DICE: Entropy-Regularized Equilibrium Selection for Stable Multi-Agent LLM Coordination
Pith reviewed 2026-06-27 19:56 UTC · model grok-4.3
The pith
Entropy-regularized equilibria with agent- and state-dependent temperatures stabilize multi-agent LLM coordination under a monotonicity condition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
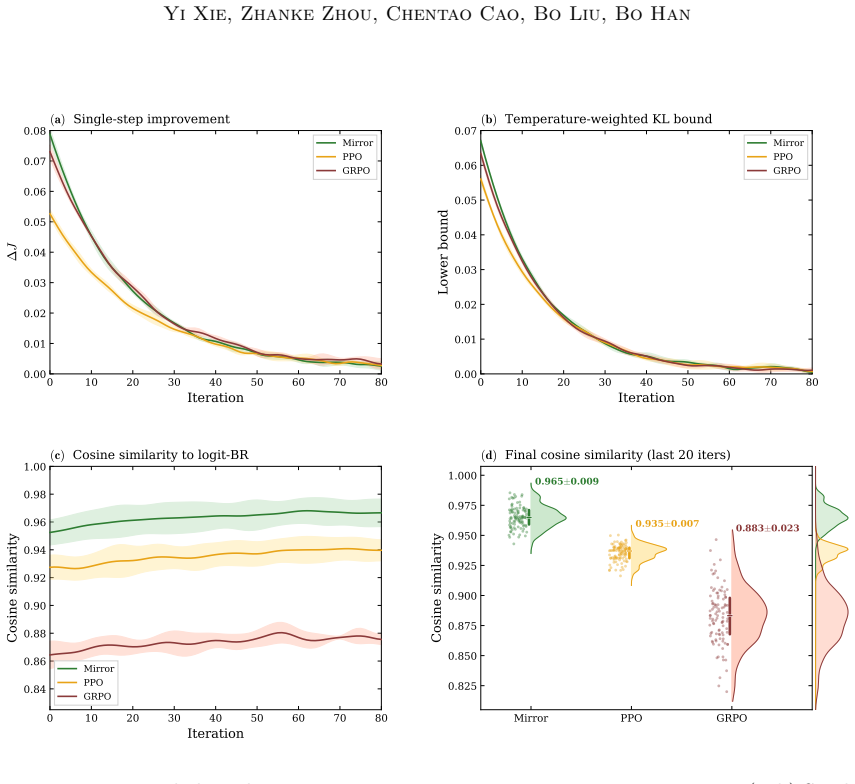
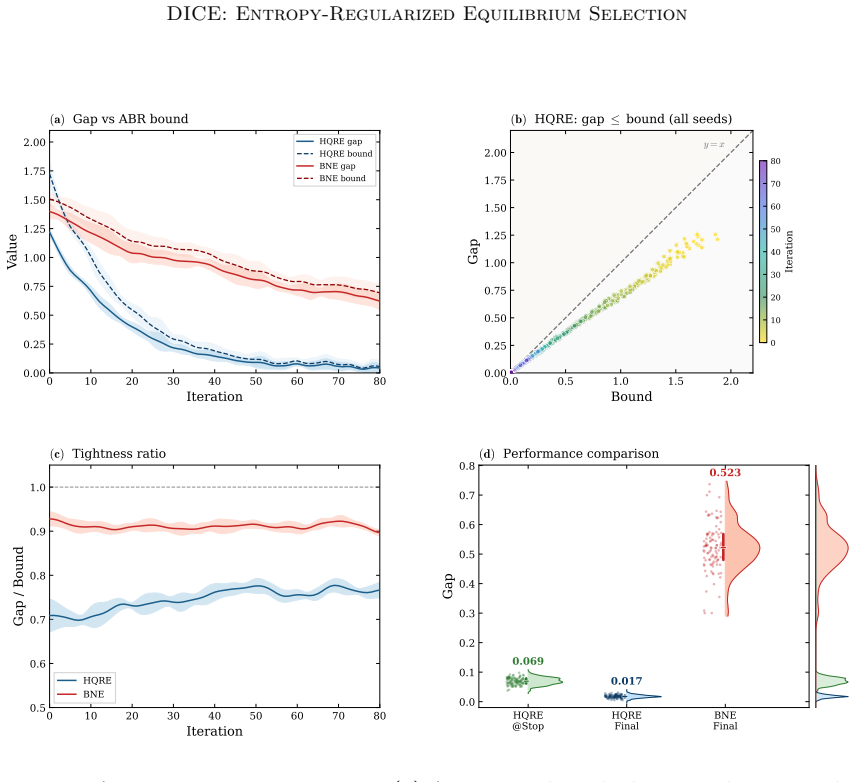
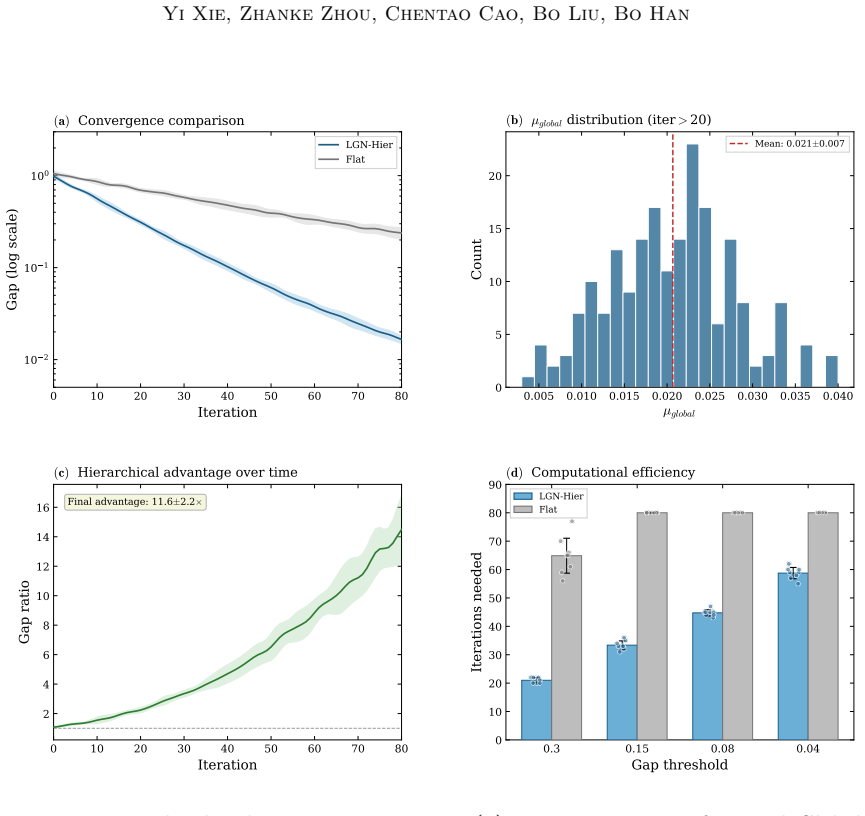
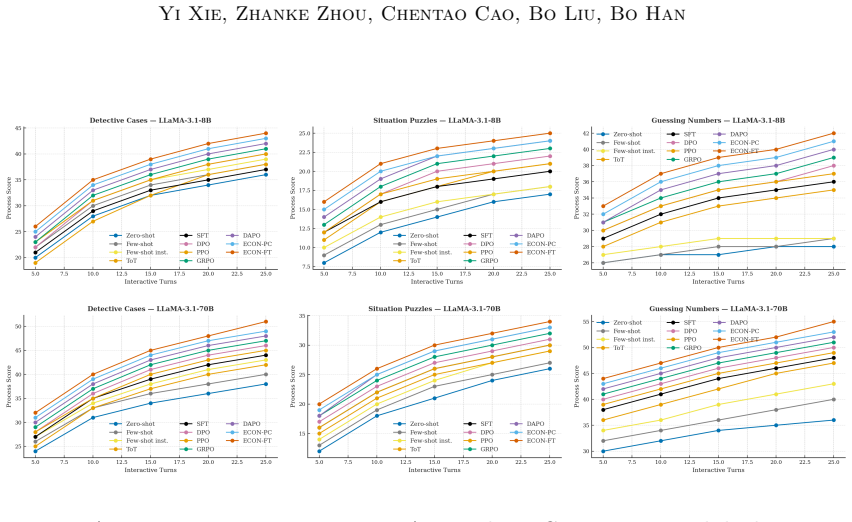
The paper claims that the Heterogeneous Quantal Response Equilibrium (HQRE), an entropy-regularized equilibrium with agent- and state-dependent temperatures, is unique under a monotonicity condition, admits linearly convergent mirror updates, and yields bounded Bayesian regret; the same condition produces rollout-measurable stability diagnostics. Instantiating this objective in DICE-PC and DICE-FT produces better accuracy-cost trade-offs than strong within-class baselines, with average gains of 4.3 percentage points for DICE-PC and 8.5 points for DICE-FT on reasoning and planning tasks.
What carries the argument
Heterogeneous Quantal Response Equilibrium (HQRE), an entropy-regularized equilibrium concept with agent- and state-dependent temperatures that selects a well-posed coordination convention in discounted incomplete-information Markov games.
