GENIE: A Fine-Grained Measure for Novelty
Pith reviewed 2026-06-27 07:08 UTC · model grok-4.3
The pith
GENIE scores novelty of model responses by measuring distinct task-specific features against other responses in the same setting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GENIE measures the novelty of responses along task-specific features with respect to a population of responses. Unlike holistic metrics, it captures the high-dimensionality of novelty and provides insight on which properties they target. The metric is then used to measure the effectiveness of mitigation methods that address creativity to better understand where these methods can improve novelty.
What carries the argument
GENIE, a metric that decomposes novelty into independent task-specific features and scores them relative to a reference population of responses.
If this is right
- Mitigation methods for low creativity can be assessed on the exact novelty dimensions they affect rather than a single aggregate score.
- Holistic novelty metrics leave the high-dimensional structure of what counts as new unexamined.
- Task-specific feature analysis can identify which properties different generation techniques actually change.
- Evaluation becomes diagnostic enough to guide targeted improvements in model outputs.
Where Pith is reading between the lines
- The same decomposition could be adapted to measure novelty in image or code generation by defining domain-appropriate features.
- Training loops could incorporate GENIE-style scores as auxiliary objectives to encourage specific kinds of diversity.
- Cross-model comparisons might surface consistent gaps in what current systems treat as novel versus human responses.
Load-bearing premise
Novelty can be split into separate task-specific features that stay independent and can be measured against a group of other responses.
What would settle it
An experiment in which all GENIE features turn out highly correlated with one another across multiple tasks and holistic metrics match GENIE rankings on the same data.
Figures


read the original abstract
Large Language Models have consistently demonstrated a lack of creativity and diversity across tasks. Prior work has focused on addressing whether models are capable of generating creative outputs. Here, we aim to consider novelty and investigate what makes model-generated content novel or not novel in a task-specific manner. We propose a fine-grained evaluation metric GENIE to measure the novelty of responses along task-specific features with respect to a population of responses. We show that unlike GENIE, holistic metrics struggle to capture the high-dimensionality of novelty and do not provide insight on which properties they target. Finally, we use GENIE to measure the effectiveness of mitigation methods that address creativity to better understand where these methods can improve novelty.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GENIE, a fine-grained metric that measures novelty of LLM responses by decomposing it along task-specific features and comparing against a reference population of responses. It claims that holistic metrics cannot capture novelty's high dimensionality or indicate which properties are targeted, and applies GENIE to assess the effectiveness of creativity mitigation methods.
Significance. If the metric can be shown to produce stable, interpretable scores that differ meaningfully from holistic baselines on concrete tasks, it would address a recognized limitation in evaluating generative diversity. The approach is parameter-free by construction and avoids introducing new entities, which strengthens its conceptual clarity.
major comments (3)
- [Abstract] Abstract: the claim that 'unlike GENIE, holistic metrics struggle to capture the high-dimensionality of novelty' is presented as a demonstrated result, yet the manuscript contains no experiments, tables, or quantitative comparisons that would substantiate this advantage.
- [Abstract] Abstract: the central claim that GENIE 'provides insight on which properties they target' requires an explicit procedure for defining and validating the task-specific features; without this, the decomposition into independent features remains an untested assumption that is load-bearing for the metric's claimed superiority.
- [Abstract] Abstract: the final sentence states that GENIE is used 'to measure the effectiveness of mitigation methods,' but no results, baselines, or evaluation protocol are supplied, leaving the practical utility of the metric unsupported.
minor comments (1)
- [Abstract] The abstract refers to 'a population of responses' without specifying how the population is constructed or sampled, which affects reproducibility even at the conceptual level.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each major comment below and will revise the abstract to ensure all claims are supported by the manuscript content.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'unlike GENIE, holistic metrics struggle to capture the high-dimensionality of novelty' is presented as a demonstrated result, yet the manuscript contains no experiments, tables, or quantitative comparisons that would substantiate this advantage.
