A Theoretical Analysis of Memory and Overfitting Phenomena in Stochastic Interpolation Models
Pith reviewed 2026-06-27 18:33 UTC · model grok-4.3
The pith
Stochastic interpolation models recover training samples exactly in continuous time when the optimal velocity field is known, and stay close under discretization and errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By leveraging closed-form expressions for the optimal velocity field and the associated score function, we show that, in the continuous-time oracle setting, both deterministic and stochastic generation processes recover training samples. Under Euler discretization, generated samples remain centered around training samples, with deviations controlled by the step size. We further analyze generation in the presence of estimation errors and show that accumulated estimation errors control the endpoint deviation from the training set. These results imply that the generated sample admits a representation as a training sample perturbed by three controlled terms: a discretization-induced bound, an es
What carries the argument
The representation of the generated sample as a training sample perturbed by three controlled terms (discretization bound, estimation-error bound, and Gaussian noise), derived from closed-form optimal velocity field and score function.
If this is right
- Both deterministic and stochastic generation recover training samples exactly in the continuous-time oracle setting.
- Under Euler discretization the output stays centered on training samples with deviations controlled by step size.
- Accumulated estimation errors bound the final deviation from the training set.
- The generated sample equals a training sample plus three controlled perturbation terms.
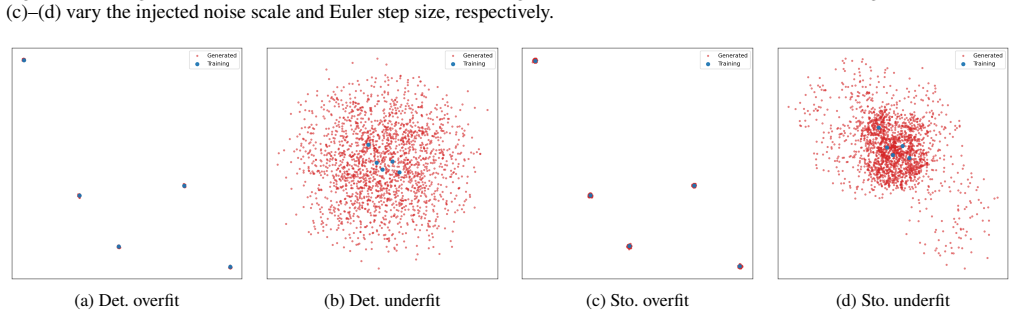
- Overfitting and underfitting receive precise definitions in terms of the sizes of those perturbation terms.
Where Pith is reading between the lines
- The same perturbation decomposition could be used to set step-size or noise schedules that keep generated outputs within a chosen distance of the training set.
- If closed-form velocity fields are unavailable for real data, the recovery guarantee may degrade to an approximate centering result rather than exact match.
- The analysis isolates memorization as a property of the interpolation operator itself, separate from how the velocity field is learned.
- Similar bounding arguments might extend to other score-based or flow-based generative models that admit comparable closed forms.
Load-bearing premise
The existence of closed-form expressions for the optimal velocity field and the associated score function in the continuous-time oracle setting.
What would settle it
A numerical check in which the closed-form velocity field is substituted into the continuous-time ODE and the endpoint fails to match the training sample exactly would falsify the recovery claim.
