Learning fMRI activations dictionaries across individual geometries via optimal transport
Pith reviewed 2026-05-21 06:35 UTC · model grok-4.3
The pith
A dictionary learning method for fMRI uses optimal transport to handle differences in individual brain geometries without projecting to a template.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By combining the Fused Gromov-Wasserstein distance with amortized neural approximation of transport plans, dictionary atoms that depend on the FGW trade-off parameter can be learned for graphs with different geometries and features; numerical experiments on the HCP dataset show that the approach captures different levels of geometric variability in the data and provides representations that preserve essential information.
What carries the argument
The Fused Gromov-Wasserstein distance, which compares graphs with different geometries and features by balancing feature alignment and structural consistency, together with amortized optimization that trains a neural network to predict approximate optimal transport plans.
If this is right
- Dictionary atoms depend on the trade-off parameter that controls the balance between feature alignment and structural consistency.
- The amortized neural approximation makes repeated FGW computations feasible on large fMRI graphs.
- The learned representations capture different levels of geometric variability across subjects.
- Essential information for downstream tasks such as classification is preserved in the representations.
Where Pith is reading between the lines
- Retaining subject-specific geometry could improve accuracy in population-level analyses that currently lose individual detail through template alignment.
- The same amortized transport approximation might reduce cost when applying dictionary learning to other mismatched graph datasets, such as connectomes from different species.
- Downstream models trained on these representations may generalize better to new subjects because geometric variability is explicitly modeled rather than removed.
Load-bearing premise
That the Fused Gromov-Wasserstein distance combined with amortized neural approximation of transport plans is sufficient to learn dictionaries whose atoms meaningfully depend on the trade-off parameter while remaining computationally tractable for fMRI-scale graphs.
What would settle it
An experiment showing that the learned dictionary atoms do not change meaningfully with the FGW trade-off parameter or that the resulting representations fail to preserve essential information better than those obtained by projecting brains to a common template.
Figures









read the original abstract
Dictionary learning is a powerful tool for creating interpretable representations. When applied to functional magnetic resonance imaging (fMRI) data, the resulting patterns of brain activity can be used for various downstream tasks, such as brain state classification or population-level analysis. However, a major challenge is the variability in brain geometry across individuals. This is usually addressed by projecting each individual brain geometry onto a common template, which removes subject-specific information. In this work, we introduce a novel approach to dictionary learning on fMRI data that explicitly accounts for this variability. We use the optimal transport-based Fused Gromov-Wasserstein (FGW) distance to compare graphs with different geometries and features. To address the challenge of computing multiple FGW distances for large graphs such as those arising from fMRI data, we rely on amortized optimization to learn a neural network that predicts an approximation of the optimal transport plans, which substantially reduces the computational cost. Additionally, we learn dictionary atoms that depend on the FGW trade-off parameter, which controls the balance between feature alignment and structural consistency. Numerical experiments on the HCP dataset demonstrate that the proposed approach captures different levels of geometric variability in the data and provides representations that preserve essential information.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a dictionary learning method for fMRI data that uses the Fused Gromov-Wasserstein (FGW) distance to compare graphs with varying individual brain geometries and node features. It addresses computational cost on large HCP-scale graphs via amortized neural-network approximation of transport plans and makes dictionary atoms explicitly dependent on the FGW trade-off parameter that balances feature alignment against structural consistency. Experiments on the HCP dataset are claimed to show that the resulting representations capture different levels of geometric variability while preserving essential information for downstream tasks.
Significance. If the numerical claims hold, the work provides a principled way to retain subject-specific geometric information in fMRI dictionary learning instead of projecting onto a common template, which could improve interpretability and performance in population-level analyses and brain-state classification. The combination of FGW with amortization is a technically interesting extension of optimal-transport tools to neuroimaging graphs.
major comments (2)
- [§3.2] §3.2 (amortized FGW approximation): the central claim that dictionary atoms 'meaningfully depend on the trade-off parameter' while remaining tractable requires that the neural-network predictor preserves sensitivity to the FGW balance parameter. No approximation-error bounds, ablation against exact FGW solvers, or sensitivity plots on representative HCP graph sizes are reported, leaving open the possibility that amortization bias erases the intended dependence on the trade-off parameter.
