Spectral-Progressive Thought Flow for Lightweight Multimodal Reasoning
Pith reviewed 2026-06-28 15:38 UTC · model grok-4.3
The pith
SpecFlow encodes visual thoughts in fixed-size discrete cosine space so multimodal spatial reasoning stays bounded in memory and latency no matter the chain length.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
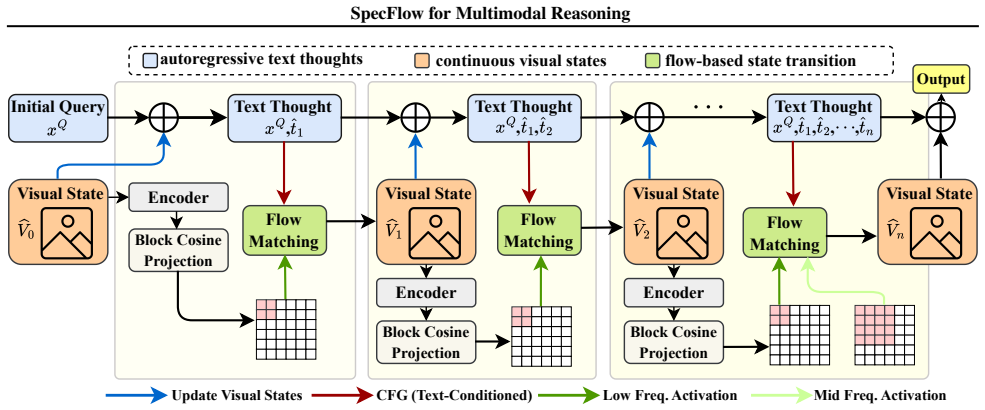
SpecFlow maintains a bounded visual workspace whose updates depend only on the current visual state and accumulated textual trace, enabling long-horizon inference with stable latency and memory usage independent of reasoning depth.
What carries the argument
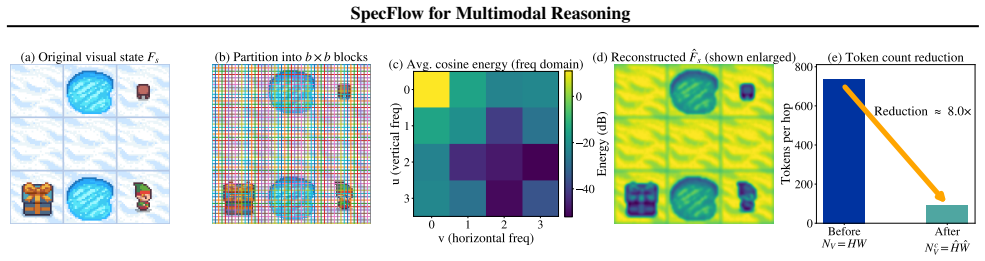
Fixed-size discrete cosine transform representation of visual thoughts, steered by classifier-free guidance from textual thoughts.
If this is right
- Reasoning depth can increase without quadratic growth in attention or cache costs.
- High-frequency visual details are introduced only when spatial precision requires them.
- Textual generation can direct visual state evolution without enlarging shared context.
