The Curse of Multiple Mediators: Hidden Interaction Effects in Activation Patching
Pith reviewed 2026-06-29 01:44 UTC · model grok-4.3
The pith
Activation patching's natural indirect effect includes hidden interaction effects between model components.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
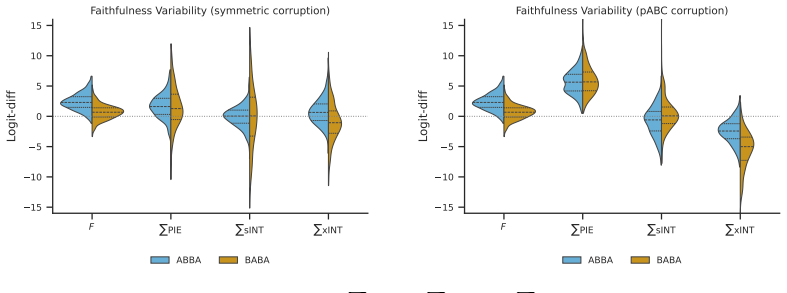
Re-deriving the activation patching estimand from causal mediation analysis reveals that the natural indirect effect (NIE) decomposes into the component's isolated causal effect plus interaction effects (INT) that quantify how much the component's effect itself depends on the states of other components. In the GPT-2 IOI circuit this produces components whose causal importance is conditional and therefore invisible or inflated under standard patching, while INT variance accounts for previously observed instability in faithfulness scores. INT scales directly with activation distance between clean and patched runs, vanishes when the model is locally affine, and factors combinatorially into pair
What carries the argument
The decomposition of the natural indirect effect (NIE) into direct causal effect plus interaction effects (INT) obtained by applying causal mediation analysis to activation patching.
Load-bearing premise
The causal mediation analysis decomposition of NIE into direct and interaction components applies without distortion to the specific intervention used in activation patching on transformer models.
What would settle it
Compute the isolated direct effect of a component while holding all other components at their clean values and compare the result to the NIE obtained by standard patching; a systematic difference matching the predicted INT term would confirm the decomposition.
Figures



read the original abstract
Activation patching is the primary tool in mechanistic interpretability. It attributes causal responsibility for a model behavior to each of its individual components by estimating its natural indirect effect (NIE). Re-deriving the activation patching estimand from causal mediation analysis, we find that the NIE does not solely capture the causal effect through the specific component. It also contains interaction effects (INT) that measure how much the component's causal effect itself depends on the state of other components in the model. A natural response may be to try to eliminate INT by adjusting the estimator or unit of analysis, but each of these potential remedies has predictable failure modes. We demonstrate these failure modes in the GPT-2 IOI circuit; components whose causal importance is conditional on the state of other components are either invisible or artificially inflated, and INT variance explains the previously documented instability of faithfulness scores. We prove that INT scales with the distance between clean and patched component activations, is negligible when the model is locally affine, and decomposes combinatorially into pairwise and higher-order group interactions. Despite its inevitability, INT is not a nuisance to be eliminated, but rather a diagnostic for interpretability studies. Its individual and group-level magnitude and sign signal when causal conclusions are prompt-dependent, and when greedy NIE-based component ranking will miss mechanisms only discoverable through combinatorial search.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that activation patching, which estimates the natural indirect effect (NIE) of a component on model behavior, actually captures both the component's direct causal effect and hidden interaction effects (INT) with other components. Re-deriving the estimand from causal mediation analysis, the authors prove that INT scales with the distance between clean and patched activations, is negligible when the model is locally affine, and combinatorially decomposes into pairwise and higher-order group interactions. They demonstrate in the GPT-2 IOI circuit that INT causes components to appear invisible or inflated under NIE-based analysis and explains instability in faithfulness scores, arguing that INT serves as a diagnostic for prompt-dependent causal conclusions rather than a quantity to eliminate.
