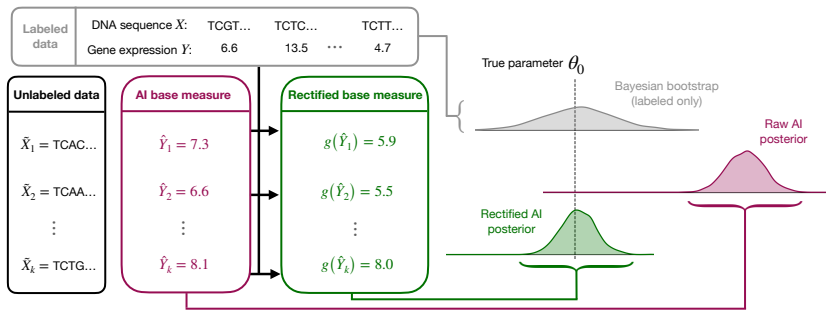
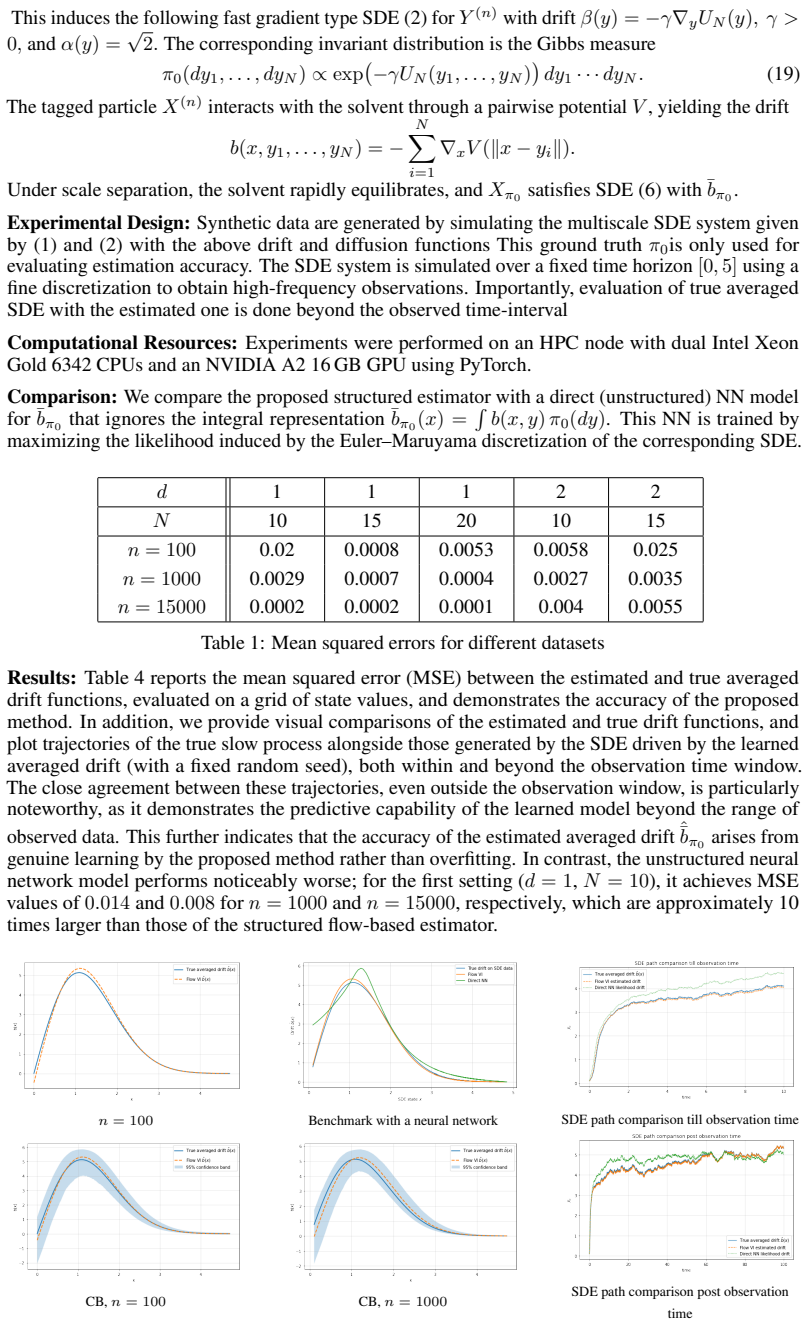
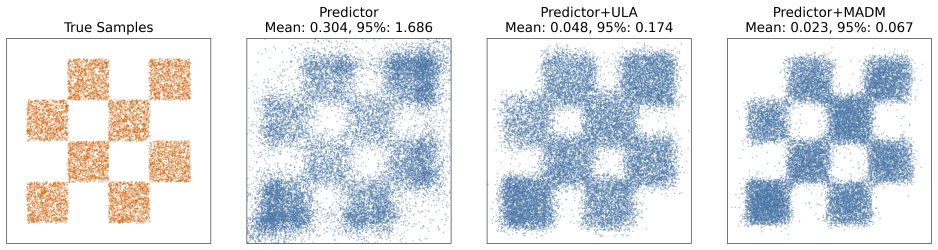
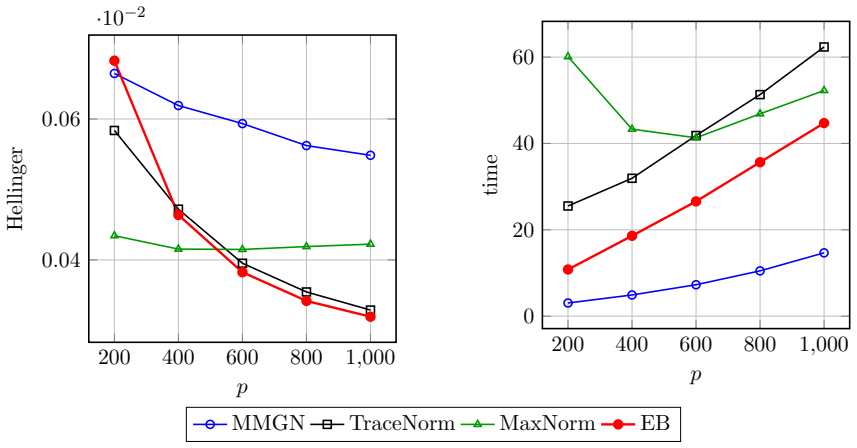
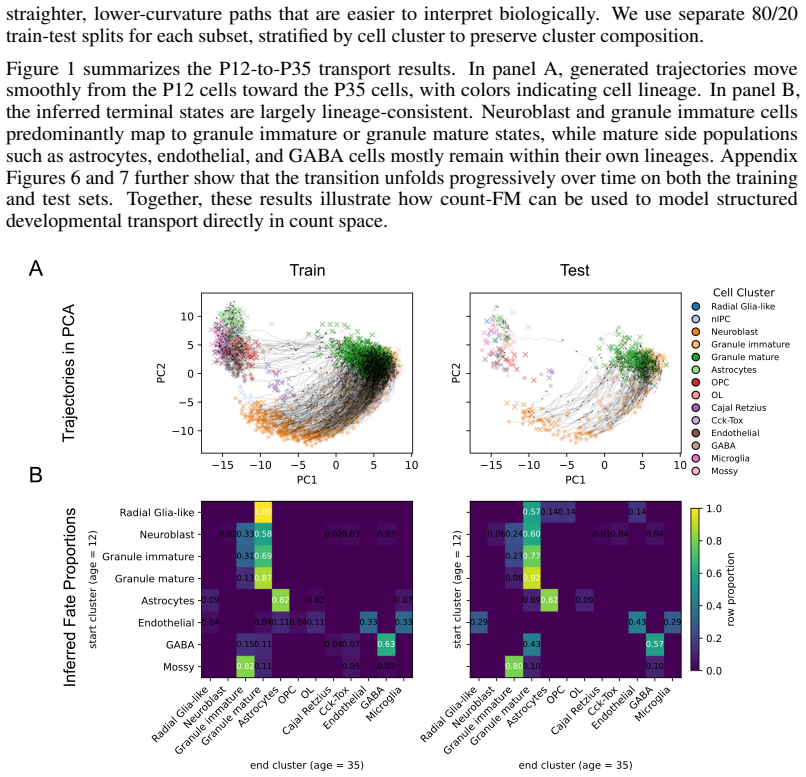