Figures
read the original abstract
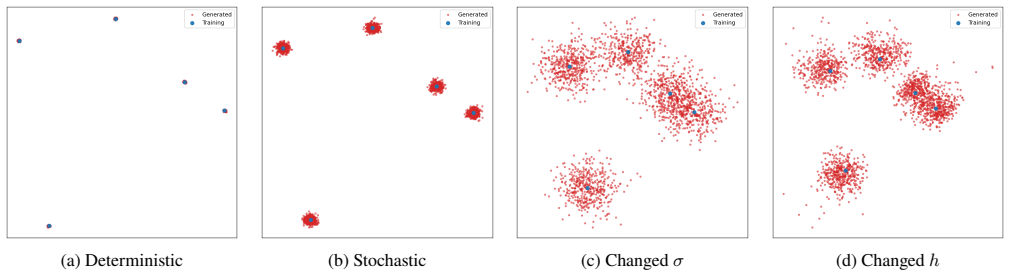
This paper provides a theoretical account of memorization in stochastic interpolation models. By leveraging closed-form expressions for the optimal velocity field and the associated score function, we show that, in the continuous-time oracle setting, both deterministic and stochastic generation processes recover training samples. Under Euler discretization, generated samples remain centered around training samples, with deviations controlled by the step size. We further analyze generation in the presence of estimation errors and show that accumulated estimation errors control the endpoint deviation from the training set. These results imply that the generated sample admits a representation as a training sample perturbed by three controlled terms: a discretization-induced bound, an estimation-error-induced bound, and stochastic Gaussian noise. Based on this characterization, we provide theoretical definitions of overfitting and underfitting in generative models. Synthetic simulations support our theoretical findings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript provides a theoretical analysis of memorization in stochastic interpolation models. Leveraging closed-form expressions for the optimal velocity field and score function, it claims that in the continuous-time oracle setting both deterministic and stochastic generation processes recover training samples exactly. Under Euler discretization, generated samples remain centered around training samples with deviations controlled by step size. In the presence of estimation errors, accumulated errors bound the endpoint deviation from the training set. Generated samples are characterized as a training sample perturbed by three controlled terms (discretization bound, estimation-error bound, and Gaussian noise). Theoretical definitions of overfitting and underfitting are proposed, supported by synthetic simulations.
Significance. If the closed-form expressions and recovery claims hold rigorously, the work supplies a precise perturbation decomposition that could clarify the mechanisms of memorization versus generalization in flow-based and diffusion-style generative models. The explicit definitions of overfitting/underfitting and the controlled-error representation are potentially useful for guiding regularization strategies. The inclusion of synthetic simulations is a positive step toward falsifiability, though the overall contribution remains conditional on the validity of the oracle closed-forms.
major comments (2)
- [Continuous-time oracle setting / recovery theorem] The exact-recovery claim for both deterministic and stochastic processes in the continuous-time oracle setting (abstract and the section deriving the recovery result) is established by direct invocation of closed-form expressions for the optimal velocity field and score function. The manuscript must derive these expressions explicitly from the stochastic interpolation SDE, state all regularity conditions on the data distribution and interpolation kernel, and verify that the endpoint lands exactly at a training point; without this derivation the subsequent discretization and estimation-error bounds rest on an unverified premise.
- [Discretization and estimation-error analysis] The representation of the generated sample as a training point perturbed by three controlled terms (discretization, estimation error, Gaussian noise) is presented as following from the oracle recovery plus error accumulation. The error-propagation argument should be made fully rigorous with explicit bounds (e.g., via Gronwall-type estimates or inductive control on the Euler steps) rather than informal accumulation statements, as this decomposition underpins the proposed definitions of overfitting and underfitting.
minor comments (2)
- Notation for the stochastic interpolation SDE, velocity field, and score function should be introduced with a single consistent table or list of symbols early in the paper to improve readability.
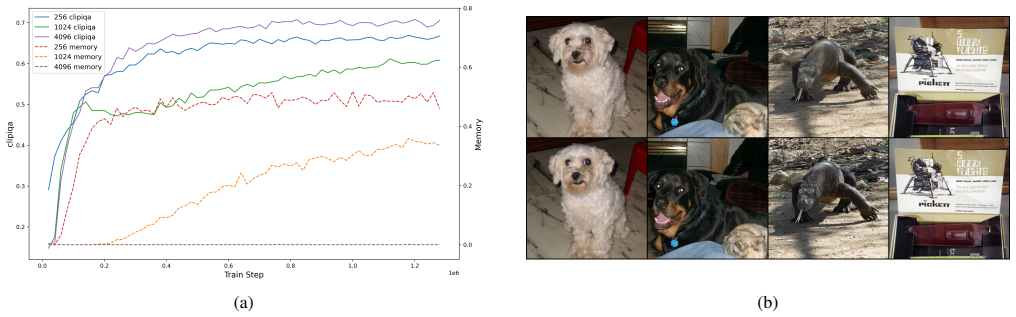
- [Synthetic simulations] The synthetic simulations section would benefit from explicit statements of the data distributions, interpolation kernels, and step-size schedules used, together with quantitative metrics (e.g., endpoint deviation histograms) rather than qualitative descriptions alone.
