REVIEW 3 major objections 3 cited by
Natural language is the action interface that finally lets interactive video world models control multiple entities at once and transfer actions across them.
Reviewed by Pith at T0; open to challenge. T0 means a machine referee read the full paper against a public rubric. the ladder, T0–T4 →
T0 review · grok-4.5
2026-07-14 18:51 UTC pith:JT2CNRU6
load-bearing objection Real multi-entity shared-camera control via per-frame NL slots, with careful three-axis eval; the Action-Index gap is partly confounded by text-encoder capacity but the system still stands. the 3 major comments →
Incantation: Natural Language as the Action Interface for Multi-Entity Video World Models
The pith
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper’s central claim is that natural language is the first action interface for multi-entity interactive video that jointly supplies open-vocabulary semantics and per-entity addressability. Conditioning a video world model at every latent frame with syntactically isolated entity prompts enables simultaneous multi-entity control under a shared viewpoint and concept-level cross-entity transfer—synthesizing both motion and visual concept on an entity that never performed the action in training—capabilities that discrete action indices, device inputs, and scene-level captions cannot deliver by construction.
What carries the argument
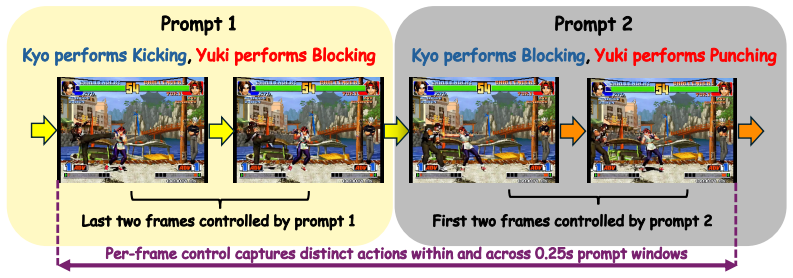
Per-frame language-conditioned attention: full bidirectional self-attention is kept over history frames to preserve pretrained video priors, while text cross-attention is restricted only to the noisy target frame so each action prompt steers its own timestep without contaminating committed history. Real-time long-horizon streaming comes from ODE-initialized Self-Forcing distillation plus a RoPE-decoupled sliding KV-cache that keeps memory and positions bounded.
Load-bearing premise
The large measured gaps rest on treating a joint-vocabulary action-index baseline as a fair stand-in for discrete control interfaces, even though natural language also brings extra pretrained capacity and an open input space the index model cannot match.
What would settle it
Retrain both interfaces on the same hybrid Margit–Crucible Knight data with capacity matched as closely as possible, then re-run the five cross-entity action pairs and four single-word OOV probes under the same blinded Action Control Accuracy protocol; if the action-index system closes the 89% vs 43% and 90% vs 0% gaps, the structural interface claim fails.
If this is right
- Multi-entity interactive worlds no longer need a separate hand-designed action vocabulary for every character and every engine.
- Cross-entity and cross-world transfer reduce to prompt wording and vocabulary-slot substitution rather than architecture redesign.
- Concept-level action transfer becomes a measurable modeling target instead of something rendering pipelines cannot express.
- The same recipe can be reapplied to visually unrelated games (shown on King of Fighters) with only per-entity action slots changed.
- Real-time multi-hour playable rollouts remain compatible with the language interface after two-step distillation (~19.7 FPS at 480p).
Where Pith is reading between the lines
- Because the interface only consumes per-entity captions, the same slots could be filled by VLM auto-labels or robot logs, turning game-memory supervision into a temporary testbed rather than a permanent requirement.
- A hybrid controller that keeps language for discrete semantics and adds a parallel continuous channel for camera pose or force would follow directly from the paper’s own limitation note without redesigning the attention pattern.