If this is right
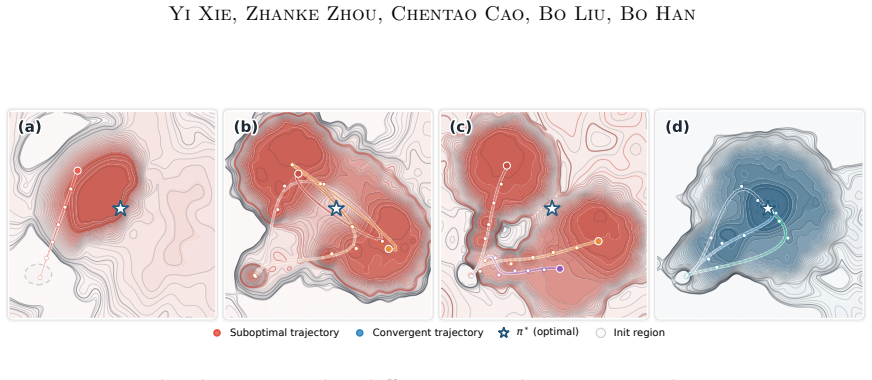
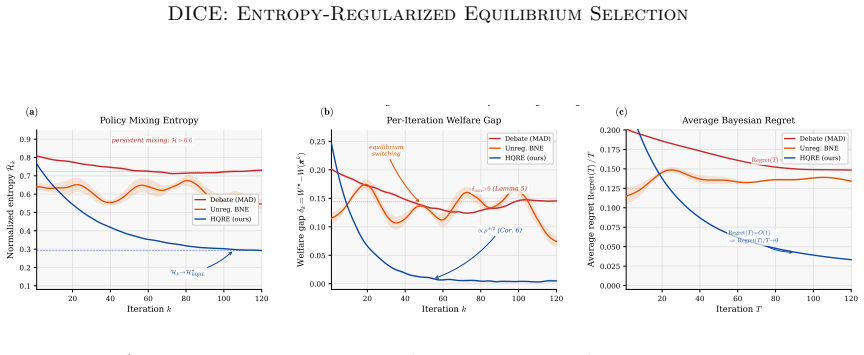
- Oscillation between competing conventions and drift across them are prevented, removing sources of unstable learning.
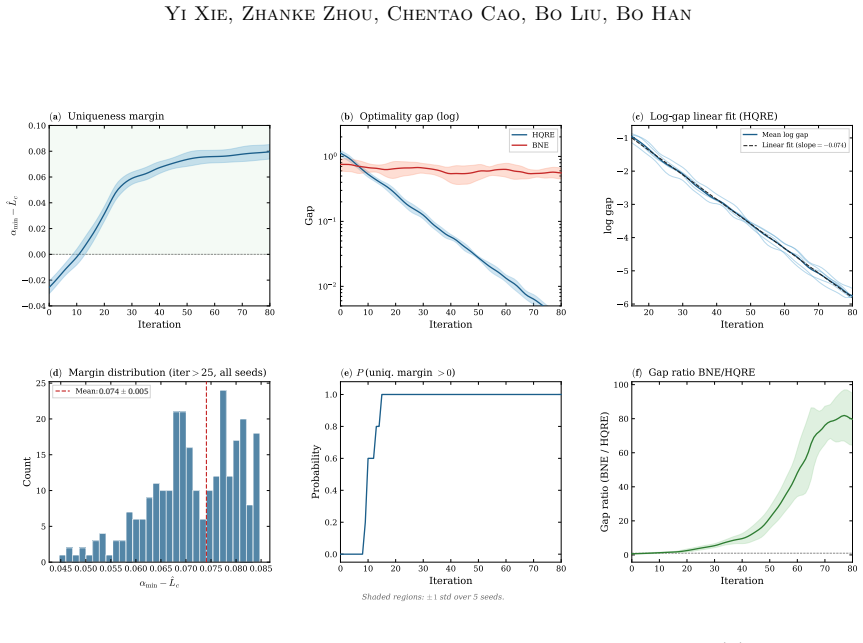
- Linearly convergent mirror updates become available for computing the equilibrium.
- Bayesian regret remains bounded rather than growing linearly.
- Rollout-measurable stability diagnostics become available for monitoring coordination.
- Accuracy-cost trade-offs improve on reasoning, planning, and other benchmark domains.
Where Pith is reading between the lines
- The same entropy-regularized selection mechanism could be tested in multi-agent settings outside LLMs, such as standard MARL environments.
- The stability diagnostics might be adapted to detect coordination failures in deployed single-model systems that use best-of-N sampling.
- Parameter-efficient mirror fine-tuning could be compared against other regularization techniques for scaling to larger agent populations.
