Score times Decoder: A Unified View of Unsupervised Inference-Time Scaling for Hallucination Mitigation
Pith reviewed 2026-06-28 19:00 UTC · model grok-4.3
The pith
No intrinsic score for LLM outputs has fixed quality; its value depends on the paired decoder and model capability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
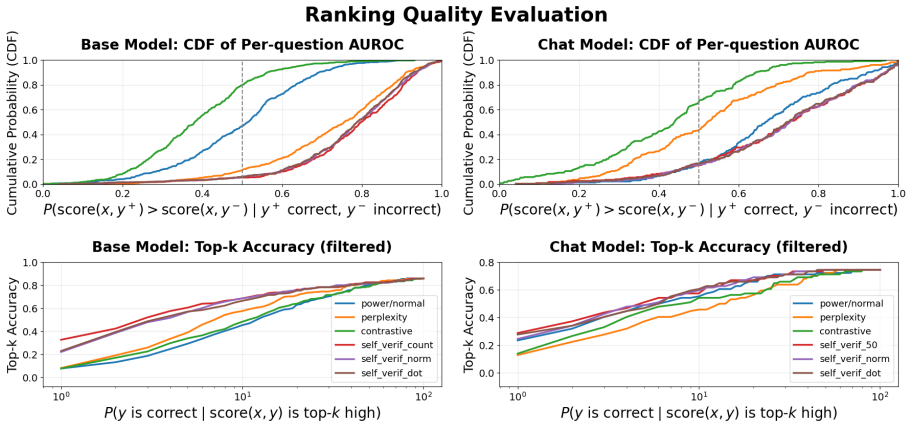
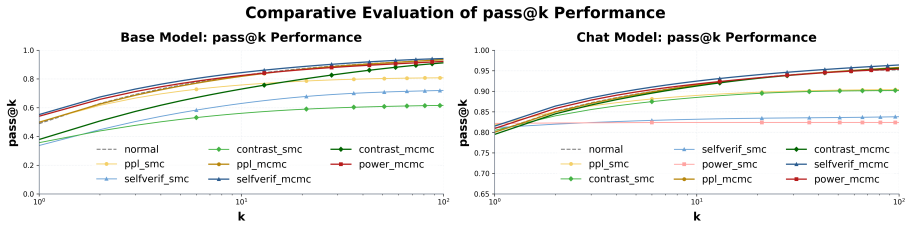
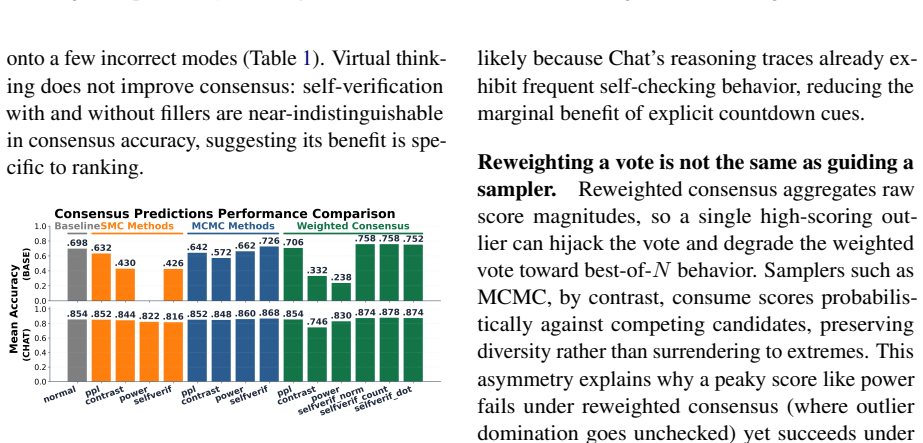
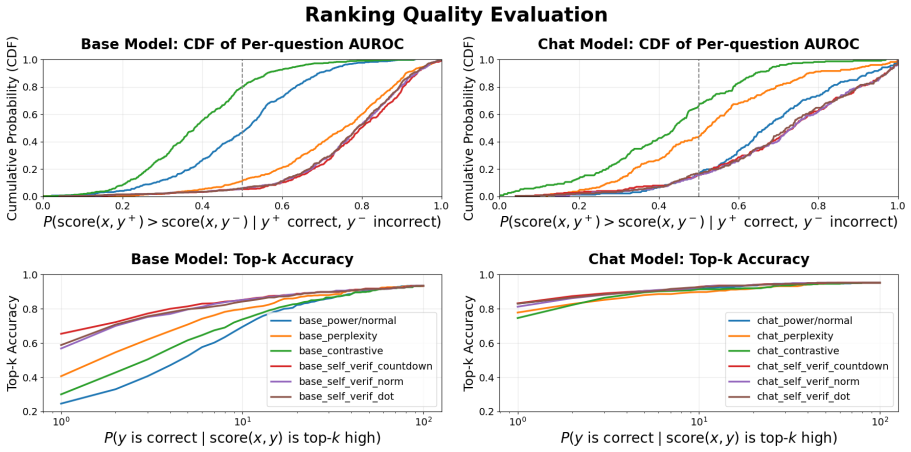
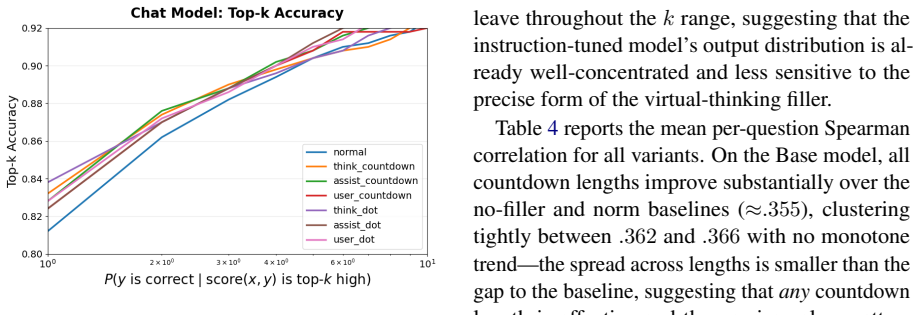
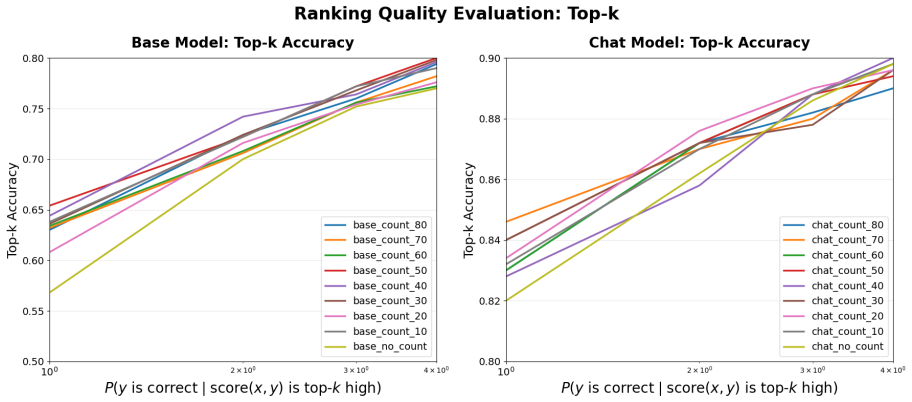
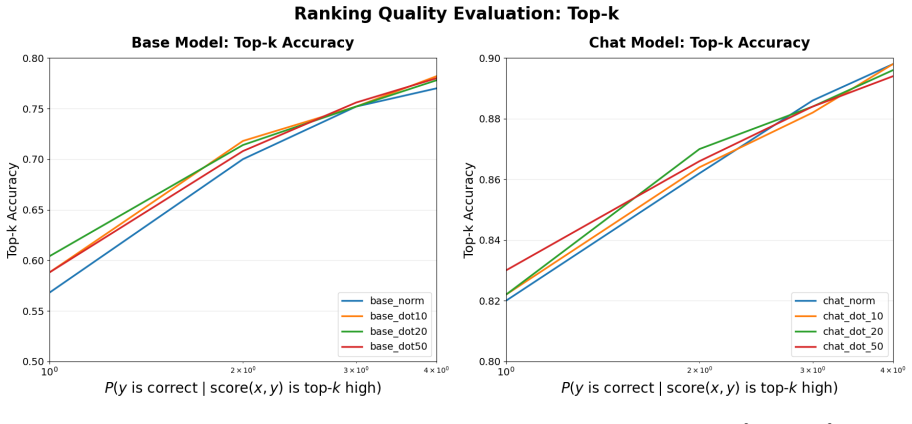
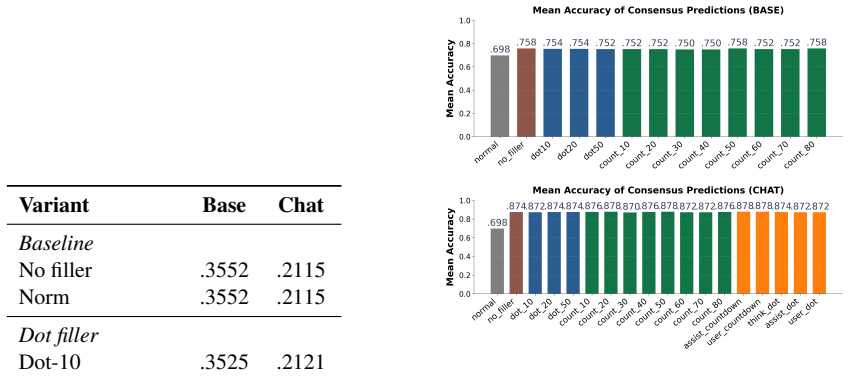
By casting unsupervised inference-time scaling as a score times decoder grid and evaluating every cell on MATH500 with both base and instruction-tuned Qwen3-1.7B, the work shows that self-verification, sharpened by a training-free virtual-thinking prefix, works well in most settings. No score possesses a fixed quality independent of the decoder that consumes it and of model capability. When no supervision is available the score and the decoding family must therefore be chosen together.
What carries the argument
Score times decoder grid: the systematic pairing of four scores (perplexity, contrastive, power-distribution likelihood, self-verification) with three decoding families (optimization, sampling, consensus) to measure their joint effect on output correctness.
If this is right