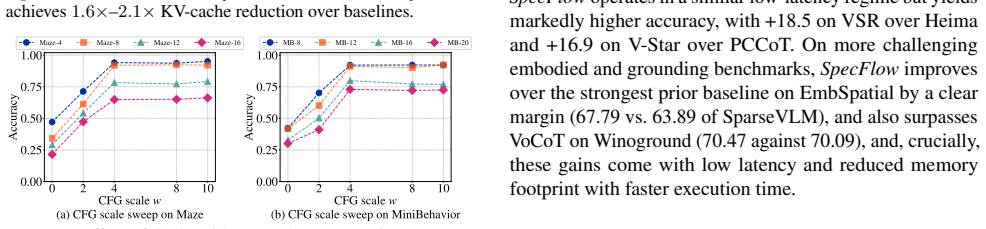
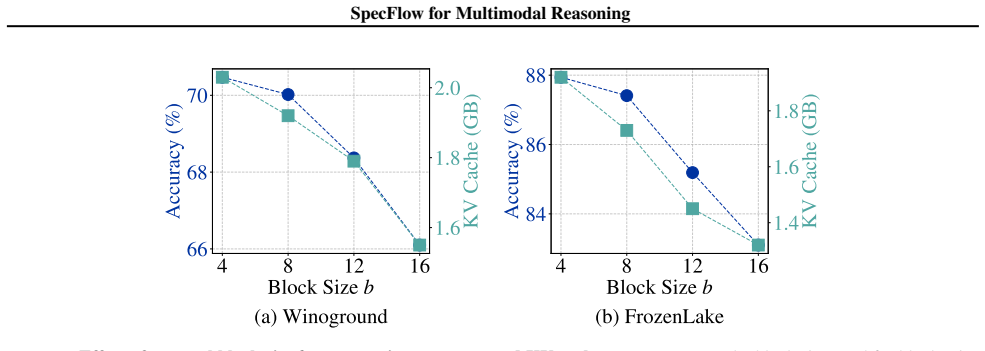
- Overall computation and KV cache usage drop by up to 2.1 times while accuracy remains competitive.
Where Pith is reading between the lines
- The same fixed spectral buffer could be tested on sequential video or audio reasoning chains.
- A direct comparison on puzzles whose solution depth exceeds the current benchmark maxima would expose any hidden limits of the fixed representation.
- Deployed agents running extended multimodal dialogues would see reduced per-step energy draw.
Load-bearing premise
A fixed-size frequency encoding plus guidance is sufficient to preserve all layout and relational structure needed for the target tasks without losing critical details.
What would settle it
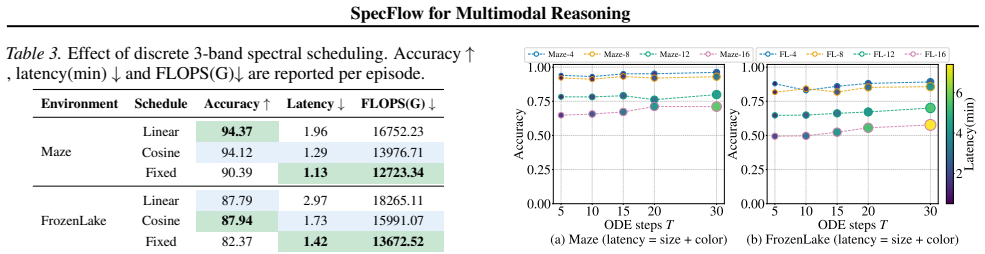
Compare SpecFlow against expanding-context baselines on a spatial reasoning benchmark whose hardest items require more than twenty chained visual-text steps; if accuracy stays competitive while measured KV cache and latency remain flat, the central claim holds.
Figures





read the original abstract
Multimodal spatial reasoning often relies on long chains of intermediate textual and visual thoughts, where accumulating visual tokens and dense cross-modal attention incur substantial computation and memory overhead. To address this challenge, we propose Spectral-Progressive Thought Flow (SpecFlow), a novel lightweight multimodal spatial reasoning framework that represents intermediate visual thoughts in a fixed-size discrete cosine space. By exploiting strong energy compaction, SpecFlow preserves global layout and relational structure while introducing high-frequency details only when increased spatial precision is required. To align visual state evolution with linguistic intent, classifier-free guidance enables autoregressive textual thoughts to steer flow-based updates of the visual workspace/state without expanding the context. As a result, SpecFlow maintains a bounded visual workspace whose updates depend only on the current visual state and accumulated textual trace, enabling long-horizon inference with stable latency and memory usage independent of reasoning depth. Empirical results show that SpecFlow achieves competitive or superior reasoning performance while reducing computation and KV cache costs by up to 2.1 times.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Spectral-Progressive Thought Flow (SpecFlow), a lightweight multimodal spatial reasoning framework that encodes intermediate visual thoughts in a fixed-size discrete cosine transform (DCT) space to preserve global layout while adding high-frequency details progressively. Classifier-free guidance aligns autoregressive textual thoughts with visual state updates without context expansion. The central claim is that this yields a bounded visual workspace whose updates depend only on the current visual state and accumulated textual trace, enabling long-horizon inference with latency and memory usage independent of reasoning depth, plus up to 2.1× reductions in computation and KV-cache costs while maintaining competitive reasoning performance.
