Can Entry-Wise Clipping Give Spectral Control of Stochastic Gradients?
Pith reviewed 2026-06-29 18:23 UTC · model grok-4.3
The pith
Entry-wise clipping can achieve spectral control of stochastic gradients by exploiting noise localization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Real gradient noise appears to be similar to entry-wise heavy-tailed contamination, and a first-order perturbation analysis reveals a localization property of such noise, under which a simple entry-wise method achieves spectral control. Exploiting this, we derive a tractable surrogate for the Bayes-optimal entry-wise estimator under a Gaussian signal prior. We establish O(ε^{-4}) convergence guarantee under Cauchy-contaminated noise.
What carries the argument
Localization property of entry-wise heavy-tailed noise under first-order perturbation analysis, which enables entry-wise clipping to achieve spectral control of the gradient matrix.
If this is right
- Yields O(ε^{-4}) convergence under Cauchy-contaminated noise.
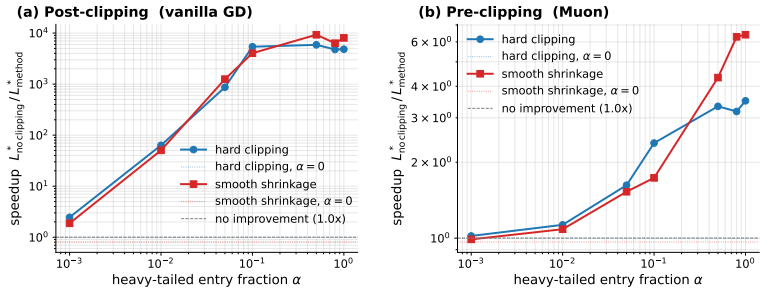
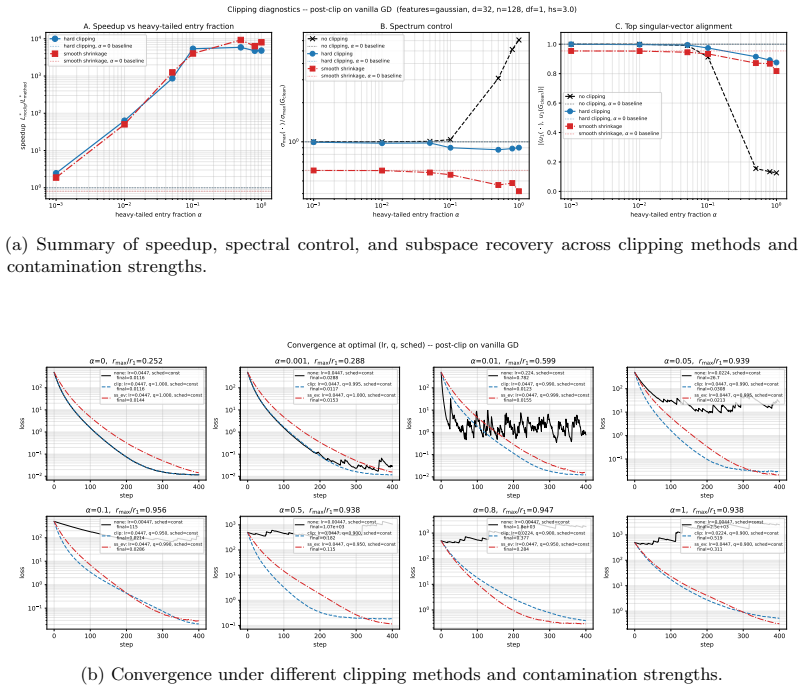
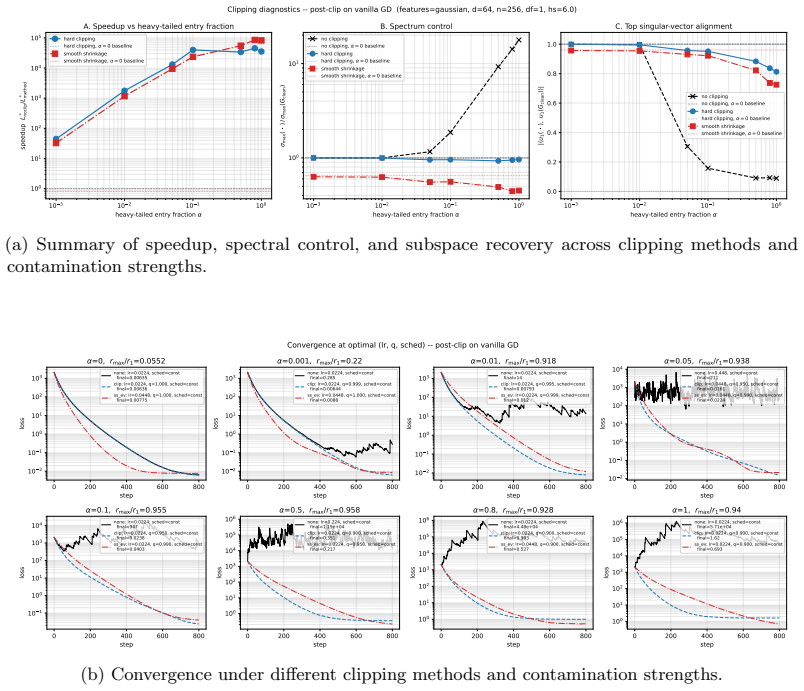
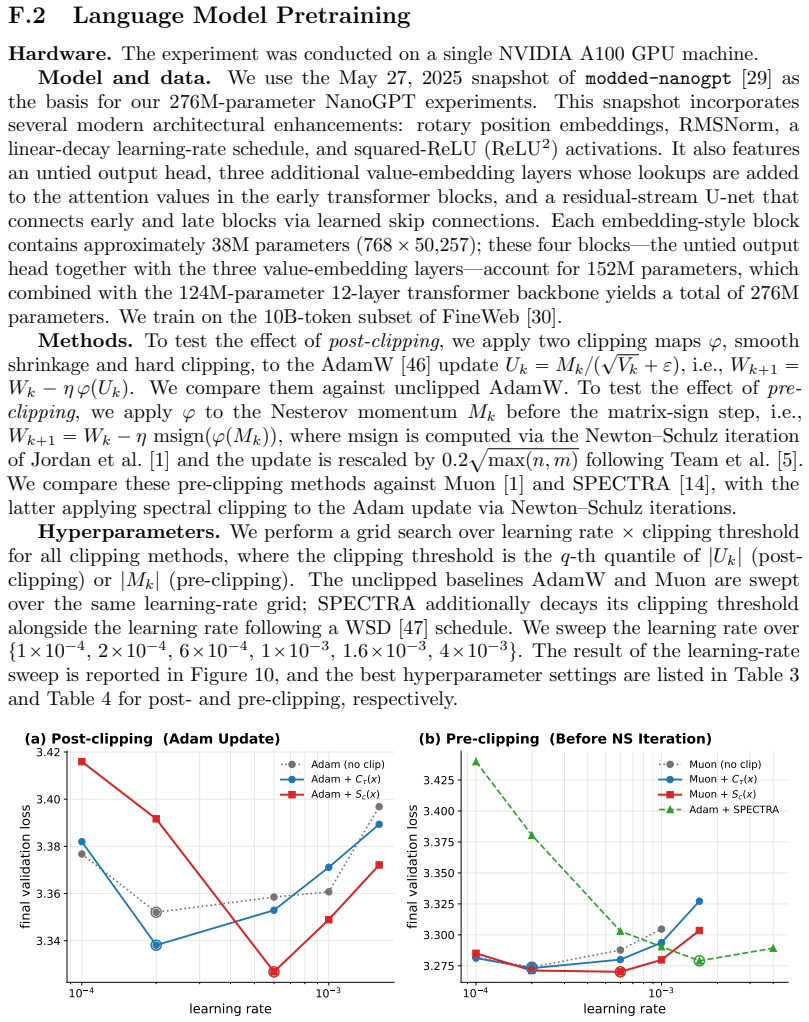
- Smooth shrinkage improves Adam on NanoGPT pretraining and saves approximately 7% of training tokens.
