PRISM: Gauge-Invariant Tangent-Space Differentially Private LoRA
Pith reviewed 2026-06-28 18:02 UTC · model grok-4.3
The pith
PRISM performs differential privacy on LoRA in tangent space so that noise on the update matrix stays bounded and independent of factorization choice.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
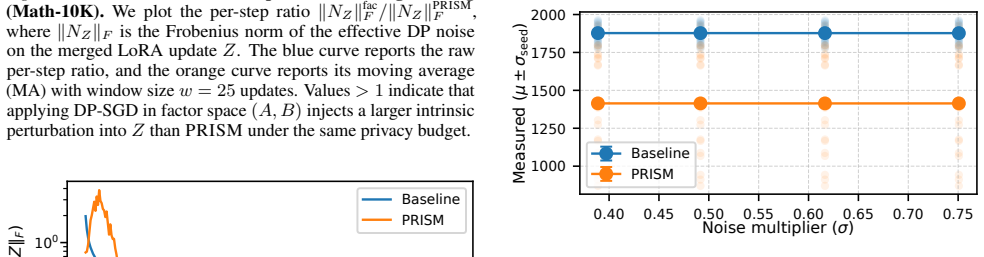
PRISM is an intrinsic DP mechanism for LoRA that is gauge invariant by construction, avoids bilinear noise amplification, and admits an efficient low-dimensional noise sampler. Moreover, PRISM yields a closed-form characterization of the effective intrinsic noise induced on Z, enabling stable privacy-utility trade-offs through bounded, gauge-invariant perturbations. We establish standard (ε,δ)-DP guarantees for PRISM and introduce a DP-aware, gauge-invariant adaptive update rule that prevents adaptive optimization from amplifying injected privacy noise, improving numerical stability in practice.
What carries the argument
Tangent-space DP mechanism that projects noise onto the space of updates Z rather than the non-unique factors A and B.
If this is right
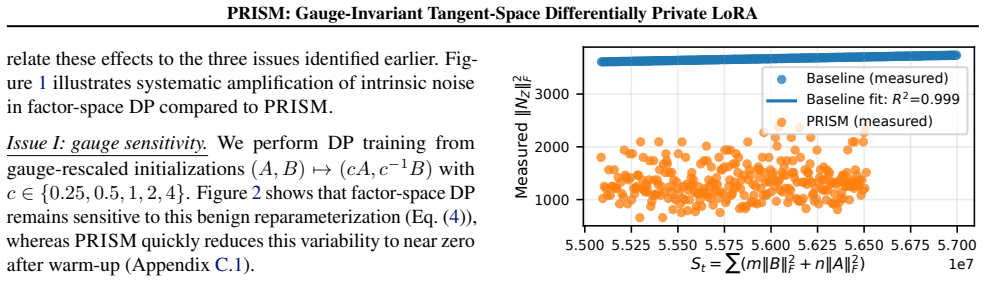
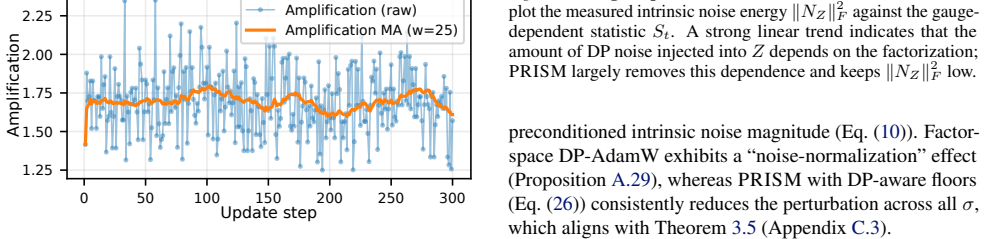
- Naive application of DP-SGD to LoRA factors induces gauge-dependent perturbations that can amplify without bound on the update Z.
- PRISM produces bounded, gauge-invariant perturbations on Z through its tangent-space construction.
- The method supplies an efficient low-dimensional noise sampler and a closed-form expression for the induced noise on Z.