Significance. If the bounded-workspace and depth-independent memory claims hold with the stated mechanisms, the work would offer a practical route to scalable long-horizon multimodal reasoning by avoiding the quadratic costs of accumulating visual tokens and dense cross-modal attention. The use of energy-compaction properties of DCT and classifier-free guidance for steering without expansion are potentially reusable ideas, but the absence of any derivation or experimental verification of the independence property limits the assessed impact at present.
major comments (1)
- [Abstract] Abstract: the claim that 'SpecFlow maintains a bounded visual workspace whose updates depend only on the current visual state and accumulated textual trace, enabling long-horizon inference with stable latency and memory usage independent of reasoning depth' is not supported by the described components. The visual workspace is stated to be fixed-size via DCT, but the textual trace is described as accumulated across autoregressive steps; standard transformer KV-cache implementations cause linear growth in context length (and thus memory) with reasoning depth. No mechanism for bounding, summarizing, windowing, or compressing the textual trace is referenced, so the independence property does not follow from the stated dependencies.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the bounded-workspace claim. We address the concern point by point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'SpecFlow maintains a bounded visual workspace whose updates depend only on the current visual state and accumulated textual trace, enabling long-horizon inference with stable latency and memory usage independent of reasoning depth' is not supported by the described components. The visual workspace is stated to be fixed-size via DCT, but the textual trace is described as accumulated across autoregressive steps; standard transformer KV-cache implementations cause linear growth in context length (and thus memory) with reasoning depth. No mechanism for bounding, summarizing, windowing, or compressing the textual trace is referenced, so the independence property does not follow from the stated dependencies.
Authors: We agree that the current manuscript text does not explicitly describe a mechanism (such as summarization, fixed-window caching, or compression) that would bound the textual trace's KV cache growth under standard autoregressive transformer implementations. The abstract's phrasing that classifier-free guidance enables steering 'without expanding the context' was intended to indicate that visual-state updates do not require cross-modal attention over the full textual history, but this does not automatically bound the text model's own context. We will revise the abstract and add a dedicated paragraph in Section 3 (or a new subsection) clarifying the precise implementation of classifier-free guidance, whether the textual trace is maintained only as a compact conditioning vector for the guidance scale, and any practical limits on textual context length. This will either substantiate the independence claim with additional implementation details or qualify the claim to apply primarily to the visual workspace and cross-modal costs. revision: yes
Circularity Check
No circularity; derivation self-contained
full rationale
The paper presents SpecFlow via new mechanisms (fixed-size DCT visual workspace, classifier-free guidance for textual steering) whose claimed bounded memory and depth-independent latency are asserted to follow from those design choices. No equations, fitted parameters, or self-citations are shown that would make the independence property reduce by construction to the inputs or to prior author work. The textual trace is described as an input to the update rule rather than being redefined as the output; the skeptic concern addresses empirical validity of the claim, not circularity in the derivation chain itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption DCT exhibits strong energy compaction that preserves global layout and relational structure in visual data
