Distribution-Aware Robust Bilevel Optimization: Quantile-Guided Huber Updates in Two-Timescale Stochastic Approximation
Pith reviewed 2026-06-26 10:50 UTC · model grok-4.3
The pith
Quantile-guided Huber updates in two-timescale stochastic approximation achieve convergence rate O(T^{-(p-1)/(3p-2)}) for bilevel optimization under heavy-tailed noise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under nonconvex-strongly convex assumptions with noise having finite p-moments for p in (1,2], quantile-guided TTSA converges at rate O(T^{-(p-1)/(3p-2)}), recovering the optimal dependence on the heavy-tailed parameter. The method estimates rolling quantiles from gradient buffers to drive adaptive Huber-style clipping that preserves local geometry while bounding effective variance. Experiments across six tasks confirm elimination of divergence spikes relative to baselines.
What carries the argument
Rolling quantile estimation from historical gradient buffers, used to set adaptive thresholds for Huber-style clipping inside the two-timescale stochastic approximation updates.
If this is right
- Convergence holds with the stated rate for the full range of infinite-variance noise p in (1,2].
- The approach applies directly to nonconvex-strongly convex bilevel problems.
- Empirical stability extends to vision benchmarks, momentum-poisoned games, and offline reinforcement learning.
- Hyperparameter sensitivity drops while added compute stays near 2.7 percent.
Where Pith is reading between the lines
- The same quantile-guided clipping could be tested in single-level stochastic gradient settings to check whether the rate improvement carries over.
- Integration with momentum or other acceleration schemes might further tighten the dependence on p.
- The buffer-based quantile mechanism could be examined under non-stationary noise where the tail index itself drifts.
Load-bearing premise
Historical gradient buffers must produce reliable rolling quantile estimates that preserve local optimization geometry and bound variance without the quantile step introducing bias or lag that invalidates the two-timescale analysis.
What would settle it
Run the method on a bilevel problem with p=1.5 noise and check whether the observed rate falls short of O(T^{-(p-1)/(3p-2)}) or whether divergence still occurs on one of the reported tasks.