Simulated Author's Rebuttal
We thank the referee for the constructive comments that highlight opportunities to strengthen the rigor of our derivations. We address each major point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Continuous-time oracle setting / recovery theorem] The exact-recovery claim for both deterministic and stochastic processes in the continuous-time oracle setting (abstract and the section deriving the recovery result) is established by direct invocation of closed-form expressions for the optimal velocity field and score function. The manuscript must derive these expressions explicitly from the stochastic interpolation SDE, state all regularity conditions on the data distribution and interpolation kernel, and verify that the endpoint lands exactly at a training point; without this derivation the subsequent discretization and estimation-error bounds rest on an unverified premise.
Authors: We agree that an explicit derivation from the SDE is required for completeness. In the revision we will add a self-contained subsection that starts from the stochastic interpolation SDE, derives the closed-form optimal velocity field and score function under stated regularity conditions (finite second moments on the data distribution, Lipschitz continuity of the velocity field, and sufficient smoothness of the interpolation kernel), and directly verifies exact endpoint recovery for both the deterministic and stochastic processes. This will remove any reliance on unverified premises. revision: yes
-
Referee: [Discretization and estimation-error analysis] The representation of the generated sample as a training point perturbed by three controlled terms (discretization, estimation error, Gaussian noise) is presented as following from the oracle recovery plus error accumulation. The error-propagation argument should be made fully rigorous with explicit bounds (e.g., via Gronwall-type estimates or inductive control on the Euler steps) rather than informal accumulation statements, as this decomposition underpins the proposed definitions of overfitting and underfitting.
Authors: We concur that the error-accumulation argument must be formalized. The revised manuscript will replace the informal statements with a rigorous error-propagation analysis that applies Gronwall's inequality (or an inductive bound on successive Euler steps) to obtain explicit constants controlling the discretization and estimation-error terms. The resulting three-term perturbation representation will then rest on these bounds, directly supporting the definitions of overfitting and underfitting. revision: yes
Circularity Check
No significant circularity; derivation self-contained via independent closed-forms
full rationale
The paper's strongest claim (exact recovery of training samples in the continuous-time oracle setting) is established by leveraging closed-form expressions for the optimal velocity field and score function. These expressions are invoked as given in the oracle setting to derive the recovery property for both deterministic and stochastic processes, after which discretization, estimation-error accumulation, and the three-term perturbation representation follow as downstream consequences. No quoted step reduces the recovery result to a self-definition, a fitted parameter renamed as prediction, or a self-citation chain; the closed-forms are treated as external to the recovery argument rather than defined circularly in terms of it. The subsequent theoretical definitions of overfitting/underfitting are likewise derived from the perturbation characterization without looping back to the inputs. This is the normal outcome for a self-contained theoretical analysis whose central steps do not collapse by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existence of closed-form expressions for the optimal velocity field and score function
Reference graph
Works this paper leans on
-
[1]
Greenwade
George D. Greenwade. The C omprehensive T ex A rchive N etwork ( CTAN ). TUGBoat. 1993
1993
-
[2]
arXiv preprint arXiv:2310.05264 , year=
The Emergence of Reproducibility and Generalizability in Diffusion Models , author=. arXiv preprint arXiv:2310.05264 , year=
-
[3]
International Conference on Machine Learning , pages=
Data-copying in generative models: a formal framework , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[4]
arXiv preprint arXiv:2310.02557 , year=