Authors: We agree that the abstract presents this as a demonstrated result without supporting experiments or comparisons in the manuscript. We will revise the abstract to remove or qualify the claim so that it does not overstate what the manuscript demonstrates. revision: yes
-
Referee: [Abstract] Abstract: the central claim that GENIE 'provides insight on which properties they target' requires an explicit procedure for defining and validating the task-specific features; without this, the decomposition into independent features remains an untested assumption that is load-bearing for the metric's claimed superiority.
Authors: The observation is correct: the abstract relies on the decomposition without supplying or referencing an explicit procedure for feature definition and validation. We will revise the abstract to avoid this claim or to indicate that such a procedure is not detailed in the current manuscript. revision: yes
-
Referee: [Abstract] Abstract: the final sentence states that GENIE is used 'to measure the effectiveness of mitigation methods,' but no results, baselines, or evaluation protocol are supplied, leaving the practical utility of the metric unsupported.
Authors: We acknowledge that the abstract asserts this application without providing results, baselines, or protocol. We will revise the final sentence to align with the actual content of the manuscript. revision: yes
Circularity Check
No significant circularity
full rationale
The paper proposes GENIE as a metric that decomposes novelty along task-specific features measured against an external reference population of responses. The abstract and available description present this as a definitional construction rather than a derivation that reduces to its own fitted inputs or self-citations. No equations, predictions, or load-bearing steps are shown that equate outputs to inputs by construction, and the central claim relies on external data and comparison to holistic baselines without internal reduction. This is the expected non-finding for a metric-definition paper whose assumptions are stated explicitly and externally verifiable.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
NarraBench: A Comprehensive Framework for Narrative Benchmarking. InProceedings of the 19th Conference of the European Chapter of the As- sociation for Computational Linguistics (Volume 1: Long Papers), pages 3786–3801, Rabat, Morocco. Association for Computational Linguistics. Fantine Huot, Reinald Kim Amplayo, Jennimaria Palo- maki, Alice Shoshana Jakob...
Pith/arXiv arXiv 2025
-
[2]
Utpal Lahiri
LLMs Corrupt Your Documents When You Delegate.arXiv preprint. Utpal Lahiri. 2001.Questions and Answers in Embed- ded Contexts. Oxford University Press UK. Florian Le Bronnec, Alexandre Verine, Benjamin Ne- grevergne, Yann Chevaleyre, and Alexandre Allauzen
2001
-
[3]
Exploring Precision and Recall to assess the quality and diversity of LLMs. InProceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers), pages 11418–11441, Bangkok, Thailand. Association for Computational Linguistics. Ximing Lu, Melanie Sclar, Skyler Hallinan, Niloofar Mireshghallah, Jiacheng Liu, Se...
Pith/arXiv arXiv 2025
-
[4]
InSecond Conference on Language Modeling
QUDsim: Quantifying Discourse Similarities in LLM-Generated Text. InSecond Conference on Language Modeling. Vishakh Padmakumar and He He. 2024. Does Writing with Language Models Reduce Content Diversity? InThe Twelfth International Conference on Learning Representations. Vishakh Padmakumar, Chen Yueh-Han, Jane Pan, Va- lerie Chen, and He He. 2026. Measuri...
arXiv 2024
-
[5]
Llama 2: Open Foundation and Fine-Tuned Chat Models.Preprint, arXiv:2307.09288. Leah Velleman and David I. Beaver. 2016. Question- based Models of Information Structure. In Caroline Féry and Shinichiro Ishihara, editors,The Oxford Handbook of Information Structure, pages 86–107. Oxford University Press, Oxford, UK. Manya Wadhwa, Tiasa Singha Roy, Harvey L...
Pith/arXiv arXiv 2016
-
[6]
From whose perspective is the story told?