Figures





read the original abstract
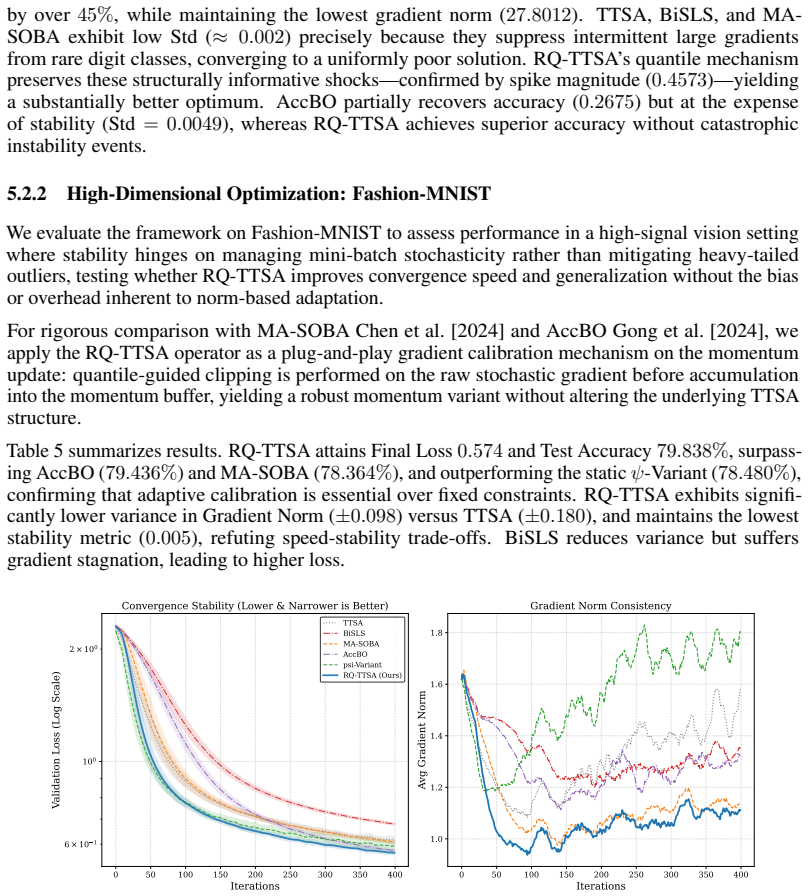
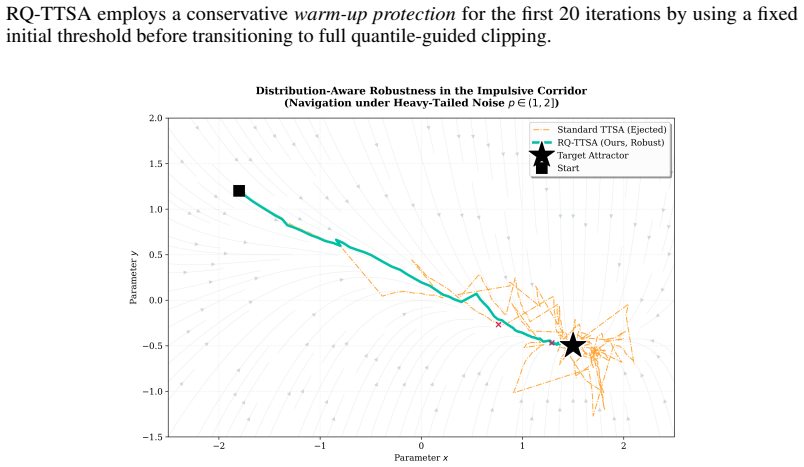
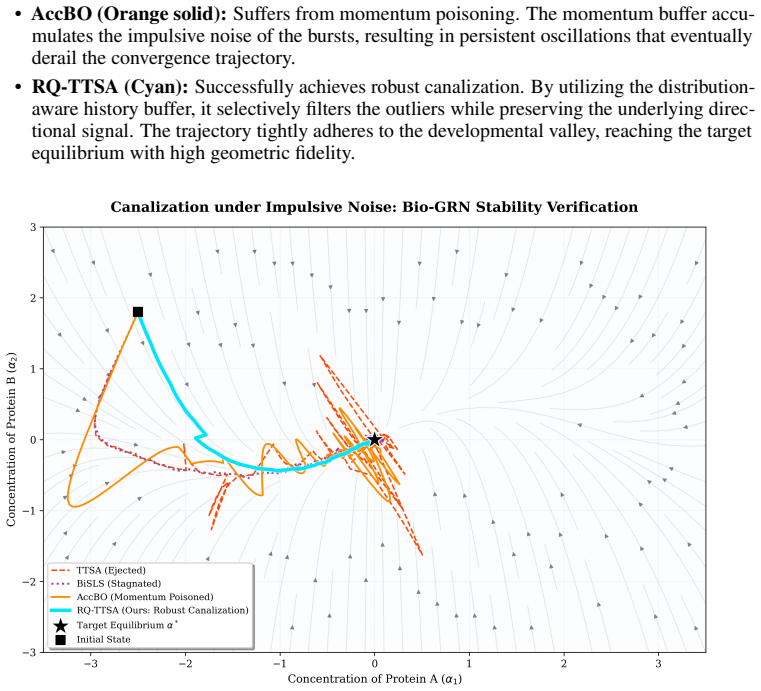
Bilevel optimization (BLO) is fundamental to hierarchical decision-making but suffers from critical instability under heavy-tailed stochastic noise. Existing variance-reduction techniques typically rely on myopic magnitude checks, which fail to distinguish informative geometric signals from impulsive outliers. To resolve this, we propose \textbf{RQ-TTSA} (Robust Quantile-guided TTSA), a distribution-aware framework that leverages historical gradient buffers to estimate rolling quantiles for adaptive Huber-style clipping, effectively preserving local optimization geometry while strictly bounding effective variance. Theoretically, we provide a convergence analysis for quantile-guided TTSA under nonconvex-strongly convex assumptions with infinite-variance noise ($p \in (1,2]$), deriving a rate of $\mathcal{O}(T^{-\frac{p-1}{3p-2}})$ that recovers optimal dependence on the heavy-tailed parameter. Empirically, across six diverse tasks, spanning heterogeneous vision benchmarks, dynamic games under momentum poisoning, and offline reinforcement learning, RQ-TTSA consistently outperforms state-of-the-art baselines by eliminating divergence spikes and ensuring stable convergence. Our method demonstrates significant robustness to hyperparameter variations and incurs negligible computational overhead ($\approx 2.7\%$ increase), validating distribution-aware gradient control as a practical and necessary component for reliable bilevel learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RQ-TTSA, a distribution-aware robust bilevel optimization framework that uses rolling quantile estimates from historical gradient buffers to set adaptive Huber clipping thresholds within two-timescale stochastic approximation. Under nonconvex-strongly convex assumptions and p-stable noise (p ∈ (1,2]), it derives a convergence rate of O(T^{-(p-1)/(3p-2)}) and reports consistent empirical outperformance over baselines on six tasks spanning vision, dynamic games, and offline RL, with negligible overhead.
