When Interpretability Is Unequally Distributed: Fairness in Hybrid Interpretable Models
Pith reviewed 2026-06-29 14:09 UTC · model grok-4.3
The pith
Hybrid interpretable models can allocate interpretability unequally across demographic groups through their routing decisions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
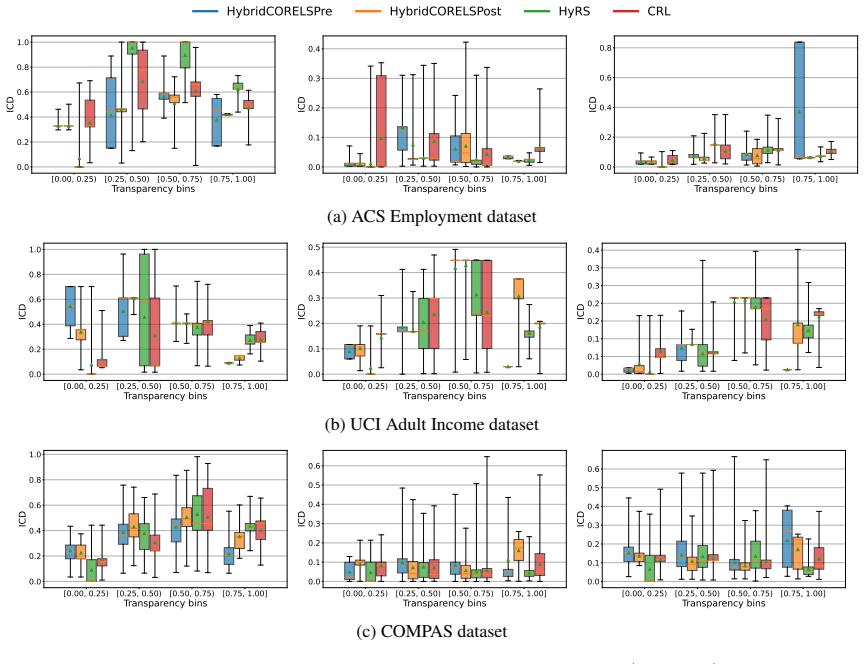
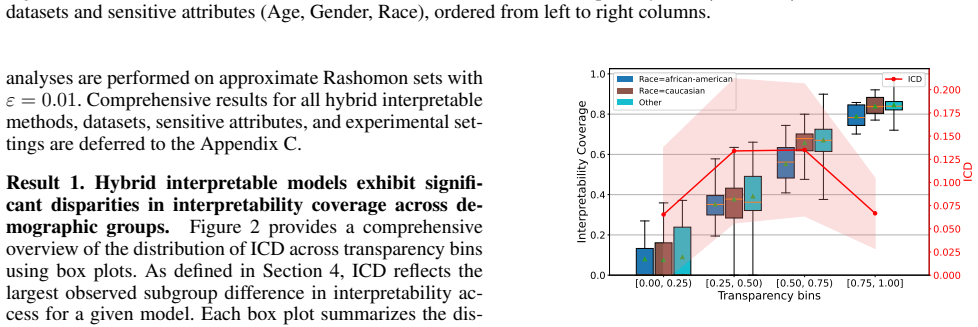
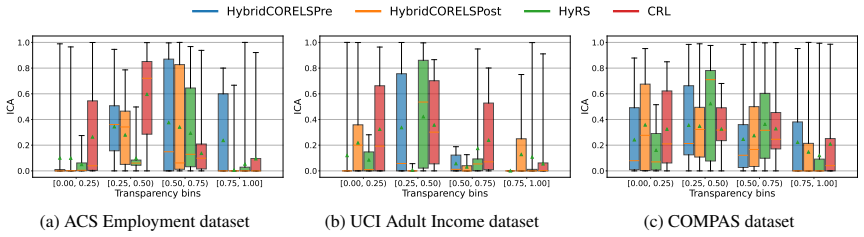
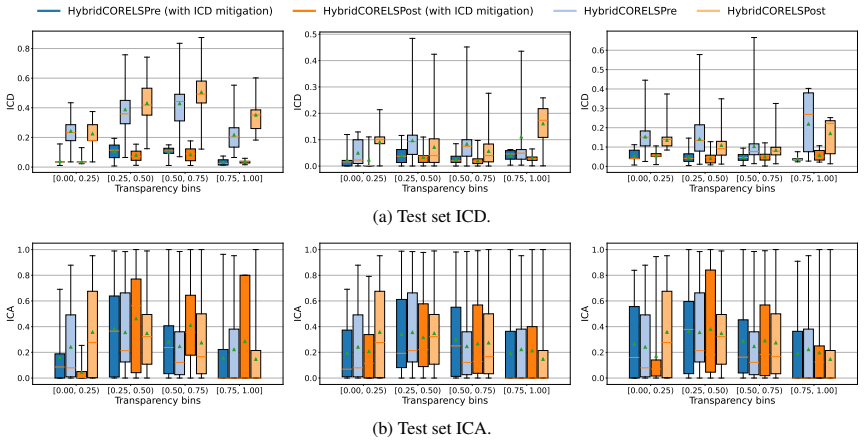
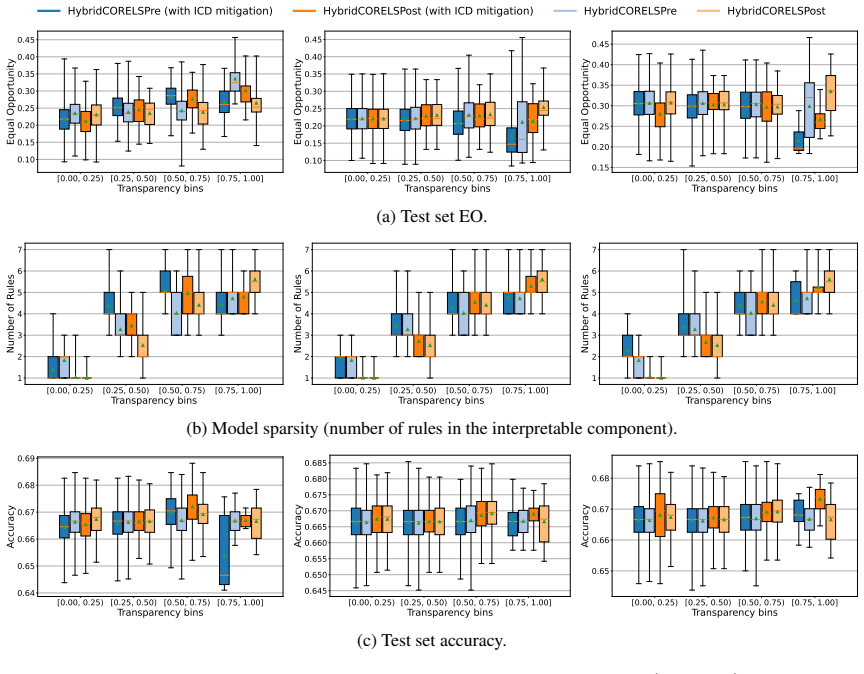
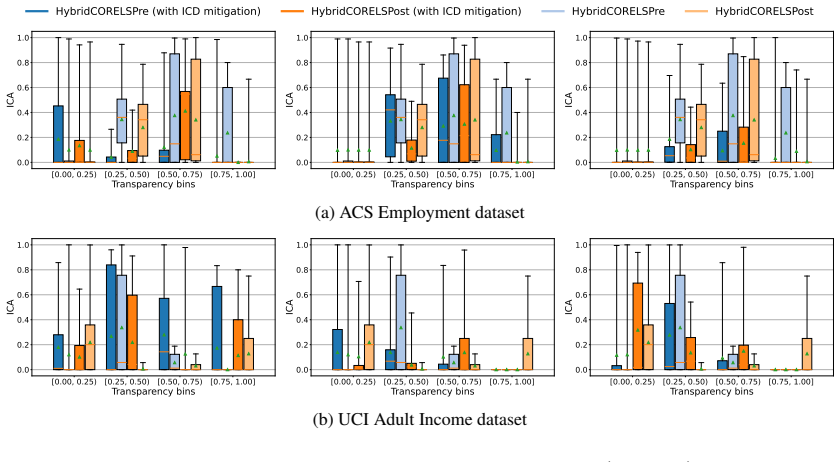
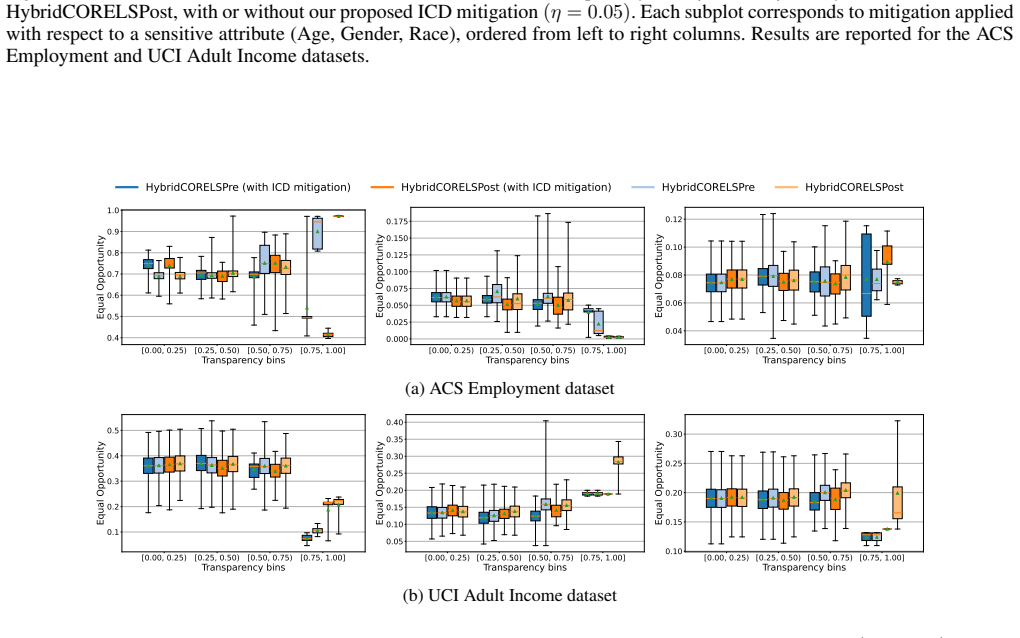
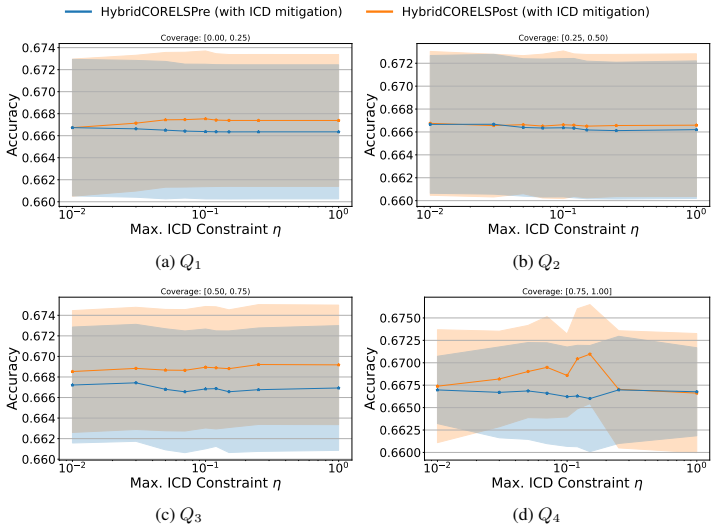
