ConsisFormer: Compute-Efficient Transformer for Wireless Foundation Models Based on Channel Consistency
Pith reviewed 2026-06-26 16:13 UTC · model grok-4.3
The pith
ConsisFormer uses channel consistency to cut WFM Transformer complexity by over 83% with negligible performance loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
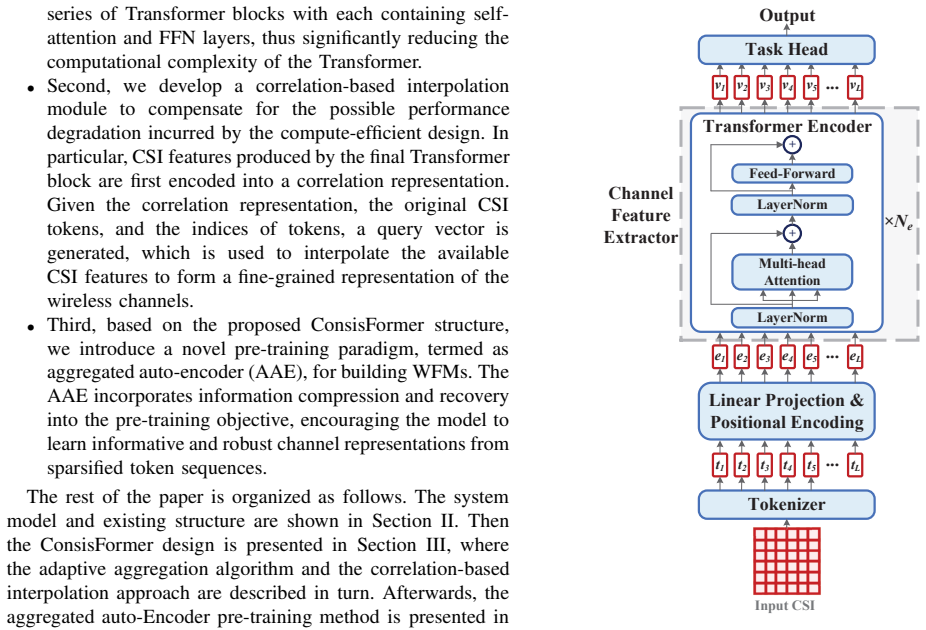
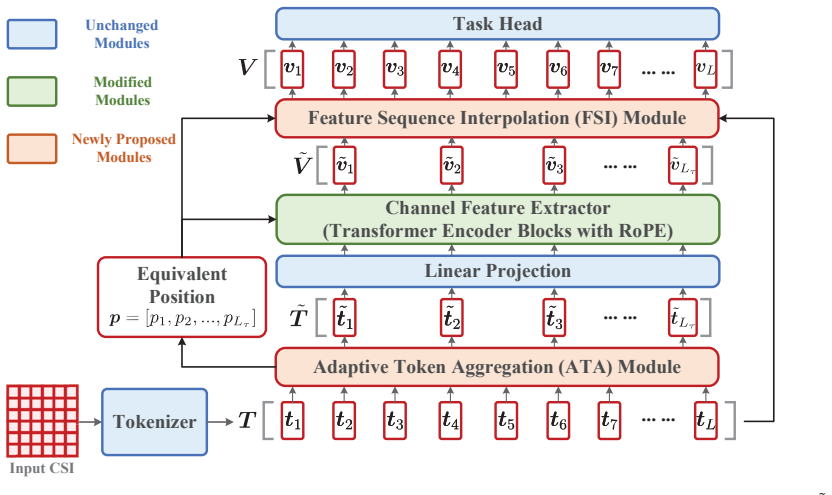
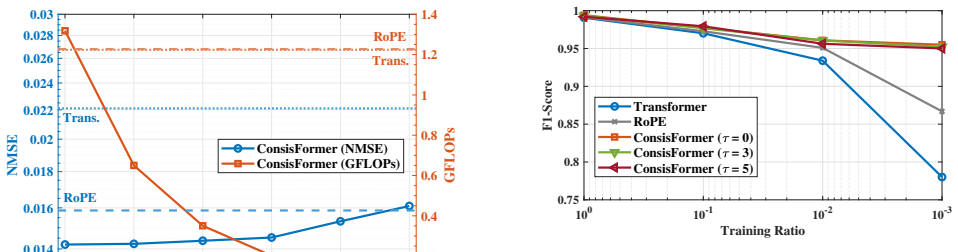
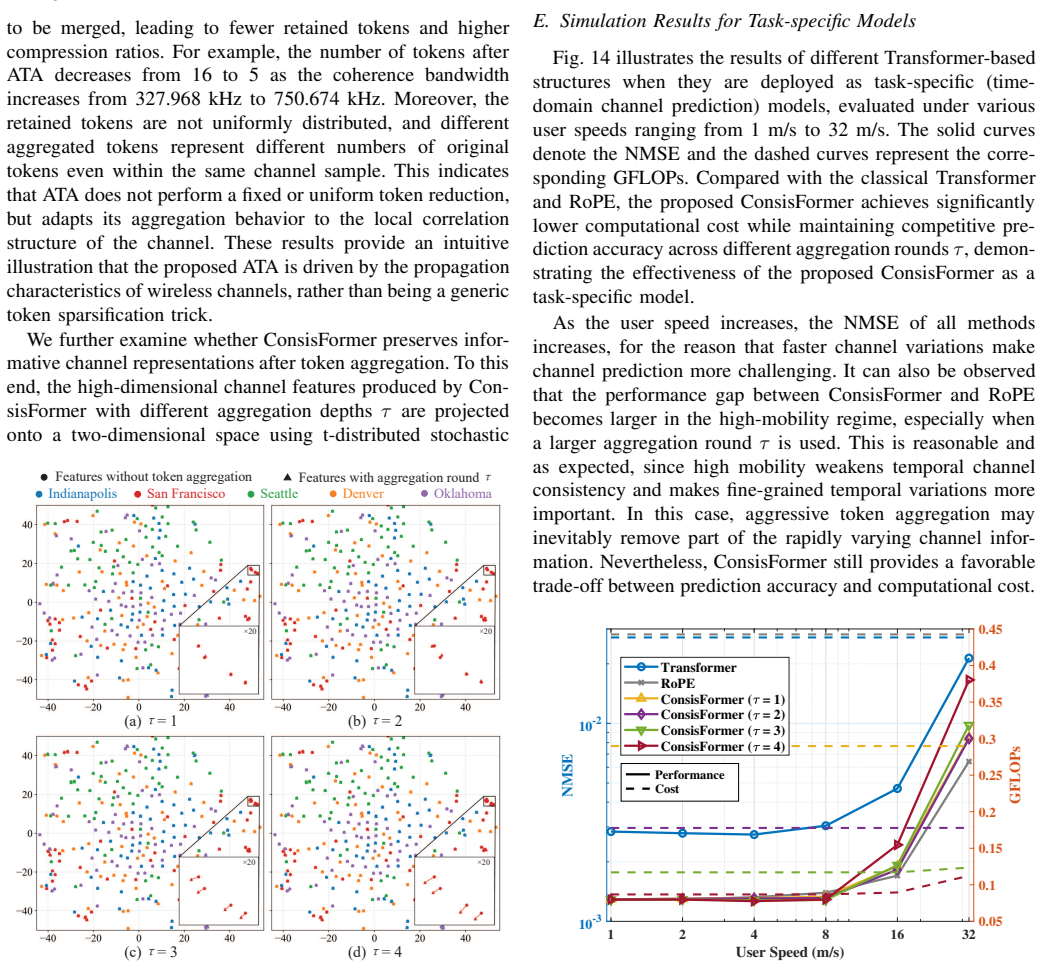
By exploiting the observation that adjacent time or frequency instances share similar clusters of scatterers, the ConsisFormer design dynamically merges neighboring CSI tokens via an adaptive token aggregation module, reducing the token sequence length for self-attention, and employs feature sequence interpolation to recover full representations, achieving over 83% reduction in computational complexity with negligible performance loss across multiple wireless tasks.