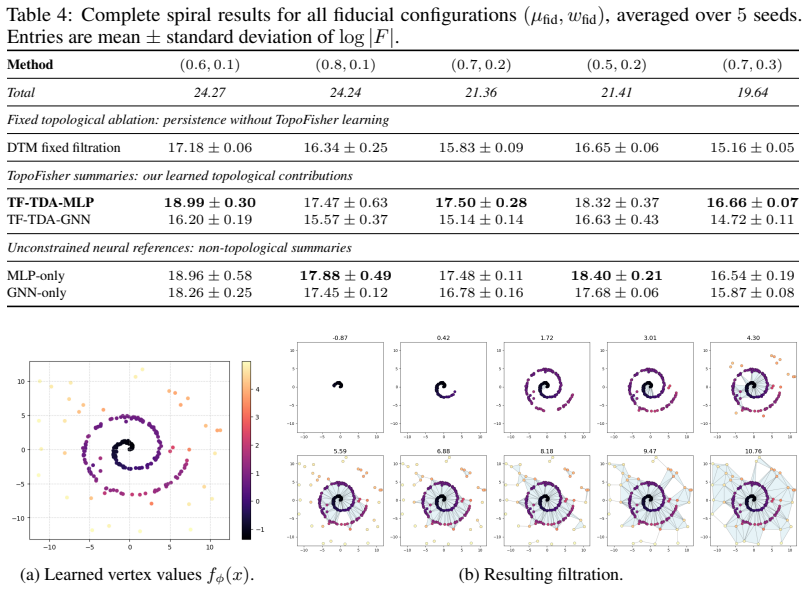
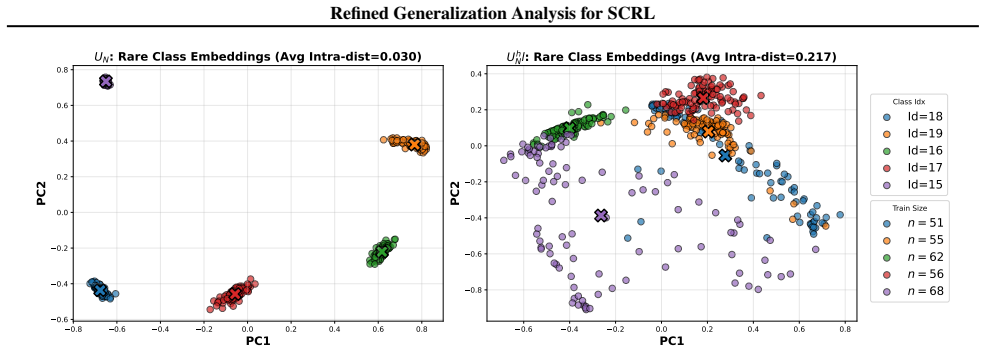
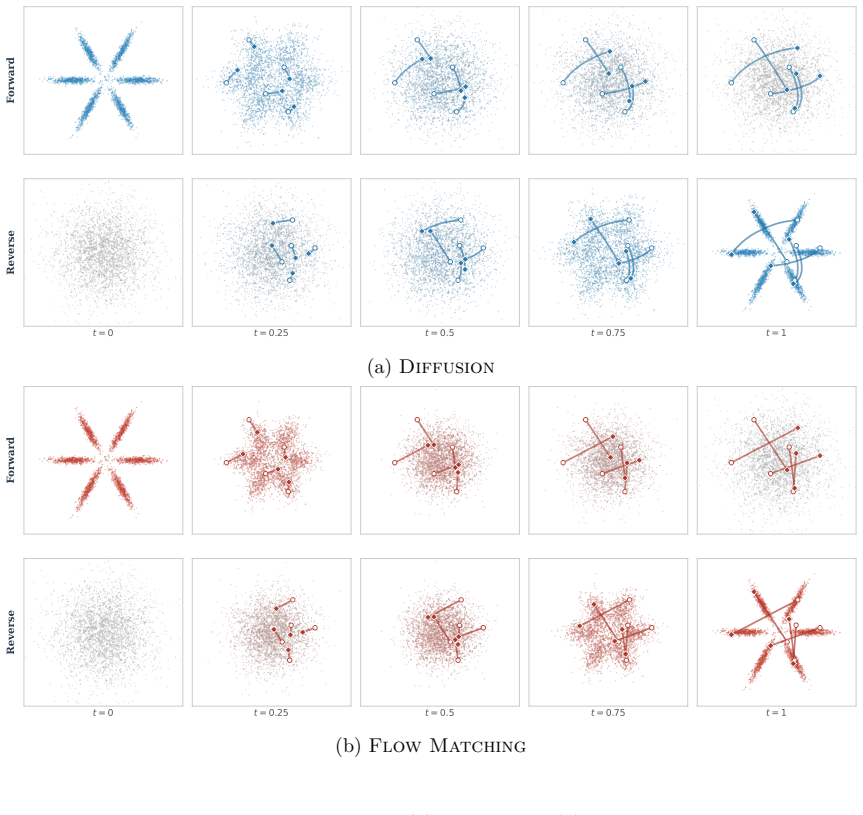
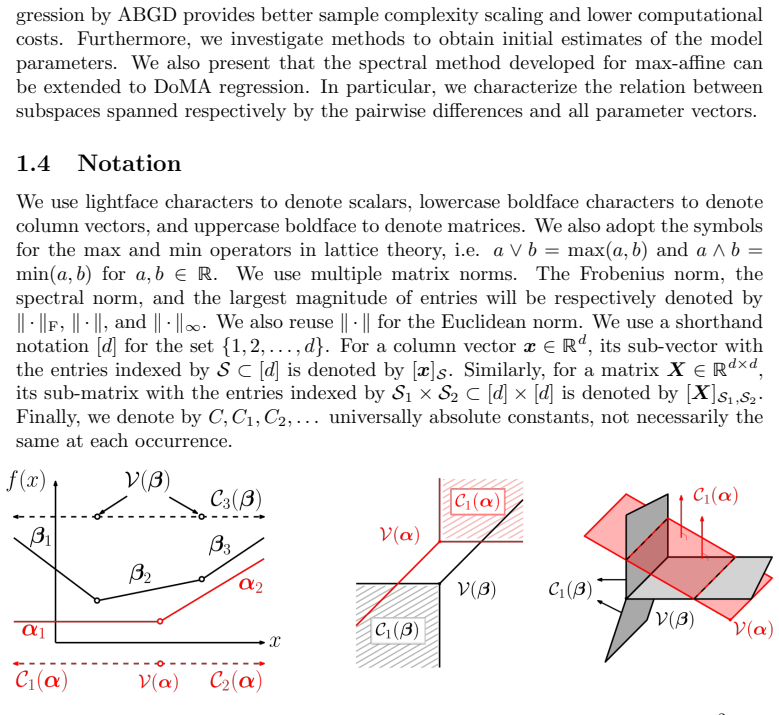
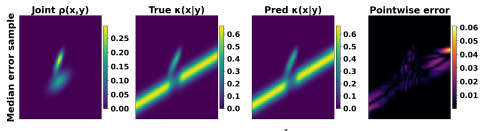