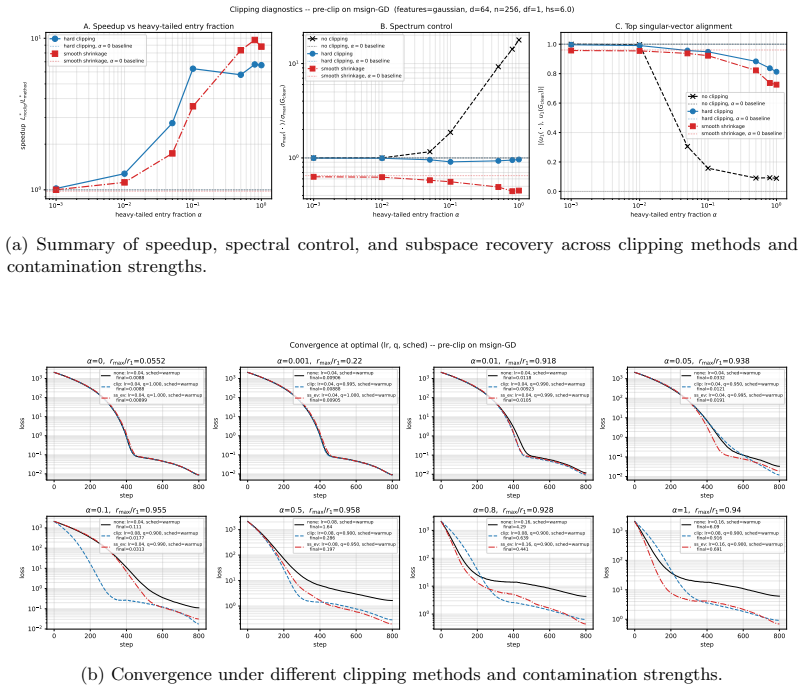
- Applying entry-wise clipping before spectral normalization adds approximately 2% further token savings on top of Muon.
- Balances the structure-cost trade-off between vector-norm clipping and full spectral normalization.
Where Pith is reading between the lines
- The same entry-wise shrinkage could be inserted into other first-order optimizers that already use per-coordinate scaling.
- If the localization property holds outside language-model training, the method may reduce instability in vision or reinforcement-learning settings.
- Hybrid entry-wise plus spectral pipelines might become a default stabilization pattern once the noise model is verified at larger scale.
- The convergence rate suggests the approach could be especially useful in regimes where noise tails are heavier than Gaussian.
Load-bearing premise
Real gradient noise appears to be similar to entry-wise heavy-tailed contamination.
What would settle it
An experiment in which entry-wise clipping leaves the spectral norm of the gradient matrix uncontrolled, or in which observed gradient noise fails to exhibit the predicted localization under perturbation.
Figures





read the original abstract
Training instabilities such as loss spikes are frequently the result of stochastic gradient noise. Because of rare expressions in language training data, and multiple layer composition, the noise impact is heavy-tailed and survives mini-batch averaging. Existing remedies trade off structure against cost: vector-norm clipping ignores the matrix structure of weight updates, while spectral normalization (e.g., Muon (Jordan et al., 2024)) respects it at additional cost. We show that this trade-off can be balanced. Real gradient noise appears to be similar to entry-wise heavy-tailed contamination, and a first-order perturbation analysis reveals a localization property of such noise, under which a simple entry-wise method achieves spectral control. Exploiting this, we derive a tractable surrogate for the Bayes-optimal entry-wise estimator under a Gaussian signal prior. We establish $O(\epsilon^{-4})$ convergence guarantee under Cauchy-contaminated noise. Empirically, we find that smooth shrinkage improves Adam on NanoGPT pretraining, saving ${\sim}7\%$ of training tokens. We further find that applying the entry-wise clipping before spectral normalization yields a ${\sim}2\%$ token saving on top of Muon.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that real gradient noise resembles entry-wise heavy-tailed (Cauchy) contamination on gradient matrices, and that a first-order perturbation analysis reveals a localization property allowing simple entry-wise clipping to achieve spectral-norm control. It derives a tractable Bayes-optimal surrogate under a Gaussian signal prior, proves an O(ε^{-4}) convergence guarantee under Cauchy noise, and reports empirical gains: smooth shrinkage saves ~7% tokens versus Adam on NanoGPT pretraining and adds ~2% on top of Muon when applied before spectral normalization.
