SPADE: Split-and-Delay Embeddings for Autoregressive High-Granularity Calorimeter Simulation
Pith reviewed 2026-06-27 10:34 UTC · model grok-4.3
The pith
SPADE splits multi-feature tokens into independent streams and delays them so standard self-attention learns intra-token correlations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
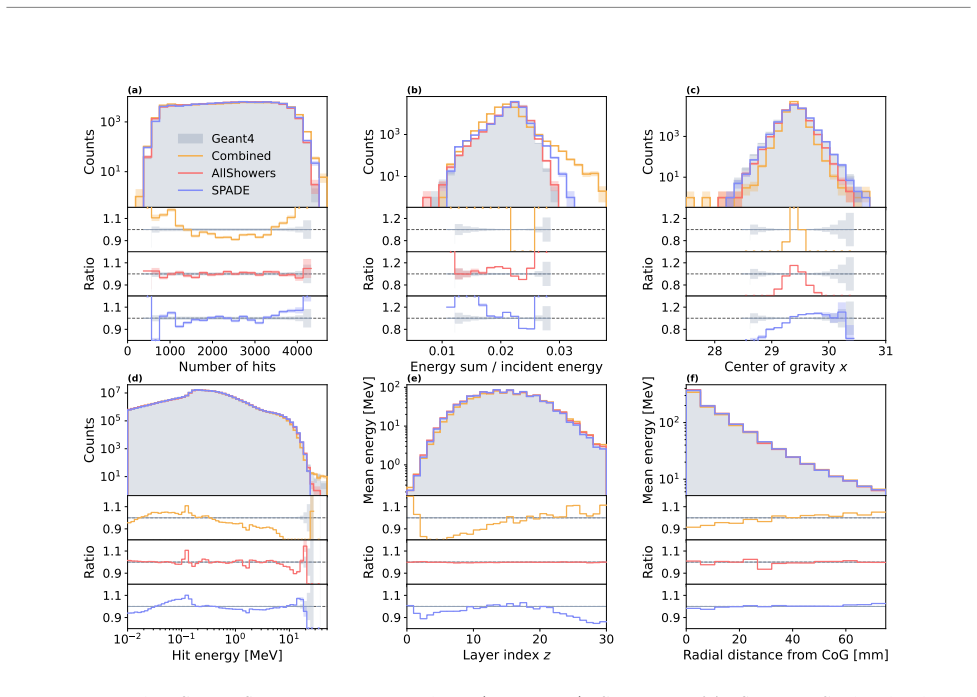
SPADE embeds each feature of a multi-feature token independently and delays each feature stream relative to the previous one. This offset allows the standard self-attention layers of an autoregressive transformer to learn the correlations that exist inside each token. Applied to point-cloud generation of calorimeter showers in the highly granular ILD detector, the resulting model is competitive with AllShowers on photon showers and substantially outperforms its VQ-VAE predecessor OmniJet-α_C. The same construction works for any generative task whose tokens carry multiple features.
What carries the argument
Split-and-delay embeddings: independent per-feature embedding streams that are shifted relative to one another so that standard self-attention can capture intra-token dependencies.
If this is right
- Any autoregressive generator that produces tokens with multiple internal features can use the same embedding offset without new architectural components.
- LLM-style pretraining pipelines become directly applicable to data whose tokens are higher-dimensional.
- Calorimeter simulation workflows can adopt the method for other particle types and detector geometries that output point clouds.
- The approach removes the need for custom intra-token modeling layers in multi-feature sequence tasks.
Where Pith is reading between the lines
- The delay technique may simplify training when tokens contain correlated variables from different physical units.
- The same offset pattern could be tested on molecular graph generation or multivariate time-series forecasting.
- Because the transformer backbone stays unchanged, scaling laws observed in language models may transfer more directly to these new domains.
Load-bearing premise
Offsetting the independent feature streams is sufficient for ordinary self-attention to learn the correlations between features that belong to the same token.