Significance. If the central derivation and proofs hold, this is a significant contribution to mechanistic interpretability. Activation patching is the dominant causal attribution tool, and identifying that its NIE estimand systematically includes interaction effects explains documented instabilities and warns against greedy component ranking. Credit is due for the formal proofs of INT scaling and combinatorial decomposition (which yield falsifiable predictions) as well as the empirical demonstration on the established GPT-2 IOI circuit. The work reframes INT as a useful diagnostic rather than a nuisance, with potential to improve the reliability of causal claims in the field.
major comments (2)
- [Re-derivation of the activation patching estimand] The re-derivation of the activation patching estimand as NIE + INT (main text, causal mediation section) rests on the assumption that replacing one component's activation while holding others at observed values corresponds exactly to the do-operator on a single mediator with no interference. In transformer computation graphs, residual connections and attention mixing mean all components are computed jointly from the same input; this may violate the no-interference assumption underlying the standard NIE decomposition, potentially distorting the extracted INT term. A concrete test (e.g., invariance of INT under patching order or residual-stream ablations) is needed to confirm the mapping holds without distortion.
- [Proof that INT scales with distance and is negligible when locally affine] § on proof of INT scaling and local affinity: the claim that INT is negligible when the model is locally affine is load-bearing for the recommendation to treat INT as diagnostic rather than eliminable, but the proof sketch does not explicitly state the functional-form assumptions on the response surface or how the affine approximation is verified empirically in the GPT-2 experiments.
minor comments (2)
- [Abstract] Abstract: the acronym INT is introduced in the second sentence without an immediate parenthetical definition, which reduces readability for readers unfamiliar with mediation analysis.
- [Combinatorial decomposition] The combinatorial decomposition into pairwise and higher-order interactions is stated clearly but would benefit from an explicit small example (e.g., three-component case) to illustrate the group-level terms before the GPT-2 results.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the causal foundations and proof details of our work. We respond to each major comment below and will revise the manuscript accordingly where appropriate.
read point-by-point responses
-
Referee: [Re-derivation of the activation patching estimand] The re-derivation assumes replacing one component's activation while holding others corresponds to the do-operator on a single mediator with no interference. In transformers, residual connections and attention mixing may violate this, distorting INT. A concrete test (e.g., invariance under patching order or residual-stream ablations) is needed.
Authors: We model the transformer as a structural causal model in which component activations are the mediators, and the activation-patching intervention is defined directly on a single mediator while others take their observed (natural) values. This matches the standard NIE definition from causal mediation analysis; residual streams and attention are part of the joint structural equations but do not alter the interventional semantics at the mediator level. We agree a concrete check is valuable and will add a subsection with an empirical invariance test of INT estimates under varied patching orders on the GPT-2 IOI circuit, plus a brief discussion of the no-interference assumption in residual architectures. revision: yes
-
Referee: [Proof that INT scales with distance and is negligible when locally affine] The claim that INT is negligible when locally affine is load-bearing, but the proof sketch does not explicitly state the functional-form assumptions on the response surface or how the affine approximation is verified empirically in the GPT-2 experiments.
Authors: The local-affinity claim rests on a first-order Taylor expansion of the response surface (model output as a function of the mediators) around the clean activation point; under this approximation all second- and higher-order terms, including INT, vanish. We will expand the proof section to state the required differentiability and neighborhood-size assumptions explicitly. We will also add empirical verification in the GPT-2 experiments by reporting second-order finite-difference measures of nonlinearity to confirm that INT remains small precisely where the local affine condition holds. revision: yes
Circularity Check
No significant circularity; derivation applies standard mediation analysis to patching estimand
full rationale
The paper re-derives the activation patching estimand by applying the standard natural indirect effect (NIE) decomposition from causal mediation analysis, identifying an interaction term (INT) as a byproduct. This step relies on the existing mathematical framework of mediation analysis (independent of the present authors or fitted model parameters) rather than any self-definition, fitted-input prediction, or self-citation chain. No equations reduce the central claim to inputs by construction, and the proofs about INT scaling and decomposition are derived from the same external causal framework. The result is self-contained against external benchmarks in causal inference.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Causal mediation analysis framework applies directly to activation patching interventions in transformer models
Reference graph
Works this paper leans on
-
[1]
URLhttps://pubmed.ncbi.nlm.nih.gov/33512846/
doi: 10.1097/EDE.0000000000001313. URLhttps://pubmed.ncbi.nlm.nih.gov/33512846/. D. Arad, A. Mueller, and Y . Belinkov. SAEs are good for steering – if you select the right features. In C. Christodoulopoulos, T. Chakraborty, C. Rose, and V . Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 10241–1...