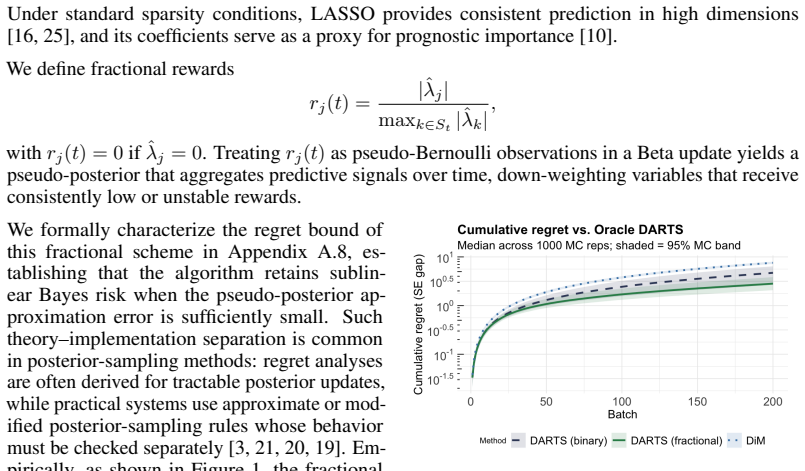
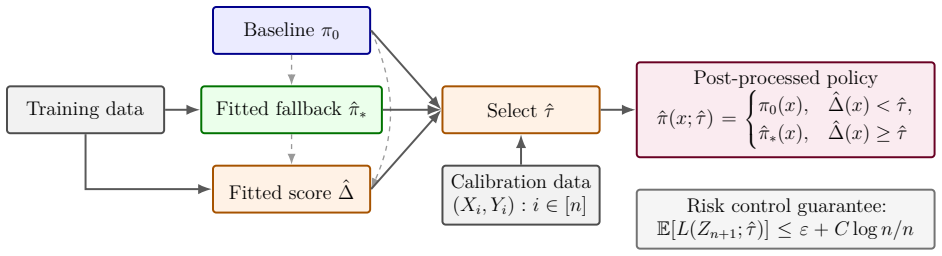
0
Bootstrap yields valid CIs for offline RL value functions
Model-based Bootstrap of Controlled Markov Chains
