Fairness-Aware Federated Learning with Trajectory Shapley Value
Pith reviewed 2026-06-29 08:59 UTC · model grok-4.3
The pith
Trajectory Shapley Value measures each client's influence on the global model's optimization path to set dynamic aggregation weights in federated learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that client influence in federated learning can be quantified by the change each client's update produces along the entire optimization trajectory, rather than by a single-round or fixed contribution score. The Trajectory Shapley Value uses a temporally consistent validation utility to compute these influences. FedTSV then converts the resulting values into dynamic client weights for the server aggregation step, allowing real-time adjustment to heterogeneous and adversarial participation patterns.
What carries the argument
Trajectory Shapley Value (TSV), a contribution metric that evaluates how each client influences the optimization trajectory of the global model using a validation-based, temporally consistent utility.
If this is right
- FedTSV accelerates convergence on standard benchmark datasets compared with fixed-weight schemes.
- The method improves robustness when some clients participate adversarially or drop out unpredictably.
- Contribution assessments become more equitable across clients with differing data volumes or qualities.
- The framework supplies a principled basis for fairness-aware aggregation rules in distributed training.
Where Pith is reading between the lines
- TSV weights could be cached across rounds to reduce computation when client sets change slowly.
- The same trajectory-based scoring might apply to measuring influence in decentralized optimization beyond the federated server-client setting.
- Combining TSV with explicit privacy mechanisms could quantify the fairness cost of noise injection.
Load-bearing premise
A validation-based, temporally consistent utility function can accurately and unbiasedly quantify each client's influence on the global optimization trajectory.
What would settle it
In a controlled experiment with one client known to send updates that slow convergence, the TSV-derived weights fail to reduce that client's aggregation share relative to uniform averaging while still reaching the same final accuracy.
Figures
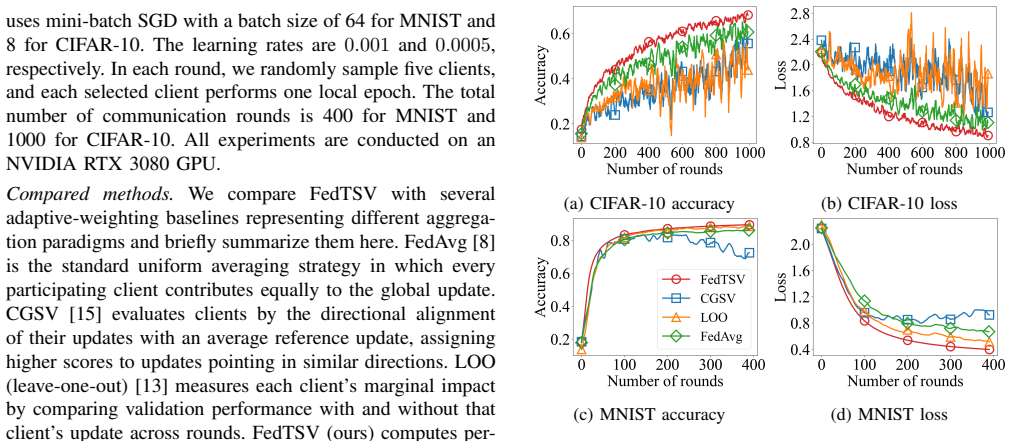
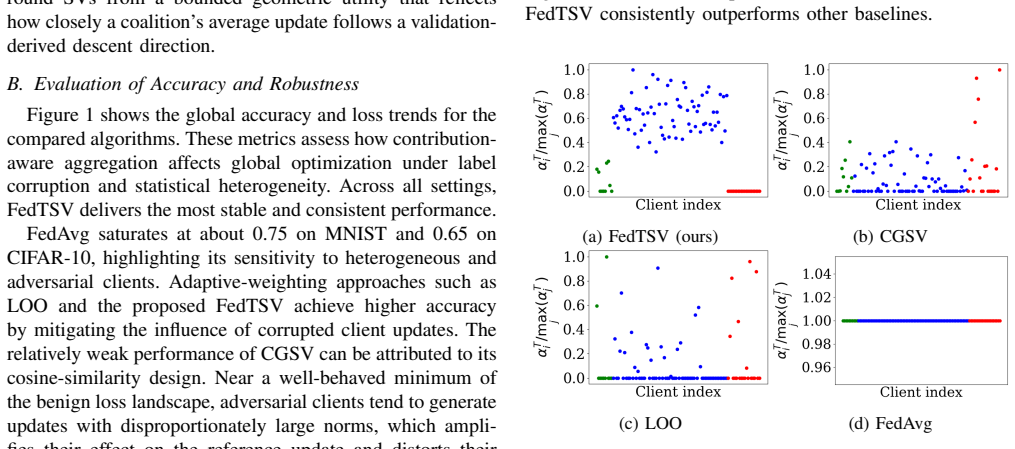
read the original abstract
Federated learning is an emerging distributed paradigm that addresses the challenges posed by heterogeneous, privacy-sensitive data. It enables multiple clients to train a model collaboratively by aggregating their local updates at a server. However, conventional aggregation schemes typically use fixed weights that fail to reflect unequal and time-varying client contributions, leading to biased and unstable learning. To improve fairness and stability, we propose the Trajectory Shapley Value (TSV), a contribution metric that evaluates how each client influences the optimization trajectory of the global model using a validation-based, temporally consistent utility. Building on TSV, we design FedTSV, an adaptive aggregation method that converts per-round evaluations into dynamic client weights, allowing the server to respond to heterogeneous and adversarial participation in real time. Experiments on benchmark datasets show that FedTSV accelerates convergence, improves robustness, and yields more equitable contribution assessments, thereby providing a principled foundation for fairness-aware federated optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Trajectory Shapley Value (TSV), a contribution metric that evaluates each client's influence on the global model's optimization trajectory via a validation-based, temporally consistent utility function. It introduces FedTSV, an adaptive aggregation scheme that converts per-round TSV scores into dynamic client weights to handle heterogeneous and adversarial participation. Experiments on benchmark datasets are reported to demonstrate accelerated convergence, improved robustness to adversaries, and more equitable contribution assessments compared to conventional fixed-weight aggregation.
