Counterfactual Explanations Under Concept Drift
Pith reviewed 2026-05-20 14:00 UTC · model grok-4.3
The pith
Counterfactual explanations lose validity as models update under concept drift but can be repaired efficiently with local sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
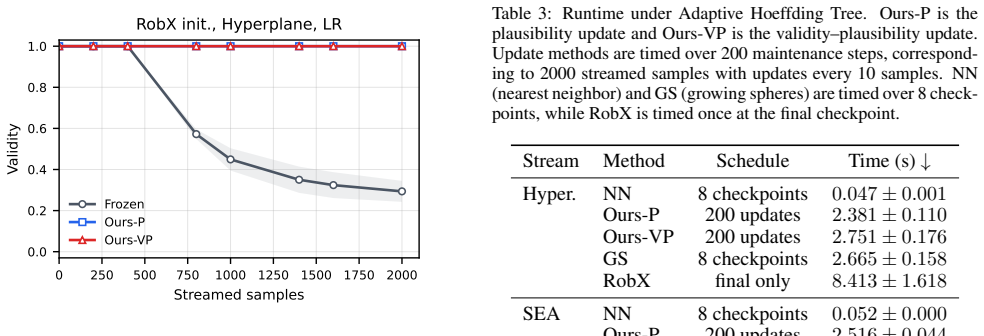
The central claim is that in online settings with concept drift, initially valid counterfactual explanations rapidly become invalid as the underlying classifier is updated, including cases using robust counterfactuals. A lightweight update scheme repairs existing explanations through local sampling that estimates validity and plausibility directions while preserving proximity to the original instance. This approach is model-agnostic and avoids full retraining or global model access, as shown by experiments where maintained explanations retain validity and local plausibility more efficiently than repeated regeneration.
What carries the argument
Lightweight update scheme that uses local sampling around the original instance to estimate validity and plausibility directions while preserving proximity.
If this is right
- Initially created counterfactual explanations rapidly lose validity in drifting data streams.
- Maintained counterfactuals preserve validity and local plausibility over time.
- The update procedure costs less than repeated full regeneration after each model update.
- The scheme works in a model-agnostic manner and applies even to robust counterfactuals.
- Continuous monitoring and repair of explanations becomes necessary for actionable recourse in streaming environments.
Where Pith is reading between the lines
- The local sampling technique could be paired with drift detection algorithms to trigger updates only when needed.
- This maintenance idea may extend to other explanation methods such as feature attributions in changing data environments.
- Real-world recourse systems in areas like credit scoring could become more reliable if explanations are kept current without heavy recomputation.
Load-bearing premise
Local sampling around the original instance is sufficient to estimate the adjustments needed to restore validity and plausibility under concept drift.
What would settle it
An experiment on a controlled drifting stream where the maintained counterfactuals show no validity improvement over unmaintained ones or where their computational cost exceeds that of full regeneration.
Figures

read the original abstract
Counterfactual explanations (CFEs) provide actionable recourse, but most methods assume a static framework with fixed data and a trained classifier. This assumption breaks in evolving data environments, such as data streams, where online models are repeatedly updated under concept drift. We identify CFE maintenance in this setting as a previously overlooked problem: explanations that are valid when generated may silently become invalid as the model evolves, including robust CFEs, which are not designed for continuous drift. We propose a lightweight, model-agnostic update scheme that repairs existing CFEs using local sampling to estimate validity and plausibility directions while preserving proximity to the original instance. Experiments on synthetic drifting streams show that initially created CFEs rapidly lose validity, whereas maintained CFEs preserve validity and local plausibility at a lower cost than repeated regeneration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies counterfactual explanation (CFE) maintenance as an overlooked problem under concept drift in data streams, where initially valid CFEs (including robust ones) can silently become invalid as models are updated online. It proposes a lightweight, model-agnostic repair scheme that uses local sampling around the original instance to estimate validity and plausibility adjustment directions while preserving proximity. Experiments on synthetic drifting streams are reported to show rapid validity loss for static CFEs and that the maintenance approach preserves validity and local plausibility at lower cost than repeated full regeneration.