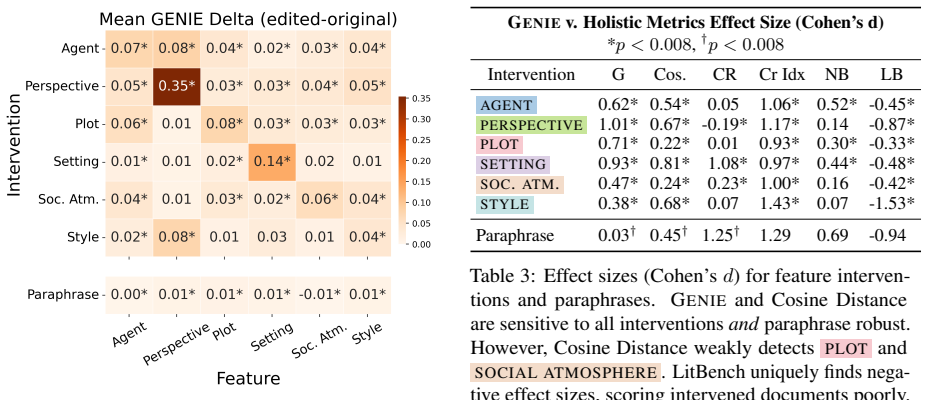
Using concise answers generates GENIEscores that are statistically larger than using answers with no length constraint. However, we also calculated the rank correlation to 12 Effect Size (Cohen’sd) Feature Cohen’sdKendall’sτ AGENT0.68* 0.56 PERSPECTIVE-0.01 0.46 PLOT0.90* 0.61 SETTING0.54* 0.51 SOC.ATM. 0.50* 0.53 STYLE0.62* 0.50 Table 8: gC,f is signific...
2024
-
[11]
Input:Prompt: {{[prompt]}} Prompt F.4: Question Generation Instantiation in Creative Writing System:You are an expert creative writing assistant
Questions are independent of each other and should not include anaphoric expressions. Input:Prompt: {{[prompt]}} Prompt F.4: Question Generation Instantiation in Creative Writing System:You are an expert creative writing assistant. Your task is to help writers analyze and expand a creative writing prompt before they begin writing into a series of question...
-
[13]
Incorrect: What fruits does the monkey like - apples, bananas or jack fruit? Correct: What fruits does the monkey like?
Examples must not be included in the question. Incorrect: What fruits does the monkey like - apples, bananas or jack fruit? Correct: What fruits does the monkey like?
-
[14]
If there are multiple parts to the question, split them and ask separate questions
A question can only ask one question at a time and may not use conjunctions for compounding. If there are multiple parts to the question, split them and ask separate questions. Incorrect: Who is the protagonist and what do they want? Correct: Who is the protagonist? What does the protagonist want?
-
[15]
Avoid future tense or conditional verbs
-
[16]
Input:Prompt: {{[prompt]}} Prompt F.5: Filtering Questions System:Given a question, do the following: Decide if the question breaks any of the criteria below
Questions are independent of each other and should not include anaphoric expressions. Input:Prompt: {{[prompt]}} Prompt F.5: Filtering Questions System:Given a question, do the following: Decide if the question breaks any of the criteria below. If it does, mark it as irrelevant
-
[18]
they can be objectively and correctly answered with no subjectivity or analysis involved
Questions must not be speculative, i.e. they can be objectively and correctly answered with no subjectivity or analysis involved
-
[19]
Questions should not include intentions, hypotheticals, conditionals and should avoid the future tense
-
[20]
Incorrect: How does the setting lend itself to imagery? This question belongs to both Set- ting and Style and is therefore irrelevant
Questions must not be associated with multiple features (>=2) as defined below. Incorrect: How does the setting lend itself to imagery? This question belongs to both Set- ting and Style and is therefore irrelevant
-
[23]
Incorrect: How is it resolved? Correct: How is the conflict between the main characters resolved? Features:
Questions are independent of each other and should not include anaphoric expressions. Incorrect: How is it resolved? Correct: How is the conflict between the main characters resolved? Features:
-
[26]
Plot - the content of the story (plotline, themes, ob- stacles, tropes, topics); the overall structure of the plot includes conflict, rising suspense, change of fortune and resolution 17
-
[29]
List all features that are clearly and fully applicable to the question
Style - the language used, tone, figurative devices em- ployed, etc. List all features that are clearly and fully applicable to the question. If there are more than one, reject the question. Follow this format: Question: Reasoning: Therefore the question is relevant: <True/False> Input:Questions: {{[questions]}} Prompt F.6: Feature Mapping System:Given a ...
