Operator Fusion for LLM Inference on the Tensix Architecture
Pith reviewed 2026-06-28 06:59 UTC · model grok-4.3
The pith
Fusing RMSNorm with matrix multiplication enables back-to-back execution in on-chip SRAM to cut LLM inference latency on Tensix hardware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
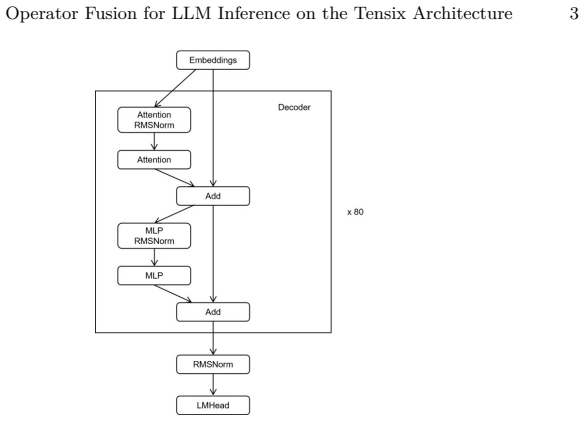
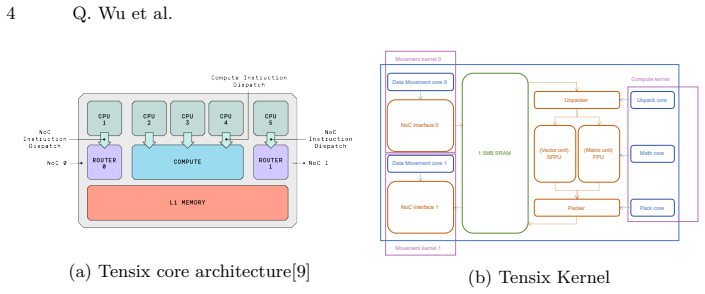
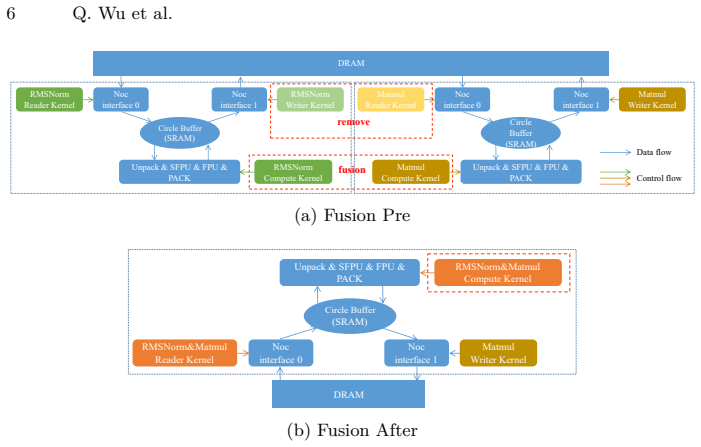
By fusing RMSNorm with matrix multiplication in self-attention and in the FFN, the method enables back-to-back execution of memory-bound and compute-bound operators in on-chip SRAM to significantly reduce DRAM reads/writes of intermediate results and scheduling overhead. To support multi-core parallelism, a NoC-based multicast mechanism is leveraged in which row/column master nodes efficiently distribute inputs and weights across the core mesh, alleviating DRAM bandwidth contention. Experiments on the Wormhole platform show up to 37.44% latency reduction for attention and 15.89% for MLP, with up to 7.91% reduction per decoder layer, while Pearson Correlation Coefficient remains above 98.75%.
What carries the argument
RMSNorm fusion with matrix multiplication plus NoC multicast for row/column data distribution across the core mesh.
If this is right
- Intermediate results stay in SRAM instead of returning to DRAM after each operator.
- Scheduling overhead drops because fused kernels run without host intervention between them.
- Multi-core bandwidth contention falls because multicast replaces repeated DRAM reads.
- End-to-end decoder-layer latency improves by up to 7.91 percent on the tested models.
- Numerical outputs remain consistent with the unfused baseline at PCC above 98.75 percent.
Where Pith is reading between the lines
- The same fusion pattern could be applied to other element-wise operations that sit between large matrix multiplies on similar mesh architectures.
- Lower DRAM traffic may allow larger batch sizes or context lengths before hitting memory limits on the same hardware.
- Extending the multicast scheme to non-uniform weight distributions might further reduce contention in deeper layers.
- The approach could be tested on models larger than 4B parameters to check whether the relative gains remain constant.
Load-bearing premise
The Tensix NoC and SRAM can execute the fused operators and multicast data movement without creating new bottlenecks or numerical errors beyond those already measured.
What would settle it
Disabling the RMSNorm fusion on the same Wormhole hardware and Qwen models and measuring latency reduction below 5 percent or PCC drop below 98 percent would falsify the efficiency claim.
