Policy Gradient for Continuous-Time Mean-Field Control
Pith reviewed 2026-05-21 04:11 UTC · model grok-4.3
The pith
Policy gradients for continuous-time mean-field control follow directly from an explicit Gâteaux formula in the value function and instantaneous advantage function.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
After computing the value function under a fixed randomized feedback policy, the policy gradient is obtained directly via an explicit Gâteaux formula in terms of the value function and the instantaneous advantage function, without solving an additional equation.
What carries the argument
The Gâteaux policy-gradient formula expressed through the instantaneous advantage function that quantifies the gain of taking a given action relative to the current randomized policy.
If this is right
- The method produces a model-based actor-critic scheme in which the critic solves the linear stationary HJB equation and the actor updates via the derived explicit gradient formula.
- Well-posedness of the underlying PDE is established in the chosen polynomial-growth function class with cylindrical dependence on the population law.
- The approach is illustrated by numerical experiments on an LQR model and a crowd-motion problem.
Where Pith is reading between the lines
- The single-PDE-per-iteration structure could reduce the number of coupled solves required in high-dimensional or many-agent control settings compared with methods that recompute a gradient-specific equation.
- The cylindrical-function representation of measure dependence may transfer to other control problems where the state law enters the dynamics or cost.
- The explicit advantage-based variation formula invites direct comparison with discrete-time mean-field policy gradients obtained by taking continuous-time limits.
Load-bearing premise
The value function belongs to a suitable polynomial-growth function class in which the linear stationary HJB equation is well-posed when the population law is represented via cylindrical functions.
What would settle it
A direct numerical check in which a small policy perturbation produces an objective change that fails to match the directional derivative predicted by the Gâteaux formula applied to the computed value function.
Figures


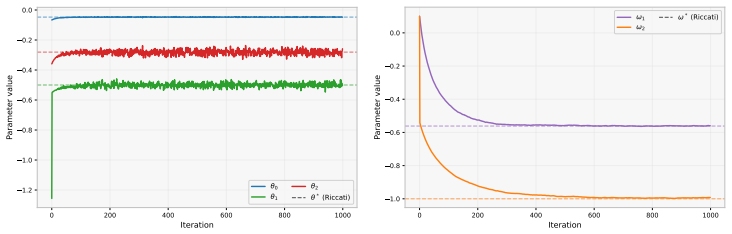
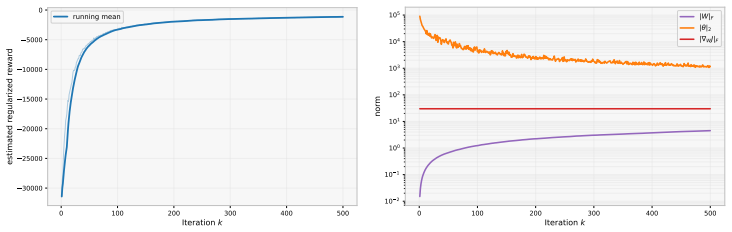


read the original abstract
This paper develops a policy gradient method for entropy-regularized mean-field control in the discounted infinite-horizon setting. We consider randomized feedback policies and a coupled representative-particle/population system, in which the representative state evolves jointly with a population law governed by a McKean--Vlasov equation. The resulting value function is therefore defined on the product space $\mathbb R^d \times \mathcal P_2(\mathbb R^d)$. A key distinction from existing policy gradient methods for mean-field control is that, after computing the value function under a fixed policy, our approach does not require solving an additional equation to obtain the policy gradient. Instead, we derive an explicit policy gradient formula directly in terms of the value function. The formulation is based on an instantaneous advantage function, which quantifies the gain of taking a given action relative to the current randomized policy. We establish a G\^ateaux policy-gradient formula, which gives the first-order variation of the objective along arbitrary policy perturbations, and then derive the corresponding ascent direction under finite-dimensional policy parametrization. The resulting formula leads to a model-based actor--critic scheme. The critic is obtained by solving the associated linear stationary Hamilton--Jacobi--Bellman equation for the value function, using cylindrical functions to represent dependence on the population law. The actor is then updated according to the derived policy-gradient formula. We further analyze the well-posedness of the PDE in a polynomial-growth function class. Finally, we illustrate the proposed method through numerical experiments on an LQR model and a crowd-motion problem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a policy gradient method for entropy-regularized mean-field control in the continuous-time, discounted infinite-horizon setting. It considers randomized feedback policies acting on a coupled representative-particle and population system whose law evolves according to a McKean-Vlasov equation. The central contribution is an explicit Gâteaux formula expressing the first-order variation of the objective directly in terms of the value function and an instantaneous advantage function, obtained after solving only the linear stationary HJB equation; this yields a model-based actor-critic scheme in which the critic uses cylindrical functions to represent measure dependence and the actor is updated via the derived ascent direction. Well-posedness of the PDE is established in a polynomial-growth function class, and the method is illustrated numerically on an LQR example and a crowd-motion problem.