- Connections between HQRE temperatures and temperature schedules in single-agent entropy-regularized RL could be examined for unified training objectives.
Load-bearing premise
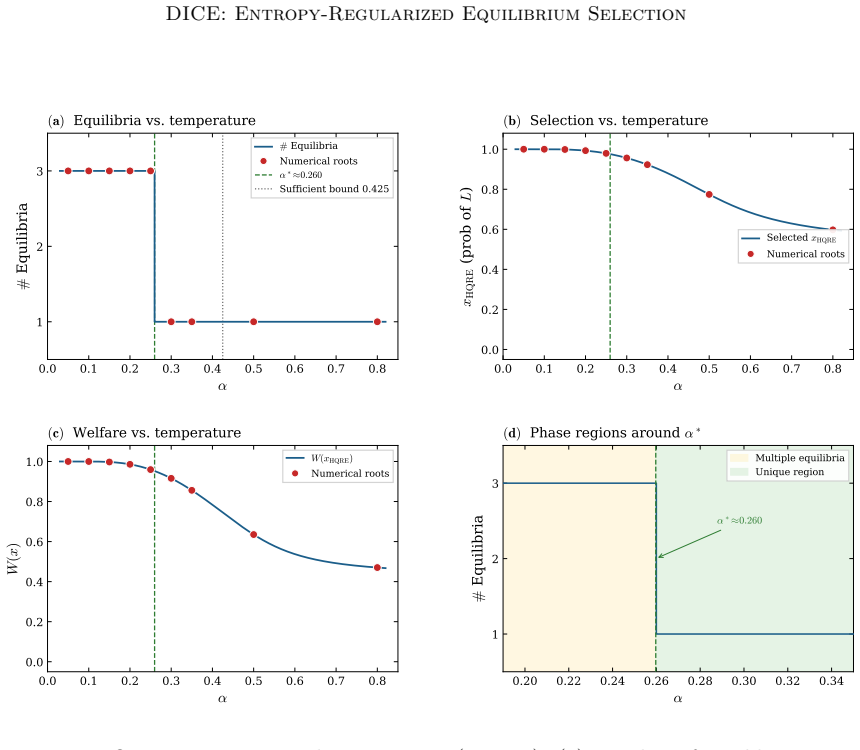
A monotonicity condition on payoffs or best-response structure must hold to guarantee uniqueness of HQRE and linear convergence of the mirror updates.
What would settle it
A game satisfying the monotonicity condition in which either multiple HQREs exist or the mirror updates fail to converge linearly would falsify the uniqueness and convergence claims.
Figures
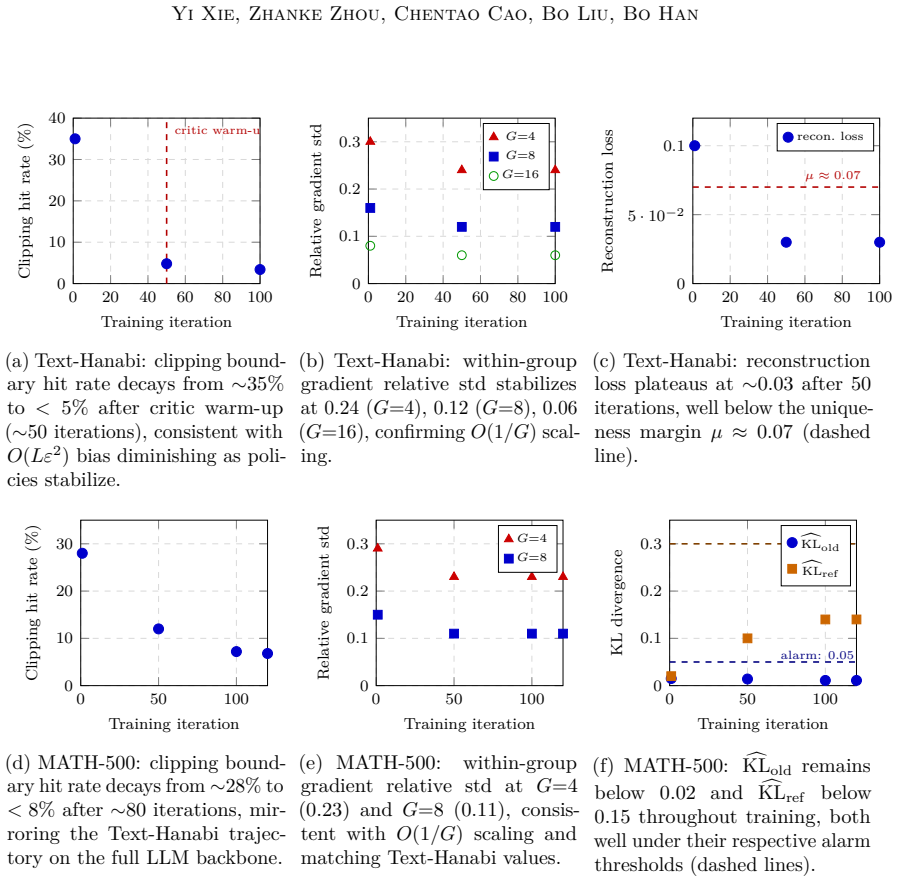
read the original abstract
Multi-agent large language model (LLM) systems often fail to reliably outperform a single strong model equipped with best-of-N sampling. We argue that a core source of this instability is ill-posed equilibrium selection: current systems specify what information agents share, but not which coordination convention should be selected. We formalize a broad class of such systems as discounted incomplete-information Markov games and show that two common pathologies, oscillation between competing conventions and drift across them, can both induce unstable learning and linear Bayesian regret. To obtain a well-posed target, we introduce the Heterogeneous Quantal Response Equilibrium (HQRE), an entropy-regularized equilibrium concept with agent- and state-dependent temperatures. Under a monotonicity condition, HQRE is unique, admits linearly convergent mirror updates, and yields bounded Bayesian regret; the same condition yields rollout-measurable stability diagnostics. We instantiate this objective in two algorithms: DICE-PC, which coordinates frozen models through prompt-control actions, and DICE-FT, which performs parameter-efficient mirror fine-tuning. Across eleven benchmarks in four domains, DICE improves accuracy-cost trade-offs over strong within-class baselines; on reasoning and planning tasks, DICE-PC improves by 4.3 percentage points on average and DICE-FT by 8.5 points.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that instability in multi-agent LLM systems stems from ill-posed equilibrium selection in discounted incomplete-information Markov games, manifesting as oscillation and drift that cause unstable learning and linear Bayesian regret. It introduces the Heterogeneous Quantal Response Equilibrium (HQRE) with agent- and state-dependent temperatures as a well-posed target. Under a monotonicity condition on payoffs or best-response structure, HQRE is unique, admits linearly convergent mirror updates, and yields bounded Bayesian regret, with the condition also enabling rollout-measurable stability diagnostics. The authors instantiate this via DICE-PC (prompt-control coordination of frozen models) and DICE-FT (parameter-efficient mirror fine-tuning), reporting accuracy-cost improvements over baselines across eleven benchmarks in four domains, including average gains of 4.3 and 8.5 points on reasoning and planning tasks.