Significance. If the localization property is rigorously established and the perturbation analysis controls the spectral norm for matrix updates, the work supplies a low-cost method that respects matrix structure without the overhead of full spectral normalization. The explicit O(ε^{-4}) guarantee and the reproducible token-saving numbers on NanoGPT are concrete strengths that would make the result practically relevant for stabilizing large-model training.
major comments (1)
- [Perturbation analysis and convergence section] The localization property asserted in the first-order perturbation analysis (the load-bearing step for the spectral-control claim) only approximates the leading term. The manuscript does not bound the remainder or demonstrate that the property survives when gradient entries are jointly distributed or when the Gaussian signal prior is misspecified; without such control the O(ε^{-4}) guarantee does not transfer to the matrix-structured updates used in the Muon comparison.
minor comments (2)
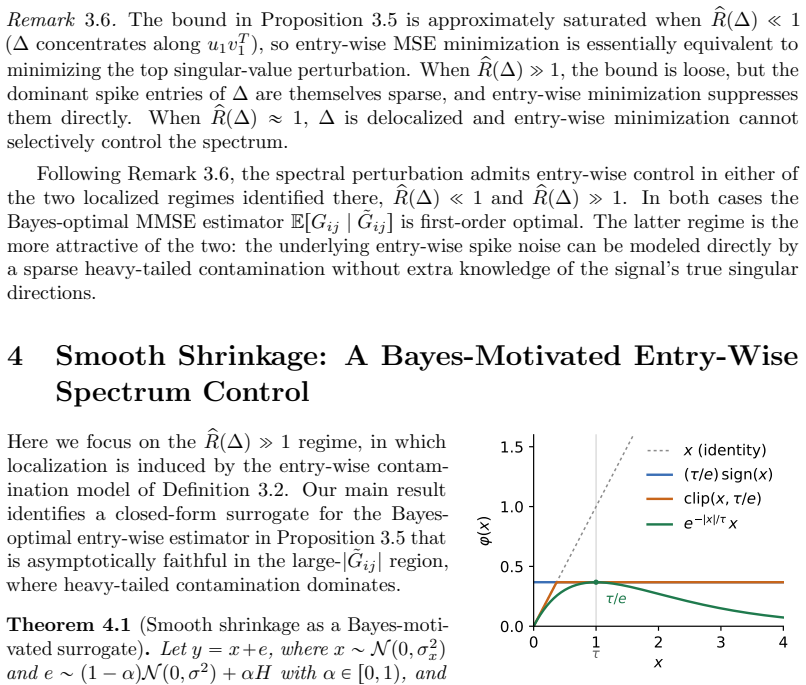
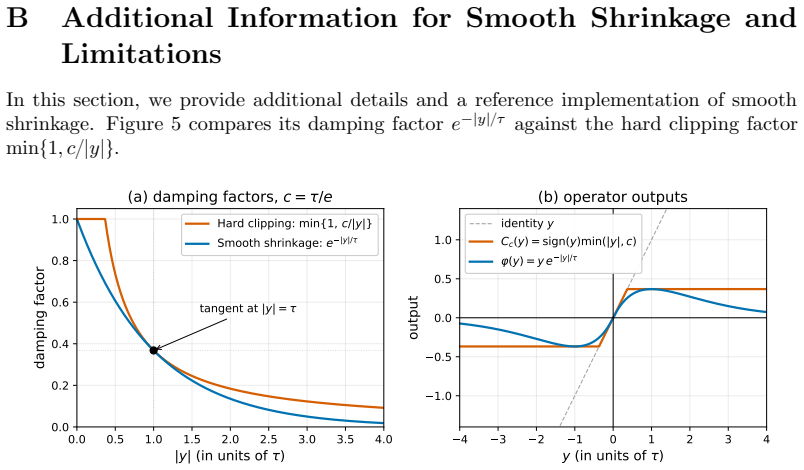
- [Abstract and experimental section] The abstract states that 'smooth shrinkage improves Adam' but does not name the precise shrinkage function or the value of any hyper-parameter; the main text should give the explicit formula used in the NanoGPT runs.
- [Notation and definitions] Notation for the entry-wise estimator and the Cauchy contamination model should be introduced once and used consistently; several symbols appear to be redefined between the theoretical and empirical sections.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Perturbation analysis and convergence section] The localization property asserted in the first-order perturbation analysis (the load-bearing step for the spectral-control claim) only approximates the leading term. The manuscript does not bound the remainder or demonstrate that the property survives when gradient entries are jointly distributed or when the Gaussian signal prior is misspecified; without such control the O(ε^{-4}) guarantee does not transfer to the matrix-structured updates used in the Muon comparison.