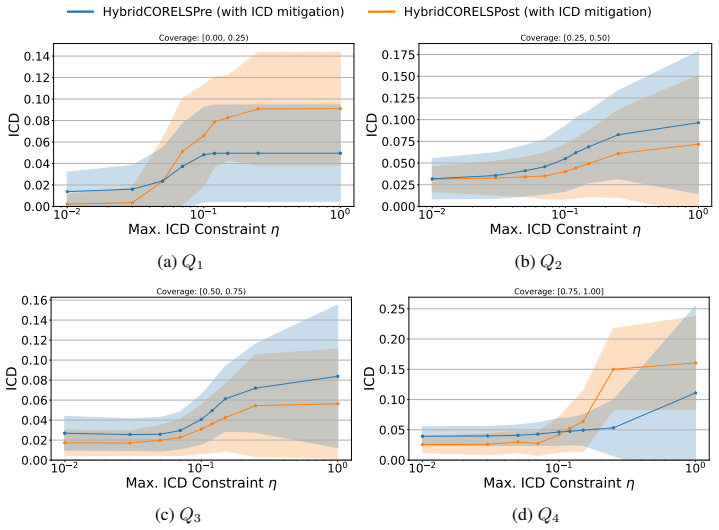
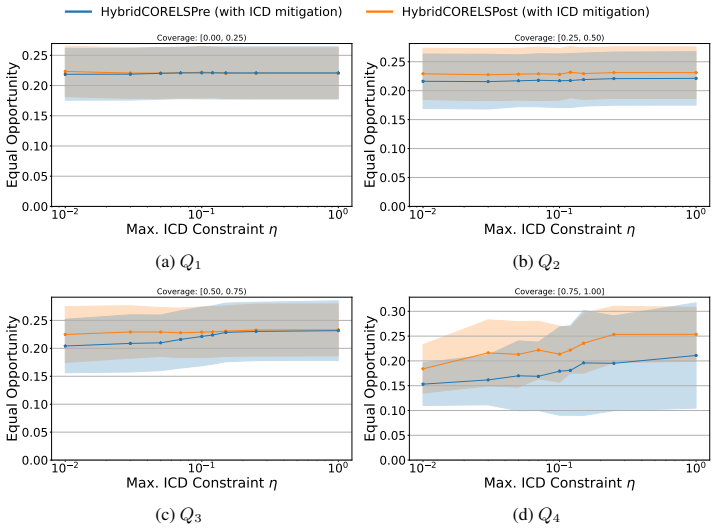
Hybrid interpretable models exhibit substantial Interpretability Coverage Disparity in intermediate transparency regimes where both the interpretable and black-box components are actively used. Simple coverage-disparity constraints can significantly reduce this disparity in exact hybrid learning methods, with only marginal impact on accuracy and sparsity, and in several settings the mitigation also improves standard algorithmic fairness metrics.
What carries the argument
Interpretability Coverage Disparity (ICD), a demographic-parity-style measure applied to the routing decision that assigns examples to the interpretable or black-box component.
If this is right
- Substantial ICD appears when both interpretable and black-box components are actively used.
- Coverage-disparity constraints substantially reduce ICD in exact hybrid learning methods.
- The constraints produce only marginal changes to accuracy and sparsity.
- ICD mitigation can improve standard algorithmic fairness metrics in several settings.
Where Pith is reading between the lines
- Hybrid models require separate auditing for fairness in interpretability allocation in addition to predictive accuracy.
- Routing disparities of this form could arise in any system that selectively applies interpretable versus automated components.
- Coverage constraints on routing might be added to training pipelines for hybrid models without major redesign.
Load-bearing premise
The routing decision is the primary procedural fairness concern and standard benchmark datasets with their sensitive attributes adequately capture real-world demographic routing patterns.
What would settle it
An observation that ICD remains near zero across multiple hybrid methods and datasets in intermediate transparency regimes, or that adding coverage-disparity constraints produces more than marginal losses in accuracy or sparsity.