-
[32]
Setting - where and when the story takes place, what unique objects define the location
Plot - the content of the story (plotline, themes, ob- stacles, tropes, topics); the overall structure of the plot includes conflict, rising suspense, change of fortune and resolution 4. Setting - where and when the story takes place, what unique objects define the location
-
[34]
Style - the language used, tone, figurative devices em- ployed, etc. If the question does not reflect any of the features well, denote ’None’ Follow this format: Question: Reasoning: Therefore the feature is: <feature> Input:Questions: {{[questions]}} Prompt F.7: Question Answering System:Given the following document, answer these questions as succinctly ...
-
[35]
Subject: Factory Operational Report - Environmental Impact and Workforce Status Date: March 14, 20XX From: Operations Management To: Corporate Headquarters
-
[36]
Facility Overview: The production facility at 122 Industrial Way continues regular operations with noted output efficiency expected for fiscal quarter
-
[37]
Data loggers detected airborne contaminants correlating with peak operational shifts
Environmental Compliance Assessment: Recent internal audit identified elevated levels of particu- late emissions and effluent discharge exceeding permitted thresholds. Data loggers detected airborne contaminants correlating with peak operational shifts. Nearby water basins report increased chemical load. is_prose: False Example 2: Document: The meteor had...
-
[38]
Questions should not be polar (yes/no) questions
-
[39]
they can be objectively and correctly answered with no subjectivity or analysis involved.]] 3
Questions must not be speculative, i.e. they can be objectively and correctly answered with no subjectivity or analysis involved.]] 3. Questions should not include intentions, hypotheticals, conditionals and should avoid the future tense
-
[40]
Incorrect: How does the setting lend itself to imagery? This question belongs to both Set- ting and Style and is therefore irrelevant
Questions must not be associated with multiple features (≥2 ) as defined below. Incorrect: How does the setting lend itself to imagery? This question belongs to both Set- ting and Style and is therefore irrelevant
-
[41]
Incorrect: Who is the protagonist and what do they want? Correct: Who is the protagonist? What does the protagonist want?
A question can only ask one question at a time and may not use conjunctions for compounding. Incorrect: Who is the protagonist and what do they want? Correct: Who is the protagonist? What does the protagonist want?
-
[42]
Incor- rect: What fruits does the monkey like - apples, bananas or jack fruit? Correct: What fruits does the monkey like?
Examples must not be included in the question. Incor- rect: What fruits does the monkey like - apples, bananas or jack fruit? Correct: What fruits does the monkey like?
-
[43]
Incorrect: How is it resolved? Correct: How is the conflict between the main characters resolved? Features: A
Questions are independent of each other and should not include anaphoric expressions. Incorrect: How is it resolved? Correct: How is the conflict between the main characters resolved? Features: A. Agent - the characters involved in the narrative and their attributes, goals, motivations, backstories, personalities and arcs B. Perspective - includes point o...
-
[44]
Agent - the characters involved in the narrative and their attributes, goals, motivations, backstories, personalities and arcs
-
[45]
Perspective - includes point of view and focalization
-
[46]
Plot - the content of the story (plotline, themes, obsta- cles, tropes, topics) and the overall structure of the plot (conflict, rising suspense, change of fortune and resolution)
-
[47]
Setting - where and when the story takes place, what unique objects define the location
-
[48]
Social Network - interactions and relationships that characters have with each other
-
[49]
If the question does not reflect any of the features well, denote ’None’
Style - the language used, tone, figurative devices em- ployed, etc. If the question does not reflect any of the features well, denote ’None’. Similarity Annotations 0: one or both of the answers are marked as completely unspecified, not applicable or ’None’. This includes cases where the question was not answered completely. 1: the answers are completely...
-
[50]
Was the expected change made? In other words, was the AltFeature appropriately reflected in the edited document?
-
[51]
Feature”, which should be replaced with the “AltFeature
How isolated was the edit? Ideally, we want the edit to be as minimally invasive as possible so that the only thing that changes is the “Feature”, which should be replaced with the “AltFeature”
-
[52]
seamless
How well does the alt-feature reflect the intervention? Q1: How well does the edited document reflect the intended change?: 1 = the AltFeature displayed is not reflected in the edited document 2 = the AltFeature is not completely reflected in the edited document, but parts of it are. 3 = the AltFeature is completely reflected in the edited document. But, ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.