Biology-inspired joint distribution neurons based on Hierarchical Correlation Reconstruction allowing for multidirectional propagation of values and densities
Pith reviewed 2026-05-24 00:54 UTC · model grok-4.3
The pith
Joint distribution neurons model local densities to enable bidirectional propagation, moment-based uncertainty handling, and local training alternatives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Neurons containing the joint-density model ρ(x) = sum a_j f_j(x) for x in [0,1]^d allow repair of missing inputs by conditional evaluation, propagate distributions via moment vectors, and admit local training procedures including direct optimization and information-bottleneck updates, while remaining compatible with existing architectures such as transformers.
What carries the argument
The joint distribution representation ρ(x) = sum_{j in B} a_j f_j(x) that encodes correlations among inputs and supplies conditional values or moments on demand.
If this is right
- Inputs can be repaired on the fly by solving for the conditional distribution given the observed coordinates.
- Uncertainty can be propagated forward by carrying vectors of moments rather than single point estimates.
- Training rules other than back-propagation become available, including direct fitting of the coefficients a_j and local information-bottleneck objectives.
- The same representation can replace softmax layers in embedding models by treating learned features as mixed moments of an underlying joint density.
Where Pith is reading between the lines
- Such neurons could support decentralized or continual learning scenarios where only local statistics are updated.
- Interpreting transformer features as moments suggests a route to uncertainty-aware attention mechanisms.
- The approach opens a concrete path for testing whether explicit joint-density modeling improves robustness on tasks that reward risk sensitivity.
Load-bearing premise
The joint distribution model can be trained and evaluated at practical cost while preserving accuracy comparable to standard layers.
What would settle it
A controlled benchmark in which networks built from these neurons require substantially more parameters or training time than MLPs or KANs to reach the same test accuracy on a standard classification or regression task.
Figures








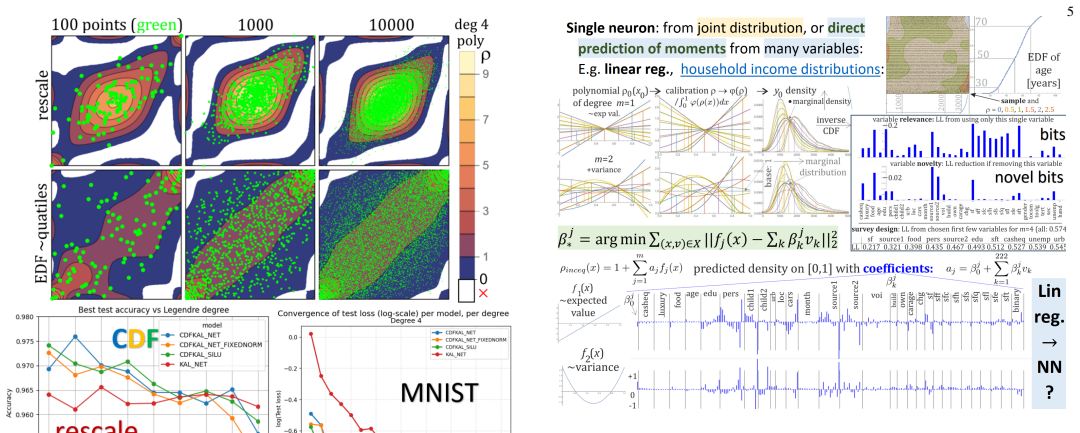




read the original abstract
Recently a million of biological neurons (BNN) has turned out better from modern RL methods in playing Pong~\cite{RL}, reminding they are still qualitatively superior e.g. in learning, flexibility and robustness - suggesting to try to improve current artificial e.g. MLP/KAN for better agreement with biological. There is proposed extension of KAN approach to neurons containing model of local joint distribution: $\rho(\mathbf{x})=\sum_{\mathbf{j}\in B} a_\mathbf{j} f_\mathbf{j}(\mathbf{x})$ for $\mathbf{x} \in [0,1]^d$, adding interpretation and information flow control to KAN, and allowing to gradually add missing 3 basic properties of biological: 1) biological axons propagate in both directions~\cite{axon}, while current artificial are focused on unidirectional propagation - joint distribution neurons can repair by substituting some variables to get conditional values/distributions for the remaining. 2) Animals show risk avoidance~\cite{risk} requiring to process variance, and generally real world rather needs probabilistic models - the proposed can predict and propagate also distributions as vectors of moments: (expected value, variance) or higher. 3) biological neurons require local training, and beside backpropagation, the proposed allows many additional ways, like direct training, through tensor decomposition, or finally local and promising: information bottleneck. Proposed approach is very general, can be also used as extension of softmax in embeddings of e.g. transformer or JEPA, suggesting interpretation that features are mixed moments of joint density of real-world properties.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes joint distribution neurons as an extension of Kolmogorov-Arnold Networks, in which each neuron models a local joint distribution via the linear expansion ρ(x)=∑_{j∈B} a_j f_j(x) for x∈[0,1]^d. The central claim is that this form supplies three missing biological properties: (1) bidirectional propagation obtained by variable substitution to produce conditionals, (2) propagation of full distributions represented as moment vectors (mean, variance, …), and (3) local training routes including direct fitting, tensor decomposition, and the information bottleneck. The same construction is suggested as a drop-in replacement for softmax layers in transformers.