- Standard (ε,δ)-DP guarantees hold, and the DP-aware adaptive rule prevents optimization from amplifying the privacy noise.
Where Pith is reading between the lines
- The same tangent-space idea could be applied to other non-identifiable low-rank or factorized parameterizations used in training.
- The closed-form noise characterization on Z might support tighter privacy accounting when multiple training steps are composed.
- If the gauge invariance holds under the stated conditions, the approach may extend to other first-order private optimizers beyond the one used here.
Load-bearing premise
The non-identifiability of the factorization Z equals A B transpose is the dominant source of unbounded noise amplification in naive DP-LoRA, and a tangent-space construction can be realized that remains gauge-invariant while preserving the DP guarantee and practical efficiency.
What would settle it
An experiment that fixes Z and varies the factorization (A,B) while applying naive DP-SGD, then measures whether the effective perturbation on Z grows without bound.
Figures



read the original abstract
Applying differential privacy (DP) via DP-SGD to Low-Rank Adaptation (LoRA) is a natural approach for privacy-preserving fine-tuning. However, LoRA's low-rank parameterization poses a fundamental challenge. In LoRA, each trainable update is represented as a low-rank matrix $Z = AB^\top$, but this factorization is inherently non-identifiable: many factor pairs $(A,B)$ represent the same update $Z$. As a result, applying DP-SGD directly to the factors induces gauge-dependent perturbations on $Z$, and we show that this naive DP-LoRA can lead to unbounded noise amplification. We propose PRISM, an intrinsic DP mechanism for LoRA that is gauge invariant by construction, avoids bilinear noise amplification, and admits an efficient low-dimensional noise sampler. Moreover, PRISM yields a closed-form characterization of the effective intrinsic noise induced on $Z$, enabling stable privacy-utility trade-offs through bounded, gauge-invariant perturbations. We establish standard $(\epsilon,\delta)$-DP guarantees for PRISM and introduce a DP-aware, gauge-invariant adaptive update rule that prevents adaptive optimization from amplifying injected privacy noise, improving numerical stability in practice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies a fundamental issue with applying DP-SGD to LoRA due to the non-identifiability of the low-rank factorization Z = AB^T, which leads to gauge-dependent noise and unbounded amplification in naive approaches. It proposes PRISM, an intrinsic DP mechanism operating in the tangent space that is gauge-invariant by construction, avoids bilinear noise amplification, admits an efficient low-dimensional noise sampler, provides a closed-form characterization of the effective noise on Z, establishes standard (ε,δ)-DP guarantees, and includes a DP-aware gauge-invariant adaptive update rule.
Significance. If the proposed method delivers on its claims of gauge-invariance and bounded noise with provable DP, it would represent a meaningful advance in privacy-preserving parameter-efficient fine-tuning of large language models, potentially enabling more reliable privacy-utility trade-offs in LoRA-based adaptations where standard DP approaches suffer from instability.
major comments (3)
- [Abstract] Abstract: The assertion that naive DP-LoRA leads to unbounded noise amplification due to non-identifiability is stated without any derivation, example, or quantitative illustration in the provided text, making it difficult to assess the severity of the problem being addressed.
- [Abstract] Abstract: Claims regarding the closed-form characterization of intrinsic noise on Z, the efficient low-dimensional noise sampler, and the establishment of standard (ε,δ)-DP guarantees are made but no supporting equations, proofs, or algorithmic descriptions are supplied in the manuscript text.
- [Abstract] Abstract: The introduction of a DP-aware, gauge-invariant adaptive update rule is described as preventing noise amplification and improving stability, but no details on the rule or empirical evidence of its effectiveness are provided.
minor comments (1)
- [Abstract] The abstract is dense with technical claims; expanding it or adding a figure illustrating the gauge issue could improve accessibility.
Simulated Author's Rebuttal
We thank the referee for their detailed comments on the abstract. We address each point below, noting that the abstract is a high-level summary while the full derivations, algorithms, and results appear in the main body of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that naive DP-LoRA leads to unbounded noise amplification due to non-identifiability is stated without any derivation, example, or quantitative illustration in the provided text, making it difficult to assess the severity of the problem being addressed.