Significance. If the proposed scheme works as claimed, the work would highlight a practically relevant gap in CFE deployment for non-stationary environments and offer a low-overhead maintenance method. The synthetic-stream results provide initial evidence that maintenance can outperform regeneration, but the limited experimental detail and reliance on local sampling limit the strength of the significance assessment at present.
major comments (2)
- [Method (local sampling procedure)] The core update scheme (described in the method) estimates validity/plausibility directions exclusively via local sampling around the original instance. This is load-bearing for the claim that repaired CFEs remain valid after drift, yet concept drift realized via global parameter changes or distribution shifts may move the decision boundary in ways not reliably detectable from a local neighborhood (particularly when the CFE lies at some distance from the instance). No analysis or experiment tests whether the local signal suffices when drift effects are non-local.
- [Experiments] The experimental results (abstract and experiments section) claim that maintained CFEs preserve validity and local plausibility at lower cost than regeneration, but the manuscript provides no details on the synthetic stream generation process, drift types simulated, number of independent runs, statistical testing, or baseline implementations. This absence makes it impossible to evaluate whether the reported benefits are robust or general.
minor comments (2)
- [Preliminaries / Method] Notation for validity and plausibility scores is introduced without a clear formal definition or reference to prior work; a short equation or pseudocode block would improve clarity.
- [Introduction] The abstract states that even 'robust CFEs' lose validity, but the manuscript does not specify which robustness notion is used or how it was implemented in the experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and indicate the revisions made to strengthen the work.
read point-by-point responses
-
Referee: [Method (local sampling procedure)] The core update scheme (described in the method) estimates validity/plausibility directions exclusively via local sampling around the original instance. This is load-bearing for the claim that repaired CFEs remain valid after drift, yet concept drift realized via global parameter changes or distribution shifts may move the decision boundary in ways not reliably detectable from a local neighborhood (particularly when the CFE lies at some distance from the instance). No analysis or experiment tests whether the local signal suffices when drift effects are non-local.
Authors: We agree this is a substantive concern. The local sampling design prioritizes computational efficiency and model-agnostic operation for streaming settings, but it implicitly assumes that relevant drift signals are detectable in the vicinity of the instance. For strongly non-local global shifts the local estimate could indeed be unreliable. In the revised manuscript we have added an explicit limitations subsection discussing this assumption and included a new experiment that injects a global parameter shift to quantify when the local repair remains effective versus when full regeneration is preferable. revision: yes
-
Referee: [Experiments] The experimental results (abstract and experiments section) claim that maintained CFEs preserve validity and local plausibility at lower cost than regeneration, but the manuscript provides no details on the synthetic stream generation process, drift types simulated, number of independent runs, statistical testing, or baseline implementations. This absence makes it impossible to evaluate whether the reported benefits are robust or general.
Authors: The referee is correct that these details were omitted. The revised Experiments section now specifies the synthetic stream generator (linear and nonlinear decision boundaries with controlled drift injection), the two drift regimes tested (abrupt and gradual), the number of independent runs (20), the statistical procedure (Wilcoxon signed-rank tests with Bonferroni correction), and the precise re-implementations of the regeneration and static baselines. revision: yes
Circularity Check
No circularity: proposal and empirical validation are self-contained
full rationale
The paper introduces a new model-agnostic update scheme for repairing counterfactual explanations under concept drift via local sampling to estimate validity and plausibility directions. This is presented as an original contribution addressing an overlooked problem, with central claims supported by experiments on synthetic drifting streams that independently demonstrate rapid loss of validity in initial CFEs versus preservation in maintained ones at lower cost. No load-bearing steps reduce to self-definition, fitted inputs renamed as predictions, or self-citation chains; the derivation relies on the proposed method and external empirical results rather than circular reduction to inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- local sampling parameters