-
[2]
Association for Computational Linguistics. ISBN 979-8-89176-332-6. doi: 10.18653/v1/2025.emnlp-main.519. URL https://aclanthology.org/2025.emnlp-main. 519/. C. Avin, I. Shpitser, and J. Pearl. Identifiability of path-specific effects. InProceedings of the 19th International Joint Conference on Artificial Intelligence, IJCAI’05, page 357–363, San Francisco...
-
[3]
https://transformer-circuits.pub/2021/framework/index.html. M. Finlayson, A. Mueller, S. Gehrmann, S. Shieber, T. Linzen, and Y . Belinkov. Causal analysis of syntactic agreement mechanisms in neural language models. In C. Zong, F. Xia, W. Li, and R. Navigli, editors,Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics a...
2021
-
[4]
doi: 10.18653/v1/2021.acl-long.144
Association for Computational Linguistics. doi: 10.18653/v1/2021.acl-long.144. URL https://aclanthology.org/2021.acl-long. 144/. A. Geiger, H. Lu, T. F. Icard, and C. Potts. Causal abstractions of neural networks. In A. Beygelzimer, Y . Dauphin, P. Liang, and J. W. Vaughan, editors,Advances in Neural Information Processing Systems,
-
[5]
URLhttps://arxiv.org/abs/2304.05969. 10 R. Gupta, I. Arcuschin, T. Kwa, and A. Garriga-Alonso. Interpbench: Semi-synthetic trans- formers for evaluating mechanistic interpretability techniques. InThe Thirty-eight Confer- ence on Neural Information Processing Systems Datasets and Benchmarks Track,
-
[6]
URLhttps://arxiv.org/abs/2603.20101. M. Hanna, O. Liu, and A. Variengien. How does GPT-2 compute greater-than?: Interpreting mathe- matical abilities in a pre-trained language model. InThirty-seventh Conference on Neural Informa- tion Processing Systems,
-
[7]
URL https: //arxiv.org/abs/2404.15255. M. A. Ikram and T. J. VanderWeele. A proposed clinical and biological interpretation of mediated interaction.European journal of epidemiology, 30(10):1115–1118,
-
[8]
URLhttps://arxiv.org/abs/2506.12152. D. Lindner, J. Kramar, S. Farquhar, M. Rahtz, T. McGrath, and V . Mikulik. Tracr: Compiled trans- formers as a laboratory for interpretability. InThirty-seventh Conference on Neural Information Processing Systems,
-
[9]
URL https://openreview.net/ forum?id=I4e82CIDxv. M. Méloux, F. Portet, and M. Peyrard. Mechanistic interpretability as statistical estimation: A variance analysis of EAP-IG. InMechanistic Interpretability Workshop at NeurIPS 2025,
2025
-
[10]
URL https://openreview.net/forum?id= zSf8PJyQb2. A. Mueller. Missed causes and ambiguous effects: Counterfactuals pose challenges for interpreting neural networks. InICML 2024 Workshop on Mechanistic Interpretability,
2024
-
[11]
ISSN 0891-2017. doi: 10.1162/COLI.a.572. URLhttps://doi.org/10.1162/COLI.a.572. C. Olah, N. Cammarata, L. Schubert, G. Goh, M. Petrov, and S. Carter. Zoom in: An introduction to circuits.Distill,
-
[12]
https://distill.pub/2020/circuits/zoom-in
doi: 10.23915/distill.00024.001. https://distill.pub/2020/circuits/zoom-in. 11 M. Paunio, J. Höök-Nikanne, T. U. Kosunen, U. Vainio, M. Salaspuro, J. Mäkinen, and O. P. Heinonen. Association of alcohol consumption and helicobacter pylori infection in young adulthood and early middle age among patients with gastric complaints: A case-control study on finni...