Significance. If the TSV utility is shown to be an unbiased estimator of marginal trajectory influence and FedTSV yields stable fairness improvements without degrading accuracy, the work would supply a concrete, per-round mechanism for fairness-aware aggregation in non-IID federated learning. The absence of derivations, proofs, or detailed error analysis in the provided abstract limits assessment of whether these gains are parameter-free or merely reparameterized.
major comments (1)
- [Abstract] Abstract: the central claim that the validation-based utility 'accurately and unbiasedly quantifies each client's influence' is load-bearing for both the TSV definition and the fairness guarantees of FedTSV, yet the abstract supplies no argument that a fixed server validation distribution remains representative of the optimization trajectory's effect on heterogeneous client distributions. Under non-IID data this choice risks systematic bias in the resulting dynamic weights.
Simulated Author's Rebuttal
We thank the referee for highlighting a key assumption in our abstract. We agree the claim about unbiased quantification merits qualification and will revise the manuscript to address representativeness of the validation distribution under non-IID conditions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the validation-based utility 'accurately and unbiasedly quantifies each client's influence' is load-bearing for both the TSV definition and the fairness guarantees of FedTSV, yet the abstract supplies no argument that a fixed server validation distribution remains representative of the optimization trajectory's effect on heterogeneous client distributions. Under non-IID data this choice risks systematic bias in the resulting dynamic weights.
Authors: We acknowledge the point: the abstract's phrasing is stronger than the supporting argument provided there. The full manuscript motivates the validation set as a proxy for trajectory progress (Section 3.2), but does not derive unbiasedness or prove representativeness under arbitrary non-IID partitions. In the revision we will (i) replace the absolute claim in the abstract with 'approximates client influence via a temporally consistent validation utility,' (ii) add a dedicated paragraph in Section 3.3 discussing the fixed validation assumption and its potential bias, and (iii) include an additional experiment varying the validation distribution to quantify sensitivity. These changes will make the limitations explicit while preserving the empirical evidence that FedTSV improves fairness metrics on the reported benchmarks. revision: yes
Circularity Check
No circularity; TSV utility defined externally via validation set
full rationale
The derivation introduces TSV as a Shapley-style metric computed from a validation-based, temporally consistent utility function that is independent of the resulting client weights. FedTSV then applies these pre-computed values as dynamic aggregation coefficients. No equation reduces the claimed influence scores or convergence improvements to a fitted parameter or self-referential definition; the utility remains an external input. No self-citations are load-bearing in the provided text, and the central construction does not collapse to renaming or tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A validation-based utility function can provide a temporally consistent measure of client contribution to the optimization trajectory.