- If compositional text is doing the real work, a frozen text-initialized entity×action table should recover most of the cross-entity gap while still scoring zero on true OOV—exactly the collapse the appendix sketches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that the main bottleneck in multi-entity interactive video world models is the action interface: animation IDs, device inputs, and scene captions bind semantics to entities or engines and lack either open-vocabulary composition or per-entity addressability. It proposes natural language as a per-latent-frame (0.25 s), per-entity interface and presents Incantation, built on Wan 2.2 with bidirectional history self-attention, noisy-target-only text cross-attention, ODE-initialized Self-Forcing distillation, and a RoPE-decoupled sliding KV-cache. On Elden Ring combat data with engine-memory labels, a natural-language model beats a joint-vocabulary Action-Index baseline on cross-entity transfer (89% vs 43% ACA) and OOV prompts (90% vs 0%), while a 2-step student runs at 19.7 FPS with stable FVD over multi-hour rollouts; the same recipe is replicated on KOF by swapping action-vocabulary slots. A dataset preview is released.
Significance. If the interface claim holds, this is a clear contribution for interactive video world models: it identifies a structural limitation of prior control protocols, demonstrates simultaneous multi-entity control under one shared viewpoint (underserved in prior work), and shows concept-level cross-entity transfer and OOV coverage that discrete interfaces cannot express by construction. The systems package is substantial—architecture ablations (Table 5, Fig. 9), long-horizon FVD stability (Table 11), real-time pipeline with TAEHV (Table 13), blinded human ACA with inter-rater and McNemar support (App. A.7), and a carefully labeled multi-world gaming dataset. These are concrete, reproducible strengths even if the attribution of the Axis-2 gap needs tightening.
major comments (3)
- The central interface claim for Axis 2 is not fully isolated from capacity. §4.1 states that NL uses the pretrained text encoder into decoupled cross-attention while Action-Index uses a learnable linear projection of a joint one-hot, and explicitly calls the capacity asymmetry “inherent.” Appendix A.10 argues that frozen text-initialized factorized tables collapse into restricted NL and trainable ones revert to the joint-index baseline, but this is an argument, not an experiment. Without a controlled capacity-matched discrete baseline (e.g., frozen CLIP/Qwen/Wan embeddings over the closed joint vocabulary, or a trainable embedding table of comparable size and initialization), the 89% vs 43% cross-entity gap (Table 1 / Table 8) remains confounded between “compositional interface protocol” and “open-vocabulary encoder prior.” Axis 3 OOV (0% by construction for Action-Index) is structural;
- The “concept-level” cross-entity claim is stronger than the score distributions support on some tiers. The introduction and abstract claim the model must synthesize both motion and visual concept on an entity with no recording of the action. In Table 8, Tier II (Tail of the crucible on Margit) is 20/70/10 for NL—mostly partial—and the VLM judge is chance (Table 9). Tier I is stronger (65% full), but the paper should qualify “concept-level transfer” by tier (full vs partial execution, motion-only vs style transfer) rather than reporting a single 89% mean that mixes regimes of very different visual difficulty.
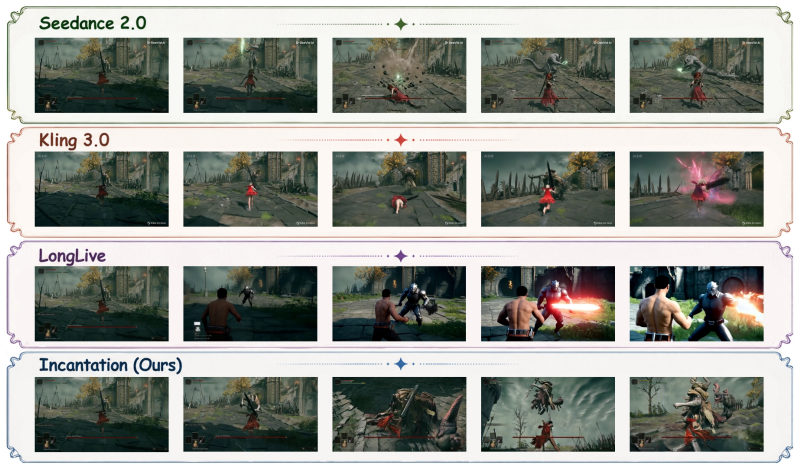
- External video baselines in Figure 5 / Table 2 are informative for visual quality but weak for the multi-entity control claim. Seedance 2.0 and LongLive are not interactive multi-entity world models; low trajectory-conditioned ACA is expected under mismatched interfaces and training. The manuscript correctly notes that no prior world model supports independent simultaneous multi-entity control in one holistic scene (Table 3). The fair comparison is therefore NL vs Action-Index under matched backbone and data; the commercial-model rows should be clearly labeled as qualitative / non-interactive references so they do not appear to support the interface superiority claim.
