MorphStrata: Layer-Specific Perturbations for Generating Morphence Students in Time-Series Moving Target Defense
Pith reviewed 2026-06-27 01:50 UTC · model grok-4.3
The pith
MorphStrata generates heterogeneous student models via layer-specific stochastic perturbations on a Transformer teacher to strengthen moving target defense against gradient-based attacks in time-series forecasting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MorphStrata maintains adversarial robustness as an MTD defense at marginal cost deltas when compared to existing baselines by using selective, layer-specific stochastic noise injection on randomly chosen architectural blocks of the Transformer teacher to create structured heterogeneity across student models.
What carries the argument
MorphStrata student generation strategy: selective, layer-specific stochastic noise injection on randomly selected Transformer blocks to induce structured heterogeneity.
If this is right
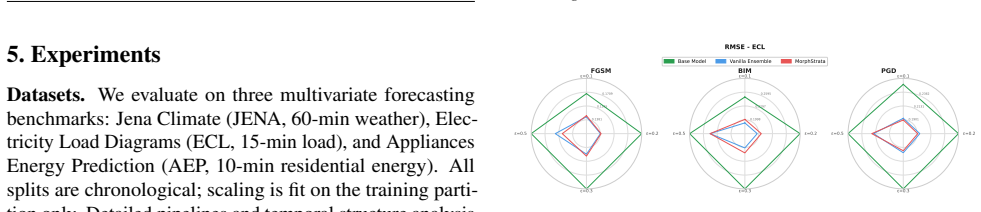
- The generated ensemble maintains comparable or lower adversarial RMSE than vanilla Transformer and Morphence baselines across the tested datasets and attack regimes.
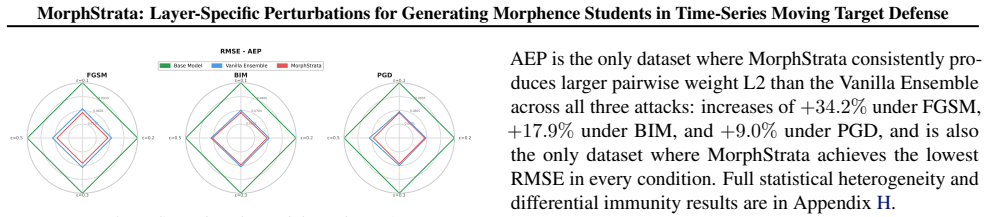
- On high-entropy periodic data such as AEP, MorphStrata records the lowest RMSE for every attack and budget examined, with double-digit percentage reductions versus the static baseline.
- Layer-targeted perturbation adds less than 1 percent to training time over the Morphence baseline in most experiments.
- Higher pairwise L2 distance among the generated students correlates with stronger overall defense effectiveness.
Where Pith is reading between the lines
- The same selective perturbation pattern could be adapted to other sequence models such as LSTMs without requiring full retraining of each student.
- Pairwise L2 distance among students might serve as an inexpensive online metric to decide when to refresh the MorphStrata ensemble during deployment.
- Because the overhead remains low, the method opens the possibility of scaling MTD to larger numbers of students on resource-constrained forecasting pipelines.
Load-bearing premise
Selective layer-specific stochastic perturbations on randomly chosen architectural blocks will reliably produce enough structured heterogeneity to drive defense gains across data distributions and threat models without dataset-specific tuning.
What would settle it
Running the same layer-targeted perturbation procedure on new time-series datasets or against additional attack variants and finding that RMSE improvements over Morphence vanish while pairwise L2 distances remain comparable would falsify the central claim.