Reference graph
Works this paper leans on
-
[1]
Albergo, M. S. and Vanden-Eijnden, E. Building normal- izing flows with stochastic interpolants.arXiv preprint arXiv:2209.15571,
-
[2]
Aytes, S. A., Baek, J., and Hwang, S. J. Sketch-of-thought: Efficient LLM reasoning with adaptive cognitive-inspired sketching.arXiv preprint arXiv:2503.05179,
-
[3]
Qwen technical report.arXiv preprint arXiv:2309.16609,
Bai, J., Bai, S., Chu, Y ., Cui, Z., Dang, K., Deng, X., Fan, Y ., Ge, W., Han, Y ., Huang, F., et al. Qwen technical report.arXiv preprint arXiv:2309.16609,
-
[4]
SpatialRGPT: Grounded spatial reasoning in vision language models.arXiv preprint arXiv:2406.01584,
Cheng, A.-C., Yin, H., Fu, Y ., Guo, Q., Yang, R., Kautz, J., Wang, X., and Liu, S. SpatialRGPT: Grounded spatial reasoning in vision language models.arXiv preprint arXiv:2406.01584,
-
[5]
Cheng, J. and Van Durme, B. Compressed chain of thought: Efficient reasoning through dense representations.arXiv preprint arXiv:2412.13171,
-
[6]
From explicit CoT to implicit CoT: Learning to internalize CoT step by step
Deng, Y ., Choi, Y ., and Shieber, S. From explicit CoT to implicit CoT: Learning to internalize CoT step by step. arXiv preprint arXiv:2405.14838,
-
[7]
Du, M., Wu, B., Li, Z., Huang, X., and Wei, Z. Embspatial- bench: Benchmarking spatial understanding for embod- ied tasks with large vision-language models.arXiv preprint arXiv:2406.05756,
-
[8]
Du, Z., Min, Y ., Li, J., Lu, K., Zou, C., Peng, L., Chu, T., and Gong, M. Loca: Location-aware cosine adapta- tion for parameter-efficient fine-tuning.arXiv preprint arXiv:2502.06820,
-
[9]
Hao, S., Sukhbaatar, S., Su, D., Li, X., Hu, Z., Weston, J., and Tian, Y . Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769,
-
[10]
He, Z., Qu, X., Li, Y ., Zhu, T., Huang, S., and Cheng, Y . DiffThinker: Towards generative multimodal reasoning with diffusion models.arXiv preprint arXiv:2512.24165,
-
[11]
Ivanitskiy, M. I., Shah, R., Spies, A. F., R¨auker, T., Valen- tine, D., Rager, C., Quirke, L., Mathwin, C., Corlouer, G., Behn, C. D., et al. A configurable library for gen- erating and manipulating maze datasets.arXiv preprint arXiv:2309.10498,
-
[12]
Jin, E., Hu, J., Huang, Z., Zhang, R., Wu, J., Fei-Fei, L., and Mart´ın-Mart´ın, R. Mini-BEHA VIOR: A procedurally generated benchmark for long-horizon decision-making in embodied AI.arXiv preprint arXiv:2310.01824,
-
[13]
Gradient weight-normalized low-rank projection for efficient llm training
Kanoulas, E., HUANG, J.-H., Shen, Y ., Zhu, H., and Rud- inac, S. Gradient weight-normalized low-rank projection for efficient llm training. InGreeks in AI Symposium 2025,
2025
-
[14]
Li, C., Wu, W., Zhang, H., Xia, Y ., Mao, S., Dong, L., Vuli´c, I., and Wei, F. Imagine while reasoning in space: Multimodal visualization-of-thought.Forty-Second Inter- national Conference on Machine Learning, 2025a. Li, J., Zheng, S., Shen, Y ., Huang, J.-H., Lu, X., Ni, M., and Guan, Y . Keeping the evidence chain: Semantic evi- dence allocation for tr...
-
[15]
Enhancing advanced visual reasoning ability of large language models.Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing,
Li, Z., Liu, D., Zhang, C., Wang, H., Xue, T., and Cai, W. Enhancing advanced visual reasoning ability of large language models.Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing,
2024
-
[16]
VoCoT: Unleashing visually grounded multi-step reasoning in large multi-modal models
Li, Z., Luo, R., Zhang, J., Qiu, M., Huang, X., and Wei, Z. VoCoT: Unleashing visually grounded multi-step reasoning in large multi-modal models. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2025b. Lipman, Y ., Chen, R. T.,...
