Empirical Bayes Conformal Prediction for Vision and Language Models
Pith reviewed 2026-05-25 04:42 UTC · model grok-4.3
The pith
r-value nonconformity scores preserve conformal coverage while reducing high-variance false candidates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the r-value, obtained from an empirical Bayes estimator of the latent score distribution, serves as a nonconformity score that preserves the target conformal coverage while provably lowering the inclusion rate of high-variance false candidates under mild regularity conditions; both Normal-Normal closed-form and nonparametric posterior-sampling estimators are supplied, and the approach is shown to improve ranking stability and reduce set size on image classification, CLIP-based VLM, and LLM benchmarks whenever variability is informative.
What carries the argument
The r-value nonconformity score, which converts mean score and observed variability into the estimated probability that a candidate's latent score belongs to the top-ranked group.
If this is right
- Target coverage is maintained on image classification, VLM, and LLM tasks.
- Prediction-set size decreases and ranking stability improves when variability distinguishes signal from noise.
- Behavior reverts to ordinary conformal prediction when variability vanishes.
- Both closed-form Normal-Normal and nonparametric sampling estimators are available for practical use.
Where Pith is reading between the lines
- The same variability-aware construction could be applied to other multi-realization regimes such as ensemble or Bayesian neural-network outputs.
- The approach suggests that modeling uncertainty directly inside the nonconformity score may yield efficiency gains in online or adaptive conformal settings.
- Testing the regularity conditions on a wider range of model families would clarify when the provable reduction in false inclusions holds.
Load-bearing premise
Observed variability in scores reliably distinguishes stable high-scoring candidates from noise-driven ones and the empirical Bayes estimator recovers this distinction accurately from the available realizations.
What would settle it
A controlled experiment in which the fraction of high-variance false candidates entering the conformal sets is no smaller (or is larger) under the r-value rule than under standard single-score or averaged CP, or in which empirical coverage on held-out data falls below the nominal target.
Figures

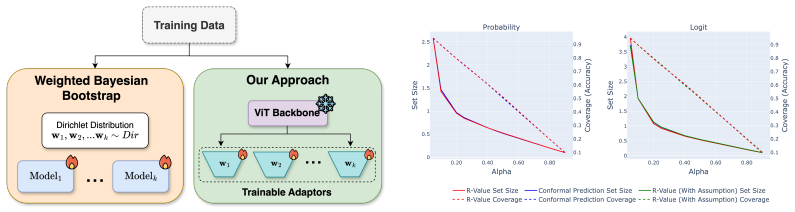
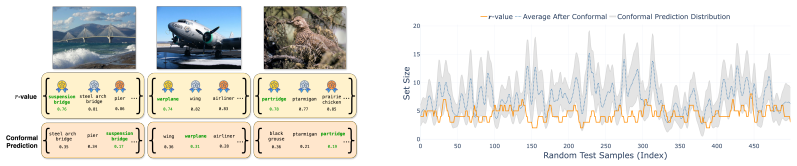



read the original abstract
Conformal prediction (CP) gives distribution-free coverage for modern vision and language models, but it is often forced to make a ranking decision from a single unstable nonconformity score. Standard CP uses one realization, while average-then-calibrate variants smooth multiple realizations into a point estimate. Both options discard the inconsistency that can help identify whether a candidate is indeed stable. A weak answer can enter the conformal set even if the evidence is not strong, simply because one posterior sample or prompt phrasing made it look strong. But variability can help distinguish a stable signal from noise-driven fluctuations. We describe an empirical Bayes conformal prediction framework that uses $r$-values to convert score variability into an uncertainty informed nonconformity score. The resulting $r$-value estimates how likely a candidate's latent score belongs to the top-ranked group after accounting for both its mean score and its uncertainty. It admits both a closed-form Normal-Normal empirical Bayes estimator and a nonparametric posterior-sampling estimator. Using the $r$-value as the nonconformity score preserves the target conformal coverage while provably reducing the inclusion of high variance false candidates under mild regularity conditions. Across image classification, CLIP-based VLM benchmarks, and LLMs, we show that $r$-value conformal prediction preserves target coverage while improving ranking stability and reducing set size when variability is informative, and reverting to CP-like behavior when variability vanishes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an empirical Bayes conformal prediction framework for vision and language models. It uses r-values—computed via either a closed-form Normal-Normal empirical Bayes estimator or a nonparametric posterior-sampling estimator—as nonconformity scores that incorporate both mean score and score variability. The central claims are that this construction preserves the target conformal coverage guarantee and provably reduces inclusion of high-variance false candidates under mild regularity conditions, with experiments on image classification, CLIP VLMs, and LLMs showing preserved coverage, improved ranking stability, and smaller sets when variability is informative.