Generalization in diffusion models arises from geometry-adaptive harmonic representations , author=. arXiv preprint arXiv:2310.02557 , year=
-
[5]
arXiv preprint arXiv:2410.23594 , year=
How Do Flow Matching Models Memorize and Generalize in Sample Data Subspaces? , author=. arXiv preprint arXiv:2410.23594 , year=
-
[6]
arXiv preprint arXiv:2310.02664 , year=
On memorization in diffusion models , author=. arXiv preprint arXiv:2310.02664 , year=
-
[7]
arXiv preprint arXiv:2305.14712 , year=
On the generalization of diffusion model , author=. arXiv preprint arXiv:2305.14712 , year=
-
[8]
Advances in Neural Information Processing Systems , volume=
Understanding and mitigating copying in diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
International conference on artificial intelligence and statistics , year=
A non-parametric test to detect data-copying in generative models , author=. International conference on artificial intelligence and statistics , year=
-
[10]
European Conference on Computer Vision , pages=
Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[11]
arXiv preprint arXiv:2410.06940 , year=
Representation alignment for generation: Training diffusion transformers is easier than you think , author=. arXiv preprint arXiv:2410.06940 , year=
-
[12]
arXiv preprint arXiv:2303.08797 , year=
Stochastic interpolants: A unifying framework for flows and diffusions , author=. arXiv preprint arXiv:2303.08797 , year=
-
[13]
arXiv preprint arXiv:2209.15571 , year=
Building normalizing flows with stochastic interpolants , author=. arXiv preprint arXiv:2209.15571 , year=
-
[14]
arXiv preprint arXiv:2011.13456 , year=
Score-based generative modeling through stochastic differential equations , author=. arXiv preprint arXiv:2011.13456 , year=
Pith/arXiv arXiv 2011
-
[15]
arXiv preprint arXiv:2210.02747 , year=
Flow matching for generative modeling , author=. arXiv preprint arXiv:2210.02747 , year=
-
[16]
International Conference on Machine Learning , pages=
Diffusion models are minimax optimal distribution estimators , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[17]
arXiv preprint arXiv:2312.05579 , year=
Conditional stochastic interpolation for generative learning , author=. arXiv preprint arXiv:2312.05579 , year=
-
[18]
arXiv preprint arXiv:2403.12448 , year=
Do generated data always help contrastive learning? , author=. arXiv preprint arXiv:2403.12448 , year=
-
[19]
ICML 2023 workshop on structured probabilistic inference \ & \ generative modeling , year=
Diffusion probabilistic models generalize when they fail to memorize , author=. ICML 2023 workshop on structured probabilistic inference \ & \ generative modeling , year=
2023
-
[20]
arXiv preprint arXiv:2502.09992 , year=
Large language diffusion models , author=. arXiv preprint arXiv:2502.09992 , year=
-
[21]
arXiv preprint arXiv:2308.12219 , year=
Diffusion language models can perform many tasks with scaling and instruction-finetuning , author=. arXiv preprint arXiv:2308.12219 , year=
-
[22]
arXiv preprint arXiv:2410.17891 , year=
Scaling Diffusion Language Models via Adaptation from Autoregressive Models , author=. arXiv preprint arXiv:2410.17891 , year=
-
[23]
Advances in Neural Information Processing Systems , volume=
One-step effective diffusion network for real-world image super-resolution , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Seesr: Towards semantics-aware real-world image super-resolution , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[25]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[26]
arXiv preprint arXiv:2206.04119 , year=
Diffusion probabilistic modeling of protein backbones in 3d for the motif-scaffolding problem , author=. arXiv preprint arXiv:2206.04119 , year=
-
[27]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Scalable diffusion models with transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[28]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Maniqa: Multi-dimension attention network for no-reference image quality assessment , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[29]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Exploring simple siamese representation learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[30]
Advances in neural information processing systems , volume=
Unsupervised learning of visual features by contrasting cluster assignments , author=. Advances in neural information processing systems , volume=
-
[31]
