PeakFocus: Bridging Peak Localization and Intensity Regression via a Unified Multi-Scale Framework for Electricity Load Forecasting
Pith reviewed 2026-05-22 00:24 UTC · model grok-4.3
The pith
PeakFocus unifies peak timing localization and intensity regression for electricity load forecasting using a multi-scale framework and location-aware decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
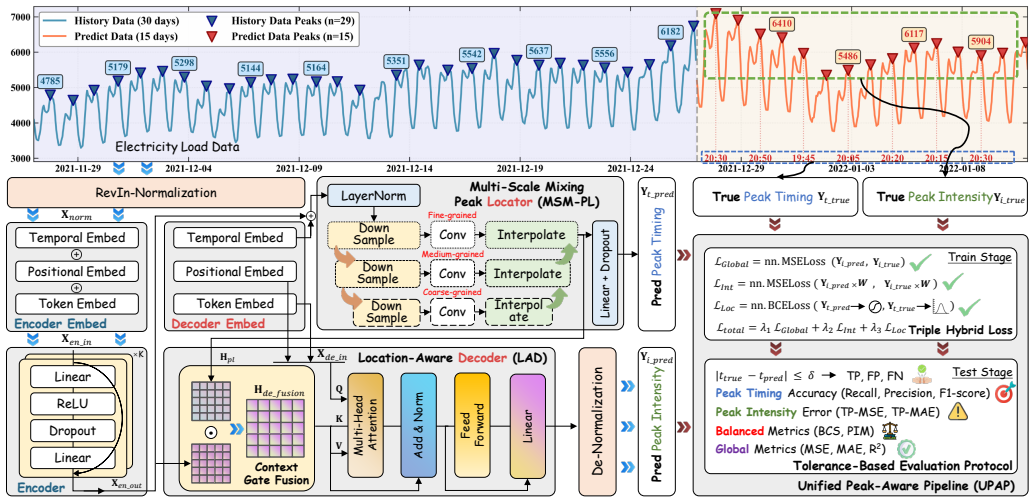
PeakFocus establishes a unified peak-aware pipeline that applies a triple hybrid loss to supervise temporal localization and intensity regression together. A Multi-Scale Mixing Peak Locator uses coarse features to reduce local-fluctuation misjudgments and cascades them into fine-grained features to fix timing misalignment. A Location-Aware Decoder then injects the resulting peak timing context into the intensity regression branch to counteract global smoothing and raise peak intensity accuracy.
What carries the argument
Unified Peak-Aware Pipeline that jointly optimizes localization and regression via triple hybrid loss, Multi-Scale Mixing Peak Locator for coarse-to-fine feature injection, and Location-Aware Decoder that supplies timing context to intensity estimation.
If this is right
- Grid operators can schedule reserves with tighter timing windows because peak occurrence and magnitude are estimated together.
- The tolerance-based evaluation protocol gives a practical success metric that tolerates small timing offsets rather than requiring exact matches.
- Multi-scale cascade injection can be reused in other time-series models where local noise masks rare high-value events.
- Explicit timing context supplied to regression reduces the dominance of average trends that otherwise flatten extreme values.
Where Pith is reading between the lines
- Similar joint localization-regression supervision could be tested on other peaky signals such as traffic surges or financial volatility spikes.
- The cascade mixing mechanism suggests that explicit coarse-to-fine pathways may help any multi-resolution time-series architecture that currently trains separate heads.
- If timing context proves useful for intensity, the reverse direction—using intensity estimates to refine localization—could be added as a further consistency constraint.
Load-bearing premise
Jointly supervising temporal localization and intensity regression with a triple hybrid loss plus multi-scale feature injection will fix peak misjudgment and intensity smoothing without creating new trade-offs or dataset-specific biases.
What would settle it
An ablation that removes the Location-Aware Decoder and measures whether peak intensity mean absolute error rises measurably on the WLEL dataset.