- Self-verification performs strongly across most decoder pairings and is improved by a virtual-thinking prefix.
- Score effectiveness changes depending on which decoding family is used.
- The same joint-selection requirement appears for both base and instruction-tuned models.
- Unsupervised hallucination mitigation requires co-design of score and decoder rather than treating either in isolation.
Where Pith is reading between the lines
- Testing the grid on non-mathematical tasks would reveal whether the dependence between score and decoder generalizes beyond reasoning problems.
- An adaptive selector that picks the decoder after seeing the score could be a direct next step from the observed interactions.
- Repeating the evaluation on larger models would test whether the dependence on model capability changes with scale.
Load-bearing premise
The patterns observed when testing four scores and three decoders on MATH500 with Qwen3-1.7B will hold for other models, datasets, and tasks.
What would settle it
Running the identical grid of scores and decoders on a second dataset such as GSM8K or with a different model family such as Llama would show whether the observed score-decoder interactions remain consistent.
Figures
read the original abstract
Large language models hallucinate even when the answer lies within their parameters. While inference-time scaling can surface this latent knowledge, the most effective methods require supervision: a trained verifier or reward model. We ask what can be done with only a base language model: which intrinsic signal best identifies correct outputs, and how should it be decoded? We cast this as a score~$\times$~decoder grid pairing four scores (perplexity, contrastive, power-distribution likelihood, and self-verification) with three decoding families (optimization, sampling, consensus), and evaluate every cell on MATH500 with the base and instruction-tuned Qwen3-1.7B. While self-verification, which prompts the model to judge its own answer and is sharpened by a training-free virtual-thinking prefix, works well in most settings, no score has a fixed quality: its value depends on the decoder that consumes it and on model capability. When no supervision is available, the score and the decoding family must be chosen together.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates a 4×3 grid of intrinsic scores (perplexity, contrastive, power-distribution likelihood, self-verification) paired with decoding families (optimization, sampling, consensus) for unsupervised inference-time scaling to reduce hallucinations. Using MATH500 and Qwen3-1.7B (base and instruction-tuned), it reports that self-verification performs well in most settings but that no score has fixed quality; its effectiveness depends on the decoder and model capability, so score and decoder must be selected jointly when supervision is unavailable.