Circularity Check
Empirical systems paper: interface claims rest on held-out human ACA/FVD, not on identities that force the reported gaps by definition.
full rationale
Incantation’s load-bearing claims (cross-entity ACA 89% vs 43%, OOV 90% vs 0%, real-time 2-step student, KOF vocabulary-only transfer) are experimental measurements under fixed protocols, not first-principles derivations. Training labels are read from engine memory independently of the model; ACA is blinded human median rating on held-out rollouts; FVD uses I3D against held-out clips. The OOV Action-Index score of 0% is acknowledged as structural (no input slot outside the fixed vocabulary), which is a stated interface property rather than a fitted quantity renamed as a prediction. Self-citations (e.g. Matrix-Game / The Matrix) appear only as related work and do not underwrite uniqueness theorems or force the evaluation outcomes. Appendix A.10’s argument that stronger Action-Index variants collapse into NL is reasoning, not a circular reduction of the measured gaps. Capacity asymmetry between the pretrained text encoder and the one-hot linear baseline is a fairness/confound concern, not circularity. No self-definitional equations, fitted-input-as-prediction, or load-bearing self-citation chain was found.
Axiom & Free-Parameter Ledger
free parameters (5)
- Recent context length Kr =
7
- Local RoPE position cap C =
16 (ablation); 12 (timing table)
- Stage-1 / distillation learning rates and step counts =
lr 2e-5/1e-5; ODE 5e-6; SF 2e-6
- Student denoising steps =
2
- Prompt-injection warm-up duration =
2 seconds
axioms (6)
- domain assumption Natural language shares action semantics across entities by construction, so a phrase can request a move on an entity that never performed it in training.
- domain assumption Games with engine-memory instrumentation are a valid testbed for multi-entity interactive video world models because they supply zero-offset per-entity action labels at interactive rates.
- domain assumption Preserving bidirectional self-attention over history retains useful pretrained Wan 2.2 spatio-temporal priors better than imposing global causal masking.
- ad hoc to paper Blinded human Action Control Accuracy on a 0/1/2 ordinal scale is an adequate primary metric for compositional action steering in this nascent task.
- ad hoc to paper A joint-vocabulary one-hot Action-Index model is a steel-man of discrete animation-ID / device-input interfaces for fair comparison.
- standard math Standard diffusion / flow-matching training and Self-Forcing distillation mathematics apply without modification to this conditioning setup.
invented entities (3)
-
Per-entity parallel natural-language action slots at 0.25 s granularity
independent evidence
-
Frame-local (noisy-target-only) text cross-attention on a bidirectional history backbone
independent evidence
-
RoPE-decoupled sliding KV-cache (cache raw keys, apply RoPE on the fly)
independent evidence
read the original abstract
Modern interactive video world models have achieved impressive visual fidelity, yet lack fine-grained multi-entity control and cross-entity, cross-world generalization. We trace this gap to the action interface: standard control protocols (e.g. animation IDs, device inputs, scene-level captions) bind action semantics to specific entities or engines at design time. We propose natural language as the interface to unlock expressiveness that no prior interface can achieve, and we present Incantation, the first interactive video world model with per-latent-frame (0.25 s) natural-language conditioning that supports simultaneous multi-entity control and concept-level cross-entity transfer beyond any fixed rendering pipeline. We pair a pretrained bidirectional video backbone with frame-local text cross-attention, and enable real-time long-horizon streaming through ODE-initialized Self-Forcing distillation with a RoPE-decoupled sliding KV-cache. We surpass the Action-Index baseline on cross-entity transfer (89% vs. 43%) and out-of-vocabulary prompts (90% vs. 0%), and our 2-step student sustains 19.7 FPS at 480p with stable FVD over 2-hour rollouts. We further apply the same architecture and training recipe to The King of Fighters, changing only the per-entity action vocabulary slots. We have released a preview subset of the Incantation dataset at https://huggingface.co/datasets/zhush/incantation-elden-ring-scenes, containing manually collected Elden Ring player-boss combat clips with structured action-oriented metadata. Larger-scale Elden Ring and KOF data will be released with the full project.