Figures






read the original abstract
Electricity load peak forecasting (ELPF), simultaneously predicting peak timing and intensity, is a prerequisite for effective grid scheduling and risk management. However, existing methods face three limitations. First, they adopt a two-stage predict-then-locate paradigm, which severs the link between temporal localization and intensity regression. Second, they still struggle with the multi-scale representation conflict, leading to peak misjudgment and timing misalignment. Third, the lack of explicit peak timing context during intensity regression causes intensity smoothing because predictions are dominated by global smoothing trends. To address these limitations, we propose PeakFocus, a unified framework for ELPF. (i) A Unified Peak-Aware Pipeline (UPAP) utilizes a triple hybrid loss to jointly supervise temporal localization and intensity regression, alongside a tolerance-based evaluation protocol. (ii) A Multi-Scale Mixing Peak Locator (MSM-PL) exploits coarse-grained features to mitigate peak misjudgment caused by local fluctuations, and injects them into fine-grained features via a cascade mechanism to resolve timing misalignment. (iii) A Location-Aware Decoder (LAD) injects peak timing context into the intensity regression process, providing explicit guidance to counteract intensity smoothing and improve peak intensity estimation. Extensive experiments on the public Electricity (ELC) dataset and our industrial-scale World Large-scale Electricity Load (WLEL) dataset show that PeakFocus outperforms baselines in both timing precision and intensity estimation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PeakFocus, a unified multi-scale framework for electricity load peak forecasting (ELPF) that simultaneously addresses peak timing localization and intensity regression. It proposes (i) a Unified Peak-Aware Pipeline (UPAP) employing a triple hybrid loss for joint supervision of localization and regression together with a tolerance-based evaluation protocol, (ii) a Multi-Scale Mixing Peak Locator (MSM-PL) that cascades coarse-grained features into fine-grained ones to reduce peak misjudgment and timing misalignment, and (iii) a Location-Aware Decoder (LAD) that injects explicit peak timing context into intensity regression to counteract smoothing. The central empirical claim is that PeakFocus outperforms existing baselines on both the public Electricity (ELC) dataset and the industrial-scale World Large-scale Electricity Load (WLEL) dataset in timing precision and intensity estimation.
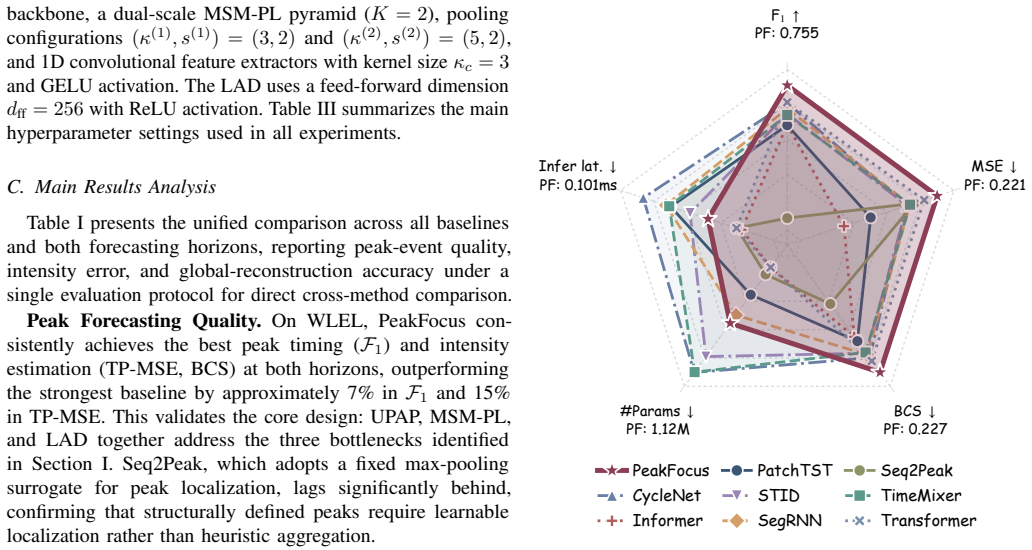
Significance. If the reported gains are substantiated by rigorous ablations, error bars, and statistical tests, the work would be significant for grid scheduling and risk management. A unified treatment of localization and regression could reduce the disconnect inherent in two-stage pipelines and yield more reliable peak forecasts on both public and large-scale industrial data.
major comments (2)
- [§4 (Experiments)] §4 (Experiments) and associated tables: the central claim of joint improvement in timing precision and intensity estimation on both ELC and WLEL rests on the unverified premise that the triple hybrid loss, MSM-PL cascade, and LAD produce net gains rather than compensating errors or dataset-specific tuning. No ablation results isolating each component (e.g., performance when the cascade injection or location context is removed) are referenced, leaving the 'no new trade-offs' assumption unsupported.