Significance. If the functional form could be equipped with concrete, tractable basis functions and training procedures that realize the three listed properties at scale, the work would supply a principled probabilistic primitive that unifies interpretation, uncertainty propagation, and locality of learning—potentially improving robustness and sample efficiency over standard MLPs or KANs. The absence of any such concrete realization, however, leaves the significance prospective rather than demonstrated.
major comments (4)
- [Abstract] Abstract: the claim that substitution of variables directly yields conditional distributions omits the marginalization integrals required for normalization; without an explicit product or separable structure on the unspecified f_j, these integrals are intractable for d>3 and therefore load-bearing for the bidirectional-propagation claim.
- [Abstract] Abstract: no choice of basis functions f_j, multi-index set B, non-negativity constraint, or normalization procedure for the coefficients a_j is supplied, rendering the three biological properties formal possibilities rather than demonstrated capabilities of the given expansion.
- [Abstract] Abstract: the information-bottleneck training route is asserted to be “local and promising,” yet no algorithm, objective, or complexity bound is derived that would show how the bottleneck can be optimized using only the linear coefficients a_j and the (unspecified) f_j.
- [Abstract] Abstract: the manuscript contains neither derivations, pseudocode, complexity analysis, nor any empirical result that would substantiate that the proposed neuron can be trained or evaluated at practical cost while preserving the claimed moment-propagation and conditioning properties.
minor comments (2)
- [Abstract] Abstract: grammatical phrasing “a million of biological neurons” and “the proposed can predict” should be corrected.
- [Abstract] Abstract: citation markers (e.g., ~cite{RL}, ~cite{axon}) appear without an accompanying reference list or context.
Simulated Author's Rebuttal
We thank the referee for the constructive critique. The manuscript is a concise conceptual proposal introducing the joint-distribution neuron form and arguing that it formally enables three biological properties. We respond point-by-point below, acknowledging where the current text is limited to the general expansion and where concrete realizations remain future work.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that substitution of variables directly yields conditional distributions omits the marginalization integrals required for normalization; without an explicit product or separable structure on the unspecified f_j, these integrals are intractable for d>3 and therefore load-bearing for the bidirectional-propagation claim.
Authors: We agree that obtaining a properly normalized conditional from the joint expansion generally requires marginalization integrals. The manuscript states that substitution yields conditionals, but does not claim this is automatic for arbitrary bases; the intent is that, once a concrete basis admitting closed-form or efficient marginals is chosen, the same linear coefficients allow both forward and backward propagation. The current text leaves the required structure on f_j implicit, which is a limitation of the presentation. revision: no
-
Referee: [Abstract] Abstract: no choice of basis functions f_j, multi-index set B, non-negativity constraint, or normalization procedure for the coefficients a_j is supplied, rendering the three biological properties formal possibilities rather than demonstrated capabilities of the given expansion.
Authors: The manuscript deliberately presents the most general linear expansion that still permits the three listed operations (variable substitution, moment-vector propagation, and local coefficient updates). Specific bases (e.g., multivariate polynomials or wavelets on [0,1]^d), non-negativity constraints, and normalization schemes are indeed omitted because the paper’s scope is to establish the functional form and its qualitative advantages over standard KAN neurons. Concrete instantiations are required for implementation and are noted as future work. revision: no
-
Referee: [Abstract] Abstract: the information-bottleneck training route is asserted to be “local and promising,” yet no algorithm, objective, or complexity bound is derived that would show how the bottleneck can be optimized using only the linear coefficients a_j and the (unspecified) f_j.