Figures




read the original abstract
Time-series forecasting models remain vulnerable to gradient-based adversarial attacks while existing defense mechanisms typically incur a trade-off in robustness for bounded response and compute cost. The problem is pronounced in Moving Target Defense where maintaining multiple randomized model instances substantially exacerbates the training overhead. In this work, we introduce MorphStrata, a student generation strategy with selective, layer-specific stochastic noise injection that extends the traditional Morphence defense. MorphStrata uses a Transformer backbone as the teacher and perturbs randomly selected architectural blocks to create structured heterogeneity across student models in response to varied data distributions and threat models. We evaluate against vanilla Transformer and Morphence backbones on a suite of benchmarks including the Jena Climate, Electricity Load Diagrams, and Appliances Energy Prediction using FGSM, BIM and PGD attacks across multiple attack strengths. Across datasets and attack regimes, the proposed ensemble maintains comparable adversarial RMSE. Specifically, for high entropy, periodic datasets as in the case of the AEP data, MorphStrata achieves the lowest RMSE across all attacks and perturbation budgets, improving over the static baseline by up to 24.11% and 97.97% under FGSM and BIM respectively at an epsilon value of 0.5 over 30 randomized trials. Targeting the layers to generate MorphStrata students accounts for less than 1% increase in train-times over the Morphence MTD baseline for most of the experiments, while accounting for double digit gains in adversarial RMSE reduction. We also observe a positive correlation between higher pairwise L2 distance (among generated students) and overall defense effectiveness. In summary, MorphStrata maintains adversarial robustness as an MTD defense at marginal cost deltas when compared to existing baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MorphStrata, an extension to Morphence for moving target defense in time-series forecasting. It applies selective layer-specific stochastic perturbations to randomly chosen architectural blocks of a Transformer teacher to generate heterogeneous student models. Evaluations on Jena Climate, Electricity Load Diagrams, and Appliances Energy Prediction datasets against FGSM, BIM, and PGD attacks report that MorphStrata achieves the lowest RMSE across regimes, with up to 24.11% and 97.97% improvement over the static baseline on AEP data at epsilon=0.5 over 30 trials, less than 1% added training time versus Morphence, and a positive correlation between pairwise student L2 distance and defense effectiveness.
Significance. If the results hold, MorphStrata supplies a practical, low-overhead mechanism for increasing MTD robustness in time-series models by inducing measurable structured heterogeneity. The work is strengthened by its use of multiple datasets, three attack types, bounded overhead claims, and an observational correlation that could serve as a design metric; these elements make the contribution concrete and potentially actionable for adversarial forecasting settings.
minor comments (3)
- [Abstract, §4] Abstract and §4: the reported percentage improvements (24.11%, 97.97%) should explicitly state whether they represent maximum, mean, or median values across the 30 trials and whether any statistical test (e.g., paired t-test) was applied.
- [§3] §3: the procedure for randomly selecting architectural blocks and the exact noise distribution (variance, per-layer probability) are described at a high level; adding pseudocode or a precise algorithmic listing would improve reproducibility.
- [Figures] Figure 3 or equivalent (L2-distance vs. RMSE plot): axis scales, trial count per point, and whether the correlation coefficient is Pearson or Spearman should be stated directly in the caption.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of MorphStrata, the detailed summary of its contributions, and the recommendation for minor revision. No major comments were raised in the report.
Circularity Check
No significant circularity detected
full rationale
The manuscript presents MorphStrata as an empirical extension of Morphence via layer-specific stochastic perturbations on a Transformer teacher. All load-bearing claims consist of reported RMSE values from concrete randomized trials on fixed datasets (Jena, Electricity, AEP) under FGSM/BIM/PGD, plus an observational correlation between pairwise L2 distance and defense effectiveness. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear; the central argument is therefore self-contained experimental comparison rather than any reduction to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi: 10.1145/3485832. 3485899. URL https://dl.acm.org/doi/10. 1145/3485832.3485899. arXiv:2108.13952. Awad, Z., Amich, A., and Eshete, B. Morphence 2.0: Eva- sion resilient moving target defense powered by out-of- distribution detection.arXiv preprint arXiv:2206.07321,