What carries the argument
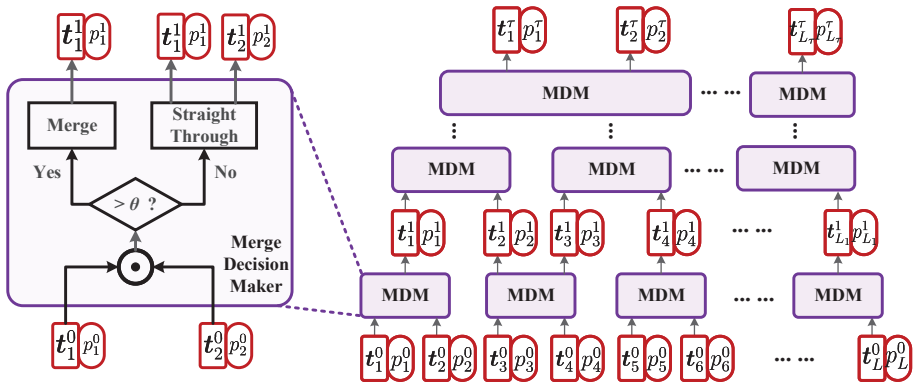
The adaptive token aggregation (ATA) module, which dynamically merges neighboring channel state information (CSI) tokens based on channel consistency.
If this is right
- Self-attention computations scale with the square of the reduced sequence length, leading to major efficiency gains.
- The design maintains performance on channel prediction, LoS/NLOS classification, beam prediction, and localization.
- The aggregated auto-encoder pre-training enables robust learning from sparsified CSI tokens.
- Overall, this supports deployment of WFMs under stringent inference latency constraints in 6G networks.
Where Pith is reading between the lines
- If channel consistency holds across more domains, similar merging could apply to other sequential data in sensing applications.
- Testing on real-world channel measurements beyond simulations would validate the consistency assumption further.
- The approach might inspire efficiency techniques in other foundation models where input sequences have natural correlations.
Load-bearing premise
Adjacent time or frequency instances share similar clusters of scatterers and thus exhibit similar channel characteristics, allowing safe dynamic merging of CSI tokens without critical information loss.
What would settle it
Observing significant performance degradation, beyond negligible loss, when applying the ATA module and FSI recovery on the tasks of channel prediction, classification, beam prediction, or localization would indicate the claim does not hold.
Figures






read the original abstract
Wireless foundation models (WFMs) have recently emerged as a promising paradigm for AI-native 6G networks, enabling universal channel representations adaptable to diverse communication and sensing tasks. Existing WFMs are predominantly built upon the Transformer architecture, which delivers superior performance but incurs computational complexity proportional to the square of the input sequence length, posing a significant barrier to their deployment under stringent inference latency constraints. To address this issue, in this paper, we propose ConsisFormer, a compute-efficient Transformer design based on short-term consistency of wireless channels, as a WFM backbone. By utilizing the observation that adjacent time or frequency instances share similar clusters of scatterers and thus exhibit similar channel characteristics, we develop an adaptive token aggregation (ATA) module to dynamically merge neighboring channel state information (CSI) tokens, thereby reducing the length of the token sequence involved in self-attention calculations to lower the computational cost. Furthermore, we propose a feature sequence interpolation (FSI) method to recover the full CSI representation based on the sparse feature sequence outputted from the Transformer blocks, thus keeping the performance unaffected while ensuring low complexity. Moreover, we propose an aggregated auto-encoder (AAE) pre-training paradigm for WFMs, enabling robust channel representation learning from sparsified CSI tokens via compression and recovery. Simulation results show that the proposed design reduces the computational complexity of WFM by over $83\%$ with negligible performance loss on various tasks including channel prediction, LoS/NLOS classification, beam prediction, and localization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce ConsisFormer, a compute-efficient Transformer for wireless foundation models that uses an adaptive token aggregation (ATA) module based on channel consistency to reduce the token sequence length for self-attention, a feature sequence interpolation (FSI) to recover full CSI, and an aggregated auto-encoder (AAE) pre-training. Simulation results are reported to show over 83% complexity reduction with negligible performance loss on channel prediction, LoS/NLOS classification, beam prediction, and localization tasks.