Authors: The claim is that the information-bottleneck objective can be expressed directly in terms of the coefficients a_j once the basis is fixed, because the modeled density is linear in those coefficients; this would in principle allow a local update without back-propagation through the rest of the network. No explicit algorithm or complexity analysis is supplied, as the manuscript only identifies the route as conceptually local. Deriving a practical optimizer is left for subsequent development. revision: no
-
Referee: [Abstract] Abstract: the manuscript contains neither derivations, pseudocode, complexity analysis, nor any empirical result that would substantiate that the proposed neuron can be trained or evaluated at practical cost while preserving the claimed moment-propagation and conditioning properties.
Authors: The manuscript is a short conceptual note whose contribution is the identification of the linear joint-density expansion and the three formal properties it enables. It therefore contains no empirical results, pseudocode, or complexity bounds. We accept that demonstrating practical cost and preservation of the properties requires concrete bases, training procedures, and experiments, none of which are present. revision: no
Circularity Check
No circularity: forward architectural proposal with independent claims
full rationale
The manuscript defines the joint density model ρ(x)=∑_{j∈B} a_j f_j(x) directly as an extension of KAN and then enumerates three biological properties (bidirectional repair via substitution, moment-vector propagation, and multiple local training routes) as consequences of that functional form. No step equates a claimed prediction or uniqueness result to a fitted parameter or prior self-citation; the conditioning argument is presented as a formal possibility of variable substitution without any reduction to an input equation or self-referential theorem. External citations (axon, risk, RL) are used only for motivation, not as load-bearing justification. The derivation chain therefore remains self-contained and non-circular.
Axiom & Free-Parameter Ledger
free parameters (1)
- a_j coefficients
axioms (1)
- domain assumption The local joint distribution can be expressed as a linear combination of basis functions f_j(x)
invented entities (1)
-
joint distribution neuron
no independent evidence
Forward citations
Cited by 1 Pith paper
-
An Empirical Study of Sustainability in Prompt-driven Test Script Generation Using Small Language Models
Small language models display distinct energy-use and coverage profiles when generating unit tests, with some models being more efficient while others offer higher stability.
Reference graph
Works this paper leans on
-
[1]
M. Khajehnejad, F. Habibollahi, A. Loeffler, A. Paul, A. Razi, and B. J. Kagan, “Dynamic network plasticity and sample efficiency in biological neural cultures: A comparative study with deep reinforcement learning,” Cyborg and Bionic Systems, vol. 6, p. 0336, 2025
work page 2025
-
[2]
Dynamics of signal propagation and collision in axons,
R. Follmann, E. Rosa Jr, and W. Stein, “Dynamics of signal propagation and collision in axons,”Physical Review E, vol. 92, no. 3, p. 032707, 2015
work page 2015
-
[3]
The concept of uncertainty in animal experi- ments using aversive stimulation
H. Imada and Y . Nageishi, “The concept of uncertainty in animal experi- ments using aversive stimulation.”Psychological bulletin, vol. 91, no. 3, p. 573, 1982
work page 1982
-
[4]
Spiking neural networks and their applications: A review,
K. Yamazaki, V .-K. V o-Ho, D. Bulsara, and N. Le, “Spiking neural networks and their applications: A review,”Brain sciences, vol. 12, no. 7, p. 863, 2022
work page 2022
-
[5]
The information bottleneck method
N. Tishby, F. C. Pereira, and W. Bialek, “The information bottleneck method,”arXiv preprint physics/0004057, 2000
work page internal anchor Pith review Pith/arXiv arXiv 2000
-
[6]
KAN: Kolmogorov-Arnold Networks
Z. Liu, Y . Wang, S. Vaidya, F. Ruehle, J. Halverson, M. Solja ˇci´c, T. Y . Hou, and M. Tegmark, “KAN: Kolmogorov-arnold networks,”arXiv preprint arXiv:2404.19756, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Multilayer feedforward net- works are universal approximators,
K. Hornik, M. Stinchcombe, and H. White, “Multilayer feedforward net- works are universal approximators,”Neural networks, vol. 2, no. 5, pp. 359–366, 1989
work page 1989
-
[8]
Information bottleneck for gaussian variables,