Significance. If the Gâteaux formula is valid, the approach offers a genuine simplification by eliminating the need for an auxiliary equation to compute the policy gradient, which is a practical advantage in mean-field settings. The combination of the explicit formula, cylindrical-function representation, and well-posedness result in a polynomial-growth class supplies a coherent theoretical framework. The numerical experiments on standard benchmark problems provide concrete evidence of implementability, although their scope remains limited to linear-quadratic and simple interaction models.
minor comments (3)
- [Abstract] The abstract states that the value function is defined on R^d × P_2(R^d) but does not indicate whether the cylindrical-function representation is introduced before or after the Gâteaux derivation; a brief forward reference would improve readability.
- [Well-posedness analysis] In the well-posedness analysis, the precise polynomial-growth exponents and the constants appearing in the a-priori estimates are not restated in the main theorem statement; adding them would make the result self-contained.
- [Numerical experiments] The numerical section reports results for the LQR and crowd-motion examples but does not specify the discretization parameters (time step, number of particles, or basis size for the cylindrical functions); these details are needed for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful and accurate summary of our work, as well as the positive assessment of its significance. The recommendation for minor revision is appreciated. We note that the major comments section of the report is empty, so we have no specific points requiring point-by-point rebuttal at this stage. We are happy to implement any minor clarifications or improvements the editor or referee may suggest in the next version.
Circularity Check
No significant circularity
full rationale
The derivation computes the value function by solving the linear stationary HJB equation under a fixed randomized feedback policy, then obtains the policy gradient via an explicit Gâteaux formula expressed directly in terms of that value function and the instantaneous advantage function. The HJB residual is used to absorb future costs and measure-coupling effects, so the gradient expression does not reduce to a fitted parameter, a renamed input, or a self-citation chain. The central claim therefore retains independent mathematical content and is self-contained against the stated well-posedness assumptions on polynomial-growth cylindrical functions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The McKean-Vlasov equation governing the population law admits a unique solution for the chosen randomized feedback policies.