Figures







Forward citations
Cited by 3 Pith papers
-
ShadowDancer: Teaching Video World Models Any Action by Learning Unified Dynamics Representations from a Video and Its Shadow
Cross-shadow prediction on appearance-resampled video pairs yields a unified latent dynamics interface that transfers demonstrated actions across environments better than prior latent-action and interactive world models.
-
StatePlay: State-Aware Game World Models for Mechanics-Consistent Generation
Coupling explicit state prediction with MoT-style video generation raises mechanics fidelity of Street Fighter 3 rollouts by about 18.6% over stateless game world models.
-
From Pixels to States: Rethinking Interactive World Models as Game Engines
Interactive world models are reorganized around the game-engine action-state-observation loop, and a 90-hour Black Myth: Wukong dataset with frame-aligned actions, ground-truth states, and observations is introduced.
Reference graph
Works this paper leans on
-
[1]
COMBAT: Conditional world models for behavioral agent training.arXiv preprint arXiv:2603.00825, 2026
Anmol Agarwal, Pranay Meshram, Sumer Singh, Saurav Suman, Andrew Lapp, Shahbuland Matiana, Louis Castricato, and Spencer Frazier. COMBAT: Conditional world models for behavioral agent training.arXiv preprint arXiv:2603.00825, 2026
arXiv 2026
-
[2]
Diffusion for world modeling: Visual details matter in Atari
Eloi Alonso, Adam Jelley, Vincent Micheli, Anssi Kanervisto, Amos Storkey, Tim Pearce, and François Fleuret. Diffusion for world modeling: Visual details matter in Atari. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[3]
Logic-guided vector fields for constrained generative modeling.arXiv preprint arXiv:2602.02009, 2026
Ali Baheri. Logic-guided vector fields for constrained generative modeling.arXiv preprint arXiv:2602.02009, 2026
Pith/arXiv arXiv 2026
-
[4]
Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
Pith/arXiv arXiv 2023
-
[5]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[6]
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Do- minik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, Varun Jampani, and Robin Rombach. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
Pith/arXiv arXiv 2023
-
[7]
Taehv: Tiny autoencoder for hunyuan video
Ollin Boer Bohan. Taehv: Tiny autoencoder for hunyuan video. https://github.com/ madebyollin/taehv, 2025
2025
-
[8]
Genie: Generative interactive environments
Jake Bruce, Michael Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[9]
GameGen-X: Interactive open-world game video generation
Haoxuan Che, Xuanhua He, Quande Liu, Cheng Jin, and Hao Chen. GameGen-X: Interactive open-world game video generation. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[10]
Christopher, Michael Cardei, Jinhao Liang, and Ferdinando Fioretto
Jacob K. Christopher, Michael Cardei, Jinhao Liang, and Ferdinando Fioretto. Neuro-symbolic generative diffusion models for physically grounded, robust, and safe generation. InProceedings of the International Conference on Neuro-Symbolic Systems, volume 288 ofProceedings of Machine Learning Research, pages 188–213. PMLR, 2025
2025
-
[11]
Oasis: A universe in a transformer
Decart AI and Etched AI. Oasis: A universe in a transformer. https://oasis-model. github.io/, 2024. 10
2024
-
[12]