Significance. If the central claims hold, this work could be significant for practical deployment of WFMs in resource-constrained 6G environments by leveraging physical channel properties to achieve substantial compute savings. The grounding in wireless channel consistency rather than ad-hoc parameter fitting is a notable strength. However, the current presentation of results limits full evaluation of its broader impact.
major comments (2)
- [Abstract] The reported simulation results claim an 83% complexity reduction with negligible loss, but provide no error bars, baseline details, dataset sizes, or statistical tests, making the performance preservation claim difficult to assess rigorously.
- [Abstract] The ATA module is based on the assumption that adjacent time or frequency instances share similar clusters of scatterers; the manuscript does not report validation or boundary testing of this assumption in high-mobility regimes, which is load-bearing for the claims on channel prediction, beam prediction, and localization tasks.
minor comments (2)
- Clarify the exact metrics (e.g., MSE, accuracy) and comparison baselines used in the simulations for each task.
- Provide more details on the AAE pre-training paradigm and how it interacts with the sparsified tokens.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment point by point below, indicating revisions where the manuscript will be updated to improve rigor and clarity.
read point-by-point responses
-
Referee: [Abstract] The reported simulation results claim an 83% complexity reduction with negligible loss, but provide no error bars, baseline details, dataset sizes, or statistical tests, making the performance preservation claim difficult to assess rigorously.
Authors: We agree that the abstract would benefit from additional context on the simulation setup. The full manuscript (Section IV) already specifies the datasets (including sizes and generation parameters), baseline models, and direct performance comparisons across tasks. To strengthen the presentation, we will revise the abstract to briefly note the dataset scale and evaluation methodology, and we will ensure all result figures include error bars with explicit baseline details. No new statistical hypothesis tests are planned, as the claims rest on consistent relative performance across multiple tasks rather than p-values. revision: yes
-
Referee: [Abstract] The ATA module is based on the assumption that adjacent time or frequency instances share similar clusters of scatterers; the manuscript does not report validation or boundary testing of this assumption in high-mobility regimes, which is load-bearing for the claims on channel prediction, beam prediction, and localization tasks.
Authors: The core assumption follows from standard wireless channel modeling (adjacent coherence intervals share dominant scatterers under moderate mobility). The manuscript validates the end-to-end design through empirical results on the listed tasks rather than isolating the assumption. We acknowledge that explicit high-mobility boundary testing is absent. We will add a dedicated paragraph in the discussion section referencing channel coherence literature and noting the assumption's scope, while clarifying that the reported gains apply within the evaluated mobility regimes. revision: partial
Circularity Check
No significant circularity; core design rests on external channel physics observation
full rationale