Significance. If the monotonicity condition holds for the relevant payoff structures and the theoretical claims are substantiated with derivations, the work would provide a principled entropy-regularized equilibrium concept for stable multi-agent LLM coordination, directly addressing oscillation and drift pathologies with accompanying convergence and regret guarantees. The empirical results across multiple domains suggest practical relevance for improving coordination without relying solely on best-of-N sampling.
major comments (2)
- [Abstract] Abstract: The uniqueness of HQRE, linear convergence of the mirror updates, and bounded Bayesian regret are all stated to hold only under a monotonicity condition on payoffs or best-response structure. The manuscript reports no verification or characterization of whether this condition holds for the payoff structures arising in the eleven benchmarks with LLM agents, so the formal guarantees do not attach to the DICE-PC and DICE-FT empirical results.
- [Abstract] Abstract: The central theoretical properties (uniqueness, linear convergence, bounded regret, and stability diagnostics) are asserted without any derivation details, proof sketches, or references to supporting appendices or lemmas, preventing assessment of whether the claims follow from the stated definitions of HQRE and the monotonicity condition.
Simulated Author's Rebuttal
We thank the referee for the detailed reading and for highlighting two important issues in the abstract. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: The uniqueness of HQRE, linear convergence of the mirror updates, and bounded Bayesian regret are all stated to hold only under a monotonicity condition on payoffs or best-response structure. The manuscript reports no verification or characterization of whether this condition holds for the payoff structures arising in the eleven benchmarks with LLM agents, so the formal guarantees do not attach to the DICE-PC and DICE-FT empirical results.
Authors: We agree that the formal guarantees are conditional on the monotonicity assumption and that the manuscript does not empirically verify whether this condition holds for the payoff structures induced by the LLM agents on the eleven benchmarks. The abstract states the condition explicitly, but does not bridge it to the experiments. In the revision we will add a dedicated subsection (likely in Section 4 or 5) that uses rollout data from the benchmarks to test approximate monotonicity of best responses or payoffs, reports any violations, and discusses the implications for the applicability of the theoretical guarantees to the reported results. revision: yes
-
Referee: [Abstract] Abstract: The central theoretical properties (uniqueness, linear convergence, bounded regret, and stability diagnostics) are asserted without any derivation details, proof sketches, or references to supporting appendices or lemmas, preventing assessment of whether the claims follow from the stated definitions of HQRE and the monotonicity condition.
