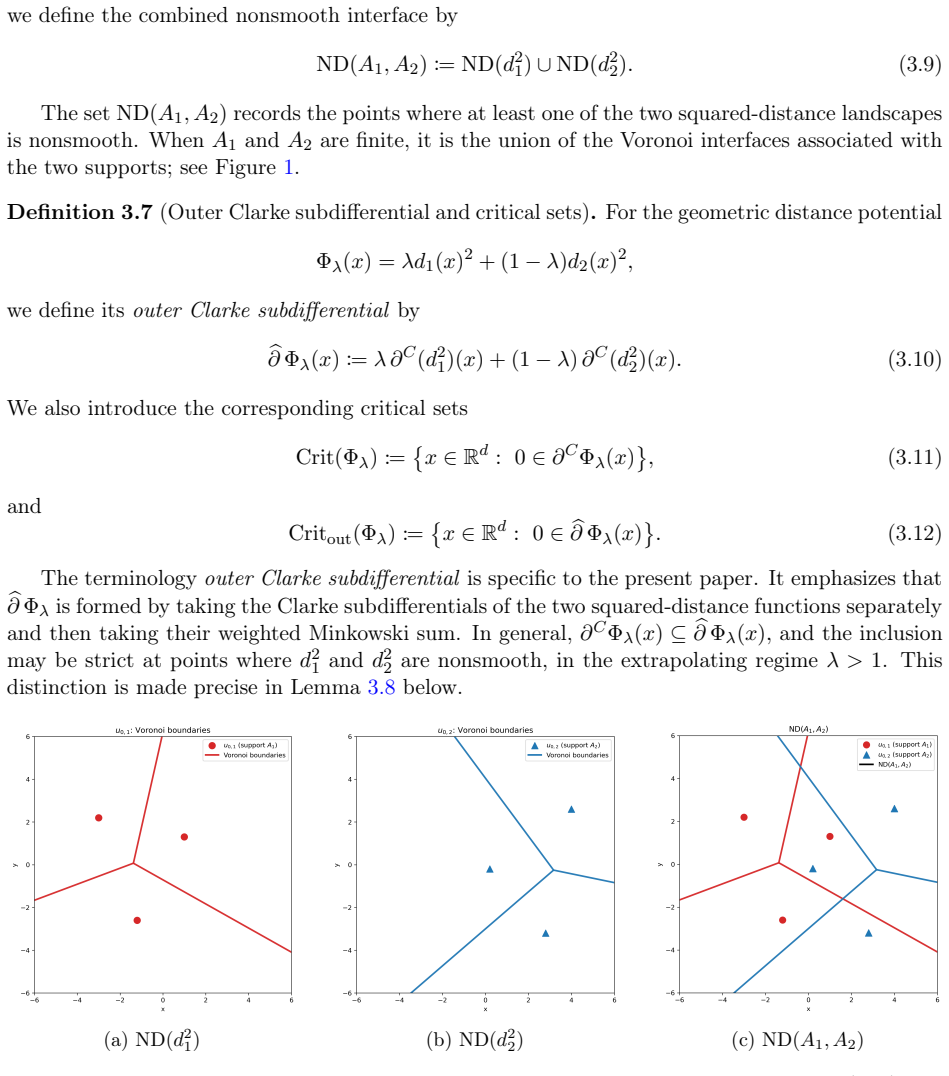
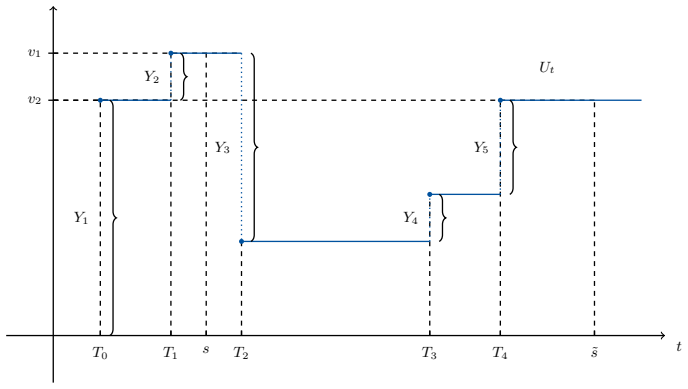
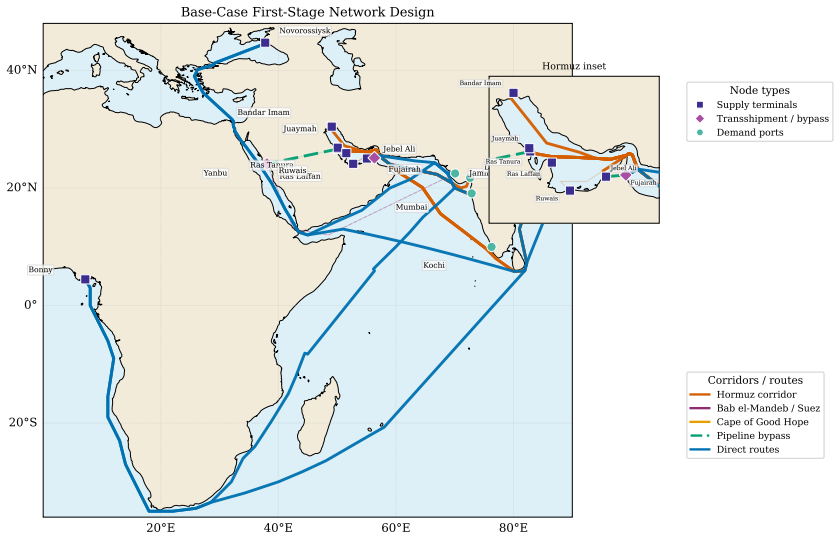
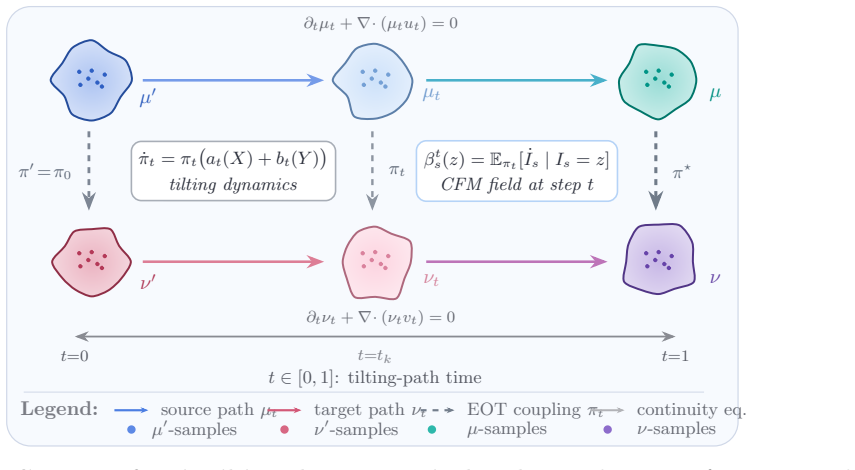
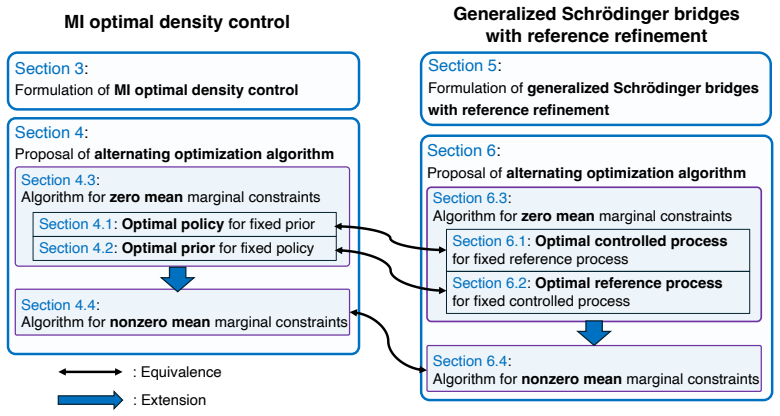
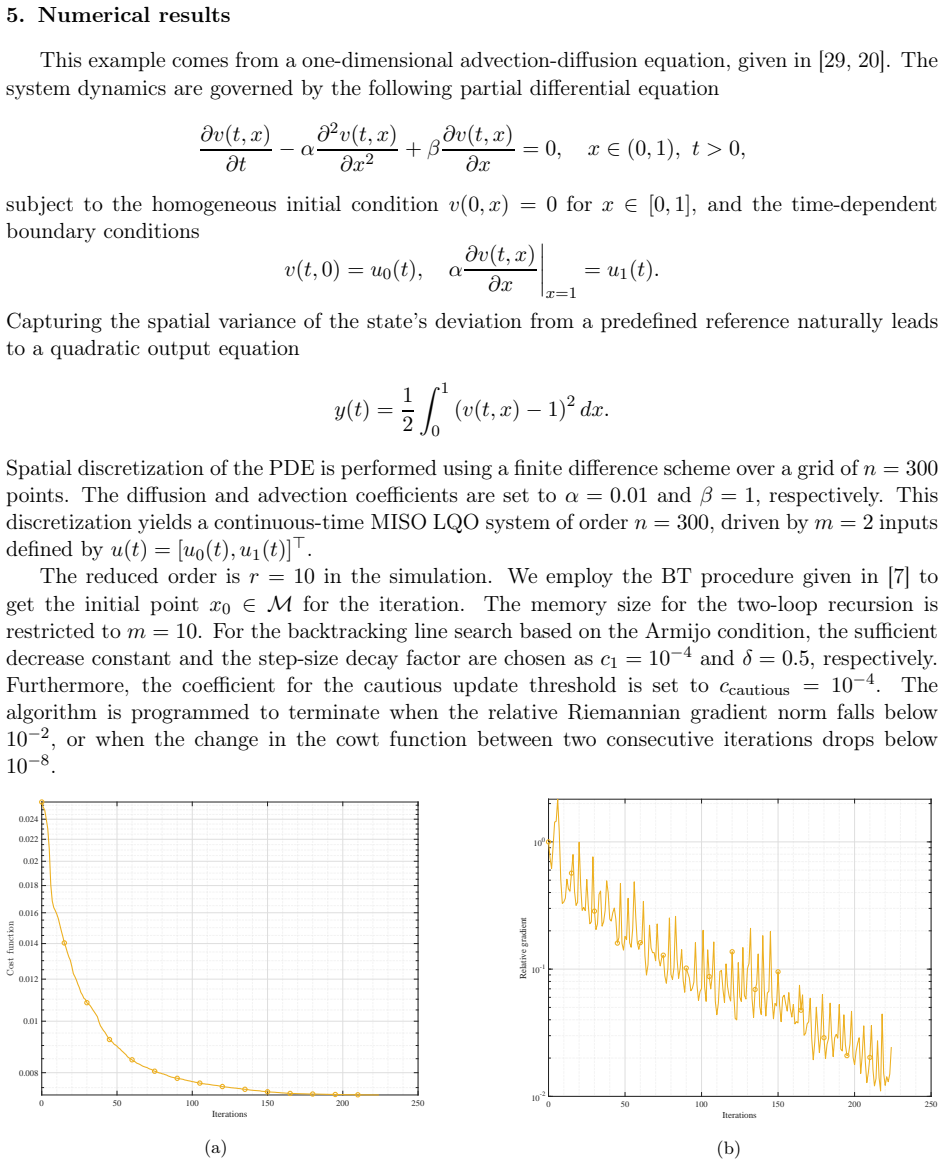
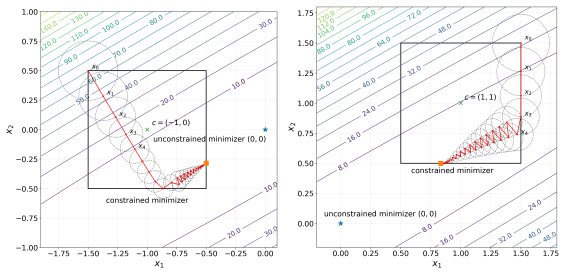
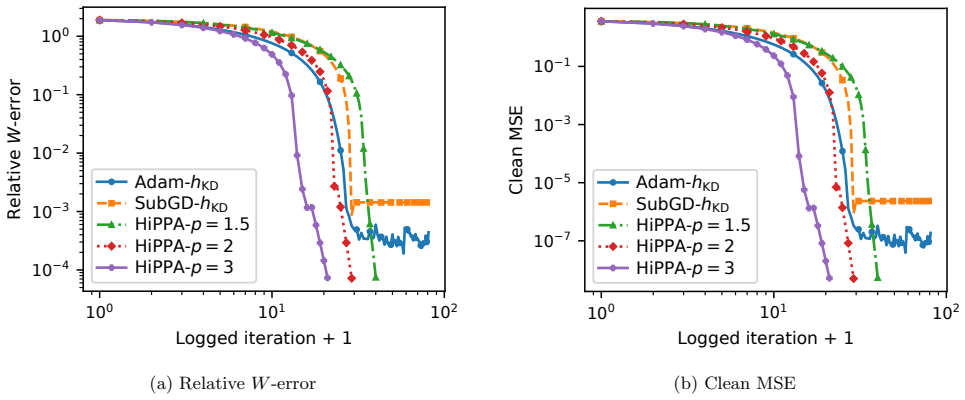
0
Alternation cuts cost in multi-objective stochastic optimization
Stochastic block coordinate and function alternation for multi-objective optimization and learning