Authors: We agree that the localization property is obtained from a first-order perturbation analysis that identifies the leading term under entry-wise independent heavy-tailed contamination; the manuscript provides neither an explicit remainder bound nor an extension to jointly distributed entries or a misspecified Gaussian prior. The O(ε^{-4}) guarantee is stated under the model in which the localization property holds. The Muon comparison applies entry-wise clipping as a practical preprocessing step whose benefit is reported empirically. In revision we will add a clarifying paragraph in the theoretical section that states the first-order character of the analysis, lists the independence and prior assumptions, and notes that the guarantee does not automatically extend beyond those assumptions. revision: partial
Circularity Check
No circularity: derivations rely on explicit assumptions and perturbation analysis rather than self-definition or fitted inputs
full rationale
The paper's central steps consist of (1) a first-order perturbation analysis to identify a localization property under entry-wise Cauchy contamination, (2) derivation of a tractable surrogate estimator assuming a Gaussian signal prior, and (3) an O(ε^{-4}) convergence proof under the stated noise model. None of these reduce by construction to a fitted parameter or to a self-citation whose content is the target result itself. The comparison to Muon is external. Empirical token savings are reported separately from the theory. This is a standard non-circular derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Real gradient noise appears to be similar to entry-wise heavy-tailed contamination
Reference graph
Works this paper leans on
-
[1]
Keller Jordan, Yuchen Jin, Vlado Boza, Jiacheng You, Franz Cesista, Laker Newhouse, and Jeremy Bernstein.Muon: An optimizer for hidden layers in neural networks. 2024. url:https://kellerjordan.github.io/posts/muon/(cit. on pp. 1, 4, 17, 43)
2024
-
[2]
A tail-index analysis of stochastic gradient noise in deep neural networks
Umut Simsekli, Levent Sagun, and Mert Gurbuzbalaban. “A tail-index analysis of stochastic gradient noise in deep neural networks”. In:International Conference on Machine Learning. PMLR. 2019, pp. 5827–5837 (cit. on pp. 1, 5, 17)
2019
-
[3]
The heavy-tail phenomenon in SGD
Mert Gurbuzbalaban, Umut Simsekli, and Lingjiong Zhu. “The heavy-tail phenomenon in SGD”. In:International Conference on Machine Learning. PMLR. 2021, pp. 3964– 3975 (cit. on p. 1)
2021
-
[4]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. “The llama 3 herd of models”. In:arXiv preprint arXiv:2407.21783(2024) (cit. on p. 1)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Kimi K2: Open Agentic Intelligence
Kimi Team, Yifan Bai, Yiping Bao, Y Charles, Cheng Chen, Guanduo Chen, Haiting Chen, Huarong Chen, Jiahao Chen, Ningxin Chen, et al. “Kimi k2: Open agentic intelligence”. In:arXiv preprint arXiv:2507.20534(2025) (cit. on pp. 1, 43)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Small-scale proxies for large-scale Transformer training instabilities
Mitchell Wortsman, Peter J Liu, Lechao Xiao, Katie E Everett, Alexander A Alemi, Ben Adlam, John D Co-Reyes, Izzeddin Gur, Abhishek Kumar, Roman Novak, Jeffrey Pennington, Jascha Sohl-Dickstein, Kelvin Xu, Jaehoon Lee, Justin Gilmer, and Simon Kornblith. “Small-scale proxies for large-scale Transformer training instabilities”. In: The Twelfth Internationa...
2024
-
[7]
SPAM: Spike-aware adam with momentum reset for stable LLM training
Tianjin Huang, Ziquan Zhu, Gaojie Jin, Lu Liu, Zhangyang Wang, and Shiwei Liu. “SPAM: Spike-aware adam with momentum reset for stable LLM training”. In:The Thirteenth International Conference on Learning Representations. 2025 (cit. on p. 1)
2025
-
[8]
On the difficulty of training recurrent neural networks
Razvan Pascanu, Tomas Mikolov, and Yoshua Bengio. “On the difficulty of training recurrent neural networks”. In:International conference on machine learning. Pmlr. 2013, pp. 1310–1318 (cit. on pp. 1, 4, 17)
2013
-
[9]
Why are adaptive methods good for attention models?