- domain assumption The value function lies in a polynomial-growth function class where the linear stationary HJB equation is well-posed under cylindrical representations of the population measure.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
after computing the value function under a fixed randomized feedback policy, the policy gradient can be obtained directly via an explicit Gâteaux formula in terms of the value function and the instantaneous advantage function, without solving an additional equation
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat ≃ Nat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
linear stationary Hamilton–Jacobi–Bellman equation ... using cylindrical functions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mean field type control with congestion.Applied Mathematics & Optimization, 73(3):393–418, 2016
Yves Achdou and Mathieu Lauri` ere. Mean field type control with congestion.Applied Mathematics & Optimization, 73(3):393–418, 2016
work page 2016
-
[2]
Mean field type control with congestion II: An augmented lagrangian method
Yves Achdou and Mathieu Lauri` ere. Mean field type control with congestion II: An augmented lagrangian method. Applied Mathematics & Optimization, 74(3):535–578, 2016
work page 2016
-
[3]
Daniel Andersson and Boualem Djehiche. A maximum principle for SDEs of mean-field type.Applied Mathematics and Optimization, 63(3):341–356, 2011
work page 2011
-
[4]
Alex Ayoub, Zeyu Jia, Csaba Szepesv´ ari, Mengdi Wang, and Lin F. Yang. Model-based reinforcement learning with value-targeted regression. InProceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 463–474. PMLR, 2020
work page 2020
-
[5]
Leemon C. Baird. Reinforcement learning in continuous time: advantage updating.Proceedings of 1994 IEEE Inter- national Conference on Neural Networks (ICNN’94), 4:2448–2453 vol.4, 1994
work page 1994
-
[6]
Matteo Basei and Huyˆ en Pham. A weak martingale approach to linear-quadratic McKean–Vlasov stochastic control problems.Journal of Optimization Theory and Applications, 181(2):347–382, 2019
work page 2019
-
[7]
Erhan Bayraktar, Hang Cheung, Ibrahim Ekren, Jinniao Qiu, Ho Man Tai, and Xin Zhang. Viscosity solutions of fully second-order hjb equations in the wasserstein space.SIAM Journal on Control and Optimization, 2026. To appear
work page 2026
-
[8]
Erhan Bayraktar, Andrea Cosso, and Huyˆ en Pham. Randomized dynamic programming principle and feynman–kac representation for optimal control of mckean–vlasov dynamics.Transactions of the American Mathematical Society, 370(3):2115–2165, 2018
work page 2018
-
[9]
Erhan Bayraktar, Ibrahim Ekren, Xihao He, and Xin Zhang. Comparison for semi-continuous viscosity solutions for second order pdes on the wasserstein space.Journal of Differential Equations, 455:1–31, 2026
work page 2026
-
[10]
Erhan Bayraktar, Ibrahim Ekren, and Xin Zhang. Comparison of viscosity solutions for a class of second-order pdes on the wasserstein space.Communications in Partial Differential Equations, 50(4):570–613, 2025
work page 2025
-
[11]
Erhan Bayraktar, Ibrahim Ekren, and Xin Zhang. Convergence rate of particle system for second-order pdes on wasserstein space.SIAM Journal on Control and Optimization, 63(3):1515–1782, 2025
work page 2025
-
[12]
Erhan Bayraktar, Martin Hernandez, Qinxin Yan, and Yuhua Zhu. Mean-field phibe: Continuous-time mean-field reinforcement learning from discrete-time data.Preprint, 2026. arXiv preprint
work page 2026
-
[13]
Ergodicity and turnpike properties of linear-quadratic mean field control problems
Erhan Bayraktar and Jiamin Jian. Ergodicity and turnpike properties of linear-quadratic mean field control problems. arXiv preprint, 2024
work page 2024
-
[14]