Zicheng Duan, Jiatong Xia, Zeyu Zhang, Wenbo Zhang, Gengze Zhou, Chenhui Gou, Yefei He, Feng Chen, Xinyu Zhang, and Lingqiao Liu. LiveWorld: Simulating out-of-sight dynamics in generative video world models.arXiv preprint arXiv:2603.07145, 2026
arXiv 2026
-
[13]
Ruili Feng, Han Zhang, Zhantao Yang, Jie Xiao, Zhilei Shu, Zhiheng Liu, Andy Zheng, Yukun Huang, Yu Liu, and Hongyang Zhang. The matrix: Infinite-horizon world generation with real-time moving control.arXiv preprint arXiv:2412.03568, 2024
Pith/arXiv arXiv 2024
-
[14]
Artur d’Avila Garcez and Luis C. Lamb. Neural-symbolic learning and reasoning: A survey and interpretation. InNeuro-Symbolic Artificial Intelligence: The State of the Art, volume 342 ofFrontiers in Artificial Intelligence and Applications, pages 1–51. IOS Press, 2022
2022
-
[15]
Genie 3: A new frontier for world models
Google DeepMind. Genie 3: A new frontier for world models. https://deepmind.google/ blog/genie-3-a-new-frontier-for-world-models/, 2025. Google DeepMind Blog
2025
-
[16]
Junliang Guo, Yang Ye, Tianyu He, Haoyu Wu, Yushu Jiang, Tim Pearce, and Jiang Bian. MineWorld: A real-time and open-source interactive world model on Minecraft.arXiv preprint arXiv:2504.08388, 2025
Pith/arXiv arXiv 2025
-
[17]
Recurrent world models facilitate policy evolution
David Ha and Jürgen Schmidhuber. Recurrent world models facilitate policy evolution. In Advances in Neural Information Processing Systems (NeurIPS), 2018
2018
-
[18]
Mastering diverse control tasks through world models.Nature, 640:647–653, 2025
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse control tasks through world models.Nature, 640:647–653, 2025
2025
-
[19]
LM- Infinite: Zero-shot extreme length generalization for large language models
Chi Han, Qifan Wang, Hao Peng, Wenhan Xiong, Yu Chen, Heng Ji, and Sinong Wang. LM- Infinite: Zero-shot extreme length generalization for large language models. InProceedings of the Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), pages 3991–4008, 2024
2024
-
[20]
Xianglong He, Chunli Peng, Zexiang Liu, Boyang Wang, Yifan Zhang, Qi Cui, Fei Kang, Biao Jiang, Mengyin An, Yangyang Ren, Baixin Xu, Hao-Xiang Guo, Kaixiong Gong, Size Wu, Wei Li, Xuchen Song, Yang Liu, Yangguang Li, and Yahui Zhou. Matrix-game 2.0: An open-source real-time and streaming interactive world model.arXiv preprint arXiv:2508.13009, 2025
Pith/arXiv arXiv 2025
-
[21]
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J. Fleet. Video diffusion models. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[22]
Vid2World: Crafting video diffusion models to interactive world models
Siqiao Huang, Jialong Wu, Qixing Zhou, Shangchen Miao, and Mingsheng Long. Vid2World: Crafting video diffusion models to interactive world models. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[23]
Self forcing: Bridging the train-test gap in autoregressive video diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[24]
Kling AI launches 3.0 model, ushering in an era where everyone can be a director
Kuaishou Technology. Kling AI launches 3.0 model, ushering in an era where everyone can be a director. https://ir.kuaishou.com/news-releases/news-release-details/ kling-ai-launches-30-model-ushering-era-where-everyone-can-be , February
-
[25]
Accessed: 2026-05-01
2026
-
[26]
Retrieval-augmented generation for knowledge-intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[27]