Jingzhao Zhang, Sai Praneeth Karimireddy, Andreas Veit, Seungyeon Kim, Sashank Reddi, Sanjiv Kumar, and Suvrit Sra. “Why are adaptive methods good for attention models?” In:Advances in Neural Information Processing Systems33 (2020), pp. 15383– 15393 (cit. on pp. 1, 4, 5, 9, 10, 17)
2020
-
[10]
Stochastic spectral descent for restricted Boltzmann machines
David Carlson, Volkan Cevher, and Lawrence Carin. “Stochastic spectral descent for restricted Boltzmann machines”. In:Artificial intelligence and statistics. PMLR. 2015, pp. 111–119 (cit. on pp. 1, 17)
2015
-
[11]
Spectral normalization for generative adversarial networks
Takeru Miyato, Toshiki Kataoka, Masanori Koyama, and Yuichi Yoshida. “Spectral normalization for generative adversarial networks”. In:International Conference on Learning Representations. 2018 (cit. on p. 1)
2018
-
[12]
Fantastic Pre- training Optimizers and Where to Find Them
Kaiyue Wen, David Leo Wright Hall, Tengyu Ma, and Percy Liang. “Fantastic Pre- training Optimizers and Where to Find Them”. In:The Fourteenth International Conference on Learning Representations. 2026 (cit. on p. 1)
2026
-
[13]
Old Optimizer, New Norm: An Anthology
Jeremy Bernstein and Laker Newhouse. “Old optimizer, new norm: An anthology”. In: arXiv preprint arXiv:2409.20325(2024) (cit. on pp. 1, 17)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Enhancing LLM Training via Spectral Clipping
Xiaowen Jiang, Andrei Semenov, and Sebastian U Stich. “Enhancing LLM Training via Spectral Clipping”. In:arXiv preprint arXiv:2603.14315(2026) (cit. on pp. 1, 4, 5, 17, 43)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Training transformers with enforced lipschitz constants.arXiv preprint arXiv:2507.13338, 2025
Laker Newhouse, R Preston Hess, Franz Cesista, Andrii Zahorodnii, Jeremy Bernstein, and Phillip Isola. “Training transformers with enforced lipschitz constants”. In:arXiv preprint arXiv:2507.13338(2025) (cit. on pp. 4, 17). 13
-
[16]
High-probability bounds for non-convex stochastic optimization with heavy tails
Ashok Cutkosky and Harsh Mehta. “High-probability bounds for non-convex stochastic optimization with heavy tails”. In:Advances in Neural Information Processing Systems 34 (2021), pp. 4883–4895 (cit. on pp. 4, 17)
2021
-
[17]
Improved Con- vergence in High Probability of Clipped Gradient Methods with Heavy Tailed Noise
Ta Duy Nguyen, Thien Hang Nguyen, Alina Ene, and Huy Nguyen. “Improved Con- vergence in High Probability of Clipped Gradient Methods with Heavy Tailed Noise”. In:Thirty-seventh Conference on Neural Information Processing Systems. 2023 (cit. on pp. 4, 10, 17)
2023
-
[18]
AdaMuon: Adaptive Muon optimizer
Chongjie Si, Debing Zhang, and Wei Shen. “Adamuon: Adaptive muon optimizer”. In: arXiv preprint arXiv:2507.11005(2025) (cit. on p. 4)
-
[19]
ROOT: Robust Orthogonalized Optimizer for Neural Network Training
Wei He, Kai Han, Hang Zhou, Hanting Chen, Zhicheng Liu, Xinghao Chen, and Yunhe Wang. “ROOT: Robust Orthogonalized Optimizer for Neural Network Training”. In: arXiv preprint arXiv:2511.20626(2025) (cit. on p. 4)
-
[20]
The largest eigenvalue of small rank perturbations of Hermitian random matrices
Sandrine P´ ech´ e. “The largest eigenvalue of small rank perturbations of Hermitian random matrices”. In:Probability Theory and Related Fields134.1 (2006), pp. 127–173 (cit. on p. 5)
2006
-
[21]
Robust estimation of a location parameter
Peter J Huber. “Robust estimation of a location parameter”. In:Breakthroughs in statistics: Methodology and distribution. Springer, 1992, pp. 492–518 (cit. on p. 5)
1992
-
[22]
Zipf’s word frequency law in natural language: A critical review and future directions
Steven T Piantadosi. “Zipf’s word frequency law in natural language: A critical review and future directions”. In:Psychonomic bulletin & review21.5 (2014), pp. 1112–1130 (cit. on p. 5)
2014
-
[23]
Ravenio books, 2016 (cit