Figures


read the original abstract
This study addresses on-device inference bottlenecks of Transformer models on Tenstorrent's Tensix architecture and proposes an operator fusion strategy that enhances data locality. RMSNorm is fused with matrix multiplication in self-attention and in the FFN, enabling back-to-back execution of memory-bound and compute-bound operators in on-chip SRAM to significantly reduce DRAM reads/writes of intermediate results and scheduling overhead. To support multi-core parallelism, a NoC-based multicast mechanism is leveraged in which row/column master nodes efficiently distribute inputs and weights across the core mesh, alleviating DRAM bandwidth contention. Experiments on the Wormhole platform with Qwen2.5-0.5B, Qwen3-0.6B, and Qwen3-4B show up to 37.44% latency reduction for attention and 15.89% for MLP, with up to 7.91% reduction per decoder layer, while Pearson Correlation Coefficient (PCC) remains above 98.75%, confirming significant end-to-end efficiency gains under numerical consistency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes fusing RMSNorm with matrix multiplication in self-attention and FFN layers on Tenstorrent's Tensix architecture. This enables back-to-back execution of memory-bound and compute-bound operators in on-chip SRAM, reducing DRAM traffic and scheduling overhead. A NoC-based multicast mechanism supports multi-core parallelism by distributing inputs and weights. Experiments on Qwen2.5-0.5B, Qwen3-0.6B, and Qwen3-4B models report up to 37.44% latency reduction for attention, 15.89% for MLP, and 7.91% per decoder layer, with PCC above 98.75%.
Significance. If the reported latency gains are attributable to the fusion keeping intermediates in SRAM rather than solely to NoC multicast, the work could offer a practical optimization for LLM inference on this hardware. The numerical consistency metric provides some reassurance on correctness, but the absence of input dimensions and implementation details limits assessment of broader applicability.
major comments (2)
- [Experiments] Experiments (abstract and §4): no sequence lengths or batch sizes are reported for the Qwen model latency measurements. This is load-bearing for the central claim that fused RMSNorm+matmul executes back-to-back in on-chip SRAM without DRAM spills, as the fit depends on activation sizes.
- [Methods] Methods (abstract and §3): the paper provides no description of the fusion implementation, data layout in SRAM, or how the NoC multicast interacts with the fused operators. Without these details or error analysis, the support for the performance numbers and PCC threshold cannot be verified.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major point below and have revised the manuscript accordingly to improve experimental reporting and methodological transparency.
read point-by-point responses
-
Referee: [Experiments] Experiments (abstract and §4): no sequence lengths or batch sizes are reported for the Qwen model latency measurements. This is load-bearing for the central claim that fused RMSNorm+matmul executes back-to-back in on-chip SRAM without DRAM spills, as the fit depends on activation sizes.
Authors: We agree this information is essential for assessing the SRAM residency claim. In the revised manuscript we have added the experimental configuration details to Section 4: all reported latency results use batch size 1 with sequence lengths of 128, 256, 512 and 1024 tokens. We have also inserted a short paragraph confirming that, for these dimensions on the tested Qwen models, the fused operator intermediates remain within on-chip SRAM capacity and incur no additional DRAM traffic. revision: yes
-
Referee: [Methods] Methods (abstract and §3): the paper provides no description of the fusion implementation, data layout in SRAM, or how the NoC multicast interacts with the fused operators. Without these details or error analysis, the support for the performance numbers and PCC threshold cannot be verified.
Authors: We accept that the original submission lacked sufficient implementation detail. Section 3 has been expanded to describe the fusion kernel, the SRAM data layout chosen to keep RMSNorm outputs resident for the subsequent matmul, and the precise interaction between the fused operator and the NoC multicast mechanism. We have also added a dedicated error-analysis subsection that explains the rationale for the 98.75 % PCC threshold based on the observed numerical results. revision: yes
Circularity Check
No circularity; paper reports empirical measurements only
full rationale
The manuscript describes an operator-fusion implementation for the Tensix architecture and presents measured latency reductions and PCC values on specific Qwen models. No equations, derivations, fitted parameters, uniqueness theorems, or self-citation chains appear in the provided text. All performance claims rest on direct experimental reporting rather than any reduction of a 'prediction' to its own inputs. The reader's circularity score of 1.0 is consistent with this assessment.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Tensix cores support back-to-back execution of fused RMSNorm and matmul inside on-chip SRAM.
- domain assumption NoC-based multicast distributes data across the core mesh without creating new bandwidth or correctness problems.