What would settle it
Training an otherwise identical model with split embeddings but no delay and measuring whether it requires extra loss terms or specialized layers to reach the same shower-generation fidelity on ILD photon data.
Figures

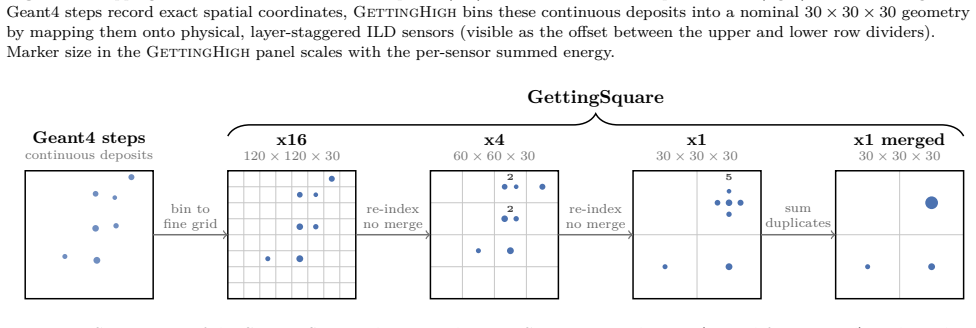
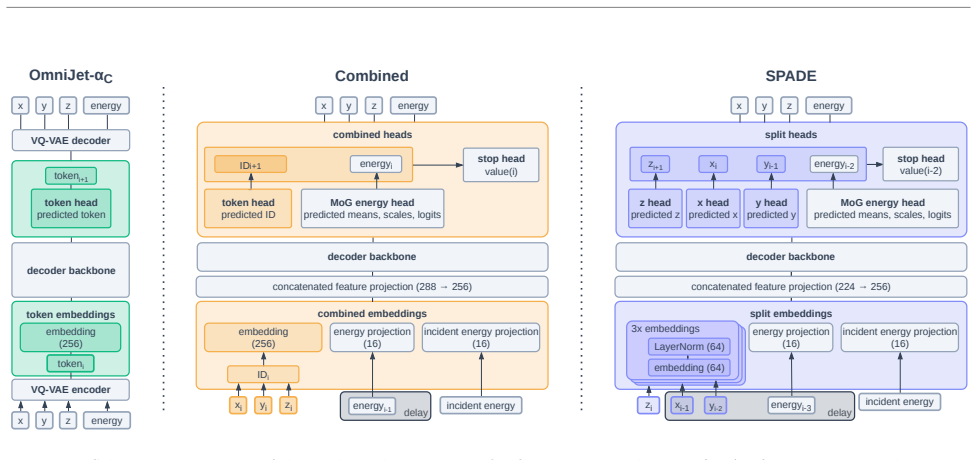


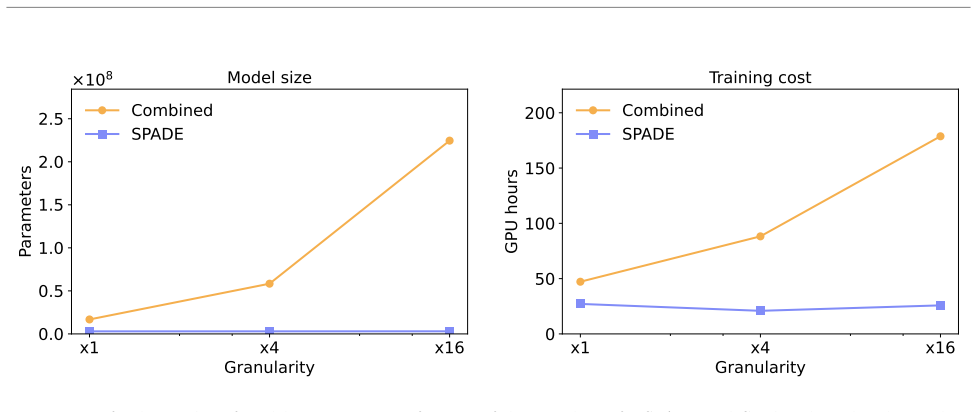
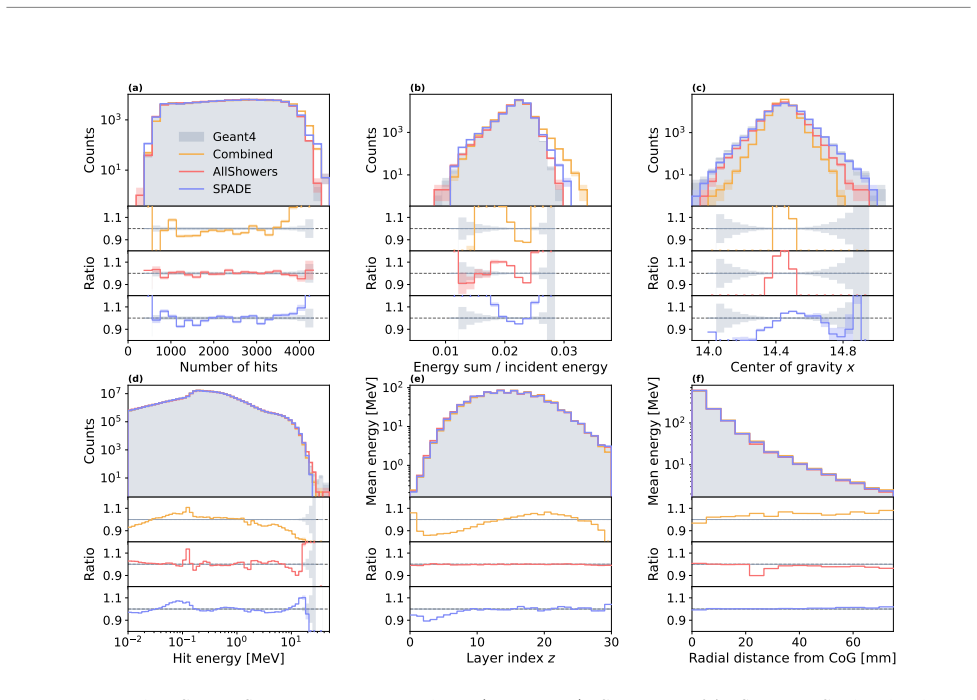





read the original abstract
We introduce SPADE (SPlit And Delay Embeddings), an autoregressive transformer for sequences whose tokens carry multiple features. Rather than embedding these features jointly, SPADE embeds them independently. Delaying each feature stream relative to the previous one allows intra-token correlations to be learned by the standard self-attention mechanism. Applied to point-cloud calorimeter shower generation in the highly granular ILD detector, SPADE is competitive with the state of the art AllShowers model on photon showers, and substantially outperforms its VQ-VAE-based predecessor OmniJet-$\alpha_C$. The mechanism is applicable to any generative task with multi-feature tokens, enabling LLM-style pretraining workflows for higher-dimensional data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SPADE (SPlit And Delay Embeddings), an autoregressive transformer for sequences whose tokens carry multiple features. Features are embedded independently rather than jointly; each feature stream is delayed relative to the previous one so that intra-token correlations can be captured by standard self-attention. The architecture is applied to point-cloud generation of electromagnetic showers in the highly granular ILD calorimeter. On photon showers the model is reported to be competitive with the AllShowers baseline and to substantially outperform the VQ-VAE-based predecessor OmniJet-α_C. The construction is presented as a general mechanism applicable to any generative task involving multi-feature tokens.
Significance. If the empirical results hold, SPADE supplies a minimal architectural modification that enables standard self-attention to model intra-token dependencies without auxiliary layers or loss terms. This could simplify autoregressive modeling of high-dimensional point-cloud data and support LLM-style pretraining workflows in calorimeter simulation and related domains. The concrete benchmark on ILD photon showers provides a falsifiable test of the central modeling assumption.
minor comments (3)
- [Abstract] Abstract: performance claims are stated without any numerical values, error bars, or dataset size; adding a single sentence summarizing the key metrics would improve readability.