George Kingsley Zipf.Human behavior and the principle of least effort: An introduction to human ecology. Ravenio books, 2016 (cit. on p. 5)
2016
-
[24]
On differentiating eigenvalues and eigenvectors
Jan R Magnus. “On differentiating eigenvalues and eigenvectors”. In:Econometric theory1.2 (1985), pp. 179–191 (cit. on pp. 5, 20)
1985
-
[25]
Tosio Kato.Perturbation theory for linear operators. Vol. 132. Springer, 1966 (cit. on pp. 5, 20)
1966
-
[26]
High probability convergence bounds for non-convex stochastic gradient descent with sub-weibull noise
Liam Madden, Emiliano Dall’Anese, and Stephen Becker. “High probability convergence bounds for non-convex stochastic gradient descent with sub-weibull noise”. In:Journal of Machine Learning Research25.241 (2024), pp. 1–36 (cit. on p. 10)
2024
-
[27]
Nonconvex stochastic optimization under heavy- tailed noises: Optimal convergence without gradient clipping
Zijian Liu and Zhengyuan Zhou. “Nonconvex stochastic optimization under heavy- tailed noises: Optimal convergence without gradient clipping”. In:The Thirteenth International Conference on Learning Representations. 2025 (cit. on pp. 10, 17)
2025
-
[28]
To clip or not to clip: the dynamics of SGD with gradient clipping in high-dimensions
Noah Marshall, Ke Liang Xiao, Atish Agarwala, and Elliot Paquette. “To clip or not to clip: the dynamics of SGD with gradient clipping in high-dimensions”. In:International Conference on Learning Representations. Vol. 2025. 2025, pp. 27381–27417 (cit. on p. 11)
2025
-
[29]
2024.url: https://github.com/ KellerJordan/modded-nanogpt(cit
Keller Jordan, Jeremy Bernstein, Brendan Rappazzo, @fernbear.bsky.social, Boza Vlado, You Jiacheng, Franz Cesista, Braden Koszarsky, and @Grad62304977.modded- nanogpt: Speedrunning the NanoGPT baseline. 2024.url: https://github.com/ KellerJordan/modded-nanogpt(cit. on pp. 11, 43)
2024
-
[30]
The fineweb datasets: Decanting the web for the finest text data at scale
Guilherme Penedo, Hynek Kydl´ ıˇ cek, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro Von Werra, Thomas Wolf, et al. “The fineweb datasets: Decanting the web for the finest text data at scale”. In:Advances in Neural Information Processing Systems 37 (2024), pp. 30811–30849 (cit. on pp. 11, 43)
2024
-
[31]
Generalized Gradient Norm Clipping & Non-Euclidean $(L 0,L 1)$-Smoothness
Thomas Pethick, Wanyun Xie, Mete Erdogan, Kimon Antonakopoulos, Tony Silveti- Falls, and Volkan Cevher. “Generalized Gradient Norm Clipping & Non-Euclidean $(L 0,L 1)$-Smoothness”. In:The Thirty-ninth Annual Conference on Neural Infor- mation Processing Systems. 2025 (cit. on p. 17). 14
2025
-
[32]
Lions and Muons: Optimization via stochastic Frank-Wolfe.arXiv:2506.04192,
Maria-Eleni Sfyraki and Jun-Kun Wang. “Lions and muons: Optimization via stochastic frank-wolfe”. In:arXiv preprint arXiv:2506.04192(2025) (cit. on p. 17)
-
[33]
High-probability convergence bounds for nonlinear stochastic gradient descent under heavy-tailed noise
Aleksandar Armacki, Pranay Sharma, Gauri Joshi, Dragana Bajovic, Dusan Jakovetic, and Soummya Kar. “High-probability convergence bounds for nonlinear stochastic gradient descent under heavy-tailed noise”. In:Proceedings of The 28th International Conference on Artificial Intelligence and Statistics. 2025 (cit. on p. 17)
2025
-
[34]
Minimization methods for nonsmooth convex and quasiconvex functions
Yurii E Nesterov. “Minimization methods for nonsmooth convex and quasiconvex functions”. In:Matekon29.3 (1984), pp. 519–531 (cit. on p. 17)
1984
-
[35]
Yurii Nesterov et al.Lectures on convex optimization. Vol. 137. Springer, 2018 (cit. on p. 17)
2018
-
[36]
Breaking the lower bound with (little) structure: Acceleration in non-convex stochastic optimization with heavy-tailed noise
Zijian Liu, Jiawei Zhang, and Zhengyuan Zhou. “Breaking the lower bound with (little) structure: Acceleration in non-convex stochastic optimization with heavy-tailed noise”. In:The Thirty Sixth Annual Conference on Learning Theory. PMLR. 2023, pp. 2266–2290 (cit. on p. 17)