-
[2]
Cheng, H., Wen, Q., Liu, Y ., Sun, L., Che, J., and Wang, Z. Robusttsf: Towards theory and design of robust time series forecasting under anomalies.arXiv preprint arXiv:2402.02032,
-
[3]
URL https://arxiv.org/ abs/1902.02918. Gal, Y . and Ghahramani, Z. Dropout as a bayesian approx- imation: Representing model uncertainty in deep learn- ing. InInternational Conference on Machine Learning (ICML), pp. 1050–1059,
Pith/arXiv arXiv 1902
-
[4]
URL https://arxiv. org/abs/1506.02142. Goodfellow, I. J., Shlens, J., and Szegedy, C. Explaining and harnessing adversarial examples. InInternational Conference on Learning Representations (ICLR),
-
[5]
Govindarajulu, Y ., Amballa, A., Kulkarni, P., and Par- mar, M
URLhttps://arxiv.org/abs/1412.6572. Govindarajulu, Y ., Amballa, A., Kulkarni, P., and Par- mar, M. Targeted attacks on timeseries forecasting. arXiv preprint arXiv:2301.11544,
-
[6]
Krishan, P., Mohapatra, R., Das, S., and Sengupta, S
URL https: //arxiv.org/abs/2301.11544. Krishan, P., Mohapatra, R., Das, S., and Sengupta, S. Adversarial attacks and defenses in multivariate time- series forecasting for smart and connected infrastruc- tures. InProceedings of the Annual Conference of the Prognostics and Health Management Society, volume
-
[7]
doi: 10.36001/phmconf.2024.v16i1
-
[8]
Lakshminarayanan, B., Pritzel, A., and Blundell, C
URL https: //arxiv.org/abs/1611.01236. Lakshminarayanan, B., Pritzel, A., and Blundell, C. Sim- ple and scalable predictive uncertainty estimation using deep ensembles. InAdvances in Neural Information Pro- cessing Systems (NeurIPS), pp. 6405–6416,
-
[9]
URL https://arxiv.org/abs/1612.01474. Liu, L., Park, Y ., Hoang, T. N., Hasson, H., and Huan, J. Towards robust multivariate time-series forecasting: Adversarial attacks and defense mechanisms. InPro- ceedings of the 8th SIGKDD Workshop on Mining and Learning from Time Series (MileTS), pp. 1–9,
-
[10]
Madry, A., Makelov, A., Schmidt, L., Tsipras, D., and Vladu, A
URL https://arxiv.org/abs/2207.09572. Madry, A., Makelov, A., Schmidt, L., Tsipras, D., and Vladu, A. Towards deep learning models resistant to adversarial attacks. InInternational Conference on Learning Representations (ICLR),
-
[11]
URL https: //arxiv.org/abs/1706.06083. Meng, D. and Chen, H. Magnet: A two-pronged defense against adversarial examples. InProceedings of the 2017 ACM SIGSAC Conference on Computer and Com- munications Security (CCS), pp. 135–147,
Pith/arXiv arXiv 2017
-
[12]
doi: 10.1145/3133956.3134057. URL https://dl.acm. org/doi/10.1145/3133956.3134057. Nie, Y ., Nguyen, N. H., Sinthong, P., and Kalagnanam, J. A time series is worth 64 words: Long-term forecasting with transformers.arXiv preprint arXiv:2211.14730,
-
[13]
doi: 10.1007/978-3-030-32430-8
-
[15]
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A
URL https: //arxiv.org/abs/2008.13261. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., and Polosukhin, I. Atten- tion is all you need. InAdvances in Neural Information Processing Systems (NeurIPS), volume 30,
arXiv 2008
-
[16]
Wen, Q., Zhou, T., Zhang, C., Chen, W., Ma, Z., Yan, J., and Sun, L
URL https://arxiv.org/abs/1706.03762. Wen, Q., Zhou, T., Zhang, C., Chen, W., Ma, Z., Yan, J., and Sun, L. Transformers in time series: A survey.arXiv preprint arXiv:2202.07125,
-
[17]
Zhang, J., Zhang, Z., Zheng, S., Wen, X., Li, J., and Bian, J. Are time series foundation models deployment-ready? a systematic study of adversarial robustness across domains. arXiv preprint arXiv:2505.19397,
-
[19]
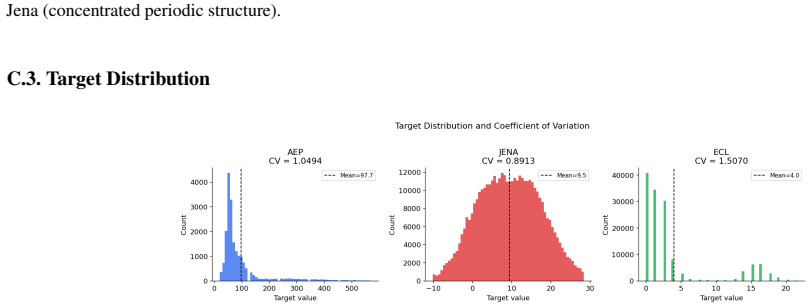
URL https:// arxiv.org/abs/1806.00580. 5 MorphStrata: Layer-Specific Perturbations for Generating Morphence Students in Time-Series Moving Target Defense A. Appendix This appendix contains dataset pipelines, temporal structure analysis, synthetic dataset experiments and generation method- ology, full RMSE tables, statistical heterogeneity and differential...
-
[20]
Electricity Load Diagrams (ECL) ECL captures electricity load at 15-minute resolution for a single meter
B.2. Electricity Load Diagrams (ECL) ECL captures electricity load at 15-minute resolution for a single meter. The task is multi-step ahead forecasting over a long historical context. Because the input history is long, input patching is applied before Transformer encoding to compress the sequence into a manageable length while preserving coarse temporal s...
2009
-
[21]
E. Model and Training Details All experiments use a shared Transformer architecture: input projection to dmodel = 128, 4 attention heads, 4 encoder layers, feed-forward dimension 256, pre-norm (norm-first) configuration, dropout 0.1. The same architecture is used for the base model, vanilla students, and MorphStrata students across all three datasets, ens...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.