G. Chechik, A. Globerson, N. Tishby, and Y . Weiss, “Information bottleneck for gaussian variables,”Advances in Neural Information Processing Systems, vol. 16, 2003
work page 2003
-
[9]
Deep learning and the information bottleneck principle,
N. Tishby and N. Zaslavsky, “Deep learning and the information bottleneck principle,” in2015 ieee information theory workshop (itw). IEEE, 2015, pp. 1–5
work page 2015
-
[10]
Hierarchical correlation reconstruction with missing data, for example for biology-inspired neuron
J. Duda, “Hierarchical correlation reconstruction with missing data, for example for biology-inspired neuron,”arXiv preprint arXiv:1804.06218, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[12]
Modelling bid-ask spread condi- tional distributions using hierarchical correlation reconstruction,
J. Duda, H. Gurgul, and R. Syrek, “Modelling bid-ask spread condi- tional distributions using hierarchical correlation reconstruction,”Statis- tics in Transition New Series, vol. 21, no. 5, 2020, preprint: https://arxiv.org/abs/1911.02361
-
[13]
Gamma-ray blazar variability: new statistical meth- ods of time-flux distributions,
J. Duda and G. Bhatta, “Gamma-ray blazar variability: new statistical meth- ods of time-flux distributions,”Monthly Notices of the Royal Astronomical Society, vol. 508, no. 1, pp. 1446–1458, 2021
work page 2021
-
[14]
J. Duda and S. Podlewska, “Prediction of probability distributions of molecular properties: towards more efficient virtual screening and better understanding of compound representations,”Molecular Diversity, pp. 1– 12, 2022
work page 2022
-
[15]
J. Duda and G. Bhatta, “Predicting conditional probability distributions of redshifts of active galactic nuclei using hierarchical correlation reconstruc- tion,”Monthly Notices of the Royal Astronomical Society, p. stae963, 2024
work page 2024
-
[16]
R. Pogodin and P. Latham, “Kernelized information bottleneck leads to biologically plausible 3-factor hebbian learning in deep networks,”Advances in Neural Information Processing Systems, vol. 33, pp. 7296–7307, 2020
work page 2020
-
[17]
The HSIC bottleneck: Deep learning without back-propagation,
W.-D. K. Ma, J. Lewis, and W. B. Kleijn, “The HSIC bottleneck: Deep learning without back-propagation,” inProceedings of the AAAI conference on artificial intelligence, vol. 34, no. 04, 2020, pp. 5085–5092
work page 2020
-
[18]
Copula theory: an introduction,
F. Durante and C. Sempi, “Copula theory: an introduction,” inCopula theory and its applications. Springer, 2010, pp. 3–31
work page 2010
-
[19]
Batch normalization: Accelerating deep network training by reducing internal covariate shift,
S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” inInternational conference on machine learning. pmlr, 2015, pp. 448–456
work page 2015
-
[20]
Rapid parametric density estimation
J. Duda, “Rapid parametric density estimation,”arXiv preprint arXiv:1702.02144, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Improving kan with cdf normalization to quantiles,
J. Strawa and J. Duda, “Improving kan with cdf normalization to quantiles,” arXiv preprint arXiv:2507.13393, 2025
-
[22]
Credibility evaluation of income data with hierarchical correlation reconstruction
J. Duda and A. Szulc, “Social benefits versus monetary and multidi- mensional poverty in Poland: imputed income exercise,” inInternational Conference on Applied Economics. Springer, 2019, pp. 87–102, preprint: arXiv:1812.08040
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[23]
Tensor decompositions and applications,
T. G. Kolda and B. W. Bader, “Tensor decompositions and applications,” SIAM review, vol. 51, no. 3, pp. 455–500, 2009
work page 2009
-
[24]
Fast optimization of common basis for matrix set through common singular value decomposition,
J. Duda, “Fast optimization of common basis for matrix set through common singular value decomposition,”arXiv preprint arXiv:2204.08242, 2022
-
[25]
Linear cost mutual information estimation and independence test of similar performance as hsic,
J. Duda, J. Bracha, and A. Przybysz, “Linear cost mutual information estimation and independence test of similar performance as hsic,”arXiv preprint arXiv:2508.18338, 2025
-
[26]
A kernel statistical test of independence,
A. Gretton, K. Fukumizu, C. Teo, L. Song, B. Sch ¨olkopf, and A. Smola, “A kernel statistical test of independence,”Advances in neural information processing systems, vol. 20, 2007
work page 2007
-
[27]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.