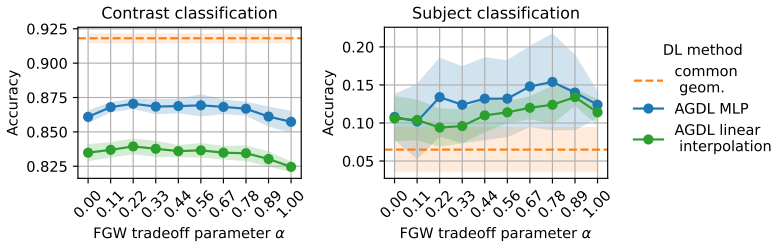
- [§4] §4 (numerical experiments on HCP): the abstract asserts that the method 'captures different levels of geometric variability,' yet the provided description contains no quantitative metrics, error bars, ablation studies, or baseline comparisons (e.g., against template-based dictionary learning). Without these, it is impossible to assess whether the learned atoms actually vary controllably with the trade-off parameter or merely reflect post-hoc choices.
minor comments (2)
- [§2] The notation for the FGW objective and the precise manner in which the trade-off parameter enters the dictionary-learning loss should be stated explicitly, ideally with an equation reference.
- [§4] Figure captions and axis labels in the experimental section should indicate which values of the trade-off parameter are shown and how variability is quantified.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help clarify how to better demonstrate the properties of the amortized FGW approximation and the experimental results. We address each major point below and will revise the manuscript to incorporate additional evidence where feasible.
read point-by-point responses
-
Referee: [§3.2] §3.2 (amortized FGW approximation): the central claim that dictionary atoms 'meaningfully depend on the trade-off parameter' while remaining tractable requires that the neural-network predictor preserves sensitivity to the FGW balance parameter. No approximation-error bounds, ablation against exact FGW solvers, or sensitivity plots on representative HCP graph sizes are reported, leaving open the possibility that amortization bias erases the intended dependence on the trade-off parameter.
Authors: We agree that explicit verification of sensitivity is important. The neural network is conditioned on the trade-off parameter α as an explicit input, and the training objective directly minimizes discrepancy to exact FGW plans; this design choice is intended to retain dependence on α. However, we acknowledge the absence of dedicated sensitivity analysis and ablations in the current version. In the revision we will add (i) sensitivity plots of atom variation across α for both the amortized predictor and exact FGW on representative HCP subgraph sizes, and (ii) an ablation comparing reconstruction and downstream performance when using the amortized versus exact solver on smaller instances. Theoretical approximation-error bounds are not currently available and would require substantial additional analysis beyond the scope of the present work. revision: partial
-
Referee: [§4] §4 (numerical experiments on HCP): the abstract asserts that the method 'captures different levels of geometric variability,' yet the provided description contains no quantitative metrics, error bars, ablation studies, or baseline comparisons (e.g., against template-based dictionary learning). Without these, it is impossible to assess whether the learned atoms actually vary controllably with the trade-off parameter or merely reflect post-hoc choices.
Authors: The current manuscript presents qualitative visualizations of atoms at different α values together with qualitative downstream-task preservation, but we concur that quantitative support is needed to substantiate the claims. In the revised version we will include (i) quantitative metrics such as atom stability across α, reconstruction error on held-out subjects, and brain-state classification accuracy with error bars, (ii) direct comparisons against a standard template-based dictionary-learning baseline, and (iii) ablation results showing performance as a function of the trade-off parameter. These additions will make the controllability of geometric variability explicit and allow readers to evaluate the claims quantitatively. revision: yes
- Theoretical approximation-error bounds for the neural-network FGW predictor
Circularity Check
No circularity; established OT machinery applied to new domain with independent amortization
full rationale
The derivation relies on the pre-existing Fused Gromov-Wasserstein distance (external to this paper) to compare graphs, with an amortized neural network introduced as a separate computational approximation to enable scaling. Dictionary atoms are explicitly parameterized by the trade-off parameter as a controllable input rather than derived tautologically from fitted outputs. Experiments on the external HCP dataset provide validation outside the method's own equations. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations appear in the chain.