- [Methods] The description of the delay operation (how many positions each stream is shifted and how this interacts with the causal mask) should be accompanied by a small diagram or explicit pseudocode in the methods section.
- [Results] Table or figure captions for the ILD photon-shower results should explicitly list the number of showers, the energy range, and the exact metric definitions used for the AllShowers and OmniJet-α_C comparisons.
Simulated Author's Rebuttal
We thank the referee for their positive summary and significance assessment of the SPADE manuscript. The recommendation of minor revision is noted. No major comments were raised in the report.
Circularity Check
No significant circularity identified
full rationale
The paper presents an architectural innovation (independent feature embeddings with relative delays in an autoregressive transformer) and reports empirical benchmark results on ILD photon showers against AllShowers and OmniJet-α_C. No equations, derivations, or first-principles claims are made that reduce by construction to fitted parameters or self-citations. The central claims are performance comparisons, which are external to any internal definitions and do not invoke uniqueness theorems, ansatzes smuggled via citation, or renaming of known results. The modeling choice (standard self-attention suffices after delay) is tested directly by the reported experiments rather than assumed.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
One Generator, Any Process: LLM-Conditioning for the LHC
LLM embeddings condition generative networks for LHC events, yielding faster convergence, higher quality, and generalization to unseen processes.
Reference graph
Works this paper leans on
-
[1]
Agostinelli Set al.(GEANT4) 2003Nucl. Instrum. Meth.A506250–303
-
[2]
Albrecht Jet al.2019Computing and Software for Big Science3ISSN 2510-2044 URLhttp://dx.doi. org/10.1007/s41781-018-0018-8
-
[3]
Boehnlein A, Biscarat C, Bressan A, Britton D, Bolton R, Gaede F, Grandi C, Hernandez F, Kuhr T, Merino G, Simon F and Watts G 2022 HL-LHC Software and Computing Review Panel, 2nd Report Tech. rep. CERN Geneva URLhttps://cds.cern.ch/record/2803119
arXiv 2022
-
[4]
Paganini M, de Oliveira L and Nachman B 2018Phys. Rev. Lett.120042003 (Preprinthttps://arxiv. org/abs/1705.02355)
-
[5]
Paganini M, de Oliveira L and Nachman B 2018Phys. Rev. D97014021 (Preprinthttps://arxiv.org/ abs/1712.10321)
-
[6]
de Oliveira L, Paganini M and Nachman B 2018J. Phys. Conf. Ser.1085042017 (Preprinthttps: //arxiv.org/abs/1711.08813)
-
[7]
Erdmann M, Geiger L, Glombitza J and Schmidt D 2018Comput. Softw. Big Sci.24 (Preprinthttps: //arxiv.org/abs/1802.03325)
-
[8]
Erdmann M, Glombitza J and Quast T 2019Comput. Softw. Big Sci.34 (Preprinthttps://arxiv.org/ abs/1807.01954)
-
[9]
Musella P and Pandolfi F 2018Comput. Softw. Big Sci.28 (Preprinthttps://arxiv.org/abs/1805. 00850)
-
[10]
Belayneh Det al.2020Eur. Phys. J. C80688 (Preprinthttps://arxiv.org/abs/1912.06794)
arXiv 1912
-
[11]