Authors: We accept that the abstract (and, upon re-examination, the main text) presents the claims without inline references to lemmas or appendices and without proof sketches. The full proofs appear in the appendix, but they are not signposted from the abstract or the statement of the main results. In the revision we will (i) add explicit forward references to the relevant lemmas and appendix sections directly in the abstract and in Section 3, and (ii) insert a short proof sketch of the uniqueness and linear convergence arguments (under the monotonicity condition) into the main text of Section 3 to improve accessibility. revision: yes
Circularity Check
No circularity: results conditional on external monotonicity assumption with no self-referential reductions
full rationale
The abstract states that uniqueness of HQRE, linear convergence of mirror updates, and bounded Bayesian regret all hold under a monotonicity condition presented as an external assumption on payoffs or best-response structure. No equations, self-citations, or fitted parameters are quoted that would make any of these claims reduce to the paper's own inputs by construction. The derivation of HQRE as an entropy-regularized equilibrium and the subsequent algorithms are introduced as a well-posed target without evidence of self-definition, renaming of known results, or load-bearing self-citation chains. The paper is therefore self-contained against its stated assumptions.
Axiom & Free-Parameter Ledger
free parameters (1)
- agent- and state-dependent temperatures
axioms (1)
- domain assumption Monotonicity condition on the game ensures uniqueness of HQRE
invented entities (1)
-
Heterogeneous Quantal Response Equilibrium (HQRE)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
NeurIPS , year=
Chain-of-thought prompting elicits reasoning in large language models , author=. NeurIPS , year=
-
[2]
International conference on machine learning , pages=
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[3]
ICLR , year=
Neural Atoms: Propagating Long-range Interaction in Molecular Graphs through Efficient Communication Channel , author=. ICLR , year=
-
[4]
Advances in Neural Information Processing Systems , volume=
Planbench: An extensible benchmark for evaluating large language models on planning and reasoning about change , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
arXiv preprint arXiv:2506.08295 , year=
From Passive to Active Reasoning: Can Large Language Models Ask the Right Questions under Incomplete Information? , author=. arXiv preprint arXiv:2506.08295 , year=
-
[6]
arXiv preprint arXiv:2502.01100 , year=
Zebralogic: On the scaling limits of llms for logical reasoning , author=. arXiv preprint arXiv:2502.01100 , year=
-
[7]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
2023 , eprint=
Evaluating Multi-Agent Coordination Abilities in Large Language Models , author=. 2023 , eprint=
2023
-
[9]
AutoLogi: Automated generation of logic puzzles for evaluating reasoning abilities of large language models , author=. arXiv preprint arXiv:2502.16906 , year=
-
[10]
Qwen2 Technical Report , author =. arXiv preprint arXiv:2407.10671 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
ICML , year =
On Strengthening and Defending Graph Reconstruction Attack with Markov Chain Approximation , author =. ICML , year =
-
[12]
NeurIPS , year=
Multi-agent actor-critic for mixed cooperative-competitive environments , author=. NeurIPS , year=
-
[13]
Journal of the ACM , year=
A new minimax theorem for randomized algorithms , author=. Journal of the ACM , year=
-
[14]
arXiv preprint arXiv:2305.19420 , year=
What and how does in-context learning learn? bayesian model averaging, parameterization, and generalization , author=. arXiv preprint arXiv:2305.19420 , year=
-
[15]
arXiv preprint arXiv:2409.14051 , year=
Groupdebate: Enhancing the efficiency of multi-agent debate using group discussion , author=. arXiv preprint arXiv:2409.14051 , year=
-
[16]
ICML , year=
Should we be going MAD? A Look at Multi-Agent Debate Strategies for LLMs , author=. ICML , year=
-
[17]
An Explanation of In-context Learning as Implicit Bayesian Inference
An explanation of in-context learning as implicit bayesian inference , author=. arXiv preprint arXiv:2111.02080 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Tian, Qingyuan and Zhu, Hanlun and Wang, Lei and Li, Yang and Lan, Yunshi , journal=. R ^
-
[19]
arXiv preprint arXiv:2310.10176 , year=
Large Language Models Meet Open-World Intent Discovery and Recognition: An Evaluation of ChatGPT , author=. arXiv preprint arXiv:2310.10176 , year=
-
[20]
Mathematics of operations research , year=