invented entities (1)
-
Trajectory Shapley Value (TSV)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Federated learning: Challenges, methods, and future directions,
T. Li, A. K. Sahu, A. Talwalkar, and V . Smith, “Federated learning: Challenges, methods, and future directions,”IEEE signal processing magazine, vol. 37, no. 3, pp. 50–60, 2020
2020
-
[2]
Advances and open problems in federated learning,
P. Kairouz, H. B. McMahanet al., “Advances and open problems in federated learning,”Foundations and Trends® in Machine Learning, vol. 14, no. 1–2, pp. 1–210, 2021
2021
-
[3]
Hierarchical split federated learning: Convergence analysis and sys- tem optimization,
Z. Lin, W. Wei, Z. Chen, C.-T. Lam, X. Chen, Y . Gao, and J. Luo, “Hierarchical split federated learning: Convergence analysis and sys- tem optimization,”IEEE Transactions on Mobile Computing, vol. 24, no. 10, pp. 9352–9367, 2025
2025
-
[4]
Federated multiagent deep reinforcement learning approach via physics-informed reward for multimicrogrid energy management,
Y . Li, S. He, Y . Li, Y . Shi, and Z. Zeng, “Federated multiagent deep reinforcement learning approach via physics-informed reward for multimicrogrid energy management,”IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 5, pp. 5902–5914, 2024
2024
-
[5]
Challenges and directions in computational fluid–structure interaction,
Y . Bazilevs, K. Takizawa, and T. E. Tezduyar, “Challenges and directions in computational fluid–structure interaction,”Mathematical Models and Methods in Applied Sciences, vol. 23, no. 02, pp. 215–221, 2013
2013
-
[6]
A review of modelling techniques for floating offshore wind turbines,
A. Otter, J. Murphy, V . Pakrashi, A. Robertson, and C. Desmond, “A review of modelling techniques for floating offshore wind turbines,” Wind Energy, vol. 25, no. 5, pp. 831–857, 2022
2022
-
[7]
A comprehensive review of wind power prediction based on machine learning: Models, applications, and challenges,
Z. Liu, H. Guo, Y . Zhang, and Z. Zuo, “A comprehensive review of wind power prediction based on machine learning: Models, applications, and challenges,”Energies, vol. 18, no. 2, 2025. [Online]. Available: https://www.mdpi.com/1996-1073/18/2/350
2025
-
[8]
Communication-efficient learning of deep networks from decentral- ized data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentral- ized data,” inProceedings of the 20th International Conference on Artificial Intelligence and Statistics. PMLR, Apr. 2017, pp. 1273– 1282
2017
-
[9]
SCAFFOLD: Stochastic controlled averaging for federated learning,
S. P. Karimireddy, S. Kale, M. Mohri, S. Reddi, S. Stich, and A. T. Suresh, “SCAFFOLD: Stochastic controlled averaging for federated learning,” inProceedings of the 37th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, H. D. III and A. Singh, Eds., vol. 119. PMLR, 13–18 Jul 2020, pp. 5132–5143
2020
-
[10]
FedADMM-InSa: An inexact and self-adaptive ADMM for federated learning,
Y . Song, Z. Wang, and E. Zuazua, “FedADMM-InSa: An inexact and self-adaptive ADMM for federated learning,”Neural Networks, vol. 181, p. 106772, Jan. 2025. [Online]. Available: https: //www.sciencedirect.com/science/article/pii/S0893608024006968
2025
-
[11]
Beyond ADMM: A unified client-variance-reduced adaptive federated learning framework,
S. Wang, Y . Xu, Z. Wang, T.-H. Chang, T. Q. S. Quek, and D. Sun, “Beyond ADMM: A unified client-variance-reduced adaptive federated learning framework,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 8, 2023, pp. 10 175–10 183
2023
-
[12]
Notes on the N-Person Game — II: The Value of an N- Person Game,
L. S. Shapley, “Notes on the N-Person Game — II: The Value of an N- Person Game,” RAND Corporation, Tech. Rep. RM-670, Aug. 1951. [Online]. Available: https://www.rand.org/pubs/research memoranda/ RM0670.html
1951
-
[13]
Measure contribution of participants in federated learning,