Figures













read the original abstract
Hybrid interpretable models combine a transparent component with a black-box model by assigning some examples to the former and deferring the rest to the latter. While this design enables flexible tradeoffs between accuracy and interpretability, it also raises a distinct procedural fairness concern: some demographic groups may systematically receive interpretable decisions, while others are disproportionately routed to a black box. We formalize this issue as Interpretability Coverage Disparity (ICD), a demographic-parity-style measure applied to the routing decision of hybrid interpretable models. Using tools from predictive multiplicity, we study ICD across four hybrid interpretable learning methods, three standard fairness benchmark datasets, and multiple sensitive attributes. Our experiments reveal substantial ICD in intermediate transparency regimes, where both the interpretable and black-box components are actively used. We further show that simple coverage-disparity constraints can significantly reduce ICD in exact hybrid learning methods, with marginal impact on accuracy and sparsity. In several settings, ICD mitigation also improves standard algorithmic fairness metrics. These results show that hybrid interpretable models should be audited not only for predictive fairness, but also for how they allocate interpretability across individuals and groups.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Interpretability Coverage Disparity (ICD), a demographic-parity-style metric on the routing decisions of hybrid interpretable models that combine a transparent component with a black-box model. Across four hybrid learning methods, three standard fairness benchmarks, and multiple sensitive attributes, the authors report substantial ICD in intermediate transparency regimes and demonstrate that simple coverage-disparity constraints can reduce ICD in exact hybrid methods with only marginal effects on accuracy and sparsity; in some cases the constraints also improve standard fairness metrics.
Significance. If the empirical findings hold, the work identifies a distinct procedural fairness issue in hybrid models and supplies both a formalization and a practical mitigation approach. The multi-method, multi-dataset experimental design and the observation that ICD mitigation can co-occur with gains in predictive fairness are constructive contributions that could prompt routine auditing of interpretability allocation alongside accuracy-based fairness checks.
major comments (2)
- [§4] §4 (Experiments): The routing decisions are produced by optimizing accuracy and sparsity on standard benchmarks (Adult, COMPAS, etc.) that supply sensitive attributes but contain no ground-truth labels for when an instance should receive an interpretable versus black-box decision. Consequently the reported group disparities in ICD may be optimization artifacts rather than evidence of a general procedural fairness phenomenon; real-world routing often depends on domain-specific factors uncorrelated with the benchmark labels.
- [§5.2] §5.2 (Mitigation results): The coverage-disparity constraints are shown to reduce ICD, yet the manuscript does not report whether the constrained solutions remain within the same intermediate transparency regimes or whether the reduction in ICD is statistically significant after multiple-testing correction across the four methods and multiple attributes.
minor comments (2)
- [§3] Notation for the routing function and the exact definition of ICD (Eq. 3) could be cross-referenced more explicitly in the experimental tables so readers can map reported numbers directly to the formal measure.
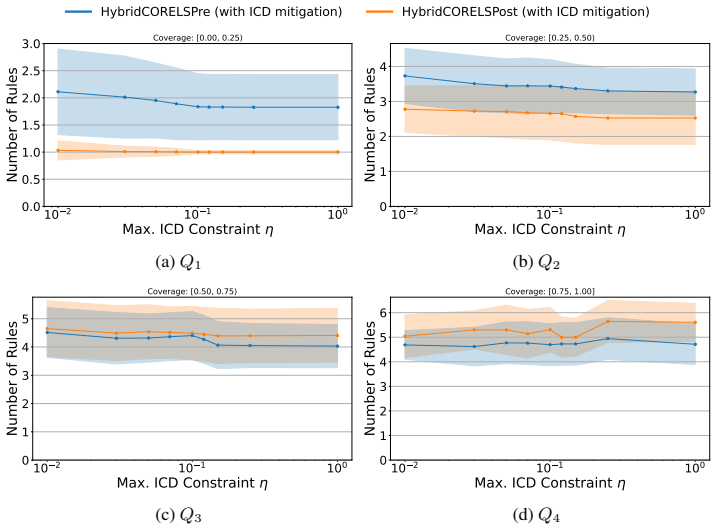
- [Figure 3] Figure 3 caption should state the number of random seeds used for the error bars; without this the visual comparison of ICD before and after mitigation is harder to interpret.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond to each major point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The routing decisions are produced by optimizing accuracy and sparsity on standard benchmarks (Adult, COMPAS, etc.) that supply sensitive attributes but contain no ground-truth labels for when an instance should receive an interpretable versus black-box decision. Consequently the reported group disparities in ICD may be optimization artifacts rather than evidence of a general procedural fairness phenomenon; real-world routing often depends on domain-specific factors uncorrelated with the benchmark labels.
