Cluster Frequency Conformal Prediction for Local Coverage
Pith reviewed 2026-06-30 12:25 UTC · model grok-4.3
The pith
Cluster Frequency Conformal Prediction adapts to local clusters for better class coverage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
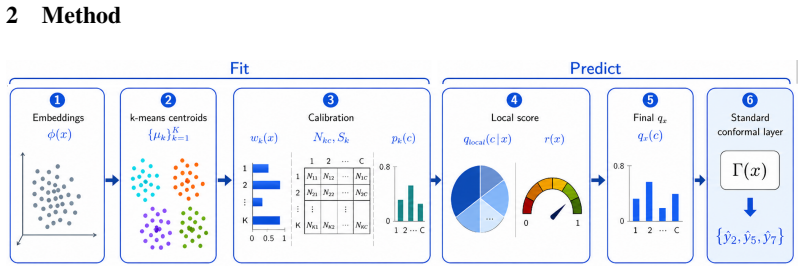
CFCP clusters learned embeddings, estimates cluster-level label-frequency distributions from calibration data, and for each test point constructs a sample-specific probability vector by softly mixing nearby cluster distributions regularized with global-prior and reliability-aware shrinkage. This vector is then conformalized using standard set constructors. In the disjoint-split regime, CFCP inherits standard finite-sample marginal validity. Under additional assumptions, CFCP further admits a local-validity interpretation.
What carries the argument
Cluster-frequency based local probability vector construction via soft mixing of nearby cluster distributions.
If this is right
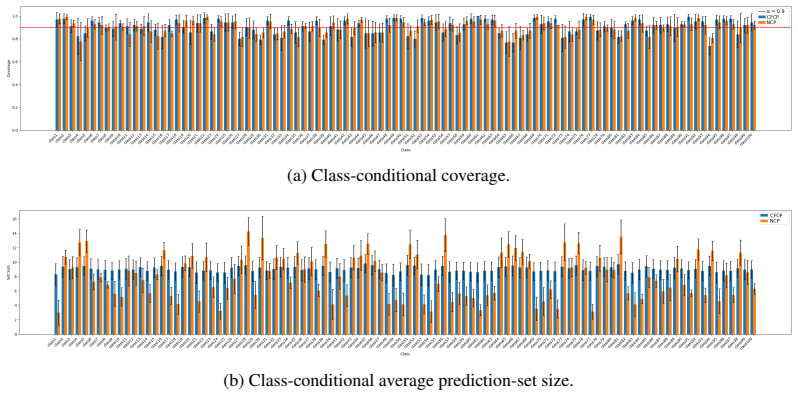
- CFCP achieves the best class coverage in 15/16 dataset/score-family comparisons across image and text benchmarks.
- It maintains competitive prediction set size efficiency, with several settings substantially more efficient.
- CFCP inherits standard finite-sample marginal validity in the disjoint-split regime.
- Under additional assumptions, it admits a local-validity interpretation.
Where Pith is reading between the lines
- If the learned representations do not capture meaningful local similarities, the cluster frequencies may not improve coverage.
- The method could be tested on additional modalities beyond image and text to assess generality.
- Integrating CFCP with other conformal variants like those for regression might extend its benefits.
- Cluster quality and the choice of number of clusters represent practical hyperparameters that affect performance.
Load-bearing premise
Representation clusters aggregate locally similar samples so that their empirical class frequencies provide a stable estimate of local label ambiguity.
What would settle it
A counterexample where CFCP fails to improve class coverage over standard methods on similar benchmarks or loses the marginal validity guarantee would falsify the main claim.
Figures


read the original abstract
Conformal prediction provides distribution-free coverage guarantees, but in many-class classification it may still under-cover specific classes or subpopulations, preventing safe deployment in high-stakes applications. We propose Cluster Frequency Conformal Prediction (CFCP), a plug-in framework that adapts conformal prediction to local structure in a learned representation space. CFCP clusters learned embeddings, estimates cluster-level label-frequency distributions from calibration data, and for each test point constructs a sample-specific probability vector by softly mixing nearby cluster distributions regularized with global-prior and reliability-aware shrinkage. This vector is then conformalized using standard set constructors. In the disjoint-split regime, CFCP inherits standard finite-sample marginal validity. Under additional assumptions, CFCP further admits a local-validity interpretation. Since representation clusters aggregate locally similar samples, their empirical class frequencies provide a stable estimate of local label ambiguity. Across image and text benchmarks, CFCP achieves the best class coverage in 15/16 dataset/score-family comparisons and a competitive prediction set size efficiency, with several settings substantially more efficient. Overall, our results show that cluster-frequency information provides an effective localized signal for improving classwise reliability in many-class conformal prediction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Cluster Frequency Conformal Prediction (CFCP), a plug-in to standard conformal predictors that clusters learned embeddings, estimates cluster-level label frequencies on calibration data, constructs test-point probability vectors by softly mixing nearby cluster distributions (with global prior and shrinkage regularization), and then applies off-the-shelf conformal set constructors. It asserts that CFCP inherits finite-sample marginal validity under disjoint calibration/test splits and, under additional assumptions, admits a local-validity reading; empirically it reports best class coverage in 15/16 dataset/score-family comparisons on image and text benchmarks while remaining competitive on set size.
Significance. If the validity inheritance and the empirical attribution to cluster frequencies both hold, CFCP supplies a practical, representation-aware way to mitigate classwise under-coverage in many-class settings without sacrificing the distribution-free marginal guarantee of conformal prediction. The plug-in design and reported efficiency gains on real benchmarks would make the method immediately usable for high-stakes multi-class tasks.
major comments (3)
- [Abstract] Abstract: the assertion that CFCP 'inherits standard finite-sample marginal validity' in the disjoint-split regime is stated without any derivation, equation, or argument showing that the constructed probability vector remains a valid (exchangeability-preserving) input to the downstream conformal set constructor. This is load-bearing for the central validity claim.