Cycling through objectives and variable blocks matches single-objective convergence rates while lowering per-iteration cost.
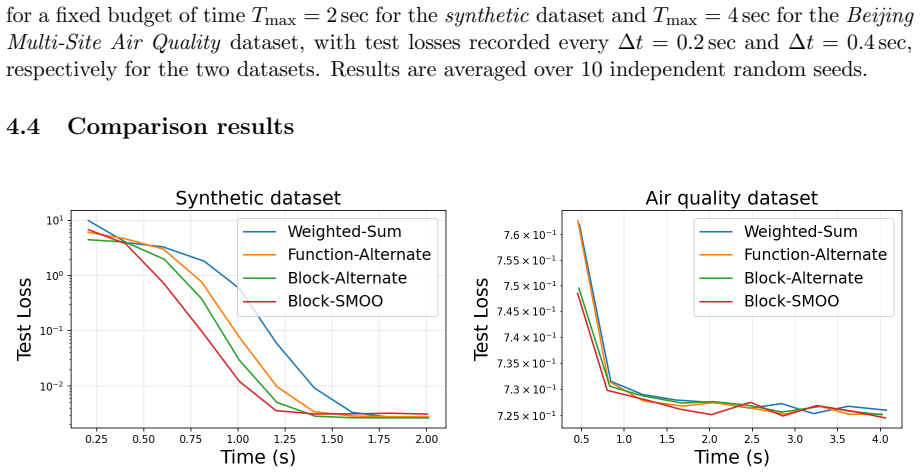 full image
full image
abstract click to expand
Multi-objective optimization is central to many engineering and machine learning applications, where multiple objectives must be optimized in balance. While multi-gradient based optimization methods combine these objectives in each step, such methods require computing gradients with respect to all variables at every iteration, resulting in high computational costs in large-scale settings. In this work, we propose a framework that simultaneously alternates the optimization of each objective and the (stochastic) gradient update with respect to each variable block. Our framework reduces per-iteration computational cost while enabling exploration of the Pareto front by allocating a prescribed number of gradient steps to each objective. We establish rigorous convergence guarantees across several stochastic smooth settings, including convex, non-convex, and Polyak-Lojasiewicz conditions, recovering classical convergence rates of single-objective methods. Numerical experiments demonstrate that our framework outperforms non-alternating methods on multi-target regression and produces a competitive Pareto front approximation, highlighting its computational efficiency and practical effectiveness.