The paper's central mechanism (ATA token merging) is justified by the stated physical observation that adjacent time/frequency CSI instances share scatterer clusters, which is an external domain fact about wireless propagation rather than a self-referential definition, fitted parameter, or self-citation chain. No equations reduce a claimed prediction to its own inputs by construction; performance claims are simulation results on downstream tasks, and the AAE pre-training is a standard compression-recovery objective applied to the sparsified sequence. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- similarity threshold or merging criteria inside ATA
axioms (1)
- domain assumption Adjacent time or frequency instances share similar clusters of scatterers and thus exhibit similar channel characteristics
Reference graph
Works this paper leans on
-
[1]
ITU-R M.2160-0, Framework and overall objectives of the future development of IMT for 2030 and beyond , ITU, Nov. 2023
2030
-
[2]
Neural repres entation for wireless radiation field reconstruction: A 3D Gaussian s platting approach,
C. Wen, J. Tong, Y . Hu, Z. Lin, and J. Zhang, “Neural repres entation for wireless radiation field reconstruction: A 3D Gaussian s platting approach,” IEEE Trans. Wireless Commun. , early access, Nov. 2025
2025
-
[3]
Fa st adversarial training for graph neural network based resour ce allocation,
H. Zhang, K. Huang, C. Y ang, L. Liang, C. Guo, and H. Y e, “Fa st adversarial training for graph neural network based resour ce allocation,” IEEE Wireless Commun. Lett. , vol. 15, pp. 126-130, Oct. 2025
2025
-
[4]
Genera- tive diffusion receivers: Achieving pilot-efficient MIMO- OFDM,
Y . Y ang, O. Alhussein, A. Arani, Z. Zhang, and M. Debbah, “ Genera- tive diffusion receivers: Achieving pilot-efficient MIMO- OFDM,” arXiv preprint arXiv:2506.18419, Jun. 2025
-
[5]
Generat ive- adversarial-network enabled signal detection for communi cation systems with unknown channel models,
L. Sun, Y . Wang, A. L. Swindlehurst, and X. Tang, “Generat ive- adversarial-network enabled signal detection for communi cation systems with unknown channel models,” IEEE J. Select. Areas Commun. , vol. 39, no. 1, pp. 47-60, Jan. 2021
2021
-
[6]
Intelligent wireless inter ference identi- fication with lightweight Transformer network,
P . Wang, Z. Wang, and Z. Han, “Intelligent wireless inter ference identi- fication with lightweight Transformer network,” IEEE Trans. Commun. , vol. 73, no. 11, pp. 11355-11367, Nov. 2025
2025
-
[7]
Transforme r- empowered predictive beamforming for rate-splitting mult iple access in non-terrestrial networks,
S. Zhang, S. Zhang, W. Y uan, and T. Q. S. Quek, “Transforme r- empowered predictive beamforming for rate-splitting mult iple access in non-terrestrial networks,” IEEE Trans. Wireless Commun. , vol. 23, no. 12, pp. 19776-19788, Dec. 2024
2024
-
[8]
Transformer-b ased power optimization for max-min fairness in cell-free massive MIM O,
I. Chafaa, G. Bacci, and L. Sanguinetti, “Transformer-b ased power optimization for max-min fairness in cell-free massive MIM O,” IEEE Wireless Commun. Lett. , vol. 14, no. 8, pp. 2316-2320, Aug. 2025
2025
-
[9]
Tran sformer network based channel prediction for CSI feedback enhancem ent in AI- native interface,
T. Zhou, X. Liu, Z. Xiang, H. Zhang, B. Ai, and L. Liu, “Tran sformer network based channel prediction for CSI feedback enhancem ent in AI- native interface,” IEEE Trans. Wireless Commun. , vol. 23, no. 9, pp. 11154-11167, Sep. 2024
2024
-
[10]
Self-attention-based real-time si gnal detector for communication systems with unknown channel models,
L. Chen and L. Sun, “Self-attention-based real-time si gnal detector for communication systems with unknown channel models,” IEEE Commun. Lett., vol. 25, no. 8, pp. 2639-2643, Aug. 2021