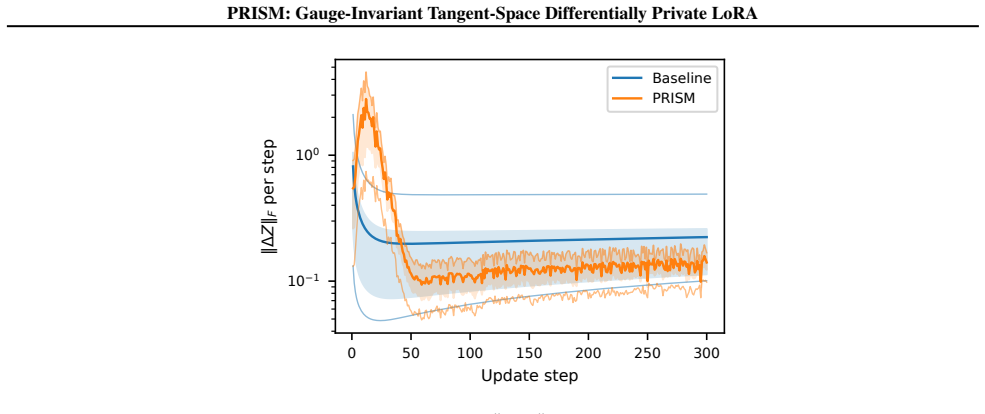
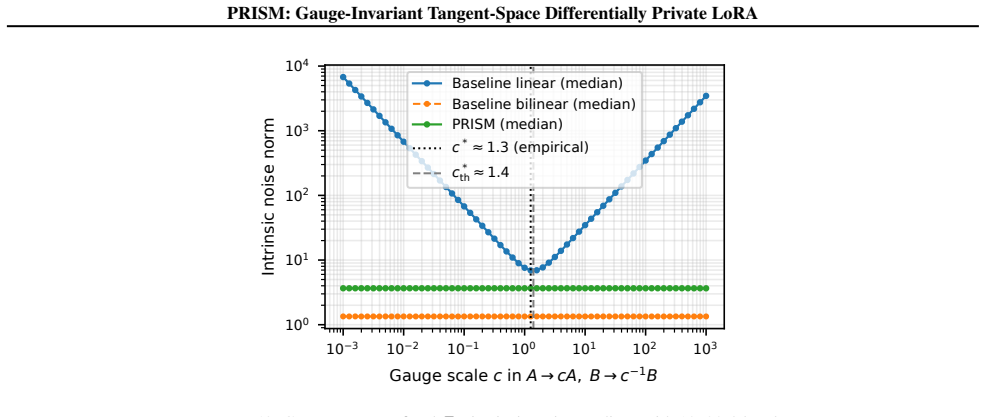
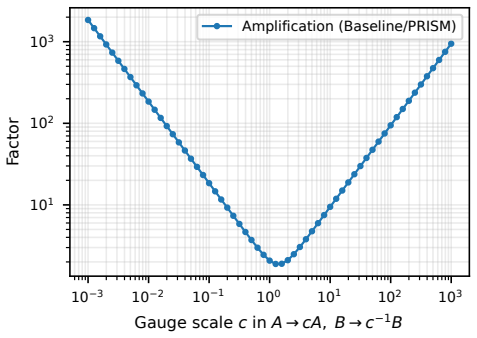
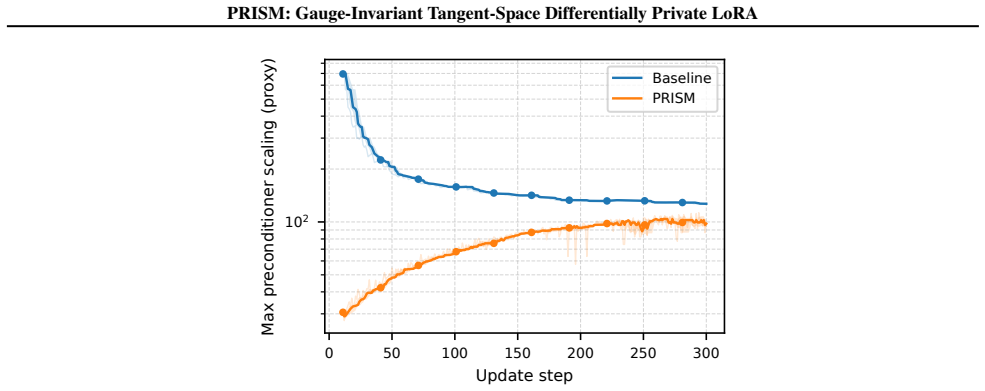
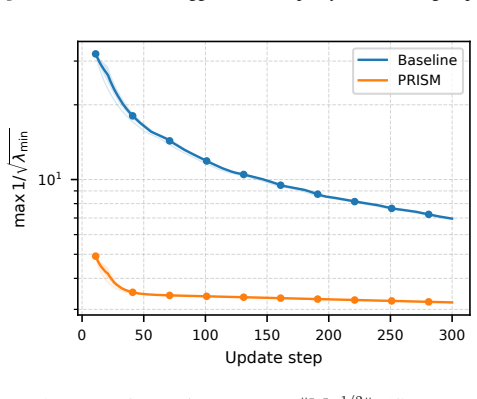
Authors: We agree the abstract states the claim concisely without a derivation. The non-identifiability of Z = AB^T and the resulting gauge-dependent noise leading to unbounded amplification are formally derived in Section 2, with a concrete low-dimensional example and quantitative illustration provided in Figure 1 and the surrounding text. To improve accessibility, we will revise the abstract to include a one-sentence reference to this analysis. revision: yes
-
Referee: [Abstract] Abstract: Claims regarding the closed-form characterization of intrinsic noise on Z, the efficient low-dimensional noise sampler, and the establishment of standard (ε,δ)-DP guarantees are made but no supporting equations, proofs, or algorithmic descriptions are supplied in the manuscript text.