Significance. If the observed score-decoder interactions hold more broadly, the work supplies a practical, supervision-free framework for inference-time methods and concrete data on relative performance across combinations. The systematic grid evaluation is a strength.
major comments (1)
- [Experimental evaluation] Experimental evaluation (MATH500 with Qwen3-1.7B base/IT): the central claim that score quality depends on model capability (and thus that score and decoder must always be chosen jointly) rests on comparisons between base and instruction-tuned variants of a single 1.7B model; no cross-family or cross-scale results are shown, so the prescriptive generalization is not supported by the data.
minor comments (1)
- [Abstract] Abstract: states that every cell was evaluated but supplies no details on exact metrics, statistical tests, error bars, or controls.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting the value of the systematic evaluation. We respond to the single major comment below.
read point-by-point responses
-
Referee: [Experimental evaluation] Experimental evaluation (MATH500 with Qwen3-1.7B base/IT): the central claim that score quality depends on model capability (and thus that score and decoder must always be chosen jointly) rests on comparisons between base and instruction-tuned variants of a single 1.7B model; no cross-family or cross-scale results are shown, so the prescriptive generalization is not supported by the data.
Authors: We agree that the experiments are limited to base and instruction-tuned variants of a single 1.7B model (Qwen3), which provides only one axis of capability variation. The observed differences in score effectiveness between these variants support the narrower claim that capability affects score quality within this setting, but do not justify the stronger prescriptive statement that score and decoder "must always be chosen jointly" across all models. We will revise the manuscript to qualify the language, framing the joint-selection recommendation as suggested by the evaluated cases rather than a universal requirement, and explicitly note the single-model-family limitation as a direction for future work. revision: yes
Circularity Check
Empirical grid evaluation with no derivations or fitted predictions
full rationale
The paper conducts a 4x3 grid of scores and decoders evaluated on MATH500 with Qwen3-1.7B (base and instruction-tuned). No equations, derivations, parameter fitting, or self-citation load-bearing steps are present in the provided text. The claim that score quality depends on decoder and capability is directly supported by the experimental outcomes rather than reducing to any input by construction. This is a standard self-contained empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374. Arnaud Doucet, Nando de Freitas, and Neil Gordon. 2001.An Introduction to Sequential Monte Carlo Methods, pages 3–14. Springer New York, New York, NY . Gonçalo R. A. Faria, Sweta Agrawal, António Farinhas, Ricardo Rei, José G. C. de Souza, and André F.T. Martins. 2024. Quest...
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[2]
arXiv preprint arXiv:2601.21590 , year=
Training large language models to reason in a continuous latent space. InSecond Conference on Language Modeling. Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. Measuring mathematical problem solving with the math dataset.NeurIPS. Xiaotong Ji, Rasul Tutunov, Matthieu Zimmer, and Ha...
-
[3]
InThe Twelfth Inter- national Conference on Learning Representations
Let’s verify step by step. InThe Twelfth Inter- national Conference on Learning Representations. João Loula, Benjamin LeBrun, Li Du, Ben Lipkin, Clemente Pasti, Gabriel Grand, Tianyu Liu, Yahya Emara, Marjorie Freedman, Jason Eisner, Ryan Cot- terell, Vikash Mansinghka, Alexander K. Lew, Tim Vieira, and Timothy J. O’Donnell. 2025. Syntactic and semantic c...
2025
-
[4]
InFirst Conference on Language Modeling
Let’s think dot by dot: Hidden computation in transformer language models. InFirst Conference on Language Modeling. Isha Puri, Shivchander Sudalairaj, Guangxuan Xu, Ab- hishek Bhandwaldar, Kai Xu, and Akash Srivastava
-
[5]
Rollout roulette: A probabilistic inference approach to inference-time scaling of llms using particle-based monte carlo methods. InAdvances in Neural Information Processing Systems, volume 38, pages 156427–156454. Curran Associates, Inc. Patrick Pynadath and Ruqi Zhang. 2025. Controlled LLM decoding via discrete auto-regressive biasing. InThe Thirteenth I...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
InProceed- ings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa- pers), pages 9426–9439, Bangkok, Thailand
Math-shepherd: Verify and reinforce LLMs step-by-step without human annotations. InProceed- ings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa- pers), pages 9426–9439, Bangkok, Thailand. Associ- ation for Computational Linguistics. Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang...