Significance. If the coverage preservation holds despite the data-dependent construction of the nonconformity score, the result would be significant for conformal prediction in unstable settings such as LLMs. It would demonstrate how to fold empirical-Bayes uncertainty quantification into the nonconformity measure while retaining distribution-free guarantees, potentially yielding more efficient sets without post-hoc adjustments. The dual parametric/nonparametric estimators and the explicit qualifier that the method reverts to standard CP when variability vanishes strengthen applicability.
major comments (2)
- [Abstract and §3] Abstract and §3 (method): The manuscript asserts that the r-value nonconformity score 'preserves the target conformal coverage' and yields a 'provable reduction' under 'mild regularity conditions,' yet supplies neither a derivation nor an explicit statement of those conditions. Because the coverage guarantee is the load-bearing claim, the absence of the proof or regularity assumptions must be addressed before the result can be evaluated.
- [§3.2] §3.2 (empirical Bayes estimator): The r-value is obtained by fitting the Normal-Normal (or nonparametric) empirical Bayes model to the observed scores; the resulting nonconformity score therefore depends on quantities estimated from the calibration data itself. This dependence must be shown not to violate the exchangeability required for marginal coverage; the current description leaves the effect on the guarantee unaddressed.
minor comments (1)
- [Experiments] The experimental section would benefit from explicit quantitative reporting of coverage deviation, set-size reduction, and the fraction of cases in which variability was deemed informative, rather than qualitative statements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the centrality of the coverage guarantee. We will revise the manuscript to include the missing theoretical derivations and explicit conditions as detailed below.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): The manuscript asserts that the r-value nonconformity score 'preserves the target conformal coverage' and yields a 'provable reduction' under 'mild regularity conditions,' yet supplies neither a derivation nor an explicit statement of those conditions. Because the coverage guarantee is the load-bearing claim, the absence of the proof or regularity assumptions must be addressed before the result can be evaluated.
Authors: We agree the proof and conditions are required for evaluation. The revised manuscript will add a formal theorem in §3 (with full proof in the appendix) establishing that the r-value nonconformity score preserves marginal coverage under exchangeability of the underlying scores. The mild regularity conditions will be stated explicitly: (i) the latent scores are exchangeable, (ii) the empirical Bayes estimator (Normal-Normal or nonparametric) is a symmetric function of the calibration scores, and (iii) the r-value mapping is monotone in the score. The provable reduction in high-variance false positives will be shown via a stochastic dominance argument under these conditions. revision: yes
-
Referee: [§3.2] §3.2 (empirical Bayes estimator): The r-value is obtained by fitting the Normal-Normal (or nonparametric) empirical Bayes model to the observed scores; the resulting nonconformity score therefore depends on quantities estimated from the calibration data itself. This dependence must be shown not to violate the exchangeability required for marginal coverage; the current description leaves the effect on the guarantee unaddressed.
Authors: The data dependence is symmetric across calibration and test points because the empirical Bayes parameters are estimated from the pooled set of scores and the r-value for every point is computed identically using those fixed parameters. Consequently the vector of r-values remains exchangeable whenever the original scores are exchangeable. We will add a short lemma in §3.2 formalizing this invariance and confirming that the standard conformal coverage argument applies unchanged to the r-value scores. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper defines an r-value nonconformity score via empirical Bayes (Normal-Normal or nonparametric) applied to observed score variability, then invokes standard conformal prediction to guarantee coverage for any fixed nonconformity function. The coverage claim is distribution-free and does not reduce to a tautology or self-fit of the estimator; the EB step is used only to construct the score, while validity follows from exchangeability of the resulting scores. No quoted derivation equates the coverage result to the fitted hyperparameters by construction, nor imports uniqueness via self-citation, nor renames a known result. The derivation remains self-contained against the external CP benchmark.