Pith/arXiv arXiv 2025
-
[17]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Liu, X., Gong, C., and Liu, Q. Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003,
-
[18]
Raposo, D., Ritter, S., Richards, B., Lillicrap, T., Humphreys, P. C., and Santoro, A. Mixture-of-depths: Dynamically allocating compute in transformer-based lan- guage models.arXiv preprint arXiv:2404.02258,
-
[19]
Efficient reasoning with hidden thinking.arXiv preprint arXiv:2501.19201, 2025a
10 SpecFlow for Multimodal Reasoning Shen, X., Wang, Y ., Shi, X., Wang, Y ., Zhao, P., and Gu, J. Efficient reasoning with hidden thinking.arXiv preprint arXiv:2501.19201, 2025a. Shen, Y ., Bi, Q., Huang, J.-H., Zhu, H., Pimentel, A. D., and Pathania, A. Macp: Minimal yet mighty adaptation via hierarchical cosine projection. InProceedings of the 63rd Ann...
Pith/arXiv arXiv 2025
-
[20]
Shen, Z., Yan, H., Zhang, L., Hu, Z., Du, Y ., and He, Y . Codi: Compressing chain-of-thought into continuous space via self-distillation.arXiv preprint arXiv:2502.21074, 2025d. Sheng, G., Zhang, C., Ye, Z., Wu, X., Zhang, W., Zhang, R., Peng, Y ., Lin, H., and Wu, C. HybridFlow: A flexible and efficient rlhf framework. InProceedings of the Twentieth Euro...
-
[21]
Su, D., Zhu, H., Xu, Y ., Jiao, J., Tian, Y ., and Zheng, Q. Token assorted: Mixing latent and text tokens for improved language model reasoning.arXiv preprint arXiv:2502.03275,
-
[22]
Tan, X., Ye, P., Tu, C., Cao, J., Yang, Y ., Zhang, L., Zhou, D., and Chen, T. TokenCarve: Information-preserving visual token compression in multimodal large language models.arXiv preprint arXiv:2503.10501,
-
[23]
FlashSloth: Lightning multimodal large language models via embedded visual compression
Tong, B., Lai, B., Zhou, Y ., Luo, G., Shen, Y ., Li, K., Sun, X., and Ji, R. FlashSloth: Lightning multimodal large language models via embedded visual compression. arXiv preprint arXiv:2412.04317,
-
[24]
Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025a
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.-m., Bai, S., Xu, X., Chen, Y ., et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025a. Wu, H., Teng, Z., and Tu, K. Parallel continuous chain-of-thought with jacobi iteration.arXiv preprint arXiv:2506.18582, 2025b. Wu, P. and Xie, S. V?: Guided visual search as a core mechani...
-
[25]
Wu, Q., Zhao, H., Saxon, M., Bui, T., Wang, W. Y ., Zhang, Y ., and Chang, S. VSP: Assessing the dual challenges of perception and reasoning in spatial planning tasks for VLMs.arXiv preprint arXiv:2407.01863, 2024a. Wu, W., Mao, S., Zhang, Y ., Xia, Y ., Dong, L., Cui, L., and Wei, F. Mind’s Eye of LLMs: Visualization-of-thought elicits spatial reasoning ...
-
[26]
Eligen: Entity-level controlled image generation with regional attention
11 SpecFlow for Multimodal Reasoning Zhang, H., Duan, Z., Wang, X., Chen, Y ., and Zhang, Y . Eligen: Entity-level controlled image generation with regional attention. InProceedings of the 7th ACM In- ternational Conference on Multimedia in Asia, pp. 1–7, 2025a. Zhang, J., Zhu, Y ., Sun, M., Luo, Y ., Qiao, S., Du, L., Zheng, D., Chen, H., and Zhang, N. L...