Reference graph
Works this paper leans on
-
[1]
Llm inference unveiled: Survey and roofline model insights.arXiv preprint arXiv:2402.16363, 2024
Yuan, Z., Shang, Y., Zhou, Y., Dong, Z., Zhou, Z., Xue, C., Wu, B., Li, Z., Gu, Q., Lee, Y.J., et al.: Llm inference unveiled: Survey and roofline model insights. arXiv preprint arXiv:2402.16363 (2024)
-
[2]
Wormhole, https://tenstorrent.com/hardware/wormhole, [Online; accessed 2026-01-14]
2026
-
[3]
tenstorrent/tt-metal: :metal: Tt-nn operator library, and tt-metalium low level kernel programming model., https://github.com/tenstorrent/tt-metal/ blob/main/METALIUM_GUIDE.md#tenstorrent-architecture-overview , [Online; accessed 2026-01-13]
2026
-
[4]
IEEE Internet of Things Journal 12(24), 51927–51950 (2025)
Wang, W., Li, K., Ji, B., et al.: A survey of ai inference technologies for on-device systems. IEEE Internet of Things Journal 12(24), 51927–51950 (2025)
2025
-
[5]
In: Pro- ceedings of the 49th Annual IEEE/ACM International Symposium on Microarchi- tecture (MICRO)
Alwani, M., Chen, H., Ferdman, M., et al.: Fused-layer cnn accelerators. In: Pro- ceedings of the 49th Annual IEEE/ACM International Symposium on Microarchi- tecture (MICRO). pp. 1–12 (2016)
2016
-
[6]
ACM Transactions on Embedded Computing Systems (TECS) 22(1), 1–26 (2022) Operator Fusion for LLM Inference on the Tensix Architecture 11
Cai, X., Wang, Y., Zhang, L.: Optimus: An operator fusion framework for deep neural networks. ACM Transactions on Embedded Computing Systems (TECS) 22(1), 1–26 (2022) Operator Fusion for LLM Inference on the Tensix Architecture 11
2022
-
[7]
In: Proceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO)
Zheng, S., Chen, S., Gao, S., et al.: Tileflow: A framework for modeling fusion dataflow via tree-based analysis. In: Proceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). pp. 1271–1288 (2023)
2023
-
[8]
Tenstorrent: tenstorrent/tt-metal: :metal: Tt-nn operator library, and tt-metalium low level kernel programming model., https://github.com/tenstorrent/ tt-metal
-
[9]
com/tenstorrent/tt-metal/blob/main/METALIUM_GUIDE.md, [Online; accessed 2026-03-12]
tt-metal/metalium_guide.md at main ctenstorrent/tt-metal, https://github. com/tenstorrent/tt-metal/blob/main/METALIUM_GUIDE.md, [Online; accessed 2026-03-12]
2026
-
[10]
EECS Department, University of California, Berkeley, Tech
Waterman, A., Lee, Y., Patterson, D.A., Asanovic, K.: The risc-v instruction set manual, volume i: User-level isa, version 2.0. EECS Department, University of California, Berkeley, Tech. Rep. UCB/EECS-2014-54 p. 4 (2014)
2014
-
[11]
to Wikimedia projects, C.: Single program, multiple data - wikipedia (10 2004), https://en.wikipedia.org/wiki/Single_program,_multiple_data, [Online; ac- cessed 2026-01-14]
2004
-
[12]
Brown, N., Barton, R.: Accelerating stencils on the Tenstorrent Grayskull RISC-V accelerator (Sep 2024)
2024
-
[13]
In: Neuwirth, S., Paul, A.K., Weinzierl, T., Carson, E.C
Brown, N., Davies, J., Clair, F.L.: Exploring Fast Fourier Transforms onătheăTenstorrent Wormhole. In: Neuwirth, S., Paul, A.K., Weinzierl, T., Carson, E.C. (eds.) High Performance Computing. pp. 598–612. Springer Nature Switzer- land, Cham (2026)
2026
-
[14]
Cavagna, H.P., Cesarini, D., Bartolini, A.: Assessing Tenstorrent’s RISC-V MatMul Acceleration Capabilities (May 2025)
2025
-
[15]
Thüning, M.: Attention in SRAM on Tenstorrent Grayskull (Jul 2024)
2024
-
[16]
In: Proceedings of the SC ’25 Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis
Almerol, J.L., Boella, E., Spera, M., et al.: Accelerating Gravitational N-Body Sim- ulations Using the RISC-V-Based Tenstorrent Wormhole. In: Proceedings of the SC ’25 Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis. pp. 1729–1735. SC Workshops ’25, Association for Computing Machinery, New York, ...
2025
-
[17]
tenstorrent/ttnn-visualizer: A comprehensive tool for visualizing and analyzing model execution, offering interactive graphs, memory plots, tensor details, buffer overviews, operation flow graphs, and multi-instance support with file or ssh- based report loading., https://github.com/tenstorrent/ttnn-visualizer, [On- line; accessed 2026-01-13]
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.