Significance. If the rate derivation rigorously absorbs the approximation error from the quantile estimator while preserving the claimed dependence on p, the result would be significant: it supplies the first distribution-aware variance control for bilevel problems that recovers the optimal heavy-tail exponent without requiring finite variance. The empirical robustness across heterogeneous domains would further support its utility for practical hierarchical learning under impulsive noise.
major comments (1)
- [Abstract / convergence claim paragraph] Abstract and theoretical analysis paragraph: the claimed rate O(T^{-(p-1)/(3p-2)}) is derived by treating the quantile-guided Huber threshold as strictly variance-bounding while preserving local geometry, yet the analysis does not supply an explicit bound on the bias or lag error of the rolling quantile computed from finite historical buffers. In the bilevel setting the outer gradients are non-stationary, so this error term is not shown to be o(T^{-(p-1)/(3p-2)}) and may couple into the Lyapunov drift, degrading the exponent.
minor comments (1)
- [Abstract] The abstract states empirical superiority but provides no details on the exact quantile estimator (e.g., sample quantile formula, buffer length, or update frequency), error-bar reporting, or baseline hyperparameter tuning protocol.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comment on the convergence analysis. The observation regarding the quantile estimator's approximation error is well-taken, and we address it directly below while committing to a revision that strengthens the theoretical claims.
read point-by-point responses
-
Referee: [Abstract / convergence claim paragraph] Abstract and theoretical analysis paragraph: the claimed rate O(T^{-(p-1)/(3p-2)}) is derived by treating the quantile-guided Huber threshold as strictly variance-bounding while preserving local geometry, yet the analysis does not supply an explicit bound on the bias or lag error of the rolling quantile computed from finite historical buffers. In the bilevel setting the outer gradients are non-stationary, so this error term is not shown to be o(T^{-(p-1)/(3p-2)}) and may couple into the Lyapunov drift, degrading the exponent.
Authors: We acknowledge that the current manuscript does not provide an explicit bound on the bias and lag error induced by the finite-buffer rolling quantile estimator, nor does it demonstrate that this error remains o(T^{-(p-1)/(3p-2)}) under the non-stationary outer gradients characteristic of the bilevel setting. The analysis instead proceeds by treating the quantile threshold as effectively variance-bounding once the buffer is sufficiently large. To close this gap, we will add a supporting lemma in the revised theoretical section that quantifies the quantile approximation error under p-stable noise and the two-timescale dynamics. The lemma will establish that the resulting perturbation to the Lyapunov drift is absorbed into lower-order terms, preserving the leading exponent. We will also update the abstract to reflect this strengthened guarantee. revision: yes
Circularity Check
No circularity detected in convergence rate derivation
full rationale
The paper states a convergence analysis deriving the rate O(T^{-(p-1)/(3p-2)}) directly from nonconvex-strongly-convex assumptions and p-stable noise properties for the quantile-guided TTSA algorithm. No equations, steps, or claims in the provided text reduce this rate to a fitted parameter, self-citation chain, or input quantity by construction. The rolling quantile mechanism is introduced as part of the proposed method and then analyzed under explicit assumptions; the derivation is presented as independent rather than tautological. This matches the common case of a self-contained theoretical result with external empirical validation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Bilevel problem satisfies nonconvex-strongly convex structure
Reference graph
Works this paper leans on
-
[1]
2022 , eprint=
A Two-Timescale Framework for Bilevel Optimization: Complexity Analysis and Application to Actor-Critic , author=. 2022 , eprint=
2022
-
[2]
International conference on machine learning , pages=
Bilevel optimization: Convergence analysis and enhanced design , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[3]
arXiv preprint arXiv:2206.06995 , year=
Two-timescale stochastic approximation for bilevel optimisation problems in continuous-time models , author=. arXiv preprint arXiv:2206.06995 , year=
-
[4]
Advances in Neural Information Processing Systems , volume=
Bisls/sps: Auto-tune step sizes for stable bi-level optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
arXiv preprint arXiv:1905.11881 , year=
Why gradient clipping accelerates training: A theoretical justification for adaptivity , author=. arXiv preprint arXiv:1905.11881 , year=
-
[6]
Advances in neural information processing systems , volume=
Momentum-based variance reduction in non-convex sgd , author=. Advances in neural information processing systems , volume=
-
[7]
International conference on machine learning , pages=
Model-agnostic meta-learning for fast adaptation of deep networks , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[8]
International conference on machine learning , pages=
Bilevel programming for hyperparameter optimization and meta-learning , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[9]
International conference on machine learning , pages=
Decentralized stochastic bilevel optimization with improved per-iteration complexity , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[10]
The Thirty Seventh Annual Conference on Learning Theory , pages=