Erhan Bayraktar and Jiamin Jian. Convergence and turnpike properties of linear-quadratic mean field control problems with common noise.arXiv preprint arXiv, 2025
work page 2025
-
[15]
Erhan Bayraktar and Ali Devran Kara. Learning with linear function approximations in mean-field control.Journal of Machine Learning Research, 26(192):1–53, 2025
work page 2025
-
[16]
Erhan Bayraktar, Ruoyu Wu, and Xin Zhang. Propagation of chaos of forward-backward stochastic differential equa- tions with graphon interactions.Applied Mathematics and Optimization, 88(1):Article 25, 2023
work page 2023
-
[17]
Alain Bensoussan, Jens Frehse, and Phillip Yam.Mean field games and mean field type control theory. SpringerBriefs in Mathematics. Springer, New York, 2013. 36
work page 2013
-
[18]
Benoˆ ıt Bonnet and Francesco Rossi. The pontryagin maximum principle in the wasserstein space.Calculus of Varia- tions and Partial Differential Equations, 58:1–36, 2017
work page 2017
-
[19]
Rainer Buckdahn, Boualem Djehiche, and Juan Li. A general maximum principle for SDEs of mean-field type.Applied Mathematics and Optimization, 64(2):197–216, 2011
work page 2011
-
[20]
Rainer Buckdahn, Juan Li, Shige Peng, and Chao Rainer. Mean-field stochastic differential equations and associated pdes.Annals of Probability, 45(2):824–878, 2017
work page 2017
-
[21]
Matteo Burzoni, Vincenzo Ignazio, A. Max Reppen, and H. Mete Soner. Viscosity solutions for controlled McKean– Vlasov jump-diffusions.SIAM Journal on Control and Optimization, 58(3):1676–1699, 2020
work page 2020
-
[22]
Society for Industrial and Applied Mathematics (SIAM), Philadelphia, PA, 2016
Ren´ e Carmona.Lectures on BSDEs, stochastic control, and stochastic differential games with financial applications, volume 1 ofFinancial Mathematics. Society for Industrial and Applied Mathematics (SIAM), Philadelphia, PA, 2016
work page 2016
-
[23]
Ren´ e Carmona and Fran¸ cois Delarue. Forward–backward stochastic differential equations and controlled McKean– Vlasov dynamics.Annals of Probability, 43(5):2647–2700, 2015
work page 2015
-
[24]
I, volume 83 of Probability Theory and Stochastic Modelling
Ren´ e Carmona and Fran¸ cois Delarue.Probabilistic theory of mean field games with applications. I, volume 83 of Probability Theory and Stochastic Modelling. Springer, Cham, 2018. Mean field FBSDEs, control, and games
work page 2018
-
[25]
II, volume 84 of Probability Theory and Stochastic Modelling
Ren´ e Carmona and Fran¸ cois Delarue.Probabilistic theory of mean field games with applications. II, volume 84 of Probability Theory and Stochastic Modelling. Springer, Cham, 2018. Mean field games with common noise and master equations
work page 2018
-
[26]
Control of McKean–Vlasov dynamics versus mean field games
Ren´ e Carmona, Fran¸ cois Delarue, and Aim´ e Lachapelle. Control of McKean–Vlasov dynamics versus mean field games. Mathematics and Financial Economics, 7(2):131–166, 2013
work page 2013
-
[27]
Mean field games and systemic risk.Communications in Mathematical Sciences, 13(4):911–933, 2015
Ren´ e Carmona, Jean-Pierre Fouque, and Li-Hsien Sun. Mean field games and systemic risk.Communications in Mathematical Sciences, 13(4):911–933, 2015
work page 2015
-
[28]
Ren´ e Carmona and Mathieu Lauri` ere. Convergence analysis of machine learning algorithms for the numerical solution of mean field control and games: II — the finite horizon case.Annals of Applied Probability, 32(6):4065–4105, 2022
work page 2022
-
[29]
Ren´ e Carmona, Mathieu Lauri` ere, and Zongjun Tan. Linear-quadratic mean-field reinforcement learning: Convergence of policy gradient methods.Preprint arXiv:1910.04295, 2019
-
[30]
Carrillo, Young-Pil Choi, and Maxime Hauray