Authors: The abstract summarizes these contributions at a high level. The closed-form noise characterization on Z appears in Theorem 3.2, the low-dimensional sampler is given as Algorithm 1 in Section 3, and the (ε,δ)-DP guarantees are established in Theorem 4.1 with the full proof in Appendix B. These elements are present in the main manuscript. We will add brief parenthetical references to the key theorem numbers in a revised abstract. revision: yes
-
Referee: [Abstract] Abstract: The introduction of a DP-aware, gauge-invariant adaptive update rule is described as preventing noise amplification and improving stability, but no details on the rule or empirical evidence of its effectiveness are provided.
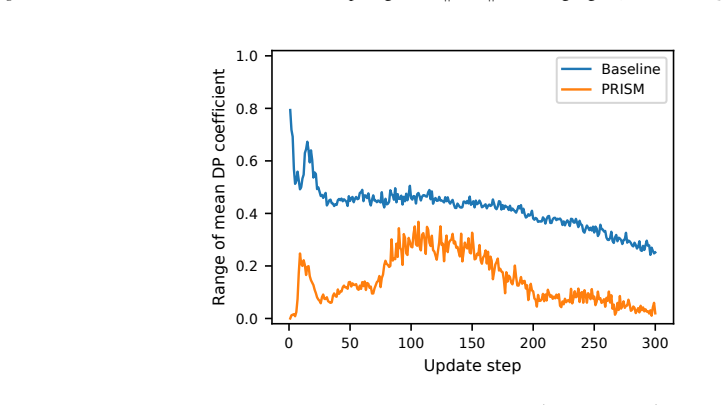
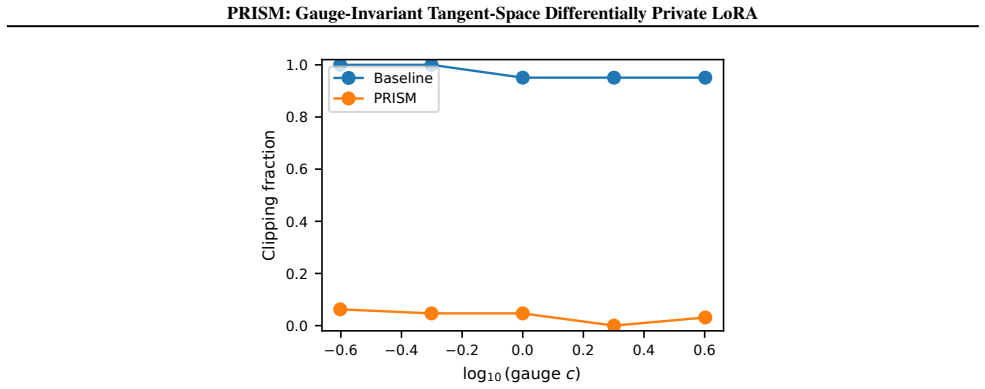
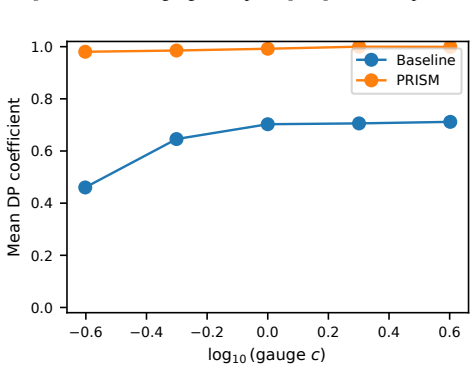
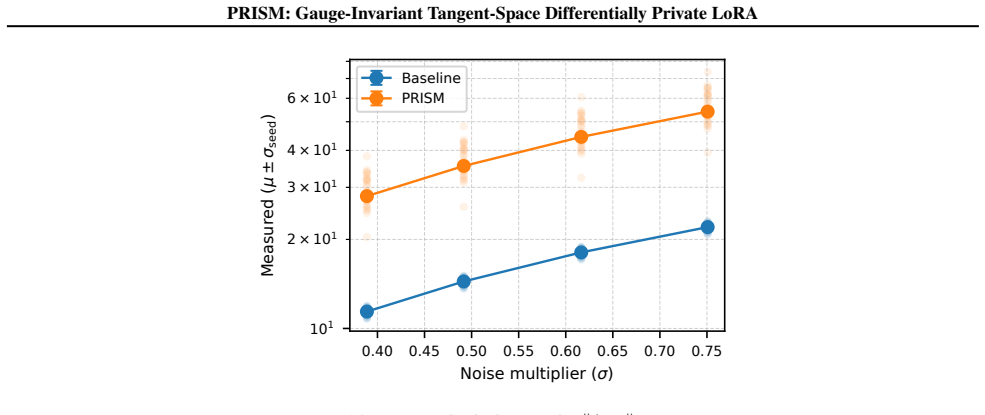
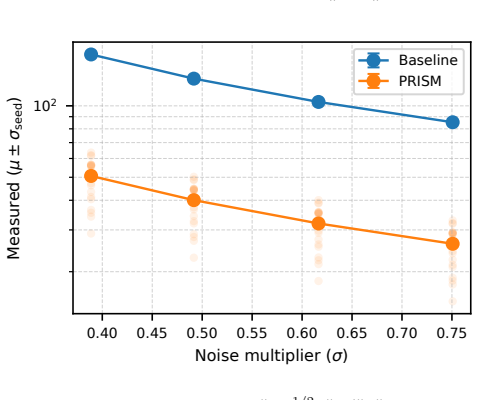
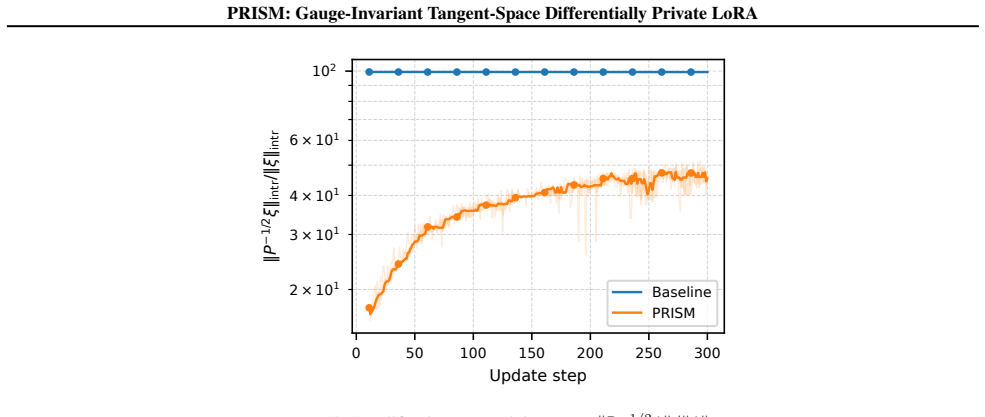
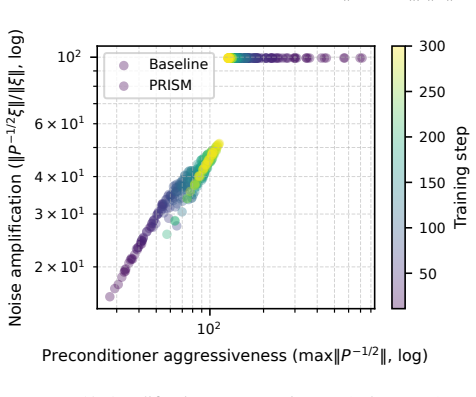
Authors: Details of the DP-aware gauge-invariant adaptive update rule, including its formulation that prevents noise amplification, are provided in Section 5. Empirical evidence demonstrating improved numerical stability appears in Section 6 (Figures 4 and 5) with ablation studies. We will revise the abstract to include a short clause summarizing the rule's mechanism. revision: yes