axioms (1)
- domain assumption Local sampling can estimate validity and plausibility directions under concept drift
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We estimate this direction by sampling perturbations around x′ and querying ft for class probabilities... v = (E⊤ W E + ηI)−1 E⊤ W q
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
p = sum Kh(zj − x′)(zj − x′) / sum Kh(zj − x′) ... moves the CFE toward a local mode of the target-class observations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
[Ateset al., 2021 ] Emre Ates, Burak Aksar, Vitus J. Leung, and Ayse K. Coskun. Counterfactual explanations for mul- tivariate time series. In2021 International Conference on Applied Artificial Intelligence (ICAPAI), page 1–8. IEEE, May
work page 2021
-
[2]
Learning from Time-Changing Data with Adaptive Win- dowing, pages 443–448
[Bifet and Gavaldà, 2007] Albert Bifet and Ricard Gavaldà. Learning from Time-Changing Data with Adaptive Win- dowing, pages 443–448
work page 2007
-
[3]
[Bodriaet al., 2023 ] Francesco Bodria, Fosca Giannotti, Riccardo Guidotti, Francesca Naretto, Dino Pedreschi, and Salvatore Rinzivillo. Benchmarking and survey of expla- nation methods for black box models.Data Mining and Knowledge Discovery, 37(5):1719–1778,
work page 2023
-
[4]
[Brzezinski and Stefanowski, 2013] Dariusz Brzezinski and Jerzy Stefanowski. Reacting to different types of concept drift: The accuracy updated ensemble algorithm.IEEE transactions on neural networks and learning systems, 25(1):81–94,
work page 2013
-
[5]
Mean shift: A robust approach toward feature space analysis.IEEE Trans
[Comaniciu and Meer, 2002] Dorin Comaniciu and Peter Meer. Mean shift: A robust approach toward feature space analysis.IEEE Trans. Pattern Anal. Mach. Intell., 24(5):603–619, May
work page 2002
-
[6]
[Delaneyet al., 2021 ] Eoin Delaney, Derek Greene, and Mark T. Keane. Instance-based counterfactual explana- tions for time series classification. InCase-Based Rea- soning Research and Development: 29th International Conference, ICCBR 2021, Salamanca, Spain, September 13–16, 2021, Proceedings, page 32–47, Berlin, Heidel- berg,
work page 2021
-
[7]
Springer-Verlag. [Duttaet al., 2022 ] Sanghamitra Dutta, Jason Long, Saumi- tra Mishra, Cecilia Tilli, and Daniele Magazzeni. Robust counterfactual explanations for tree-based ensembles. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato, editors,Pro- ceedings of the 39th International Conference on Machine Lear...
work page 2022
-
[8]
A survey on concept drift adaptation.ACM computing sur- veys (CSUR), 46(4):1–37,
[Gamaet al., 2014 ] João Gama, Indr ˙e Žliobait ˙e, Albert Bifet, Mykola Pechenizkiy, and Abdelhamid Bouchachia. A survey on concept drift adaptation.ACM computing sur- veys (CSUR), 46(4):1–37,
work page 2014
-
[9]
Counterfactual vi- sual explanations
[Goyalet al., 2019 ] Yash Goyal, Ziyan Wu, Jan Ernst, Dhruv Batra, Devi Parikh, and Stefan Lee. Counterfactual vi- sual explanations. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors,Proceedings of the 36th Interna- tional Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 2376–
work page 2019
-
[10]
[Guidotti, 2022] Riccardo Guidotti. Counterfactual expla- nations and how to find them: literature review and benchmarking.Data Mining and Knowledge Discovery, 38(5):2770–2824, April
work page 2022
-
[11]
Model-based ex- planations of concept drift.Neurocomputing, 555:126640, 07
[Hinderet al., 2023 ] Fabian Hinder, Valerie Vaquet, Jo- hannes Brinkrolf, and Barbara Hammer. Model-based ex- planations of concept drift.Neurocomputing, 555:126640, 07
work page 2023
-
[12]
Robust counterfactual ex- planations in machine learning: a survey
[Jianget al., 2024 ] Junqi Jiang, Francesco Leofante, Anto- nio Rago, and Francesca Toni. Robust counterfactual ex- planations in machine learning: a survey. InProceedings of the Thirty-Third International Joint Conference on Ar- tificial Intelligence, IJCAI ’24,
work page 2024
-
[13]
Model-agnostic counter- factual explanations for consequential decisions
[Karimiet al., 2020 ] Amir-Hossein Karimi, Gilles Barthe, Borja Balle, and Isabel Valera. Model-agnostic counter- factual explanations for consequential decisions. In Silvia Chiappa and Roberto Calandra, editors,Proceedings of the Twenty Third International Conference on Artificial Intel- ligence and Statistics, volume 108 ofProceedings of Ma- chine Learn...