Axiom & Free-Parameter Ledger
free parameters (1)
- FGW trade-off parameter
axioms (1)
- domain assumption Optimal transport plans exist and can be approximated by a neural network for the graph sizes arising in fMRI parcellations.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
L_α(G1,G2,P)=(1-α)∑‖F1_i−F2_j‖²P_ij + α∑|(C1_ik−C2_jl)|²P_ij P_kl
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We use amortized optimization to learn a neural network that predicts an approximation of the optimal transport plans
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Optuna: A next-generation hyperparameter optimization framework
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. Optuna: A next-generation hyperparameter optimization framework. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2019
work page 2019
-
[2]
Tutorial on amortized optimization.Foundations and Trends® in Machine Learning, 16(5):592–732, 2023
Brandon Amos et al. Tutorial on amortized optimization.Foundations and Trends® in Machine Learning, 16(5):592–732, 2023
work page 2023
-
[3]
Nilearn contributors. nilearn
-
[4]
Gorgolewski, Demian Wassermann, Bertrand Thirion, and Arthur Mensch
Kamalaker Dadi, Gaël Varoquaux, Antonia Machlouzarides-Shalit, Krzysztof J. Gorgolewski, Demian Wassermann, Bertrand Thirion, and Arthur Mensch. Fine-grain atlases of functional modes for fmri analysis.NeuroImage, 221:117126, 2020
work page 2020
-
[5]
Learning the parts of objects by non-negative matrix factorization.Nature, 401:788– 791, 1999
D Daniel. Learning the parts of objects by non-negative matrix factorization.Nature, 401:788– 791, 1999
work page 1999
-
[6]
Sparse dictionary learning of resting state fmri networks
Harini Eavani, Roman Filipovych, Christos Davatzikos, Theodore D Satterthwaite, Raquel E Gur, and Ruben C Gur. Sparse dictionary learning of resting state fmri networks. In2012 Second International Workshop on Pattern Recognition in NeuroImaging, pages 73–76. IEEE, 2012
work page 2012
-
[7]
Freesurfer.Neuroimage, 62(2):774–781, 2012
Bruce Fischl. Freesurfer.Neuroimage, 62(2):774–781, 2012
work page 2012
-
[8]
Individual variability of the system-level organization of the human brain.Cereb
Evan M Gordon, Timothy O Laumann, Babatunde Adeyemo, and Steven E Petersen. Individual variability of the system-level organization of the human brain.Cereb. Cortex, 27(1):386–399, January 2017
work page 2017
-
[9]
Independent component analysis
Aapo Hyvärinen, Jarmo Hurri, and Patrik O Hoyer. Independent component analysis. In Natural image statistics: A probabilistic approach to early computational vision, pages 151–
-
[10]
Asif Iqbal, Abd-Krim Seghouane, and Tülay Adalı. Shared and subject-specific dictionary learning (shssdl) algorithm for multisubject fmri data analysis.IEEE Transactions on Biomedical Engineering, 65(11):2519–2528, 2018
work page 2018
-
[11]
Muhammad Usman Khalid and Malik Muhammad Nauman. A novel subject-wise dictionary learning approach using multi-subject fmri spatial and temporal components.Scientific Reports, 13(1):20201, 2023
work page 2023
-
[12]
Jinglei Lv, Xi Jiang, Xiang Li, Dajiang Zhu, Hanbo Chen, Tuo Zhang, Shu Zhang, Xintao Hu, Junwei Han, Heng Huang, et al. Sparse representation of whole-brain fmri signals for identification of functional networks.Medical image analysis, 20(1):112–134, 2015
work page 2015
-
[13]
Online dictionary learning for sparse coding
Julien Mairal, Francis Bach, Jean Ponce, and Guillermo Sapiro. Online dictionary learning for sparse coding. InProceedings of the 26th annual international conference on machine learning, pages 689–696, 2009
work page 2009
-
[14]
Sonia Mazelet, Rémi Flamary, and Bertrand Thirion. Unsupervised learning for optimal transport plan prediction between unbalanced graphs.arXiv preprint arXiv:2506.12025, 2025
-
[15]
Arthur Mensch, Julien Mairal, Bertrand Thirion, and Gaël Varoquaux. Stochastic Subsampling for Factorizing Huge Matrices.IEEE Transactions on Signal Processing, 66(1):113–128, January 2018
work page 2018
-
[16]
Gromov-wasserstein averaging of kernel and distance matrices