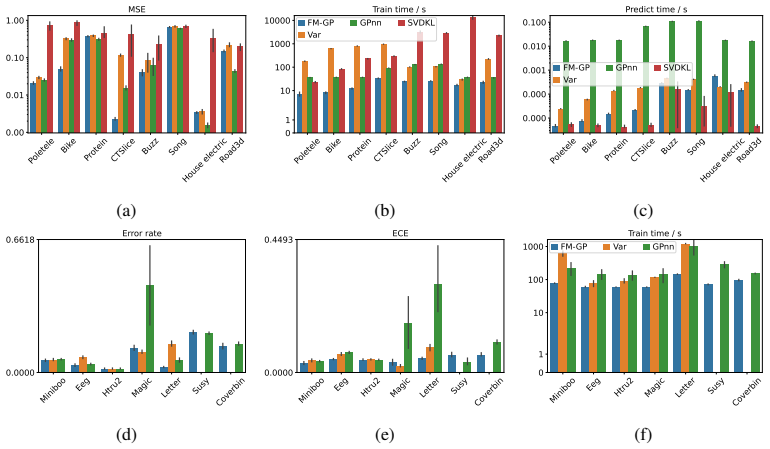
New resampling scheme for Markov transition kernels attains nominal coverage at small samples where plug-in and episodic baselines fail.