The complexity of decentralized control of Markov decision processes , author=. Mathematics of operations research , year=
-
[21]
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
GLUE: A multi-task benchmark and analysis platform for natural language understanding , author=. arXiv preprint arXiv:1804.07461 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
ACC , year=
Representation learning for context-dependent decision-making , author=. ACC , year=
-
[23]
arXiv preprint arXiv:2309.17234 , year=
Llm-deliberation: Evaluating llms with interactive multi-agent negotiation games , author=. arXiv preprint arXiv:2309.17234 , year=
-
[24]
Artificial Intelligence Review , volume=
Multi-agent deep reinforcement learning: a survey , author=. Artificial Intelligence Review , volume=. 2022 , publisher=
2022
-
[25]
Frontiers of Information Technology & Electronic Engineering , volume=
Decentralized multi-agent reinforcement learning with networked agents: Recent advances , author=. Frontiers of Information Technology & Electronic Engineering , volume=. 2021 , publisher=
2021
-
[26]
2018 , publisher=
Reinforcement Learning: An Introduction , author=. 2018 , publisher=
2018
-
[27]
Learning to Model Other Minds:
Foerster, Jakob and Chen, Richard Y and Al-Shedivat, Maruan and Whiteson, Shimon and Abbeel, Pieter and Mordatch, Igor , booktitle=. Learning to Model Other Minds:
-
[28]
ICML , year=
Social Influence as Intrinsic Motivation for Multi-Agent Deep Reinforcement Learning , author=. ICML , year=
-
[29]
arXiv preprint arXiv:2309.17179 , year=
Alphazero-like tree-search can guide large language model decoding and training , author=. arXiv preprint arXiv:2309.17179 , year=
-
[30]
COLT , year=
Provably efficient reinforcement learning with linear function approximation , author=. COLT , year=
-
[31]
AAAI , year=
Counterfactual multi-agent policy gradients , author=. AAAI , year=
-
[32]
Neurocomputing , year=
Multi-agent reinforcement learning as a rehearsal for decentralized planning , author=. Neurocomputing , year=
-
[33]
arXiv preprint arXiv:2406.17744 , year=
Following length constraints in instructions , author=. arXiv preprint arXiv:2406.17744 , year=
-
[34]
Journal of Machine Learning Research , year=
Finite-Time Bounds for Fitted Value Iteration , author=. Journal of Machine Learning Research , year=
-
[35]
CoLM , year=
Don't throw away your value model! Generating more preferable text with Value-Guided Monte-Carlo Tree Search decoding , author=. CoLM , year=
-
[36]
2009 , publisher=
Stochastic Approximation: A Dynamical Systems Viewpoint , author=. 2009 , publisher=
2009
-
[37]
SIAM Journal on Optimization , year=
Robust Stochastic Approximation Approach to Stochastic Programming , author=. SIAM Journal on Optimization , year=
-
[38]
2016 , publisher=
Introduction to Online Convex Optimization , author=. 2016 , publisher=
2016
-
[39]
2012 , publisher=
Online Learning and Online Convex Optimization , author=. 2012 , publisher=
2012
-
[40]
1998 , publisher=
The Theory of Learning in Games , author=. 1998 , publisher=
1998
-
[41]
NeurIPS , year=
A Unified Game-Theoretic Approach to Multiagent Reinforcement Learning , author=. NeurIPS , year=
-
[42]
Applied Sciences , year=
What disease does this patient have? a large-scale open domain question answering dataset from medical exams , author=. Applied Sciences , year=
-
[43]
ICML , year=
Generalization without systematicity: On the compositional skills of sequence-to-sequence recurrent networks , author=. ICML , year=
-
[44]
SmoothLLM: Defending Large Language Models Against Jailbreaking Attacks
Smoothllm: Defending large language models against jailbreaking attacks , author=. arXiv preprint arXiv:2310.03684 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
ICWSM , year=
Stance detection with collaborative role-infused llm-based agents , author=. ICWSM , year=
-
[46]
ReAct: Synergizing Reasoning and Acting in Language Models
React: Synergizing reasoning and acting in language models , author=. arXiv preprint arXiv:2210.03629 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
arXiv preprint arXiv:2405.06373 , year=
LLM Discussion: Enhancing the Creativity of Large Language Models via Discussion Framework and Role-Play , author=. arXiv preprint arXiv:2405.06373 , year=
-
[48]
NeurIPS , year=
Self-evaluation guided beam search for reasoning , author=. NeurIPS , year=
-
[49]
NeurIPS , year=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. NeurIPS , year=
-
[50]
arXiv preprint arXiv:2406.14228 , year=
EvoAgent: Towards Automatic Multi-Agent Generation via Evolutionary Algorithms , author=. arXiv preprint arXiv:2406.14228 , year=
-
[51]