work page 2020
-
[14]
Comparison-based Inverse Classification for Interpretability in Machine Learning
[Laugelet al., 2018 ] Thibault Laugel, Marie-Jeanne Lesot, Christophe Marsala, Xavier Renard, and Marcin De- tyniecki. Comparison-based Inverse Classification for Interpretability in Machine Learning. In Jesús Med- ina, Manuel Ojeda-Aciego, José Luis Verdegay, David A. Pelta, Inma P. Cabrera, Bernadette Bouchon-Meunier, and Ronald R. Yager, editors,Inform...
work page 2018
-
[15]
[Luet al., 2018 ] Jie Lu, Anjin Liu, Fan Dong, Feng Gu, Joao Gama, and Guangquan Zhang
Springer Verlag. [Luet al., 2018 ] Jie Lu, Anjin Liu, Fan Dong, Feng Gu, Joao Gama, and Guangquan Zhang. Learning under concept drift: A review.IEEE Transactions on Knowledge and Data Engineering, PP:1–1, 10
work page 2018
-
[16]
River: Machine learning for streaming data in python,
[Montielet al., 2021 ] Jacob Montiel, Max Halford, Saulo Martiello Mastelini, Geoffrey Bolmier, Raphael Sourty, Robin Vaysse, Adil Zouitine, Heitor Murilo Gomes, Jesse Read, Talel Abdessalem, et al. River: Machine learning for streaming data in python,
work page 2021
-
[17]
Mothilal, Amit Sharma, and Chenhao Tan
[Mothilalet al., 2020 ] Ramaravind K. Mothilal, Amit Sharma, and Chenhao Tan. Explaining machine learning classifiers through diverse counterfactual explanations. InProceedings of the 2020 Conference on Fairness, Ac- countability, and Transparency, FAT* ’20, page 607–617. ACM, January
work page 2020
-
[18]
[Ribeiroet al., 2016 ] Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. "why should i trust you?": Ex- plaining the predictions of any classifier. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, page 1135–1144, New York, NY , USA,
work page 2016
-
[19]
[St˛ epka and Stefanowski, 2025] Ignacy St˛ epka and Jerzy Stefanowski
Association for Computing Machinery. [St˛ epka and Stefanowski, 2025] Ignacy St˛ epka and Jerzy Stefanowski. Explaining concept drift through the evolution of group counterfactuals.arXiv preprint arXiv:2509.09616,
-
[20]
Counterfactual explanations with prob- abilistic guarantees on their robustness to model change
[St˛ epkaet al., 2025] Ignacy St˛ epka, Jerzy Stefanowski, and Mateusz Lango. Counterfactual explanations with prob- abilistic guarantees on their robustness to model change. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1, pages 1277– 1288,
work page 2025
-
[21]
Springer Interna- tional Publishing,
[Van Looveren and Klaise, 2021] Arnaud Van Looveren and Janis Klaise.Interpretable Counterfactual Explanations Guided by Prototypes, page 650–665. Springer Interna- tional Publishing,
work page 2021
-
[22]
[Vermaet al., 2024 ] Sahil Verma, Varich Boonsanong, Minh Hoang, Keegan Hines, John Dickerson, and Chirag Shah. Counterfactual explanations and algorithmic recourses for machine learning: A review.ACM Computing Surveys, 56(12):1–42, October
work page 2024
-
[23]
Counterfactual explanations without opening the black box: Automated decisions and the gdpr
[Wachteret al., 2017 ] Sandra Wachter, Brent Mittelstadt, and Chris Russell. Counterfactual explanations without opening the black box: Automated decisions and the gdpr. SSRN Electronic Journal, 2017
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.