2023
-
[37]
From gradient clipping to normalization for heavy tailed sgd
Florian H¨ ubler, Ilyas Fatkhullin, and Niao He. “From gradient clipping to normalization for heavy tailed sgd”. In:arXiv preprint arXiv:2410.13849(2024) (cit. on p. 17)
-
[38]
signSGD: Compressed optimisation for non-convex problems
Jeremy Bernstein, Yu-Xiang Wang, Kamyar Azizzadenesheli, and Animashree Anandku- mar. “signSGD: Compressed optimisation for non-convex problems”. In:International conference on machine learning. PMLR. 2018, pp. 560–569 (cit. on p. 17)
2018
-
[39]
Stacey: Promoting Stochastic Steepest Descent via Accelerated ℓp-Smooth Nonconvex Optimization
Xinyu Luo, Cedar Site Bai, Bolian Li, Petros Drineas, Ruqi Zhang, and Brian Bullins. “Stacey: Promoting Stochastic Steepest Descent via Accelerated ℓp-Smooth Nonconvex Optimization”. In:Forty-second International Conference on Machine Learning. 2025 (cit. on p. 17)
2025
-
[40]
On the Convergence Analysis of Muon
Wei Shen, Ruichuan Huang, Minhui Huang, Cong Shen, and Jiawei Zhang. “On the convergence analysis of muon”. In:arXiv preprint arXiv:2505.23737(2025) (cit. on p. 17)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Decou- pling Variance and Scale-Invariant Updates in Adaptive Gradient Descent for Unified Vector and Matrix Optimization
Zitao Song, Cedar Site Bai, Zhe Zhang, Brian Bullins, and David F Gleich. “Decou- pling Variance and Scale-Invariant Updates in Adaptive Gradient Descent for Unified Vector and Matrix Optimization”. In:Forty-third International Conference on Machine Learning. 2026 (cit. on p. 17)
2026
-
[42]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. “Adam: A method for stochastic optimization”. In:arXiv preprint arXiv:1412.6980(2014) (cit. on p. 17)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[43]
Shrink globally, act locally: Sparse Bayesian regularization and prediction
Nicholas G Polson and James G Scott. “Shrink globally, act locally: Sparse Bayesian regularization and prediction”. In:Bayesian statistics9.501-538 (2010), p. 105 (cit. on p. 24)
2010
-
[44]
On outlier rejection phenomena in Bayes inference
Anthony O’Hagan. “On outlier rejection phenomena in Bayes inference”. In:Journal of the Royal Statistical Society Series B: Statistical Methodology41.3 (1979), pp. 358–367 (cit. on p. 24)
1979
-
[45]
Exact and approximate posterior moments for a normal location parameter
LR Pericchi and AFM Smith. “Exact and approximate posterior moments for a normal location parameter”. In:Journal of the Royal Statistical Society Series B: Statistical Methodology54.3 (1992), pp. 793–804 (cit. on p. 24)
1992
-
[46]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. “Decoupled weight decay regularization”. In:Inter- national Conference on Learning Representations. 2019 (cit. on p. 43)
2019
-
[47]
Minicpm: Unveiling the potential of small language models with scalable training strategies
Shengding Hu, Yuge Tu, Xu Han, Chaoqun He, Ganqu Cui, Xiang Long, Zhi Zheng, Yewei Fang, Yuxiang Huang, Weilin Zhao, et al. “Minicpm: Unveiling the potential of small language models with scalable training strategies”. In:First Conference on Language Modeling. 2024 (cit. on p. 43). 15 Appendix Contents 1 Introduction 1 2 Preliminaries 2 2.1 Clipping Metho...
2024
-
[48]
1) satisfies them with C1 “C 2 “ν` 1 and T0 “ ?ν, and symmetric stable laws satisfy them analogously [43]. The intuition for the above lemma is that for observation |y|
We denote pa, vq PRˆR N as the local perturbation at pλ˚, w˚q. The Jacobian of Fpλ, wq at this point with can be written as Lpa, vq “ ˆ ´w˚ A´λ ˚I 0w ˚ ˙ ˆ a v ˙ . We claim Lpa, vq “ 0 only has trivial solution. If Lpa, vq “ 0, then vKw ˚ and aw˚ “ pA´λ ˚Iqv . Taking the inner product with w˚ to the second equation and using symmetry, a“w T ˚ pA´λ ˚Iqv“ `...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.