Jos´ e A. Carrillo, Young-Pil Choi, and Maxime Hauray. The derivation of swarming models: Mean-field limit and Wasserstein distances. InCollective Dynamics from Bacteria to Crowds, CISM International Centre for Mechanical Sciences, pages 1–46. Springer, 2014
work page 2014
-
[31]
Carrillo, Massimo Fornasier, Giuseppe Toscani, and Francesco Vecil
Jos´ e A. Carrillo, Massimo Fornasier, Giuseppe Toscani, and Francesco Vecil. Particle, kinetic, and hydrodynamic models of swarming. InMathematical Modeling of Collective Behavior in Socio-Economic and Life Sciences, Modeling and Simulation in Science, Engineering and Technology, pages 297–336. Birkh¨ auser Boston, 2010
work page 2010
-
[32]
Propagation of chaos: A review of models, methods and applications
Louis-Pierre Chaintron and Antoine Diez. Propagation of chaos: A review of models, methods and applications. I. models and methods.Kinetic and Related Models, 15(6):895–1015, 2022
work page 2022
-
[33]
Jean-Fran¸ cois Chassagneux, Dan Crisan, and Fran¸ cois Delarue. Numerical method for FBSDEs of McKean–Vlasov type.Annals of Applied Probability, 29(3):1640–1684, 2019
work page 2019
-
[34]
Emergent behavior in flocks.IEEE Transactions on Automatic Control, 52(5):852–862, 2007
Felipe Cucker and Steve Smale. Emergent behavior in flocks.IEEE Transactions on Automatic Control, 52(5):852–862, 2007
work page 2007
-
[35]
Mao Fabrice Djete, Dylan Possama¨ ı, and Xiaolu Tan. Mckean–vlasov optimal control: Limit theory and equivalence between different formulations.Mathematics of Operations Research, 47(4):2891–2930, 2022
work page 2022
-
[36]
Nicole El Karoui and Sylvie M´ el´ eard. Martingale measures and stochastic calculus.Probability Theory and Related Fields, 84(1–2):83–101, 1990
work page 1990
-
[37]
Actor-critic learning for mean-field control in continuous time.J
Noufel Frikha, Maximilien Germain, Mathieu Lauriere, Huyˆ en Pham, and Xuanye Song. Actor-critic learning for mean-field control in continuous time.J. Mach. Learn. Res., 26:Paper No. [127], 42, 2025
work page 2025
- [38]
-
[39]
Hamilton-Jacobi equations in the Wasserstein space.Methods Appl
Wilfrid Gangbo, Truyen Nguyen, and Adrian Tudorascu. Hamilton-Jacobi equations in the Wasserstein space.Methods Appl. Anal., 15(2):155–183, 2008
work page 2008
-
[40]
Opinion dynamics and bounded confidence: Models, analysis and simulation
Rainer Hegselmann and Ulrich Krause. Opinion dynamics and bounded confidence: Models, analysis and simulation. Journal of Artificial Societies and Social Simulation, 5(3), 2002
work page 2002
-
[41]
Howard.Dynamic programming and Markov processes
Ronald A. Howard.Dynamic programming and Markov processes. Technology Press of M.I.T., Cambridge, MA; John Wiley & Sons, Inc., New York-London, 1960
work page 1960
-
[42]
Jianhui Huang, Xun Li, and Jiongmin Yong. A linear-quadratic optimal control problem for mean-field stochastic differential equations in infinite horizon.Math. Control Relat. Fields, 5(1):97–139, 2015
work page 2015
-
[43]
Infinite horizon value functions in the Wasserstein spaces.J
Ryan Hynd and Hwa Kil Kim. Infinite horizon value functions in the Wasserstein spaces.J. Differential Equations, 258(6):1933–1966, 2015
work page 1933
-
[44]
Accuracy of discretely sampled stochastic policies in continuous-time reinforcement learning
Yanwei Jia, Du Ouyang, and Yufei Zhang. Accuracy of discretely sampled stochastic policies in continuous-time reinforcement learning. Preprint arXiv:2503.09981, 2025
-
[45]
Yanwei Jia and Xun Yu Zhou. Policy evaluation and temporal-difference learning in continuous time and space: A martingale approach.Journal of Machine Learning Research, 23(1):6918–6972, 2022
work page 2022
-
[46]
Yanwei Jia and Xun Yu Zhou. Policy gradient and actor-critic learning in continuous time and space.Journal of Machine Learning Research, 23(1):12603–12652, 2022
work page 2022
-
[47]