Circularity Check
No significant circularity
full rationale
The abstract and provided context contain no equations, derivations, or self-citations that reduce any claimed result to its own inputs by construction. The motivation around non-identifiability of Z=AB^T and the proposal of a tangent-space mechanism are stated as new constructions without load-bearing reductions to fitted parameters, prior self-citations, or renamed known results. The work builds directly on standard DP-SGD and LoRA without evident circular steps in the given text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The approximation of one matrix by another of lower rank
doi: 10.1007/BF02288367. URL https://doi. org/10.1007/BF02288367. Edelman, A., Arias, T. A., and Smith, S. T. The geometry of algorithms with orthogonality constraints.SIAM Jour- nal on Matrix Analysis and Applications, 20(2):303–353,
-
[2]
SIAM Journal on Matrix Analysis and Applications , author =
doi: 10.1137/S0895479895290954. URL https: //doi.org/10.1137/S0895479895290954. Fredrikson, M., Jha, S., and Ristenpart, T. Model in- version attacks that exploit confidence information and basic countermeasures. InProceedings of the 22nd ACM SIGSAC Conference on Computer and Commu- nications Security, CCS ’15, pp. 1322–1333. Associa- tion for Computing M...
-
[3]
cc/paper_files/paper/2021/file/ 6097d8f3714205740f30debe1166744e-Paper
URL https://proceedings.neurips. cc/paper_files/paper/2021/file/ 6097d8f3714205740f30debe1166744e-Paper. pdf. Hayou, S., Ghosh, N., and Yu, B. LoRA+: Effi- cient low rank adaptation of large models. InPro- ceedings of the 41st International Conference on Ma- chine Learning, volume 235 ofProceedings of Ma- chine Learning Research, pp. 17783–17806. PMLR,
2021
-
[4]
URL https://proceedings.mlr.press/ v235/hayou24a.html. Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., De Laroussilhe, Q., Gesmundo, A., Attariyan, M., and Gelly, S. Parameter-efficient transfer learning for NLP. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Ma- chine Learning Research, pp. 2790...
