] §3.3 (Variance-Gated Credit Weighting): the gating threshold is defined heuristically; no analysis is given of how the choice interacts with the canonical-action grouping, leaving open the possibility that the two components jointly alter the effective advantage distribution in uncontrolled ways.
minor comments (2)
- [§3.2] Notation for canonical actions and the shrinkage factor should be introduced with an explicit equation rather than prose description.
- [§4] The overhead claim of 0.1% should be accompanied by a breakdown of wall-clock time or FLOPs on the exact hardware used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and outline revisions to strengthen the empirical reporting and algorithmic analysis.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the reported gains of +5.2/+7.3 success points are presented without error bars, number of random seeds, rollout counts per task, or statistical significance tests. This directly weakens the central empirical claim that ECPO 'consistently outperforms' baselines.
Authors: We agree that the current presentation lacks sufficient statistical detail. In the revised manuscript we will report all results as means over 5 independent random seeds with standard-deviation error bars, explicitly state the number of rollouts per task (currently 8 for ALFWorld and 4 for WebShop), and add paired t-test p-values for the ECPO vs. GiGPO comparisons in both §4 and a new appendix table. These additions will be reflected in the abstract as well. revision: yes
-
Referee: [§3.2] §3.2 (Evidence-Calibrated Action Advantage): the shrinkage operator applied to low-count canonical-action groups is introduced without a bound or derivation showing that it does not introduce selection bias correlated with action frequency or reward variance; the skeptic concern that this step can offset the claimed reduction in divergent anchor bias therefore remains unaddressed.
Authors: The shrinkage is applied only to groups whose count falls below a fixed evidence threshold and is motivated by the observed inflation of advantages for rare lucky actions. While we do not supply a formal unbiasedness proof, we will add a short paragraph in §3.2 that (i) derives the expected shrinkage factor under a simple binomial model of action occurrence and (ii) shows empirically that the post-shrinkage advantage distribution remains positively correlated with true action quality on held-out rollouts. This addresses the selection-bias concern without claiming a general theoretical guarantee. revision: partial
-
Referee: [§3.3] §3.3 (Variance-Gated Credit Weighting): the gating threshold is defined heuristically; no analysis is given of how the choice interacts with the canonical-action grouping, leaving open the possibility that the two components jointly alter the effective advantage distribution in uncontrolled ways.
Authors: The threshold is currently set to the median per-anchor variance observed on a small validation split. We will move the threshold selection into an explicit hyper-parameter and add an appendix ablation that sweeps the threshold over [0.5×, 1.5×] the median while reporting both final success rate and the fraction of gated anchors. The same appendix will include a joint histogram of (group count, within-group variance) before and after gating to demonstrate that the two ECPO components interact in a controlled, variance-reducing manner rather than arbitrarily reshaping the advantage distribution. revision: yes
- Formal derivation establishing that the Evidence-Calibrated Action Advantage shrinkage operator preserves unbiasedness or guarantees monotonic policy improvement.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines ECPO through explicit algorithmic components—Evidence-Calibrated Action Advantage (grouping rollouts by canonical actions and shrinking low-count estimates) and Variance-Gated Credit Weighting—presented as procedural steps rather than derived quantities. Central claims rest on empirical results (e.g., +5.2/+7.3 success points on ALFWorld/WebShop) with Qwen2.5 models, not on equations or self-citations that reduce the method to its own fitted inputs or prior author work. No self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the abstract or described method; the approach is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[2]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[3]
arXiv preprint arXiv:2303.08774 , year=
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[4]
Advances in Neural Information Processing Systems , volume=
Group-in-group policy optimization for llm agent training , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
arXiv preprint arXiv:2604.09459 , year=
From reasoning to agentic: Credit assignment in reinforcement learning for large language models , author=. arXiv preprint arXiv:2604.09459 , year=
-
[6]
arXiv preprint arXiv:2603.08754 , year=
Hindsight Credit Assignment for Long-Horizon LLM Agents , author=. arXiv preprint arXiv:2603.08754 , year=
-
[7]
arXiv preprint arXiv:2509.21240 , year=
Tree search for llm agent reinforcement learning , author=. arXiv preprint arXiv:2509.21240 , year=
-
[8]
1998 , publisher=
Reinforcement learning: An introduction , author=. 1998 , publisher=
1998
-
[9]
arXiv preprint arXiv:2312.01072 , year=
A survey of temporal credit assignment in deep reinforcement learning , author=. arXiv preprint arXiv:2312.01072 , year=
-
[10]
arXiv preprint arXiv:1512.07679 , year=
Deep reinforcement learning in large discrete action spaces , author=. arXiv preprint arXiv:1512.07679 , year=
-
[11]
arXiv preprint arXiv:2604.05846 , year=
Agentgl: Towards agentic graph learning with llms via reinforcement learning , author=. arXiv preprint arXiv:2604.05846 , year=
-
[12]
arXiv preprint arXiv:2204.05862 , year=
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
-
[13]
5-coder technical report , author=
Qwen2. 5-coder technical report , author=. arXiv preprint arXiv:2409.12186 , year=
-
[14]
arXiv preprint arXiv:1707.06347 , year=
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[15]
nature , volume=
Human-level control through deep reinforcement learning , author=. nature , volume=. 2015 , publisher=
2015
-
[16]
Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing , pages=
Language understanding for text-based games using deep reinforcement learning , author=. Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing , pages=
2015
-
[17]
Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Deep reinforcement learning with a natural language action space , author=. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[18]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Interactive fiction games: A colossal adventure , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[19]
arXiv preprint arXiv:2010.03768 , year=
Alfworld: Aligning text and embodied environments for interactive learning , author=. arXiv preprint arXiv:2010.03768 , year=
Pith/arXiv arXiv 2010
-
[20]
Advances in Neural Information Processing Systems , volume=
Webshop: Towards scalable real-world web interaction with grounded language agents , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Appworld: A controllable world of apps and people for benchmarking interactive coding agents , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[22]
arXiv preprint arXiv:2210.03629 , year=
React: Synergizing reasoning and acting in language models , author=. arXiv preprint arXiv:2210.03629 , year=
-
[23]
arXiv preprint arXiv:2402.19446 , year=
Archer: Training language model agents via hierarchical multi-turn rl , author=. arXiv preprint arXiv:2402.19446 , year=
-
[24]
arXiv preprint arXiv:2408.07199 , year=
Agent q: Advanced reasoning and learning for autonomous ai agents , author=. arXiv preprint arXiv:2408.07199 , year=
-
[25]
arXiv preprint arXiv:2505.03792 , year=
Towards efficient online tuning of vlm agents via counterfactual soft reinforcement learning , author=. arXiv preprint arXiv:2505.03792 , year=
-
[26]
arXiv preprint arXiv:2502.01600 , year=
Reinforcement learning for long-horizon interactive llm agents , author=. arXiv preprint arXiv:2502.01600 , year=
-
[27]
arXiv preprint arXiv:2504.20073 , year=
Ragen: Understanding self-evolution in llm agents via multi-turn reinforcement learning , author=. arXiv preprint arXiv:2504.20073 , year=
-
[28]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Webagent-r1: Training web agents via end-to-end multi-turn reinforcement learning , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[29]
arXiv preprint arXiv:2603.03078 , year=
RAPO: Expanding Exploration for LLM Agents via Retrieval-Augmented Policy Optimization , author=. arXiv preprint arXiv:2603.03078 , year=
-
[30]
arXiv preprint arXiv:1909.08593 , year=
Fine-tuning language models from human preferences , author=. arXiv preprint arXiv:1909.08593 , year=
Pith/arXiv arXiv 1909
-
[31]
Advances in neural information processing systems , volume=
Learning to summarize with human feedback , author=. Advances in neural information processing systems , volume=
-
[32]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[33]
Machine learning , volume=
Simple statistical gradient-following algorithms for connectionist reinforcement learning , author=. Machine learning , volume=. 1992 , publisher=
1992
-
[34]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Back to basics: Revisiting REINFORCE-style optimization for learning from human feedback in LLMs , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[35]
arXiv preprint arXiv:2503.20783 , year=
Understanding r1-zero-like training: A critical perspective , author=. arXiv preprint arXiv:2503.20783 , year=
-
[36]
Advances in Neural Information Processing Systems , volume=
Dapo: An open-source llm reinforcement learning system at scale , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
Advances in Neural Information Processing Systems , volume=
Cppo: Accelerating the training of group relative policy optimization-based reasoning models , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
arXiv preprint arXiv:2507.18071 , year=
Group sequence policy optimization , author=. arXiv preprint arXiv:2507.18071 , year=
-
[39]
arXiv preprint arXiv:2505.16410 , year=
Tool-star: Empowering llm-brained multi-tool reasoner via reinforcement learning , author=. arXiv preprint arXiv:2505.16410 , year=
-
[40]
arXiv preprint arXiv:2507.19849 , year=
Agentic reinforced policy optimization , author=. arXiv preprint arXiv:2507.19849 , year=
-
[41]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[42]
arXiv preprint arXiv:2601.03267 , year=
Openai gpt-5 system card , author=. arXiv preprint arXiv:2601.03267 , year=
-
[43]
Google Keyword Blog.-12/17/2025.-[Electronic resource] URL: https://blog
Gemini 3 Flash: frontier intelligence built for speed , author=. Google Keyword Blog.-12/17/2025.-[Electronic resource] URL: https://blog. google/products/gemini/gemini-3-flash/(accessed: 10/16/2025) , year=
2025
-
[44]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[45]
arXiv preprint arXiv:2501.12948 , year=
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
-
[46]
arXiv preprint arXiv:2503.09516 , year=
Search-r1: Training llms to reason and leverage search engines with reinforcement learning , author=. arXiv preprint arXiv:2503.09516 , year=
-
[47]
arXiv preprint arXiv:2505.04588 , year=
Zerosearch: Incentivize the search capability of llms without searching , author=. arXiv preprint arXiv:2505.04588 , year=
-
[48]
arXiv preprint arXiv:2505.15107 , year=
Stepsearch: Igniting llms search ability via step-wise proximal policy optimization , author=. arXiv preprint arXiv:2505.15107 , year=
-
[49]
Transactions of the Association for Computational Linguistics , volume=
Natural questions: a benchmark for question answering research , author=. Transactions of the Association for Computational Linguistics , volume=. 2019 , publisher=
2019
-
[50]
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension , author=. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[51]
Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
When not to trust language models: Investigating effectiveness of parametric and non-parametric memories , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[52]
Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
HotpotQA: A dataset for diverse, explainable multi-hop question answering , author=. Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
2018
-
[53]
Proceedings of the 28th International Conference on Computational Linguistics , pages=
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps , author=. Proceedings of the 28th International Conference on Computational Linguistics , pages=
-
[54]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Measuring and narrowing the compositionality gap in language models , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[55]
arXiv preprint arXiv:2112.09332 , year=
Webgpt: Browser-assisted question-answering with human feedback , author=. arXiv preprint arXiv:2112.09332 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.