Yanwei Jia and Xun Yu Zhou.q-learning in continuous time.Journal of Machine Learning Research, 24(161):1–61, 2023
work page 2023
-
[48]
Chi Jin, Zhuoran Yang, Zhaoran Wang, and Michael I. Jordan. Provably efficient reinforcement learning with linear function approximation. InProceedings of the Thirty Third Conference on Learning Theory, volume 125 ofProceedings of Machine Learning Research, pages 2137–2143. PMLR, 2020
work page 2020
-
[49]
Daniel Lacker. Limit theory for controlled McKean–Vlasov dynamics.SIAM Journal on Control and Optimization, 55(3):1641–1672, 2017. 37
work page 2017
-
[50]
Mean field games.Japanese Journal of Mathematics, 2(1):229–260, 2007
Jean-Michel Lasry and Pierre-Louis Lions. Mean field games.Japanese Journal of Mathematics, 2(1):229–260, 2007
work page 2007
-
[51]
Mathieu Lauri` ere. Numerical methods for mean field games and mean field type control.Proceedings of Symposia in Applied Mathematics, 78:221–282, 2021
work page 2021
-
[52]
Dynamic programming for mean-field type control.Comptes Rendus Math´ ematique
Mathieu Lauri` ere and Olivier Pironneau. Dynamic programming for mean-field type control.Comptes Rendus Math´ ematique. Acad´ emie des Sciences. Paris, 352(9):707–713, 2014
work page 2014
-
[53]
Xun Li, Jingrui Sun, and Jiongmin Yong. Mean-field stochastic linear quadratic optimal control problems: Closed-loop solvability.Probability, Uncertainty and Quantitative Risk, 1(1):2, 2016
work page 2016
-
[54]
Cours au Coll` ege de France: Th´ eorie des jeux ` a champ moyen, 2012
Pierre-Louis Lions. Cours au Coll` ege de France: Th´ eorie des jeux ` a champ moyen, 2012. Audio lectures, 2006–2012
work page 2012
-
[55]
Huyˆ en Pham. Linear quadratic optimal control of conditional McKean–Vlasov equation with random coefficients and applications.Journal of Mathematical Economics, 66:7–26, 2016
work page 2016
-
[56]
Actor-critic learning algorithms for mean-field control with moment neural networks
Huyˆ en Pham and Xavier Warin. Actor-critic learning algorithms for mean-field control with moment neural networks. Methodology and Computing in Applied Probability, 27(13), 2025
work page 2025
-
[57]
Dynamic programming for optimal control of stochastic McKean–Vlasov dynamics
Huyˆ en Pham and Xiaoli Wei. Dynamic programming for optimal control of stochastic McKean–Vlasov dynamics. SIAM Journal on Control and Optimization, 55(2):1069–1101, 2017
work page 2017
-
[58]
Bellman equation and viscosity solutions for mean-field stochastic control problem
Huyˆ en Pham and Xiaoli Wei. Bellman equation and viscosity solutions for mean-field stochastic control problem. ESAIM Control Optim. Calc. Var., 24(1):437–461, 2018
work page 2018
-
[59]
Huyˆ en Pham and Xavier Warin. Mean-field neural networks: Learning mappings on wasserstein space.Neural Net- works, 168:380–393, 2023
work page 2023
-
[60]
Zhenjie Ren, Xiaoli Wei, Xiang Yu, and Xun Yu Zhou. Continuous-time q-learning for mean-field control with common noise, part-i: Theoretical foundations, 2026
work page 2026
-
[61]
Zhenjie Ren, Xiaoli Wei, Xiang Yu, and Xun Yu Zhou. Continuous-time q-learning for mean-field control with common noise, part-ii: q-learning algorithms, 2026
work page 2026
-
[62]
Osher, Wuchen Li, Levon Nurbekyan, and Samy Wu Fung
Lars Ruthotto, Stanley J. Osher, Wuchen Li, Levon Nurbekyan, and Samy Wu Fung. A machine learning framework for solving high-dimensional mean field game and mean field control problems.Proceedings of the National Academy of Sciences, 117(17):9183–9193, 2020
work page 2020
-
[63]
Mete Soner, Josef Teichmann, and Qinxin Yan
H. Mete Soner, Josef Teichmann, and Qinxin Yan. Learning algorithms for mean field optimal control.Preprint arXiv:2503.17869, 2025
-
[64]