- [§3.1 (UPAP)] §3.1 (UPAP): the tolerance-based evaluation protocol is introduced as part of the joint supervision but its precise definition, threshold selection, and interaction with the triple hybrid loss are not shown to be parameter-free or robust across the two datasets; this directly affects reproducibility of the reported outperformance.
minor comments (2)
- [Abstract] Abstract: while the three limitations and three proposed modules are clearly enumerated, the abstract contains no numerical results, error bars, or baseline names, which is atypical for an empirical claim of outperformance.
- [Notation and figures] Notation and figures: ensure all acronyms (UPAP, MSM-PL, LAD) are expanded on first use in the main text and that multi-scale cascade diagrams include explicit feature-dimension labels for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the empirical support and reproducibility.
read point-by-point responses
-
Referee: [§4 (Experiments)] §4 (Experiments) and associated tables: the central claim of joint improvement in timing precision and intensity estimation on both ELC and WLEL rests on the unverified premise that the triple hybrid loss, MSM-PL cascade, and LAD produce net gains rather than compensating errors or dataset-specific tuning. No ablation results isolating each component (e.g., performance when the cascade injection or location context is removed) are referenced, leaving the 'no new trade-offs' assumption unsupported.
Authors: We agree that explicit ablations are necessary to confirm net gains rather than compensating effects. In the revised version we will add a dedicated ablation subsection in §4 that isolates each component: (i) UPAP without MSM-PL cascade, (ii) full model without LAD location injection, and (iii) variants with/without the triple hybrid loss. Results will be reported on both ELC and WLEL with error bars and paired statistical tests. revision: yes
-
Referee: [§3.1 (UPAP)] §3.1 (UPAP): the tolerance-based evaluation protocol is introduced as part of the joint supervision but its precise definition, threshold selection, and interaction with the triple hybrid loss are not shown to be parameter-free or robust across the two datasets; this directly affects reproducibility of the reported outperformance.
Authors: We will expand §3.1 with the exact formulation of the tolerance-based protocol, including the mathematical definition of tolerated timing windows and how the tolerance interacts with each term of the triple hybrid loss. We will also report the threshold selection procedure (cross-validation on a held-out validation split) and include a sensitivity table demonstrating stable performance across a range of tolerance values on both datasets. revision: yes
Circularity Check
No circularity: empirical model proposal validated on external datasets
full rationale
The paper proposes an architectural framework (UPAP with triple hybrid loss, MSM-PL cascade, LAD injection) and reports empirical gains on the public ELC dataset plus the authors' new WLEL dataset. No mathematical derivation chain, equations, or fitted parameters are shown that reduce the claimed timing/intensity improvements to the inputs by construction. The central claim rests on comparative experiments rather than self-definition, self-citation load-bearing, or renaming of known results. This is the normal case for an applied ML architecture paper; the derivation is self-contained against the reported benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MSM-PL exploits coarse-grained features to mitigate peak misjudgment... via a cascade mechanism... hierarchical architecture comprising a bottom-up pyramid and a top-down cascade