Authors: We agree that the benchmarks lack ground-truth routing labels, so the observed ICD reflects disparities arising under standard accuracy/sparsity optimization rather than 'correct' allocations. This is a limitation of the experimental design. However, the core claim is that hybrid models trained via common objectives on widely used fairness benchmarks produce unequal interpretability allocation; this procedural disparity is itself a fairness issue worth auditing, independent of ground truth. Real-world routing may incorporate additional factors, but the benchmark results still demonstrate that ICD can emerge without explicit fairness considerations in the routing. We will add a dedicated limitations paragraph in §4 and the discussion section acknowledging the lack of ground-truth labels and the need for future work on domain-specific routing. revision: partial
-
Referee: [§5.2] §5.2 (Mitigation results): The coverage-disparity constraints are shown to reduce ICD, yet the manuscript does not report whether the constrained solutions remain within the same intermediate transparency regimes or whether the reduction in ICD is statistically significant after multiple-testing correction across the four methods and multiple attributes.
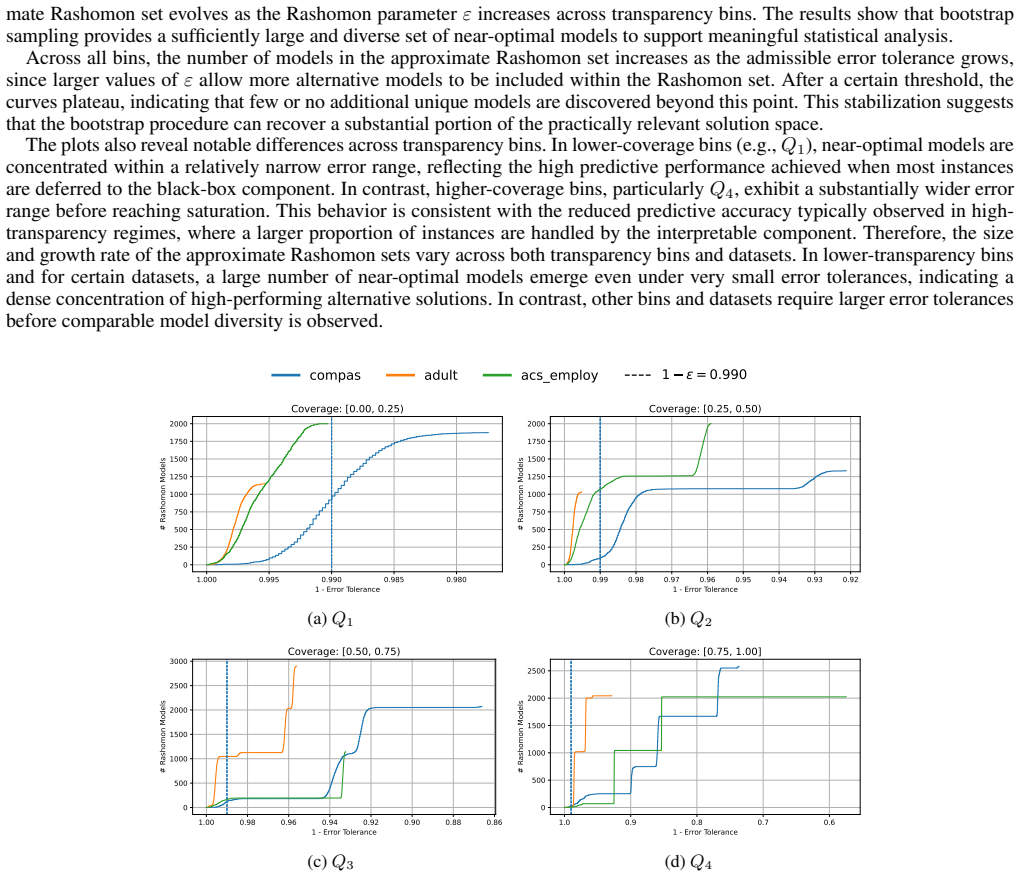
Authors: The constrained solutions do remain in intermediate transparency regimes (coverage typically 30-70% interpretable), as the disparity constraints are applied on top of the original accuracy/sparsity objectives without altering target coverage levels; this is visible in the reported coverage values but was not explicitly stated. For statistical significance, we will revise §5.2 to include p-values computed with Bonferroni correction across the four methods and attributes, confirming that ICD reductions remain significant. We will also add an explicit statement that intermediate regimes are preserved under the constraints. revision: yes
Circularity Check
No circularity: empirical evaluation of newly defined ICD measure
full rationale