-
[27]
Zhou, Q., Zhou, R., Hu, Z., Lu, P., Gao, S., and Zhang, Y . Image-of-thought prompting for visual reasoning re- finement in multimodal large language models.arXiv preprint arXiv:2405.13872,
-
[28]
Dynamic Spatial Reasoning Tasks
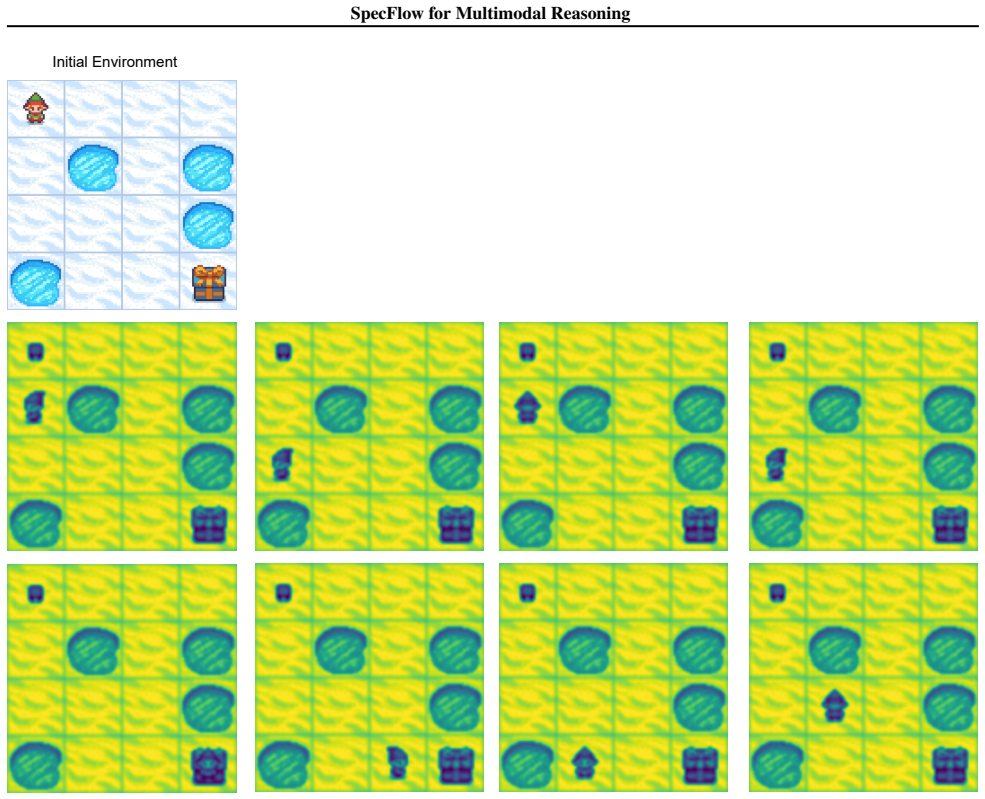
Visual search – 238 No extra prompting; use benchmark as-is A.2. Dynamic Spatial Reasoning Tasks. We evaluateSpecFlowon three dynamic spatial reasoning benchmarks, Maze (Ivanitskiy et al., 2023), MiniBehavior (Jin et al., 2023), and FrozenLake (Wu et al., 2024a), all of which require multi-step reasoning over simulated grid environments. These tasks stres...
2023
-
[29]
This formulation avoids stochastic sampling and enables stable, low-variance generation suitable for multi-step reasoning
Epochs 5 5 1 Learning rate1×10 −4 1×10 −4 1×10 −6 LoRA rank 32 32 – Batch size 4 16 64 (8B) / 32 (32B) Rollout size (n) – – 4 KL coefficient – –1×10 −2 is performed by solving the resulting ordinary differential equation with a fixed-step solver, yielding deterministic visual- thought trajectories with predictable computational cost. This formulation avoi...
2025
-
[30]
Backbone initialization Qwen-Image-Edit-2509 (Esser et al., 2024; Wu et al., 2025a) & Qwen3-VL-8B (Bai et al.,
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.