G. Wang, C. X. Dang, and Z. Zhou, “Measure contribution of participants in federated learning,” in2019 IEEE International Conference on Big Data (Big Data). IEEE, 2019, pp. 2597–2604. [Online]. Available: https://ieeexplore.ieee.org/document/9006179
-
[14]
On the volatility of shapley-based contribution metrics in federated learning,
A. Geimer, B. Fiz, and R. State, “On the volatility of shapley-based contribution metrics in federated learning,” in2025 International Joint Conference on Neural Networks (IJCNN). IEEE, 2025, pp. 1–8
2025
-
[15]
Gradient driven rewards to guarantee fairness in collaborative machine learn- ing,
X. Xu, L. Lyu, X. Ma, C. Miao, C. S. Foo, and B. K. H. Low, “Gradient driven rewards to guarantee fairness in collaborative machine learn- ing,” inAdvances in Neural Information Processing Systems, vol. 34. Curran Associates, Inc., 2021, pp. 16 104–16 117
2021
-
[16]
A multi-objective optimization framework for decentralized learning with coordination constraints,
R. Morales and U. Biccari, “A multi-objective optimization framework for decentralized learning with coordination constraints,” Jul. 2025, arXiv:2507.13983
-
[17]
GTG-Shapley: Efficient and accurate participant contribution evaluation in federated learning,
Z. Liu, Y . Chen, H. Yu, Y . Liu, and L. Cui, “GTG-Shapley: Efficient and accurate participant contribution evaluation in federated learning,” ACM Transactions on Intelligent Systems and Technology, vol. 13, no. 4, pp. 1–21, 2022
2022
-
[18]
ShapleyFL: Robust federated learning based on shapley value,
Q. Sun, X. Li, J. Zhang, L. Xiong, W. Liu, J. Liu, Z. Qin, and K. Ren, “ShapleyFL: Robust federated learning based on shapley value,” in Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, ser. KDD ’23. New York, NY , USA: Association for Computing Machinery, 2023, p. 2096–2108. [Online]. Available: https://doi.org/10.114...
-
[19]
H. Peters,Game Theory. Berlin, Heidelberg: Springer, 2008. [Online]. Available: http://link.springer.com/10.1007/978-3-540-69291-1
-
[20]
Efficient sampling approaches to shapley value approximation,
J. Zhang, Q. Sun, J. Liu, L. Xiong, J. Pei, and K. Ren, “Efficient sampling approaches to shapley value approximation,”Proc. ACM Manag. Data, vol. 1, no. 1, May 2023
2023
-
[21]
Towards efficient data valuation based on the shapley value,
R. Jia, D. Dao, B. Wang, F. A. Hubis, N. Hynes, N. M. G ¨urel, B. Li, C. Zhang, D. Song, and C. J. Spanos, “Towards efficient data valuation based on the shapley value,” inProceedings of the Twenty- Second International Conference on Artificial Intelligence and Statis- tics, ser. Proceedings of Machine Learning Research, K. Chaudhuri and M. Sugiyama, Eds....
2019
-
[22]
How to backdoor federated learning,
E. Bagdasaryan, A. Veit, Y . Hua, D. Estrin, and V . Shmatikov, “How to backdoor federated learning,” inProceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, ser. Proceedings of Machine Learning Research, S. Chiappa and R. Calandra, Eds., vol. 108. PMLR, 26–28 Aug 2020, pp. 2938– 2948
2020
-
[23]
Gradient-based learning applied to document recognition,
Y . LeCun, L. Bottou, Y . Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,”Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998
1998
-
[24]
Learning multiple layers of features from tiny images,
A. Krizhevsky and G. Hinton, “Learning multiple layers of features from tiny images,” University of Toronto, Tech. Rep. TR- 2009, 2009. [Online]. Available: https://www.cs.toronto.edu/ ∼kriz/ learning-features-2009-TR.pdf
2009
-
[25]
Measuring the effects of non-identical data distribution for federated visual classification,
T.-M. H. Hsu, H. Qi, and M. Brown, “Measuring the effects of non-identical data distribution for federated visual classification,”
-
[26]
Measuring the Effects of Non-Identical Data Distribution for Federated Visual Classification
[Online]. Available: https://arxiv.org/abs/1909.06335 6
work page internal anchor Pith review Pith/arXiv arXiv 1909
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.