2023
-
[7]
InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
Sampling-efficient test-time scaling: Self- estimating the best-of-n sampling in early decoding. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. Yixuan Weng, Minjun Zhu, Fei Xia, Bin Li, Shizhu He, Shengping Liu, Bin Sun, Kang Liu, and Jun Zhao
-
[8]
InFindings of the Associa- tion for Computational Linguistics: EMNLP 2023, pages 2550–2575, Singapore
Large language models are better reasoners with self-verification. InFindings of the Associa- tion for Computational Linguistics: EMNLP 2023, pages 2550–2575, Singapore. Association for Com- putational Linguistics. Yuxi Xie, Kenji Kawaguchi, Yiran Zhao, James Xu Zhao, Min-Yen Kan, Junxian He, and Michael Xie
2023
-
[9]
InAdvances in Neural Information Processing Systems, volume 36, pages 41618–41650
Self-evaluation guided beam search for reason- ing. InAdvances in Neural Information Processing Systems, volume 36, pages 41618–41650. Curran As- sociates, Inc. Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik R Narasimhan. 2023. Tree of thoughts: Deliberate problem solving with large language models. In Thirty-...
2023
-
[10]
role": "system
(a 500-problem research evaluation subset of MATH (Hendrycks et al., 2021)) and the Qwen3- 1.7B model family (Team, 2025). Both are used strictly for research evaluation, consistent with their intended purpose. MATH500 is a publicly released research benchmark; our use is limited to model evaluation and we do not redistribute it. Qwen3-1.7B is released un...
2021
-
[11]
A solution must be mathematically sound AND produce a properly formatted final answer to be marked✓
SCOPE: Judge both mathematical correctness and answer formatting. A solution must be mathematically sound AND produce a properly formatted final answer to be marked✓
-
[12]
It must appear inside \boxed{} with no trailing punctuation or extra text inside the box
FINAL ANSWER REQUIRED: A final answer MUST be present. It must appear inside \boxed{} with no trailing punctuation or extra text inside the box. If no \boxed{} answer is present, or the box contains extra text/punctuation, mark as✗
-
[13]
MATHEMATICAL CORRECTNESS: If the solution contains any logical error, arithmetic error, or invalid reasoning step that affects the final answer, mark as✗
-
[14]
NO PROGRESS / LOOPING: If the solution repeats the same step or sequence of steps three or more times without producing new intermediate results or progressing toward a final answer, mark as✗
-
[15]
‘1/2’ vs ‘\frac{1}{2}’, extra whitespace, equivalent algebraic forms) are not errors
NOTATION TOLERANCE: Minor notational or spacing differences (e.g. ‘1/2’ vs ‘\frac{1}{2}’, extra whitespace, equivalent algebraic forms) are not errors. CRITICAL INSTRUCTION: Before outputting the ‘### Verdict:’ line, you must carefully think through your evaluation internally as the countdown progresses. Do not rush to give the answer—explicitly engage in...
-
[16]
Do NOT penalize for being incomplete
A partial solution with no final answer yet should be judged ONLY on whether its steps and reasoning are correct so far. Do NOT penalize for being incomplete
-
[17]
If the solution is overly repetitive or cycling through the same steps without making progress, mark as✗
-
[18]
with an end-of-text token) before any boxed answer appears, mark as✗as the model stopped without providing a final answer
If the solution terminates early (e.g. with an end-of-text token) before any boxed answer appears, mark as✗as the model stopped without providing a final answer
-
[19]
If a final answer IS present, it must appear in boxed with no trailing punctuation or extra text inside the box, otherwise it is✗
-
[20]
Minor notational or spacing differences are not errors
Judge mathematical correctness only. Minor notational or spacing differences are not errors. CRITICAL INSTRUCTION: Before outputting the ’### Verdict:’ line, you must carefully think through your evaluation internally as the countdown progresses. Do not rush to give the answer—explicitly engage in silent, step-by-step reasoning during the countdown before...
-
[21]
where n is the countdown length. The decreas- ing integer sequence signals to the model that it should complete an internal reasoning pro- cess of commensurate depth before producing the verdict. • Dot filler. . . . [ddots]. . . where d is the number of dot characters in- serted. This variant is motivated by the obser- vation that punctuation tokens can s...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.