Butter A, Diefenbacher S, Kasieczka G, Nachman B and Plehn T 2021SciPost Phys.10139 (Preprint https://arxiv.org/abs/2008.06545)
arXiv 2008
-
[12]
ATLAS collaboration 2020-11 Fast simulation of the ATLAS calorimeter system with Generative Adver- sarial Networks techreport ATL-SOFT-PUB-2020-006 CERN (Preprinthttps://cds.cern.ch/record/ 2746032)
2020
-
[13]
ATLAS Collaboration 2020J. Phys. Conf. Ser.1525012077
-
[14]
ATLAS Collaboration 2022Comput. Softw. Big Sci.67 (Preprinthttps://arxiv.org/abs/2109.02551)
-
[15]
ATLAS Collaboration 2024Comput. Softw. Big Sci.87 (Preprinthttps://arxiv.org/abs/2210.06204)
-
[16]
Faucci Giannelli M and Zhang R 2024Eur. Phys. J. Plus139597 (Preprinthttps://arxiv.org/abs/ 2309.06515)
-
[17]
Simsek E, Isildak B, Dogru A, Aydogan R, Bayrak A B and Ertekin S 2024PTEP2024083C01 (Preprint https://arxiv.org/abs/2401.02248)
-
[18]
Cresswell J C, Ross B L, Loaiza-Ganem G, Reyes-Gonzalez H, Letizia M and Caterini A L 2022-11 Calo- Man: Fast generation of calorimeter showers with density estimation on learned manifolds36th Conference on Neural Information Processing Systems: Workshop on Machine Learning and the Physical Sciences (Preprinthttps://arxiv.org/abs/2211.15380)
arXiv 2022
-
[19]
Hoque S, Jia H, Abhishek A, Fadaie M, Toledo-Marín J Q, Vale T, Melko R G, Swiatlowski M and Fedorko W T 2024Eur. Phys. J. C841244 (Preprinthttps://arxiv.org/abs/2312.03179)
-
[20]
Liu Q, Shimmin C, Liu X, Shlizerman E, Li S and Hsu S C 2024-05 Calo-VQ: Vector-Quantized Two-Stage Generative Model in Calorimeter Simulation (Preprinthttps://arxiv.org/abs/2405.06605)
arXiv 2024
-
[21]
Krause C and Shih D 2023Phys. Rev. D107113003 (Preprinthttps://arxiv.org/abs/2106.05285) 17
-
[22]
Krause C and Shih D 2023Phys. Rev. D107113004 (Preprinthttps://arxiv.org/abs/2110.11377)
-
[23]
Schnake S, Krücker D and Borras K 2022 Generating calorimeter showers as point clouds36th Conference on Neural Information Processing Systems: Workshop on Machine Learning and the Physical Sciences (Preprinthttps://ml4physicalsciences.github.io/2022/files/NeurIPS_ML4PS_2022_77.pdf)
2022
-
[24]
Krause C, Pang I and Shih D 2024SciPost Phys.16126 (Preprinthttps://arxiv.org/abs/2210.14245)
-
[25]
Xu A, Han S, Ju X and Wang H 2024JINST19P02003 (Preprinthttps://arxiv.org/abs/2303.10148)
-
[26]
Buckley M R, Krause C, Pang I and Shih D 2024Phys. Rev. D109033006 (Preprinthttps://arxiv. org/abs/2305.11934)
-
[27]
Pang I, Shih D and Raine J A 2024Phys. Rev. D109092009 (Preprinthttps://arxiv.org/abs/2308. 11700)
-
[28]
Ernst F, Favaro L, Krause C, Plehn T and Shih D 2025SciPost Phys.18081 (Preprinthttps://arxiv. org/abs/2312.09290)
-
[29]
Schnake S, Krücker D and Borras K 2024-03 CaloPointFlow II Generating Calorimeter Showers as Point Clouds (Preprinthttps://arxiv.org/abs/2403.15782)
arXiv 2024
-
[30]
Du H, Krause C, Mikuni V, Nachman B, Pang I and Shih D 2025Phys. Rev. D111076004 (Preprint https://arxiv.org/abs/2404.18992)
-
[31]
Majerz E, Dzwinel W and Kitowski J 2025-12 Inverse Autoregressive Flows for Zero Degree Calorimeter fast simulation39th Annual Conference on Neural Information Processing Systems: Includes Machine Learning and the Physical Sciences (ML4PS)(Preprinthttps://arxiv.org/abs/2512.20346)