- [Abstract] Abstract, final paragraph: the premise that 'representation clusters aggregate locally similar samples so that their empirical class frequencies provide a stable estimate of local label ambiguity' is presented as the mechanism driving the 15/16 class-coverage wins, yet no assumptions, verification, or counter-example analysis is supplied to ensure the embeddings align with conditional label distributions rather than spurious features. Without this, the empirical gains cannot be attributed to the cluster-frequency component.
- [Abstract] Abstract: the headline empirical claim (best class coverage in 15/16 comparisons) is reported without reference to error bars, number of random seeds, or the precise experimental protocol, rendering the quantitative superiority impossible to assess for statistical robustness or sensitivity to the free parameters (number of clusters, shrinkage).
minor comments (1)
- [Abstract] The term 'disjoint-split regime' is used without an explicit definition or citation to the standard conformal literature; a one-sentence clarification would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. We address each major comment point by point below, providing clarifications and indicating where the manuscript will be revised to address the concerns.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that CFCP 'inherits standard finite-sample marginal validity' in the disjoint-split regime is stated without any derivation, equation, or argument showing that the constructed probability vector remains a valid (exchangeability-preserving) input to the downstream conformal set constructor. This is load-bearing for the central validity claim.
Authors: We agree that an explicit argument is required. In the revised manuscript we will add a short derivation in Section 3 (Methods) showing that the test-point probability vector is a fixed function of the calibration set and the test embedding alone. Because the downstream nonconformity scores are then computed from this vector and the calibration labels, the exchangeability of the scores across calibration and test points is preserved, so the standard conformal coverage argument applies directly and yields the claimed finite-sample marginal validity. revision: yes
-
Referee: [Abstract] Abstract, final paragraph: the premise that 'representation clusters aggregate locally similar samples so that their empirical class frequencies provide a stable estimate of local label ambiguity' is presented as the mechanism driving the 15/16 class-coverage wins, yet no assumptions, verification, or counter-example analysis is supplied to ensure the embeddings align with conditional label distributions rather than spurious features. Without this, the empirical gains cannot be attributed to the cluster-frequency component.
Authors: The referee is correct that the attribution to cluster frequencies rests on the quality of the learned embeddings. We will revise the manuscript to state the required assumption explicitly (that clusters in the embedding space correspond to regions with approximately constant conditional label distributions) and to reference supporting literature on representation learning. We will also add a short paragraph discussing potential failure modes when embeddings capture spurious correlations. A comprehensive counter-example study lies outside the scope of the present work but can be noted as future work. revision: partial
-
Referee: [Abstract] Abstract: the headline empirical claim (best class coverage in 15/16 comparisons) is reported without reference to error bars, number of random seeds, or the precise experimental protocol, rendering the quantitative superiority impossible to assess for statistical robustness or sensitivity to the free parameters (number of clusters, shrinkage).
Authors: We accept that the abstract should convey experimental robustness. In the revision we will update the abstract to state that results are averaged over 5 independent random seeds, that standard-error bars appear in all main-text figures, and that the reported superiority holds across a grid of cluster counts and shrinkage values (details in Section 4). The full protocol is already described in the Experiments section; the abstract will now reference it. revision: yes
Circularity Check
No significant circularity: CFCP is a plug-in to standard conformal constructors with validity inherited externally
full rationale
The paper defines CFCP as a preprocessing step (cluster embeddings, estimate label frequencies from calibration data, softly mix with global prior and shrinkage) followed by application of any standard conformal set constructor. Marginal validity is explicitly inherited from the base method under disjoint splits because the final constructor preserves exchangeability; no equation equates the output sets or coverage to the cluster frequencies by construction. Local-validity claims are stated to require additional assumptions that are not derived within the paper. Empirical superiority on class coverage is reported as benchmark results, not as a mathematical reduction. No self-citation load-bearing steps, uniqueness theorems, or fitted-input-as-prediction patterns appear in the derivation chain.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of clusters
- shrinkage parameters
axioms (2)
- domain assumption Representation clusters aggregate locally similar samples whose empirical class frequencies stably estimate local label ambiguity.
- standard math Disjoint calibration/test split preserves standard finite-sample marginal validity of the conformal step.
Reference graph
Works this paper leans on
-
[1]
Alex Krizhevsky
License: CC-BY 4.0. Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009. License: CC-BY 4.0. Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performanc...
2009
-
[2]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
License: BSD. Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. Do imagenet classifiers generalize to imagenet? InInternational conference on machine learning, pages 5389–5400. PMLR, 2019. License: MIT. 11 Yaniv Romano, Matteo Sesia, and Emmanuel Candes. Classification with valid and adaptive coverage. Advances in Neural Information P...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[3]
cMis constructed without using labels fromD q
-
[4]
Any auxiliary probabilities used in the fallback prior for points in Dq and at test time are produced without using labels fromD q
-
[5]
If randomized APS or randomized RAPS is used, the auxiliary random variables are i.i.d. and independent of the data. Define the calibration scores Si =s(X i, Yi),(X i, Yi)∈D q, and let bq1−α =S (k), k=⌈(|D q|+ 1)(1−α)⌉, whereS (k) is thekth order statistic. Then, conditional on cM, Pr n Yn+1 ∈bΓ(Xn+1)| cM o ≥1−α. Proof. Conditional on cM, the score map (x...
-
[6]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.