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LAD injects peak timing context into the intensity regression process... Context Gate Fusion... multi-head cross-attention
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
triple hybrid objective... Ltotal = λ1 LGlobal + λ2 LInt + λ3 LLoc... soft weight mask W generated using a truncated Gaussian kernel
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Informer: Beyond efficient transformer for long sequence time-series forecasting,
H. Zhou, S. Zhang, J. Peng, S. Zhang, J. Li, H. Xiong, and W. Zhang, “Informer: Beyond efficient transformer for long sequence time-series forecasting,” inAAAI, vol. 35, 2021, pp. 11 106–11 115
work page 2021
-
[2]
Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting,
H. Wu, J. Xu, J. Wang, and M. Long, “Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting,” in NeurIPS, vol. 34, 2021, pp. 22 419–22 430
work page 2021
-
[3]
TimeMixer: Decomposable multiscale mixing for time series forecasting,
S. Wang, H. Wu, X. Shi, T. Hu, H. Luo, L. Ma, J. Y . Zhang, and J. Zhou, “TimeMixer: Decomposable multiscale mixing for time series forecasting,” inICLR, 2024
work page 2024
-
[4]
Adaptive multi-scale decomposition framework for time series forecasting,
Y . Hu, P. Liu, P. Zhu, D. Cheng, and T. Dai, “Adaptive multi-scale decomposition framework for time series forecasting,” inAAAI, vol. 39, 2025, pp. 17 359–17 367
work page 2025
-
[5]
Deep Time Series Models: A Comprehensive Survey and Benchmark
Y . Wang, H. Wu, J. Dong, Y . Liu, C. Wang, M. Long, and J. Wang, “Deep time series models: A comprehensive survey and benchmark,” arXiv preprint arXiv:2407.13278, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Deep learning for time series forecasting: Tutorial and literature survey,
K. Benidis, S. S. Rangapuram, V . Flunkert, Y . Wang, D. Maddix, C. Turkmen, J. Gasthaus, M. Bohlke-Schneider, D. Salinas, L. Stella, F.-X. Aubet, L. Callot, and T. Januschowski, “Deep learning for time series forecasting: Tutorial and literature survey,”ACM Comput. Surv., vol. 55, no. 6, pp. 1–36, 2022
work page 2022
-
[7]
Daily peak electrical load forecasting with a multi-resolution approach,
Y . Amara-Ouali, M. Fasiolo, Y . Goude, and H. Yan, “Daily peak electrical load forecasting with a multi-resolution approach,”Int. J. Forecast., vol. 39, no. 3, pp. 1272–1286, 2023
work page 2023
-
[8]
S. Huang, T. Zhang, Z. Zhang, X. Wang, L. Wang, and X. Wang, “MetaEformer: Unveiling and leveraging meta-patterns for complex and dynamic systems load forecasting,” inKDD, 2025, pp. 991–1002
work page 2025
-
[9]
Electrical peak demand forecasting - A review,
S. Dai, F. Meng, H. Dai, Q. Wang, and X. Chen, “Electrical peak demand forecasting - A review,”arXiv preprint arXiv:2108.01393, 2021
-
[10]
Unlocking the potential of deep learning in peak-hour series forecasting,
Z. Zhang, X. Wang, J. Xie, H. Zhang, and Y . Gu, “Unlocking the potential of deep learning in peak-hour series forecasting,” inCIKM, 2023, pp. 4415–4419
work page 2023
-
[11]
Enhancing wind power forecasting at local peak points: A novel Seq2LPP model,
N. Zhu, Y . Wang, K. Yuan, Y . Pan, and K. Zhang, “Enhancing wind power forecasting at local peak points: A novel Seq2LPP model,”IEEE Trans. Ind. Informat., 2025, early Access
work page 2025
-
[12]
Reversible instance normalization for accurate time-series forecasting against distribution shift,