-
[5]
Adam: A Method for Stochastic Optimization
URL https://aclanthology.org/2023. emnlp-main.319/. Kingma, D. P. and Ba, J. Adam: A method for stochastic optimization. InInternational Conference on Learning Representations (ICLR), 2015. URL https://arxiv. org/abs/1412.6980. Koncel-Kedziorski, R., Roy, S., Amini, A., Kushman, N., and Hajishirzi, H. MAWPS: A math word problem repos- itory. In Knight, K....
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/n16-1136 2023
-
[6]
URL https://openreview.net/forum? id=j1zQGmQQOX1. Li, X. L. and Liang, P. Prefix-Tuning: Optimizing con- tinuous prompts for generation. InProceedings of the 59th Annual Meeting of the Association for Computa- tional Linguistics and the 11th International Joint Con- ference on Natural Language Processing (Volume 1: Long Papers), pp. 4582–4597. Association...
-
[7]
acl-long.353/
URL https://aclanthology.org/2021. acl-long.353/. Li, Y ., Yu, Y ., Liang, C., Karampatziakis, N., He, P., Chen, W., and Zhao, T. LoftQ: LoRA-fine-tuning-aware quantization for large language models. InThe Twelfth International Conference on Learning Representations,
2021
-
[8]
URL https://openreview.net/forum? id=LzPWWPAdY4. Ling, W., Yogatama, D., Dyer, C., and Blunsom, P. Pro- gram induction by rationale generation: Learning to solve and explain algebraic word problems. InPro- ceedings of the 55th Annual Meeting of the Associa- tion for Computational Linguistics (Volume 1: Long Papers), pp. 158–167. Association for Computatio...
-
[9]
URL https: //doi.org/10.1007/s00180-013-0464-z
doi: 10.1007/s00180-013-0464-z. URL https: //doi.org/10.1007/s00180-013-0464-z. Opacus Contributors. Opacus PrivacyEngine API ref- erence. https://opacus.ai/api/privacy_ engine.html, 2026. Patel, A., Bhattamishra, S., and Goyal, N. Are NLP models really able to solve simple math word prob- lems? InProceedings of the 2021 Conference of the North American C...
-
[10]
URL https://aclanthology.org/2021. naacl-main.168/. Shokri, R., Stronati, M., Song, C., and Shmatikov, V . Mem- bership inference attacks against machine learning mod- els. In2017 IEEE Symposium on Security and Privacy (SP), pp. 3–18. IEEE Computer Society, 2017. doi: 10.1109/SP.2017.41. URL https://doi.org/10. 1109/SP.2017.41. Sun, Y ., Li, Z., Li, Y ., ...
-
[11]
Tang, Q., Shpilevskiy, F., and L ´ecuyer, M
URL https://openreview.net/forum? id=NLPzL6HWNl. Tang, Q., Shpilevskiy, F., and L ´ecuyer, M. DP- AdamBC: Your DP-Adam is actually DP-SGD (un- less you apply bias correction).Proceedings of the AAAI Conference on Artificial Intelligence, 38 (14):15276–15283, 2024. doi: 10.1609/aaai.v38i14. 29451. URL https://ojs.aaai.org/index. php/AAAI/article/view/29451...
-
[12]
IEEE, 2025. doi: 10.1109/ICDM65498.2025.00089. URL https://doi.org/10.1109/ICDM65498. 2025.00089. Yen, J.-N., Si, S., Meng, Z., Yu, F., Duvvuri, S. S., Dhillon, I. S., Hsieh, C.-J., and Kumar, S. LoRA Done RITE: Robust invariant transformation equilibration for LoRA optimization. InThe Thirteenth International Conference on Learning Representations, 2025....
-
[13]
mechanism check
and is evaluated on the standard test splits of its component datasets. Common fine-tuning hyperparameters.Unless otherwise stated, all methods share the same backbone, LoRA configuration, and DP settings in Table 7. For DP runs, the noise multiplier is calibrated with Opacus make private with epsilonusing the default PRV accountant (Gopi et al., 2021; Op...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.