International conference on machine learning , pages=
A simple framework for contrastive learning of visual representations , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[32]
arXiv preprint arXiv:2003.04297 , year=
Improved baselines with momentum contrastive learning , author=. arXiv preprint arXiv:2003.04297 , year=
Pith/arXiv arXiv 2003
-
[33]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Residual denoising diffusion models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[34]
Advances in Neural Information Processing Systems , volume=
Resshift: Efficient diffusion model for image super-resolution by residual shifting , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
Generalization through variance: how noise shapes inductive biases in diffusion models , author=
-
[36]
arXiv e-prints , pages=
On the Closed-Form of Flow Matching: Generalization Does Not Arise from Target Stochasticity , author=. arXiv e-prints , pages=
-
[37]
arXiv preprint arXiv:2401.04856 , year=
A good score does not lead to a good generative model , author=. arXiv preprint arXiv:2401.04856 , year=
-
[38]
arXiv e-prints , pages=
From memorization to generalization: a theoretical framework for diffusion-based generative models , author=. arXiv e-prints , pages=
-
[39]
Advances in Neural Information Processing Systems , volume=
On the generalization properties of diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
arXiv preprint arXiv:2505.17638 , year=
Why Diffusion Models Don't Memorize: The Role of Implicit Dynamical Regularization in Training , author=. arXiv preprint arXiv:2505.17638 , year=
-
[41]
Journal of Machine Learning Research , year =
Victor Guilherme Turrisi da Costa and Enrico Fini and Moin Nabi and Nicu Sebe and Elisa Ricci , title =. Journal of Machine Learning Research , year =
-
[42]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[43]
Advances in Neural Information Processing Systems , volume=
On the edge of memorization in diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
arXiv preprint arXiv:2509.25705 , year=
How diffusion models memorize , author=. arXiv preprint arXiv:2509.25705 , year=
-
[45]
arXiv preprint arXiv:2511.03202 , year=
Provable separations between memorization and generalization in diffusion models , author=. arXiv preprint arXiv:2511.03202 , year=
-
[46]
arXiv preprint arXiv:2512.20963 , year=
Generalization of Diffusion Models Arises with a Balanced Representation Space , author=. arXiv preprint arXiv:2512.20963 , year=
-
[47]
arXiv preprint arXiv:2510.01378 , year=
Selective Underfitting in Diffusion Models , author=. arXiv preprint arXiv:2510.01378 , year=
-
[48]
ICLR 2026 Workshop on Geometry-grounded Representation Learning and Generative Modeling , year=
Manifold Generalization Provably Proceeds Memorization in Diffusion Models , author=. ICLR 2026 Workshop on Geometry-grounded Representation Learning and Generative Modeling , year=
2026
-
[49]
arXiv preprint arXiv:2601.19285 , year=
Smoothing the Score Function for Generalization in Diffusion Models: An Optimization-based Explanation Framework , author=. arXiv preprint arXiv:2601.19285 , year=
-
[50]
arXiv preprint arXiv:2602.17846 , year=
Two calm ends and the wild middle: A geometric picture of memorization in diffusion models , author=. arXiv preprint arXiv:2602.17846 , year=
-
[51]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
From navigation to refinement: Revealing the two-stage nature of flow-based diffusion models through oracle velocity , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[52]
2026 , eprint=
Diffusion Models Memorize in Training -- and Generalize in Inference , author=. 2026 , eprint=
2026
-
[53]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
A Novel Metric for Detecting Memorization in Generative Models for Brain MRI Synthesis , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[54]
arXiv preprint arXiv:2601.21348 , year=
Memorization Control in Diffusion Models from Denoising-centric Perspective , author=. arXiv preprint arXiv:2601.21348 , year=
-
[55]
Advances in Neural Information Processing Systems , volume=
A Closer Look at Model Collapse: From a Generalization-to-Memorization Perspective , author=. Advances in Neural Information Processing Systems , volume=
-
[56]
arXiv preprint arXiv:2603.13421 , year=
Generalization and memorization in rectified flow , author=. arXiv preprint arXiv:2603.13421 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.