arXiv 2025
-
[32]
MikuniVandNachmanB2022Phys. Rev. D106092009(Preprinthttps://arxiv.org/abs/2206.11898)
-
[33]
Acosta F T, Mikuni V, Nachman B, Arratia M, Karki B, Milton R, Karande P and Angerami A 2024 JINST19P05003 (Preprinthttps://arxiv.org/abs/2307.04780)
arXiv 2024
-
[34]
Mikuni V and Nachman B 2024JINST19P02001 (Preprinthttps://arxiv.org/abs/2308.03847)
-
[35]
Amram O and Pedro K 2023Phys. Rev. D108072014 (Preprinthttps://arxiv.org/abs/2308.03876)
-
[36]
Jiang C, Qian S and Qu H 2025SciPost Phys.18195 (Preprinthttps://arxiv.org/abs/2401.13162)
-
[37]
Kobylianskii D, Soybelman N, Dreyer E and Gross E 2024Phys. Rev. D110072003 (Preprinthttps: //arxiv.org/abs/2402.11575)
-
[38]
Jiang C, Qian S and Qu H 2024-04 BUFF: Boosted Decision Tree based Ultra-Fast Flow matching (Preprint https://arxiv.org/abs/2404.18219)
arXiv 2024
-
[39]
Favaro L, Ore A, Schweitzer S P and Plehn T 2025SciPost Phys.18088 (Preprinthttps://arxiv.org/ abs/2405.09629)
-
[40]
Hildebrandt R, Kourlitis E, Hashemi B, Bünstorf M, Meyer T, Boskov N, Kagan M, Rosenbaum D, Gan- guly S and Heinrich L 2026 Bricks: Compositional neural markov kernels for zero-shot radiation-matter simulation (Preprint2605.06591) URLhttps://arxiv.org/abs/2605.06591
Pith/arXiv arXiv 2026
-
[41]
Li W, Shao D Y, Shi H Z and Sun Y X 2026 Nested-gpt for variable-multiplicity parton showers: A case study in the resummation of non-global logarithms (Preprint2605.18360) URLhttps://arxiv.org/abs/ 2605.18360
Pith/arXiv arXiv 2026
-
[42]
Bommasani Ret al.2022 On the opportunities and risks of foundation models (Preprint2108.07258) URL https://arxiv.org/abs/2108.07258
Pith/arXiv arXiv 2022
-
[43]
Hallin A 2025 Foundation models for high-energy physics2nd European AI for Fundamental Physics Con- ference(Preprint2509.21434)
arXiv 2025
-
[44]
Birk J, Hallin A and Kasieczka G 2024Mach. Learn. Sci. Tech.5035031 (Preprint2403.05618) 18
-
[45]
Radford A, Narasimhan K, Salimans T and Sutskever I 2018 Improving language understanding by generative pre-training URLhttps://cdn.openai.com/research-covers/language-unsupervised/ language_understanding_paper.pdf
2018
-
[46]
van den Oord A, Vinyals O and Kavukcuoglu K 2018 Neural discrete representation learning (Preprint 1711.00937)
Pith/arXiv arXiv 2018
-
[47]
Bao H, Dong L, Piao S and Wei F 2022 BEiT: BERT Pre-Training of Image Transformers (Preprint 2106.08254)
Pith/arXiv arXiv 2022
-
[48]
Huh M, Cheung B, Agrawal P and Isola P 2023 Straightening out the straight-through estimator: Over- coming optimization challenges in vector quantized networks (Preprint2305.08842)
arXiv 2023
-
[49]
Birk J, Gaede F, Hallin A, Kasieczka G, Mozzanica M and Rose H 2025JINST20P07007 (Preprint 2501.05534)
-
[50]
Cardona-GiraldoC,FanelliC,GirouxJ,GrangerC,NachmanBandSabinG2026Generalizablefoundation models for calorimetry via mixtures-of-experts and parameter efficient fine tuning (Preprint2603.28804) URLhttps://arxiv.org/abs/2603.28804