Axiom & Free-Parameter Ledger
free parameters (1)
- prior hyperparameters in Normal-Normal empirical Bayes estimator
axioms (2)
- domain assumption Score variability is generated from a distribution compatible with the chosen empirical Bayes model (Normal-Normal or nonparametric)
- domain assumption Mild regularity conditions hold that allow the provable reduction in high-variance false candidates
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Using the r-value as the nonconformity score preserves the target conformal coverage while provably reducing the inclusion of high variance false candidates under mild regularity conditions.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the r-value estimates how likely a candidate’s latent score belongs to the top-ranked group after accounting for both its mean score and its uncertainty
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Rajendra Acharya, Vladimir Makarenkov, and Saeid Nahavandi
Moloud Abdar, Farhad Pourpanah, Sadiq Hussain, Dana Rezazadegan, Li Liu, Mohammad Ghavamzadeh, Paul Fieguth, Xiaochun Cao, Abbas Khosravi, U. Rajendra Acharya, Vladimir Makarenkov, and Saeid Nahavandi. A review of uncertainty quantification in deep learning: Techniques, applications and challenges.Information Fusion, 76:243–297, 5 2021. doi: 10.1016/j.inf...
-
[2]
Angelopoulos and Stephen Bates
Anastasios N. Angelopoulos and Stephen Bates. Conformal prediction: A gentle intro- duction.Foundations and Trends® in Machine Learning, 16(4):494–591, 1 2023. doi: 10.1561/2200000101. URLhttps://doi.org/10.1561/2200000101
-
[3]
Anastasios N. Angelopoulos, Stephen Bates, Emmanuel J. Candès, Michael Jordan, I, and Lihua Lei. Learn then Test: Calibrating Predictive Algorithms to Achieve Risk Control, 10 2021. URL https://arxiv.org/abs/2110.01052
-
[4]
Angelopoulos, Stephen Bates, Adam Fisch, Lihua Lei, and Tal Schuster
Anastasios N. Angelopoulos, Stephen Bates, Adam Fisch, Lihua Lei, and Tal Schuster. Con- formal Risk Control. InInternational Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=33XGfHLtZg
work page 2024
-
[5]
Conformalized Credal Re- gions for Classification with Ambiguous Ground Truth
Michele Caprio, David Stutz, Shuo Li, and Arnaud Doucet. Conformalized Credal Re- gions for Classification with Ambiguous Ground Truth. OpenReview, 2025. URL https: //openreview.net/forum?id=L7sQ8CW2FY
work page 2025
-
[6]
Angelica Chen, Jason Phang, Alicia Parrish, Vishakh Padmakumar, Chen Zhao, Samuel R. Bowman, and Kyunghyun Cho. Two failures of Self-Consistency in the Multi-Step reasoning of LLMs, 5 2023. URLhttps://arxiv.org/abs/2305.14279
-
[7]
Distributional Conformal Prediction
Victor Chernozhukov, Kaspar Wüthrich, and Yinchu Zhu. Distributional Conformal Prediction. Proceedings of the National Academy of Sciences, 118(48):e2107794118, 2021. doi: 10.1073/ pnas.2107794118. URLhttps://www.pnas.org/doi/10.1073/pnas.2107794118
-
[8]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021. URL https:...
work page 2021
-
[9]
Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning
Yarin Gal and Zoubin Ghahramani. Dropout as a Bayesian approximation: representing model uncertainty in deep learning, 6 2015. URLhttps://arxiv.org/abs/1506.02142
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[10]
Jia He, Mukund Rungta, David Koleczek, Arshdeep Sekhon, Franklin X. Wang, and Sadid Hasan. Does prompt formatting have any impact on llm performance?, 2024. URL https: //arxiv.org/abs/2411.10541
-
[11]
Nicholas C. Henderson and Michael A. Newton. Making the cut: Improved ranking and selection for Large-Scale inference.Journal of the Royal Statistical Society Series B (Statistical Methodology), 78(4):781–804, 11 2015. doi: 10.1111/rssb.12131. URL https://doi.org/ 10.1111/rssb.12131
-
[12]