2021
-
[11]
LLM4CP: Ada pting large language models for channel prediction,
B. Liu, X. Liu, S. Gao, X. Cheng, and L. Y ang, “LLM4CP: Ada pting large language models for channel prediction,” J. Commun. Inf. Netw. , vol. 19, no. 2, pp.113-125, Jun. 2024
2024
-
[12]
Be am prediction based on large language models,
Y . Sheng, K. Huang, L. Liang, P . Liu, S. Jin, and Y . Li, “Be am prediction based on large language models,” arXiv preprint arXiv:2408.08707, Feb. 2025
-
[13]
Multi-modal l arge models based beam prediction: An example empowered by DeepSeek,
Y . Zhu, L. Y u, L. Shi, J. Zhang, and G. Liu, “Multi-modal l arge models based beam prediction: An example empowered by DeepSeek,” arXiv preprint arXiv:2506.0592, Jun. 2025
-
[14]
WiFo: Wirel ess foundation model for channel prediction,
B. Liu, S. Gao, X. Liu, X. Cheng, and L. Y ang, “WiFo: Wirel ess foundation model for channel prediction,” Sci. China Inf. Sci. , vol. 68, no. 6, Jun. 2025
2025
-
[15]
A generative pre-trained language model for channe l prediction in wireless communications systems,
B. Lin, H. Zhang, Y . Jiang, Y . Wang, T. Zhang, S. Y an, H. Li, Y . Liu, and F. Gao, “A generative pre-trained language model for channe l prediction in wireless communications systems,” in Proc. 2025 Conf. Empirical Methods Natural Language Process. , Suzhou, China, Nov. 2025, pp. 13417-13430
2025
-
[16]
Large wirele ss model (LWM): A foundation model for wireless channels,
S. Alikhani, G. Charan, and A. Alkhateeb, “Large wirele ss model (LWM): A foundation model for wireless channels,” arXiv preprint arXiv:2411.08872, Apr. 2025
-
[17]
WirelessGPT: A generative pre-trained multi-task learni ng framework for wireless communication,
T. Y ang, P . Zhang, M. Zheng, Y . Shi, L. Jing, J. Huang, and N. Li, “WirelessGPT: A generative pre-trained multi-task learni ng framework for wireless communication,” IEEE Net. , vol. 39, no. 5, pp. 58-65, Sep. 2025
2025
-
[18]
Sig- nal compression for wireless communication and sensing: A g eneral approach utilizing pretrained wireless foundation models
L. Jing, T. Y ang, H. Zhang, Y . Shi, C. Zhang, and B. Zhang, “Sig- nal compression for wireless communication and sensing: A g eneral approach utilizing pretrained wireless foundation models ” IEEE Trans. Mob. Comput., early access, Mar. 2026
2026
-
[19]
A wireless foundation model for multi-task prediction,
Y . Sheng, J. Wang, X. Zhou, L. Liang, H. Y e, S. Jin, and Y . L i, “A wireless foundation model for multi-task prediction,” arXiv preprint arXiv:2507.05938, Jul. 2025
-
[20]
A MIMO wireless ch annel foundation model via CIR-CSI consistency,
J. Jiang, W. Y u, Y . Li, Y . Gao and S. Xu, “A MIMO wireless ch annel foundation model via CIR-CSI consistency,” in Proc. IEEE Int. Conf. Mach. Learn. Commun. Netw. (ICMLCN) , Barcelona, Spain, May, 2025, pp. 1-6
2025
-
[21]
MUSE-FM: Multi-task environment-aware foundation model for wireless communications,
T. Zheng, J. Guo, L. Dai, S. Jin, and J. Zhang, “MUSE-FM: M ulti-task environment-aware foundation model for wireless communic ations,” arXiv preprint arXiv:2509.01967 , Sep. 2025
-
[22]
Attention is all you need,
A. V aswani et al., “Attention is all you need,” in Proc. Int. Conf. Neural Inf. Process. Syst. (NIPS) , Long Beach, CA, USA, Dec. 2017, vol. 30, pp. 5998–6008
2017
-
[23]
ClST: A convol utional transformer framework for automatic modulation recogniti on by knowl- edge distillation,
D. Hou, L. Li, W. Lin, J. Liang, and Z. Han, “ClST: A convol utional transformer framework for automatic modulation recogniti on by knowl- edge distillation,” IEEE Trans. Wireless Commun. , vol. 23, no. 7, pp. 8013–8028, Jul. 2024