H. Mete Soner and Qinxin Yan. Viscosity solutions for McKean–Vlasov control on a torus.SIAM Journal on Control and Optimization, 62(2):903–923, 2024
work page 2024
-
[65]
H. Mete Soner and Qinxin Yan. Viscosity solutions of the eikonal equation on the wasserstein space.Applied Mathe- matics & Optimization, 90(1), 2024
work page 2024
-
[66]
Jingrui Sun. Mean-field stochastic linear quadratic optimal control problems: Open-loop solvabilities.ESAIM: Control, Optimisation and Calculus of Variations, 23(3):1099–1127, 2017
work page 2017
-
[67]
Jingrui Sun and Hanxiao Wang. Mean-field stochastic linear-quadratic optimal control problems: Weak closed-loop solvability.Mathematical Control and Related Fields, 11(1):47–71, 2021
work page 2021
-
[68]
Jingrui Sun and Jiongmin Yong.Stochastic linear-quadratic optimal control theory: differential games and mean-field problems. Springer Nature, 2020
work page 2020
-
[69]
Yeneng Sun. The exact law of large numbers via fubini extension and characterization of insurable risks.Journal of Economic Theory, 126(1):31–69, 2006
work page 2006
-
[70]
Richard S. Sutton and Andrew G. Barto.Reinforcement learning: an introduction. Adaptive Computation and Ma- chine Learning. MIT Press, Cambridge, MA, second edition, 2018
work page 2018
-
[71]
Synthesis Lectures on Artificial Intelligence and Machine Learning
Csaba Szepesv´ ari.Algorithms for Reinforcement Learning. Synthesis Lectures on Artificial Intelligence and Machine Learning. Morgan & Claypool, 2010
work page 2010
-
[72]
Topics in propagation of chaos
Alain-Sol Sznitman. Topics in propagation of chaos. In ´Ecole d’ ´Et´ e de Probabilit´ es de Saint-Flour XIX—1989, volume 1464 ofLecture Notes in Mathematics, pages 165–251. Springer, Berlin, Heidelberg, 1991
work page 1989
-
[73]
Lukasz Szpruch, Tanut Treetanthiploet, and Yufei Zhang. Optimal scheduling of entropy regularizer for continuous- time linear-quadratic reinforcement learning.SIAM Journal on Control and Optimization, 62(1):135–166, 2024
work page 2024
-
[74]
Making deep Q-learning methods robust to time discretization
Corentin Tallec, L´ eonard Blier, and Yann Ollivier. Making deep Q-learning methods robust to time discretization. In Proceedings of the 36th International Conference on Machine Learning (ICML), volume 97 ofPMLR, pages 6096– 6104, 2019
work page 2019
-
[75]
Kinetic models of opinion formation.Communications in Mathematical Sciences, 4(3):481–496, 2006
Giuseppe Toscani. Kinetic models of opinion formation.Communications in Mathematical Sciences, 4(3):481–496, 2006
work page 2006
-
[76]
Haoran Wang, Thaleia Zariphopoulou, and Xun Yu Zhou. Reinforcement learning in continuous time and space: A stochastic control approach.Journal of Machine Learning Research, 21(198):1–34, 2020
work page 2020
-
[77]
Weichen Wang, Jiequn Han, Zhuoran Yang, and Zhaoran Wang. Global convergence of policy gradient for linear- quadratic mean-field control/game in continuous time. InProceedings of the 38th International Conference on Machine Learning (ICML), volume 139 ofPMLR, pages 10772–10782, 2021
work page 2021
-
[78]
Xiaoli Wei and Xiang Yu. Continuous time q-learning for mean-field control problems.Applied Mathematics & Opti- mization, 91(1):10, 2025
work page 2025
-
[79]
Xiaoli Wei, Xiang Yu, and Fengyi Yuan. Unified continuous-time q-learning for mean-field game and mean-field control problems.ArXiv, abs/2407.04521, 2024
-
[80]
Efficient local planning with linear function approximation
Dong Yin, Botao Hao, Yasin Abbasi-Yadkori, Nevena Lazi´ c, and Csaba Szepesv´ ari. Efficient local planning with linear function approximation. InProceedings of the 33rd International Conference on Algorithmic Learning Theory, volume 167 ofProceedings of Machine Learning Research, pages 1165–1192. PMLR, 2022
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.