Conffusion: confidence intervals for diffusion models, 11
Eliahu Horwitz and Yedid Hoshen. Conffusion: confidence intervals for diffusion models, 11
- [13]
-
[14]
Parameter-Efficient Transfer Learning for NLP
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, De Laroussilhe Quentin, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-Efficient Transfer Learning for NLP, 2 2019. URLhttps://arxiv.org/abs/1902.00751
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[15]
Conformalized Credal Set Predictors
Alireza Javanmardi, David Stutz, and Eyke Hüllermeier. Conformalized Credal Set Predictors. InAdvances in Neural Information Processing Systems, 2024. URL https://proceedings.neurips.cc/paper_files/paper/2024/file/ d42a8bf2f40555d4a5120300f98c88f6-Paper-Conference.pdf. 10
work page 2024
-
[16]
Laurent Valentin Jospin, Hamid Laga, Farid Boussaid, Wray Buntine, and Mohammed Ben- namoun. Hands-On Bayesian Neural Networks—A tutorial for deep learning users.IEEE Computational Intelligence Magazine, 17(2):29–48, 4 2022. doi: 10.1109/mci.2022.3155327. URLhttps://doi.org/10.1109/mci.2022.3155327
-
[17]
Length Optimization in Conformal Prediction, 2024
Shayan Kiyani, George Pappas, and Hamed Hassani. Length Optimization in Conformal Prediction, 2024. URLhttps://arxiv.org/abs/2406.18814
-
[18]
Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles, 12 2016. URL https://arxiv. org/abs/1612.01474
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[19]
Zongxia Li, Xiyang Wu, Hongyang Du, Huy Nghiem, and Guangyao Shi. Benchmark Evalua- tions, Applications, and Challenges of large Vision Language Models: a survey, 1 2025. URL https://arxiv.org/abs/2501.02189
-
[20]
TruthfulQA: Measuring How Models Mimic Human Falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods, 2022. URLhttps://arxiv.org/abs/2109.07958
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Conformity Score Averaging for Classification
Rui Luo and Zhixin Zhou. Conformity Score Averaging for Classification. InProceedings of the 42nd International Conference on Machine Learning, 2025. URL https://proceedings. mlr.press/v267/luo25v.html
work page 2025
-
[22]
Rui Luo and Zhixin Zhou. Trustworthy classification through rank-based conformal prediction sets.Pattern Recognition, 172:112330, 2026. doi: 10.1016/j.patcog.2025.112330
-
[23]
Eric Mitchell, Joseph J. Noh, Siyan Li, William S. Armstrong, Ananth Agarwal, Patrick Liu, Chelsea Finn, and Christopher D. Manning. Enhancing Self-Consistency and Performance of Pre-Trained Language Models through Natural Language Inference, 11 2022. URL https: //arxiv.org/abs/2211.11875
-
[24]
M. A. Newton, N. G. Polson, and J. Xu. Weighted bayesian bootstrap for scalable posterior distributions.Canadian Journal of Statistics, 49(2):421–437, 2020. doi: https://doi.org/10. 1002/cjs.11570
work page 2020
-
[25]
Daniel Nolte, Souparno Ghosh, and Ranadip Pal. Efficient Normalized Conformal Prediction and Uncertainty Quantification for Anti-Cancer Drug Sensitivity Prediction with Deep Regression Forests, 2024. URLhttps://arxiv.org/abs/2402.14080
-
[26]
Conformal Prediction for Ensem- bles: Improving Efficiency via Score-Based Aggregation
Eduardo Ochoa Rivera, Yash Patel, and Ambuj Tewari. Conformal Prediction for Ensem- bles: Improving Efficiency via Score-Based Aggregation. InAdvances in Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=sNTqqdPVSv
work page 2025
-
[27]
Efficient Conformal Prediction under Data Heterogeneity
Vincent Plassier, Nikita Kotelevskii, Aleksandr Rubashevskii, Fedor Noskov, Maksim Ve- likanov, Alexander Fishkov, Samuel Horvath, Martin Takác, Éric Moulines, Maxim Panov, Lagrange Mathematics, Computing Research Center, Paris CMAP, Ecole Polytechnique, Skolkovo Institute of Science, Technology, Moscow HSE University, Technology Innova- tion Institute, a...