Wang Lin, Liyu Jia, Wentao Hu, Kaihang Pan, Zhongqi Yue, Wei Zhao, Jingyuan Chen, Fei Wu, and Hanwang Zhang. Reasoning physical video generation with diffusion timestep tokens via reinforcement learning.arXiv preprint arXiv:2504.15932, 2025
Pith/arXiv arXiv 2025
-
[28]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InInternational Conference on Learning Representations (ICLR), 2023. 11
2023
-
[29]
Genie 2: A large-scale foundation world model
Jack Parker-Holder, Philip Ball, Jake Bruce, Vibhavari Dasagi, Kristian Holsheimer, Christos Kaplanis, Alexandre Moufarek, Guy Scully, Jeremy Shar, Jimmy Shi, et al. Genie 2: A large-scale foundation world model. https://deepmind.google/blog/ genie-2-a-large-scale-foundation-world-model/, 2024. Google DeepMind Blog
2024
-
[30]
Ryan Po, David Junhao Zhang, Amir Hertz, Gordon Wetzstein, Neal Wadhwa, and Nataniel Ruiz. MultiGen: Level-design for editable multiplayer worlds in diffusion game engines.arXiv preprint arXiv:2603.06679, 2026
arXiv 2026
-
[31]
A VID: Adapting video diffusion models to world models
Marc Rigter, Tarun Gupta, Agrin Hilmkil, and Chao Ma. A VID: Adapting video diffusion models to world models. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[32]
Solaris: Building a multiplayer video world model in Minecraft.arXiv preprint arXiv:2602.22208, 2026
Georgy Savva, Oscar Michel, Daohan Lu, Suppakit Waiwitlikhit, Timothy Meehan, Dhairya Mishra, Srivats Poddar, Jack Lu, and Saining Xie. Solaris: Building a multiplayer video world model in Minecraft.arXiv preprint arXiv:2602.22208, 2026
arXiv 2026
-
[33]
Zero-shot conditioning of score-based diffusion models by neuro-symbolic constraints
Davide Scassola, Sebastiano Saccani, Ginevra Carbone, and Luca Bortolussi. Zero-shot conditioning of score-based diffusion models by neuro-symbolic constraints. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 20302–20309, 2025
2025
-
[34]
Team Seedance, De Chen, Liyang Chen, Xin Chen, Ying Chen, Zhuo Chen, Zhuowei Chen, Feng Cheng, Tianheng Cheng, Yufeng Cheng, Mojie Chi, Xuyan Chi, Jian Cong, Qinpeng Cui, Fei Ding, Qide Dong, Yujiao Du, Haojie Duanmu, Junliang Fan, Jiarui Fang, Jing Fang, Zetao Fang, Chengjian Feng, Yu Gao, Diandian Gu, Dong Guo, Hanzhong Guo, Qiushan Guo, Boyang Hao, Hon...
Pith/arXiv arXiv 2026
-
[35]
BlendRL: A framework for merging symbolic and neural policy learning
Hikaru Shindo, Quentin Delfosse, Devendra Singh Dhami, and Kristian Kersting. BlendRL: A framework for merging symbolic and neural policy learning. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[36]
Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al
David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. Mastering the game of Go with deep neural networks and tree search.Nature, 529:484–489, 2016
2016
-
[37]
Wenqiang Sun, Haiyu Zhang, Haoyuan Wang, Junta Wu, Zehan Wang, Zhenwei Wang, Yunhong Wang, Jun Zhang, Tengfei Wang, and Chunchao Guo. WorldPlay: Towards long-term geometric consistency for real-time interactive world modeling.arXiv preprint arXiv:2512.14614, 2025. 12
Pith/arXiv arXiv 2025
-
[38]
Junshu Tang, Jiacheng Liu, Jiaqi Li, Longhuang Wu, Haoyu Yang, Penghao Zhao, Siruis Gong, Xiang Yuan, Shuai Shao, Linfeng Zhang, and Qinglin Lu. Hunyuan-gamecraft-2: Instruction- following interactive game world model.arXiv preprint arXiv:2511.23429, 2025
arXiv 2025
-
[39]
Advancing open-source world models