2024
-
[24]
Tiny-WiFo: A lightweigh t wireless foundation model for channel prediction via multi-compone nt adaptive knowledge distillation,
H. Zhang, S. Gao, and X. Cheng, “Tiny-WiFo: A lightweigh t wireless foundation model for channel prediction via multi-compone nt adaptive knowledge distillation,” IEEE Wireless Commun. Lett., vol. 15, pp. 1846- 1850, Feb. 2026
2026
-
[25]
Pruned and quantize d hybrid models for edge-based automatic modulation recognition,
Y . Byeon, D. Kim, Y . Cao, and W. Lim, “Pruned and quantize d hybrid models for edge-based automatic modulation recognition,” IEEE Internet Things J. , early access, Apr. 2026
2026
-
[26]
Token merging: Y our ViT but faster,
Y . Bolya, C. Fu, X. Dai, P . Zhang, C. Feichtenhofer, and J . Hoffman, “Token merging: Y our ViT but faster,” in Proc. Int. Conf. Learn. Represent. (ICLR) , Kigali, Rwanda, 2023
2023
-
[27]
Learning to merge tokens in vision transformers ,
C. Renggli, A. Pinto, N. Houlsby, B. Mustafa, J. Puigcer ver, and C. Riquelme, “Learning to merge tokens in vision transformers ,” arXiv preprint arXiv:2202.12015, Feb. 2022
-
[28]
M2M-TAG: Training-free many-to-man y token aggregation for vision transformer acceleration,
F. Zeng and D. Y u, “M2M-TAG: Training-free many-to-man y token aggregation for vision transformer acceleration,” in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS) , V ancouver, BC, Canada, 2024
2024
-
[29]
Focus on the core: Efficient at tention via pruned token compression for document classification,
J. Y un, M. Kim, and Y . Kim, “Focus on the core: Efficient at tention via pruned token compression for document classification,” in Findings of the Assoc. Comput. Linguist. (EMNLP) , Singapore, 2023, pp. 13617- 13628
2023
-
[30]
Deep CNN-based channel estimation for mmWave massive MIMO syste ms,
P . Dong, H. Zhang, G. Y . Li, I. S. Gaspar, and N. NaderiAli zadeh, “Deep CNN-based channel estimation for mmWave massive MIMO syste ms,” IEEE J. of Sel. Topics in Signal Process. , vol. 13, no. 5, pp. 989-1000, Sep. 2019
2019
-
[31]
Characterization of randomly time-variant linear channels,
P . Bello, “Characterization of randomly time-variant linear channels,” IEEE Trans. Commun. , vol. 11, no. 4, pp. 360-393, Dec. 1963
1963
-
[32]
RoFormer: Enhanced Transformer with Rotary Position Embedding
J. Su, Y . Lu, S. Pan, A. Murtadha, B. Wen, and Y . Liu, “RoFo rmer: Enhanced transformer with rotary position embedding,” arXiv preprint arXiv:2104.09864, Apr. 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[33]
Self-Attention with Relative Position Representations
P . Shaw, J. Uszkoreit, A. V aswani, “Self-Attention wit h relative position representations,” arXiv preprint arXiv:1803.02155 , Mar. 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[34]
Masked autoencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P . Doll´ ar, and R. Girshick, “Masked autoencoders are scalable vision learners,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR) , New Orleans, LA, USA, 2022
2022
-
[35]
DeeepMIMO: A generic deep learning data set for millimeter wave and massive MIMO applications,
A. Alkhateeb, “DeeepMIMO: A generic deep learning data set for millimeter wave and massive MIMO applications,” in Proc. IEEE Inf. Theory Appl. W orkshop (ITA), San Diego, CA, USA, Feb. 2019, pp. 1-8
2019
-
[36]
Visualizing high-dimensiona l data using t- SNE,
L. Maaten and G. Hinton, “Visualizing high-dimensiona l data using t- SNE,” J. Mach. Learn. Res. , vol. 9, no. 86, pp. 2579–2605, Nov. 2008
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.