T. Kim, J. Kim, Y . Tae, C. Park, J.-H. Choi, and J. Choo, “Reversible instance normalization for accurate time-series forecasting against distribution shift,” inICLR, 2021
work page 2021
-
[13]
Spatial-temporal identity: A simple yet effective baseline for multivariate time series forecasting,
Z. Shao, Z. Zhang, F. Wang, and Y . Xu, “Spatial-temporal identity: A simple yet effective baseline for multivariate time series forecasting,” in CIKM, 2022, pp. 4455–4459
work page 2022
-
[14]
On the role of attention masks and LayerNorm in Transformers,
X. Wu, A. Ajorlou, Y . Wang, S. Jegelka, and A. Jadbabaie, “On the role of attention masks and LayerNorm in Transformers,” inNeurIPS, vol. 37, 2024, pp. 14 774–14 809
work page 2024
-
[15]
Feature pyramid networks for object detection,
T.-Y . Lin, P. Doll´ar, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” inCVPR, 2017, pp. 2117–2125
work page 2017
-
[16]
U-Net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-Net: Convolutional networks for biomedical image segmentation,” inMICCAI, 2015, pp. 234–241
work page 2015
-
[17]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” inNeurIPS, vol. 30, 2017
work page 2017
-
[18]
Focal loss for dense object detection,
T.-Y . Lin, P. Goyal, R. Girshick, K. He, and P. Doll ´ar, “Focal loss for dense object detection,” inICCV, 2017, pp. 2980–2988
work page 2017
-
[19]
Density- based weighting for imbalanced regression,
M. Steininger, K. Kobs, P. Davidson, A. Krause, and A. Hotho, “Density- based weighting for imbalanced regression,”Mach. Learn., vol. 110, pp. 2187–2211, 2021
work page 2021
-
[20]
Learning stationary time series using Gaussian processes with nonparametric kernels,
F. Tobar, T. D. Bui, and R. E. Turner, “Learning stationary time series using Gaussian processes with nonparametric kernels,” inNeurIPS, vol. 28, 2015
work page 2015
-
[21]
Complex event recognition in the big data era: a survey,
N. Giatrakos, E. Alevizos, A. Artikis, A. Deligiannakis, and M. N. Garofalakis, “Complex event recognition in the big data era: a survey,” VLDB J., vol. 29, no. 1, pp. 313–352, 2020
work page 2020
-
[22]
A time series is worth 64 words: Long-term forecasting with transformers,
Y . Nie, N. H. Nguyen, P. Sinthong, and J. Kalagnanam, “A time series is worth 64 words: Long-term forecasting with transformers,” inICLR, 2023
work page 2023
-
[23]
SegRNN: Segment recurrent neural network for long-term time series forecasting,
S. Lin, W. Lin, W. Wu, F. Zhao, R. Mo, and H. Zhang, “SegRNN: Segment recurrent neural network for long-term time series forecasting,” IEEE IoT J., vol. 13, no. 5, pp. 9861–9871, 2026
work page 2026
-
[24]
CycleNet: Enhancing time series forecasting through modeling periodic patterns,
S. Lin, W. Lin, X. Hu, W. Wu, R. Mo, and H. Zhong, “CycleNet: Enhancing time series forecasting through modeling periodic patterns,” inNeurIPS, vol. 37, 2024, pp. 106 315–106 345
work page 2024
-
[25]
W. Yu, D. Cheng, L. Zhu, and C. Jiang, “Large language models for time series analysis: Methodologies, applications, and emerging challenges,” TechRxiv, 2026
work page 2026
-
[26]
K. Zhu, C. Zhao, and B. Huang, “Breaking information granularity heterogeneity: A mutual information-inspired causal discovery framework for multi-rate time series,”IEEE TKDE, 2025
work page 2025
-
[27]
Unlocking the power of LSTM for long term time series forecasting,
Y . Kong, Z. Wang, Y . Nie, T. Zhou, S. Zohren, Y . Liang, P. Sun, and Q. Wen, “Unlocking the power of LSTM for long term time series forecasting,” inAAAI, vol. 39, 2025, pp. 11 968–11 976
work page 2025
-
[28]
Are Transformers effective for time series forecasting?