The paper defines Interpretability Coverage Disparity (ICD) as a demographic-parity-style measure on routing decisions in hybrid models, then reports experimental results on its prevalence and mitigation across four methods and three benchmarks. No equations or claims reduce a prediction to a fitted input by construction, no self-citations bear load on the central empirical findings, and the derivation chain consists of independent formalization followed by external evaluation on standard datasets. This is a standard non-circular empirical study.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Interpretability Coverage Disparity (ICD)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Uniform Guidelines on Employee Selection Proce- dures. 29 CFR Part 1607. Equal Employment Opportunity Commission. A¨ıvodji, U.; Arai, H.; Fortineau, O.; Gambs, S.; Hara, S.; and Tapp, A. 2019. Fairwashing: The Risk of Rationaliza- tion. InProceedings of the 36th International Conference on Machine Learning, ICML, 161–170. Angwin, J.; Larson, J.; Mattu, S....
-
[2]
InProceedings of the 38th AAAI Conference on Artificial Intelligence, AAAI, 22004–22012
Arbitrariness and Social Prediction: The Confounding Role of Variance in Fair Classification. InProceedings of the 38th AAAI Conference on Artificial Intelligence, AAAI, 22004–22012. Coston, A.; Rambachan, A.; and Chouldechova, A. 2021. Characterizing fairness over the set of good models under selective labels. InProceedings of the 38th International Conf...
2021
-
[3]
Fair Recourse for All: Ensuring Individual and Group Fairness in Counterfactual Explanations. arXiv:2601.20449. Feldman, M.; Friedler, S. A.; Moeller, J.; Scheidegger, C.; and Venkatasubramanian, S. 2015. Certifying and Remov- ing Disparate Impact. InProceedings of the 21st ACM SIGKDD International Conference on Knowledge Discov- ery and Data Mining, KDD,...
-
[4]
InProceedings of the 30th International Conference on Machine Learning, ICML, 325–333
Learning Fair Representations. InProceedings of the 30th International Conference on Machine Learning, ICML, 325–333. Zhang, B. H.; Lemoine, B.; and Mitchell, M. 2018. Miti- gating unwanted biases with adversarial learning. InPro- ceedings of the AAAI/ACM Conference on AI, Ethics, and Society, AIES, 335–340. Zhao, Y .; Wang, Y .; and Derr, T. 2022. Fairne...
2018
-
[5]
Exploring and interacting with the set of good sparse generalized additive models.Proceedings of the 38th An- nual Conference on Neural Information Processing Systems, NeurIPS, 56673–56699. Algorithm 1: HybridCORELSPre (with ICD mitigation) Input: Training dataSwith set of pre-mined antecedentsΥ; minimum transparency valueC min; initial prefixr 0 such tha...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.