-
[51]
CopetJ,KreukF,GatI,RemezT,KantD,SynnaeveG,AdiYandDéfossezA2024Simpleandcontrollable music generation (Preprint2306.05284) URLhttps://arxiv.org/abs/2306.05284
-
[52]
Buss T, Day-Hall H, Gaede F, Kasieczka G and Krüger K 2026 AllShowers: One model for all calorimeter showers (Preprint2601.11716)
arXiv 2026
-
[53]
Buhmann E, Diefenbacher S, Eren E, Gaede F, Kasieczka G, Korol A and Krüger K 2021Comput. Softw. Big Sci.513 (Preprint2005.05334)
-
[54]
Frank M, Gaede F, Grefe C and Mato P 2014Journal of Physics: Conference Series513022010 URL https://doi.org/10.1088/1742-6596/513/2/022010
-
[55]
Abramowicz Het al.(ILD Concept Group) 2020 International Large Detector: Interim Design Report (Preprint2003.01116)
arXiv 2020
-
[56]
Suehara Tet al.2018JINST13C03015 (Preprint1801.02024)
-
[57]
Ba J L, Kiros J R and Hinton G E 2016 Layer normalization (Preprint1607.06450) URLhttps://arxiv. org/abs/1607.06450
Pith/arXiv arXiv 2016
-
[58]
Bishop C 1994 Mixture density networks WorkingPaper 4288 Aston University copyright©1994, Christopher M. Bishop. This work is licensed under a Creative Commons Attribution-NonCommercial- NoDerivatives 4.0 International License (https://creativecommons.org/licenses/by-nc-nd/4.0/)
1994
-
[59]
Su J, Ahmed M, Lu Y, Pan S, Bo W and Liu Y 2024Neurocomputing568127063 ISSN 0925-2312 URL https://www.sciencedirect.com/science/article/pii/S0925231223011864
-
[60]
Shazeer N 2019 Fast transformer decoding: One writer, en heads (Preprint1911.02150)
Pith/arXiv arXiv 2019
-
[61]
Dao T, Fu D Y, Ermon S, Rudra A and Ré C 2022 Flashattention: Fast and memory-efficient exact attention with io-awarenessAdvances in Neural Information Processing Systemsvol 35 pp 10488–10500
2022
-
[62]
Dao T 2024 Flashattention-2: Faster attention with better parallelism and work partitioningThe Twelfth International Conference on Learning Representations
2024
-
[63]
Zhang M, Lucas J, Ba J and Hinton G E 2019 Lookahead optimizer: k steps forward, 1 step backAdvances in Neural Information Processing Systemsvol 32 ed Wallach H, Larochelle H, Beygelzimer A, d'Alché- Buc F, Fox E and Garnett R (Curran Associates, Inc.) URLhttps://proceedings.neurips.cc/paper_ files/paper/2019/file/90fd4f88f588ae64038134f1eeaa023f-Paper.pdf
2019
-
[64]
Liu L, Jiang H, He P, Chen W, Liu X, Gao J and Han J 2020 On the variance of the adaptive learning rate and beyondInternational Conference on Learning RepresentationsURLhttps://openreview.net/ forum?id=rkgz2aEKDr 19
2020
-
[65]
Tarvainen A and Valpola H 2018 Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results (Preprint1703.01780) URLhttps://arxiv.org/ abs/1703.01780
Pith/arXiv arXiv 2018
-
[66]
Heneka C, Nieser F, Ore A, Plehn T and Schiller D 2026SciPost Phys.20070 (Preprint2506.14757)
-
[67]
Buhmann E, Diefenbacher S, Eren E, Gaede F, Kasicezka G, Korol A, Korcari W, Krüger K and McKe- own P 2023Journal of Instrumentation18P11025 ISSN 1748-0221 URLhttp://dx.doi.org/10.1088/ 1748-0221/18/11/P11025 20
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.