Robbyant Team, Zelin Gao, Qiuyu Wang, Yanhong Zeng, Jiapeng Zhu, Ka Leong Cheng, Yixuan Li, Hanlin Wang, Yinghao Xu, Shuailei Ma, et al. Advancing open-source world models. arXiv preprint arXiv:2601.20540, 2026
Pith/arXiv arXiv 2026
-
[40]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Wan Team, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[41]
Diffusion models are real-time game engines
Dani Valevski, Yaniv Leviathan, Moab Arar, and Shlomi Fruchter. Diffusion models are real-time game engines. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[42]
Czarnecki, Michaël Mathieu, Andrew Dudzik, Junyoung Chung, David H
Oriol Vinyals, Igor Babuschkin, Wojciech M. Czarnecki, Michaël Mathieu, Andrew Dudzik, Junyoung Chung, David H. Choi, Richard Powell, Timo Ewalds, Petko Georgiev, et al. Grand- master level in StarCraft II using multi-agent reinforcement learning.Nature, 575:350–354, 2019
2019
-
[43]
Memory networks.arXiv preprint arXiv:1410.3916, 2014
Jason Weston, Sumit Chopra, and Antoine Bordes. Memory networks.arXiv preprint arXiv:1410.3916, 2014
Pith/arXiv arXiv 2014
-
[44]
Ruiqi Wu, Xuanhua He, Meng Cheng, Tianyu Yang, Yong Zhang, Zhuoliang Kang, Xunliang Cai, Xiaoming Wei, Chunle Guo, Chongyi Li, and Ming-Ming Cheng. Infinite-World: Scaling interactive world models to 1000-frame horizons via pose-free hierarchical memory.arXiv preprint arXiv:2602.02393, 2026
arXiv 2026
-
[45]
Efficient streaming language models with attention sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[46]
Longlive: Real-time interactive long video generation.arXiv preprint arXiv:2509.22622, 2025
Shuai Yang, Wei Huang, Ruihang Chu, Yicheng Xiao, Yuyang Zhao, Xianbang Wang, Muyang Li, Enze Xie, Yingcong Chen, Yao Lu, et al. Longlive: Real-time interactive long video generation.arXiv preprint arXiv:2509.22622, 2025
Pith/arXiv arXiv 2025
-
[47]
Freeman, and Taesung Park
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Frédo Durand, William T. Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6613–6623, 2024
2024
-
[48]
GameFactory: Creating new games with generative interactive videos
Jiwen Yu, Yiran Qin, Xintao Wang, Pengfei Wan, Di Zhang, and Xihui Liu. GameFactory: Creating new games with generative interactive videos. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 11590–11599, 2025
2025
-
[49]
Matrix-game: Interactive world foundation model.arXiv preprint arXiv:2506.18701, 2025
Yifan Zhang, Chunli Peng, Boyang Wang, Puyi Wang, Qingcheng Zhu, Fei Kang, Biao Jiang, Zedong Gao, Eric Li, Yang Liu, and Yahui Zhou. Matrix-game: Interactive world foundation model.arXiv preprint arXiv:2506.18701, 2025
Pith/arXiv arXiv 2025
-
[50]
Neuro-symbolic synergy for interactive world modeling.arXiv preprint arXiv:2602.10480, 2026
Hongyu Zhao, Siyu Zhou, Haolin Yang, Zengyi Qin, and Tianyi Zhou. Neuro-symbolic synergy for interactive world modeling.arXiv preprint arXiv:2602.10480, 2026
arXiv 2026
-
[51]
Jiayi Zhu, Jianing Zhang, Yiying Yang, Wei Cheng, and Xiaoyun Yuan. ShareVerse: Multi-agent consistent video generation for shared world modeling.arXiv preprint arXiv:2603.02697, 2026. 13 Table 3: Systematic comparison of interactive video world models. ✓ = supported, ✗ = not supported, ∼ = partial.Multi-entityrequires independent and simultaneous control...
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.