EMNLP , year=
Exchange-of-thought: Enhancing large language model capabilities through cross-model communication , author=. EMNLP , year=
-
[52]
ICML , year=
Certified adversarial robustness via randomized smoothing , author=. ICML , year=
-
[53]
ICLR Workshop , year=
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation , author=. ICLR Workshop , year=
-
[54]
arXiv preprint arXiv:2311.09277 , year=
Contrastive chain-of-thought prompting , author=. arXiv preprint arXiv:2311.09277 , year=
-
[55]
arXiv preprint arXiv:2303.03846 , year=
Larger language models do in-context learning differently , author=. arXiv preprint arXiv:2303.03846 , year=
-
[56]
Large Language Models Can Self-Improve
Large language models can self-improve , author=. arXiv preprint arXiv:2210.11610 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
arXiv preprint arXiv:2308.03188 , year=
Automatically correcting large language models: Surveying the landscape of diverse self-correction strategies , author=. arXiv preprint arXiv:2308.03188 , year=
-
[58]
ICML , year=
Large language models can be easily distracted by irrelevant context , author=. ICML , year=
-
[59]
arXiv preprint arXiv:2311.07587 , year=
Frontier Language Models are not Robust to Adversarial Arithmetic, or" What do I need to say so you agree 2+ 2= 5? , author=. arXiv preprint arXiv:2311.07587 , year=
-
[60]
arXiv preprint arXiv:2307.07171 , year=
Certified Robustness for Large Language Models with Self-Denoising , author=. arXiv preprint arXiv:2307.07171 , year=
-
[61]
EMNLP , year=
R3 Prompting: Review, Rephrase and Resolve for Chain-of-Thought Reasoning in Large Language Models under Noisy Context , author=. EMNLP , year=
-
[62]
Lei, Fangyu and Li, Xiang and Wei, Yifan and He, Shizhu and Huang, Yiming and Zhao, Jun and Liu, Kang , journal=. S
-
[63]
Computational Linguistics , year=
Certified robustness to text adversarial attacks by randomized [mask] , author=. Computational Linguistics , year=
-
[64]
arXiv preprint arXiv:2305.14497 , year=
Self-Polish: Enhance Reasoning in Large Language Models via Problem Refinement , author=. arXiv preprint arXiv:2305.14497 , year=
-
[65]
EMNLP , year=
Noisy Exemplars Make Large Language Models More Robust: A Domain-Agnostic Behavioral Analysis , author=. EMNLP , year=
-
[66]
arXiv preprint arXiv:2212.10001 , year=
Towards understanding chain-of-thought prompting: An empirical study of what matters , author=. arXiv preprint arXiv:2212.10001 , year=
-
[67]
arXiv preprint arXiv:2307.10573 , year=
Invalid Logic, Equivalent Gains: The Bizarreness of Reasoning in Language Model Prompting , author=. arXiv preprint arXiv:2307.10573 , year=
-
[68]
ICLR , year=
Self-consistency improves chain of thought reasoning in language models , author=. ICLR , year=
-
[69]
arXiv preprint arXiv:1908.06177 , year=
CLUTRR: A diagnostic benchmark for inductive reasoning from text , author=. arXiv preprint arXiv:1908.06177 , year=
-
[70]
arXiv preprint arXiv:2307.02477 , year=
Reasoning or reciting? exploring the capabilities and limitations of language models through counterfactual tasks , author=. arXiv preprint arXiv:2307.02477 , year=
-
[71]
, author=
Thinking and problem solving: An introduction to human cognition and learning. , author=. 1977 , publisher=
1977
-
[72]
QuAC : Question Answering in Context
QuAC: Question answering in context , author=. arXiv preprint arXiv:1808.07036 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[73]
A Survey on In-context Learning
A survey for in-context learning , author=. arXiv preprint arXiv:2301.00234 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[74]
NeurIPS , year=
Language models are few-shot learners , author=. NeurIPS , year=
-
[75]
Emergent Abilities of Large Language Models
Emergent abilities of large language models , author=. arXiv preprint arXiv:2206.07682 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[76]
EMNLP , year=
Adversarial examples for evaluating reading comprehension systems , author=. EMNLP , year=
-
[77]
EMNLP , year=
Sorting through the noise: Testing robustness of information processing in pre-trained language models , author=. EMNLP , year=
-
[78]
Large Language Models as Optimizers
Large language models as optimizers , author=. arXiv preprint arXiv:2309.03409 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[79]
Journal of Machine Learning Research , year=
Palm: Scaling language modeling with pathways , author=. Journal of Machine Learning Research , year=
-
[80]
arXiv preprint arXiv:2210.00720 , year=
Complexity-based prompting for multi-step reasoning , author=. arXiv preprint arXiv:2210.00720 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.