Gabriel Peyré, Marco Cuturi, and Justin Solomon. Gromov-wasserstein averaging of kernel and distance matrices. InInternational conference on machine learning, pages 2664–2672. PMLR, 2016
work page 2016
-
[17]
Hui Shen, Huaze Xu, Lubin Wang, Yu Lei, Liu Yang, Peng Zhang, Jian Qin, Ling-Li Zeng, Zongtan Zhou, Zheng Yang, et al. Making group inferences using sparse representation of resting-state functional mri data with application to sleep deprivation.Human brain mapping, 38(9):4671–4689, 2017. 11
work page 2017
-
[18]
Dorina Thanou, David I Shuman, and Pascal Frossard. Learning parametric dictionaries for signals on graphs.IEEE Transactions on Signal Processing, 62(15):3849–3862, 2014
work page 2014
-
[19]
Bertrand Thirion, Alexis Thual, and Ana Luísa Pinho. From deep brain phenotyping to functional atlasing.Current Opinion in Behavioral Sciences, 40:201–212, August 2021
work page 2021
-
[20]
Which fmri clustering gives good brain parcellations?Frontiers in neuroscience, 8:167, 2014
Bertrand Thirion, Gaël Varoquaux, Elvis Dohmatob, and Jean-Baptiste Poline. Which fmri clustering gives good brain parcellations?Frontiers in neuroscience, 8:167, 2014
work page 2014
-
[21]
Alexis Thual, Quang Huy Tran, Tatiana Zemskova, Nicolas Courty, Rémi Flamary, Stanislas Dehaene, and Bertrand Thirion. Aligning individual brains with fused unbalanced gromov wasserstein.Advances in neural information processing systems, 35:21792–21804, 2022
work page 2022
-
[22]
Dictionary learning.IEEE Signal Processing Magazine, 28(2):27–38, 2011
Ivana Toši´c and Pascal Frossard. Dictionary learning.IEEE Signal Processing Magazine, 28(2):27–38, 2011
work page 2011
-
[23]
D C Van Essen, K Ugurbil, E Auerbach, D Barch, T E J Behrens, R Bucholz, A Chang, L Chen, M Corbetta, S W Curtiss, S Della Penna, D Feinberg, M F Glasser, N Harel, A C Heath, L Larson-Prior, D Marcus, G Michalareas, S Moeller, R Oostenveld, S E Petersen, F Prior, B L Schlaggar, S M Smith, A Z Snyder, J Xu, E Yacoub, and WU-Minn HCP Consortium. The human c...
work page 2012
-
[24]
The wu-minn human connectome project: an overview.Neuroimage, 80:62–79, 2013
David C Van Essen, Stephen M Smith, Deanna M Barch, Timothy EJ Behrens, Essa Yacoub, Kamil Ugurbil, Wu-Minn HCP Consortium, et al. The wu-minn human connectome project: an overview.Neuroimage, 80:62–79, 2013
work page 2013
-
[25]
Multi-subject dictionary learning to segment an atlas of brain spontaneous activity
Gaël Varoquaux, Alexandre Gramfort, Fabian Pedregosa, Vincent Michel, and Bertrand Thirion. Multi-subject dictionary learning to segment an atlas of brain spontaneous activity. InBien- nial International Conference on information processing in medical imaging, pages 562–573. Springer, 2011
work page 2011
-
[26]
Fused gromov-wasserstein distance for structured objects.Algorithms, 13(9):212, 2020
Titouan Vayer, Laetitia Chapel, Rémi Flamary, Romain Tavenard, and Nicolas Courty. Fused gromov-wasserstein distance for structured objects.Algorithms, 13(9):212, 2020
work page 2020
-
[27]
Online graph dictionary learning
Cédric Vincent-Cuaz, Titouan Vayer, Rémi Flamary, Marco Corneli, and Nicolas Courty. Online graph dictionary learning. InInternational conference on machine learning, pages 10564–10574. PMLR, 2021
work page 2021
-
[28]
Jianwen Xie, Pamela K Douglas, Ying Nian Wu, Arthur L Brody, and Ariana E Anderson. Decoding the encoding of functional brain networks: An fmri classification comparison of non-negative matrix factorization (nmf), independent component analysis (ica), and sparse coding algorithms.Journal of neuroscience methods, 282:81–94, 2017
work page 2017
-
[29]
Gromov-wasserstein learning for graph matching and node embedding
Hongteng Xu, Dixin Luo, Hongyuan Zha, and Lawrence Carin Duke. Gromov-wasserstein learning for graph matching and node embedding. InInternational conference on machine learning, pages 6932–6941. PMLR, 2019. A AGDL algorithm and amortized ULOT training A.1 AGDL algorithm The algorithm used for AGDL is described in Algorithm 1, and the unmixing step is desc...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.