-
[13]
doi: 10.1007/BF01730371. J. Pearl. Direct and indirect effects. InProceedings of the Seventeenth Conference on Uncertainty in Artificial Intelligence, UAI’01, page 411–420, San Francisco, CA, USA,
-
[14]
URLhttps://arxiv.org/abs/2602.02315. C. Shi, N. Beltran-Velez, A. Nazaret, C. Zheng, A. Garriga-Alonso, A. Jesson, M. Makar, and D. Blei. Hypothesis testing the circuit hypothesis in LLMs. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems,
-
[15]
Wang, L., Yang, N., Huang, X., Yang, L., Majumder, R., and Wei, F
Association for Computational Linguistics. doi: 10.18653/v1/ 2024.blackboxnlp-1.25. URLhttps://aclanthology.org/2024.blackboxnlp-1.25/. T. J. VanderWeele. A Three-way Decomposition of a Total Effect into Direct, Indirect, and Interactive Effects.Epidemiology, 24(2):224–232,
-
[16]
doi: 10.1097/EDE.0000000000000121. T. J. VanderWeele.Explanation in Causal Inference: Methods for Mediation and Interaction. Oxford University Press, New York,
-
[17]
URL https://proceedings.neurips.cc/ paper_files/paper/2020/file/92650b2e92217715fe312e6fa7b90d82-Paper.pdf. K. R. Wang, A. Variengien, A. Conmy, B. Shlegeris, and J. Steinhardt. Interpretability in the wild: a circuit for indirect object identification in GPT-2 small. InThe Eleventh International Conference on Learning Representations,
2020
-
[18]
12 A Proofs We reproduce the definition of the path-specific effect [Avin et al., 2005] for reference
URL https://openreview.net/forum?id= NpsVSN6o4ul. 12 A Proofs We reproduce the definition of the path-specific effect [Avin et al., 2005] for reference. Definition A.1(Path-Specific Effect).Fix a DAG G and let g⊆G be aneffect subgraphwith complement ¯g=G\g . Themodified model Mg is obtained from G by replacing each ¯g-parent of every nodeVwith its baselin...
2005
-
[19]
For R=C , the only superset of C in C is C itself, so the inner sum equals (−1)0 = 1, contributing Y(C) to the overall sum
We claim: f(C) =− X ∅̸=T ⊆C xINT(T)(5) Substituting the definition xINT(T) =− P R⊆T (−1)|T |−|R|Y(R) and exchanging the order of summation: X ∅̸=T ⊆C xINT(T) =− X ∅̸=T ⊆C X R⊆T (−1)|T |−|R|Y(R) =− X R⊆C Y(R) X T:R⊆T ⊆C T ̸=∅ (−1)|T |−|R| 15 We evaluate the inner sum by cases. For R=C , the only superset of C in C is C itself, so the inner sum equals (−1)0...
2023
-
[20]
All logit-diff units;N= 1000, pABC mean-ablation
behavioral profile. All logit-diff units;N= 1000, pABC mean-ablation. Head PIE±CI PIE rank NIE±CI NIE rank xINT(L9H9)±CI xINT(NMH)±CI Wang et al. [2023]profile L10H10+0.481±0.0314+0.133±0.01617−0.057±0.008 +0.027±0.016name-mover-likeL10H6+0.309±0.0405+0.213±0.02914−0.080±0.008−0.099±0.011name-mover-likeL10H1+0.257±0.0296+0.081±0.01726−0.021±0.005−0.017±0....
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.