A. Zeng, M. Chen, L. Zhang, and Q. Xu, “Are Transformers effective for time series forecasting?” inAAAI, vol. 37, 2023, pp. 11 121–11 128
work page 2023
-
[29]
N-BEATS: Neural basis expansion analysis for interpretable time series forecasting,
B. N. Oreshkin, D. Carpov, N. Chapados, and Y . Bengio, “N-BEATS: Neural basis expansion analysis for interpretable time series forecasting,” inICLR, 2020
work page 2020
-
[30]
FEDformer: Frequency enhanced decomposed transformer for long-term series forecasting,
T. Zhou, Z. Ma, Q. Wen, X. Wang, L. Sun, and R. Jin, “FEDformer: Frequency enhanced decomposed transformer for long-term series forecasting,” inICML, 2022, pp. 27 268–27 286
work page 2022
-
[31]
iTrans- former: Inverted transformers are effective for time series forecasting,
Y . Liu, T. Hu, H. Zhang, H. Wu, S. Wang, L. Ma, and M. Long, “iTrans- former: Inverted transformers are effective for time series forecasting,” inICLR, 2024
work page 2024
-
[32]
TimesNet: Temporal 2D-variation modeling for general time series analysis,
H. Wu, T. Hu, Y . Liu, H. Zhou, J. Wang, and M. Long, “TimesNet: Temporal 2D-variation modeling for general time series analysis,” in ICLR, 2023
work page 2023
-
[33]
Pyraformer: Low-complexity pyramidal attention for long-range time series modeling and forecasting,
S. Liu, H. Yu, C. Liao, J. Li, W. Lin, A. X. Liu, and S. Dustdar, “Pyraformer: Low-complexity pyramidal attention for long-range time series modeling and forecasting,” inICLR, 2022
work page 2022
-
[34]
SCINet: Time series modeling and forecasting with sample convolution and interaction,
M. Liu, A. Zeng, M. Chen, Z. Xu, Q. Lai, L. Ma, and Q. Xu, “SCINet: Time series modeling and forecasting with sample convolution and interaction,” inNeurIPS, vol. 35, 2022, pp. 5816–5828
work page 2022
-
[35]
Multi-scale adaptive graph neural network for multivariate time series forecasting,
L. Chen, D. Chen, Z. Shang, B. Wu, C. Zheng, B. Wen, and W. Zhang, “Multi-scale adaptive graph neural network for multivariate time series forecasting,”IEEE TKDE, vol. 35, no. 10, pp. 10 748–10 761, 2023
work page 2023
-
[36]
Z. Shao, F. Wang, Y . Xu, W. Wei, C. Yu, Z. Zhang, D. Yao, T. Sun, G. Jin, X. Cao, G. Cong, C. S. Jensen, and X. Cheng, “Exploring progress in multivariate time series forecasting: Comprehensive benchmarking and heterogeneity analysis,”IEEE TKDE, vol. 37, no. 1, pp. 291–305, 2024
work page 2024
-
[37]
C. Liu, H. Miao, Q. Xu, S. Zhou, C. Long, Y . Zhao, Z. Li, and R. Zhao, “Efficient multivariate time series forecasting via calibrated language models with privileged knowledge distillation,” inICDE, 2025, pp. 3165– 3178
work page 2025
-
[38]
Towards spatio- temporal aware traffic time series forecasting,
R.-G. Cirstea, B. Yang, C. Guo, T. Kieu, and S. Pan, “Towards spatio- temporal aware traffic time series forecasting,” inICDE, 2022, pp. 2900– 2913
work page 2022
-
[39]
H. Miao, Y . Zhao, C. Guo, B. Yang, K. Zheng, F. Huang, J. Xie, and C. S. Jensen, “A unified replay-based continuous learning framework for spatio-temporal prediction on streaming data,” inICDE, 2024, pp. 1050–1062
work page 2024
-
[40]
Multi-step spatio-temporal forecasting with decoupled dynamic graphs,
K. Zhao, C. Guo, Y . Cheng, P. Han, M. Chen, and B. Yang, “Multi-step spatio-temporal forecasting with decoupled dynamic graphs,” inICDE, 2024, pp. 3142–3155
work page 2024
-
[41]
Robust and explainable autoencoders for unsupervised time series outlier detection,
T. Kieu, B. Yang, C. Guo, R.-G. Cirstea, Y . Zhao, Y . Song, and C. S. Jensen, “Robust and explainable autoencoders for unsupervised time series outlier detection,” inICDE, 2022, pp. 1342–1354
work page 2022
-
[42]
TimeFilter: Patch-specific spatial-temporal graph filtration for time series forecasting,
Y . Hu, G. Zhang, P. Liu, D. Lan, N. Li, D. Cheng, T. Dai, S.-T. Xia, and S. Pan, “TimeFilter: Patch-specific spatial-temporal graph filtration for time series forecasting,” inICML, 2025
work page 2025
-
[43]
Meta-learning for cross-region electricity load forecasting under distribution shift,
J. Hu, Y . Liu, C. Guo, B. Yang, and C. S. Jensen, “Meta-learning for cross-region electricity load forecasting under distribution shift,” inICDE, 2025, pp. 2018–2031
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.