work page 2024
-
[28]
Conformal language modeling.arXiv preprint arXiv:2306.10193, 2023
Victor Quach, Adam Fisch, Tal Schuster, Adam Yala, Jae Ho Sohn, Tommi S. Jaakkola, and Regina Barzilay. Conformal language modeling, 6 2023. URL https://arxiv.org/abs/ 2306.10193
-
[29]
Conformal prediction under ambiguous ground truth.Transactions on Machine Learning Research, 2023
David Stutz, Abhijit Guha Roy, Tatiana Matejovicova, Patricia Strachan, Ali Taylan Cemgil, and Arnaud Doucet. Conformal prediction under ambiguous ground truth.Transactions on Machine Learning Research, 2023. URLhttps://openreview.net/forum?id=CAd6V2qXxc
work page 2023
-
[30]
Vladimir V ovk, Alexander Gammerman, and Glenn Shafer.Algorithmic Learning in a Random World. Springer, 2005. URLhttps://link.springer.com/book/10.1007/b98835. 11
-
[31]
Mitigating LLM hallucinations via conformal abstention, 4 2024
Yasin Abbasi Yadkori, Ilja Kuzborskij, David Stutz, András György, Adam Fisch, Arnaud Doucet, Iuliya Beloshapka, Wei-Hung Weng, Yao-Yuan Yang, Csaba Szepesvári, Ali Taylan Cemgil, and Nenad Tomasev. Mitigating LLM hallucinations via conformal abstention, 4 2024. URLhttps://arxiv.org/abs/2405.01563
-
[32]
Scaling vision transform- ers, 6 2021
Xiaohua Zhai, Alexander Kolesnikov, Neil Houlsby, and Lucas Beyer. Scaling vision transform- ers, 6 2021. URLhttps://arxiv.org/abs/2106.04560. 12 A Code Availability We provide the full implementation of the r-value method and demo for CLIP at: https://github.com/Yogesh914/conformal-rvalue B Computation Efficiency Analysis Table 3: Training time for 1,000...
-
[33]
For any selected conformal setC, the expected size of the set can be decomposed as: E[|C|] =E X 1(y true ∈C) + X y′̸=ytrue 1(y ′ ∈C) = Pr (ytrue ∈C) + X y′̸=ytrue Pr (y′ ∈C), where1(·)is the indicator function andy true is the true label. We want to show that E[|Cr|]−E[|C avg|] = (P(y true ∈C r)−P(y true ∈C avg)) + X y′̸=ytrue (P(y ′ ∈C r)−P(y ′ ∈C...
-
[34]
Uniform dominance of inclusion probabilities.For every moderately small σ2 ≥0 and every false labely ′ withθ y′ =µ 0, P r incl σ2 |µ 0 ≤P std incl σ2 |µ 0 . Then the r-value conformal predictor produces, on average, a smaller prediction set than standard conformal prediction: E[|C r|]≤E[|C std|]. Proof. Let Ytrue denote the true label, and let y′ ̸=Y true...
-
[35]
This implies E[|C avg|]≥E[|C r|]
Expectation-level guarantee.Iff(δ)≥0, thenE[G k]≥0. This implies E[|C avg|]≥E[|C r|]
-
[36]
High-probability guarantee.Note that for each i, the difference 1(i∈C avg)−1(i∈C r) lies in[−1,1]. Since these are independent acrossi, we may apply Hoeffding’s inequality: P(Gk ≤0) =P(G k −E[G k]≤ −E[G k]) ≤exp −2E[G k]2 4k ≤exp −2(kf(δ)) 2 4k = exp −1 2 kf(δ) 2 . To ensure P(|C r|<|C avg|)≥1−η, we require: exp −1 2 kf(δ) 2 ≤η⇐ ⇒k≥ 2 log(1/η) f(δ) 2 . Th...
-
[37]
Read the description carefully
-
[38]
Generate{num_rephrases}diverse and natural-sounding rephrasings of the description
-
[39]
Keep the core meaning the same
-
[40]
Return a JSON object with the keyrephrased_descriptions, containing a list of strings. User prompt. Original description:{input_image_description} 29 GPQA Rephrasing Prompt System prompt. You are an expert exam question rephraser. Your task is to:
-
[41]
Read the question and its answer options carefully
-
[42]
Generate different rephrased versions of the question while maintaining relevance to the answer options
-
[43]
Return the rephrased versions as a JSON object with the keyrephrased_questions, containing a list of strings
-
[44]
Return exactly the requested number of rephrased questions. User prompt. Rephrase the following question while considering the answer options. Question:{input_text} Answer options:{options_text} Number of rephrased questions to return:{num_rephrases} TruthfulQA Evaluation Prompt System prompt. You are an expert evaluator assessing how well answers address...
-
[45]
Read each question and the provided answer carefully
-
[46]
Evaluate how directly and completely the answer addresses each question
-
[47]
Consider factors such as accuracy, relevance, and comprehensiveness
-
[48]
Assign a score from 0 to 10, with one decimal place, for each question
-
[49]
Return the scores as a JSON object with ascoresarray
-
[50]
Use the full range of decimal scores, avoid round numbers, and avoid assigning the same score to every question. User prompt. Evaluate how well the following answer addresses each question. Return only a JSON object with a scores array containing scores from 0 to 10 with one decimal place. Answer to evaluate:{answer} Questions:{formatted_questions} I Broa...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.