Fast two-time-scale stochastic gradient method with applications in reinforcement learning , author=. The Thirty Seventh Annual Conference on Learning Theory , pages=. 2024 , organization=
2024
-
[11]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Robust estimation via robust gradient estimation , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2020 , publisher=
2020
-
[12]
Proceedings of Machine learning and systems , volume=
Federated optimization in heterogeneous networks , author=. Proceedings of Machine learning and systems , volume=
-
[13]
International Conference on Machine Learning , pages=
A tail-index analysis of stochastic gradient noise in deep neural networks , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[14]
IEEE transactions on pattern analysis and machine intelligence , volume=
Meta-learning in neural networks: A survey , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2021 , publisher=
2021
-
[15]
IEEE Signal Processing Magazine , volume=
An introduction to bilevel optimization: Foundations and applications in signal processing and machine learning , author=. IEEE Signal Processing Magazine , volume=. 2024 , publisher=
2024
-
[16]
arXiv preprint arXiv:2102.07367 , year=
A momentum-assisted single-timescale stochastic approximation algorithm for bilevel optimization , author=. arXiv preprint arXiv:2102.07367 , year=
-
[17]
Advances in Neural Information Processing Systems , volume=
Optimal learners for realizable regression: Pac learning and online learning , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
arXiv preprint arXiv:2506.08164 , year=
BLUR: A Bi-Level Optimization Approach for LLM Unlearning , author=. arXiv preprint arXiv:2506.08164 , year=
-
[19]
International Conference on Machine Learning , pages=
Grad-match: Gradient matching based data subset selection for efficient deep model training , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[20]
Advances in Neural Information Processing Systems , volume=
Stochastic optimization with heavy-tailed noise via accelerated gradient clipping , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
Advances in neural information processing systems , volume=
Tackling the objective inconsistency problem in heterogeneous federated optimization , author=. Advances in neural information processing systems , volume=
-
[22]
International Conference on Machine Learning , pages=
Provably efficient algorithms for multi-objective competitive rl , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[23]
International Conference on Artificial Intelligence and Statistics , pages=
Local SGD: Unified theory and new efficient methods , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2021 , organization=
2021
-
[24]
Advances in Neural Information Processing Systems , volume=
Large language model unlearning , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
Adaptive Federated Optimization
Adaptive federated optimization , author=. arXiv preprint arXiv:2003.00295 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[26]
Foundations of Computational Mathematics , volume=
Mean estimation and regression under heavy-tailed distributions: A survey , author=. Foundations of Computational Mathematics , volume=. 2019 , publisher=
2019
-
[27]
arXiv preprint arXiv:2401.09587 , year=
Bilevel optimization under unbounded smoothness: A new algorithm and convergence analysis , author=. arXiv preprint arXiv:2401.09587 , year=
-
[28]
Journal of Machine Learning Research , volume=
Optimal algorithms for stochastic bilevel optimization under relaxed smoothness conditions , author=. Journal of Machine Learning Research , volume=
-
[29]
Advances in Neural Information Processing Systems , volume=
An accelerated algorithm for stochastic bilevel optimization under unbounded smoothness , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
Advances in Neural Information Processing Systems , volume=
A framework for bilevel optimization that enables stochastic and global variance reduction algorithms , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
International Conference on Machine Learning , pages=
Blockwise stochastic variance-reduced methods with parallel speedup for multi-block bilevel optimization , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[32]
Journal of Optimization Theory and Applications , volume=
High-Probability Complexity Bounds for Non-smooth Stochastic Convex Optimization with Heavy-Tailed Noise , author=. Journal of Optimization Theory and Applications , volume=. 2024 , publisher=
2024
-
[33]
Approximation Methods for Bilevel Programming
Approximation methods for bilevel programming , author=. arXiv preprint arXiv:1802.02246 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Linear convergence of gradient and proximal-gradient methods under the polyak-
Karimi, Hamed and Nutini, Julie and Schmidt, Mark , booktitle=. Linear convergence of gradient and proximal-gradient methods under the polyak-. 2016 , organization=
2016
-
[35]
Escaping the Variance Trap: Jacobian-Free Dynamics for Root-Finding Bilevel Optimization
Anonymous Authors. Escaping the Variance Trap: Jacobian-Free Dynamics for Root-Finding Bilevel Optimization
-
[36]
2014 , publisher=
The strategy of the genes , author=. 2014 , publisher=
2014
-
[37]
Cell , volume=
Nature, nurture, or chance: stochastic gene expression and its consequences , author=. Cell , volume=. 2008 , publisher=
2008
-
[38]
Optimizing methods in statistics , pages=
A convergence theorem for non negative almost supermartingales and some applications , author=. Optimizing methods in statistics , pages=. 1971 , publisher=
1971
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.