 full image
full image
abstract click to expand
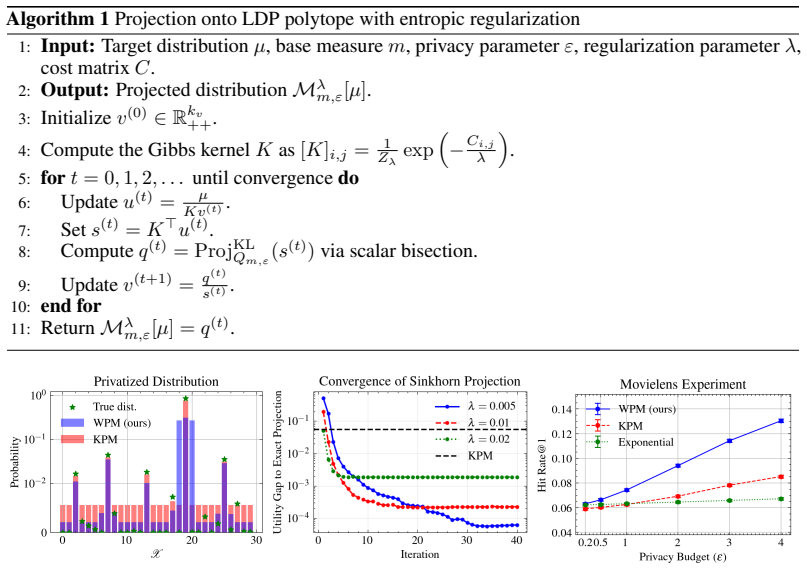
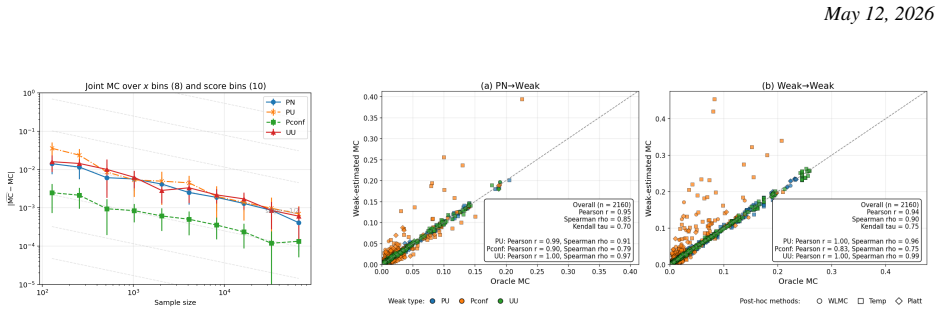
We propose and analyze a model-based bootstrap for transition kernels in finite controlled Markov chains (CMCs) with possibly nonstationary or history-dependent control policies, a setting that arises naturally in offline reinforcement learning (RL) when the behavior policy generating the data is unknown. We establish distributional consistency of the bootstrap transition estimator in both a single long-chain regime and the episodic offline RL regime. The key technical tools are a novel bootstrap law of large numbers (LLN) for the visitation counts and a novel use of the martingale central limit theorem (CLT) for the bootstrap transition increments. We extend bootstrap distributional consistency to the downstream targets of offline policy evaluation (OPE) and optimal policy recovery (OPR) via the delta method by verifying Hadamard differentiability of the Bellman operators, yielding asymptotically valid confidence intervals for value and $Q$-functions. Experiments on the RiverSwim problem show that the proposed bootstrap confidence intervals (CIs), especially the percentile CIs, outperform the episodic bootstrap and plug-in CLT CIs, and are often close to nominal ($50\%$, $90\%$, $95\%$) coverage, while the baselines are poorly calibrated at small sample sizes and short episode lengths.