Structural Grid Descriptors Predict Within-Task Solver Success on ARC-AGI
Pith reviewed 2026-06-27 17:29 UTC · model grok-4.3
The pith
Structural properties of intermediate grid states predict whether a symbolic ARC-AGI solver will succeed on a given task.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
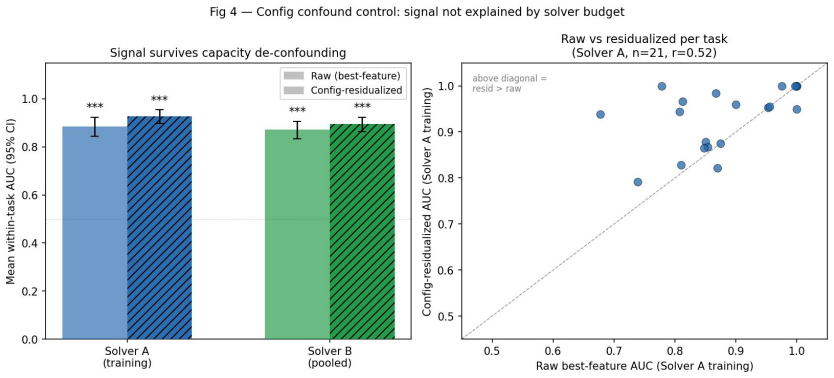
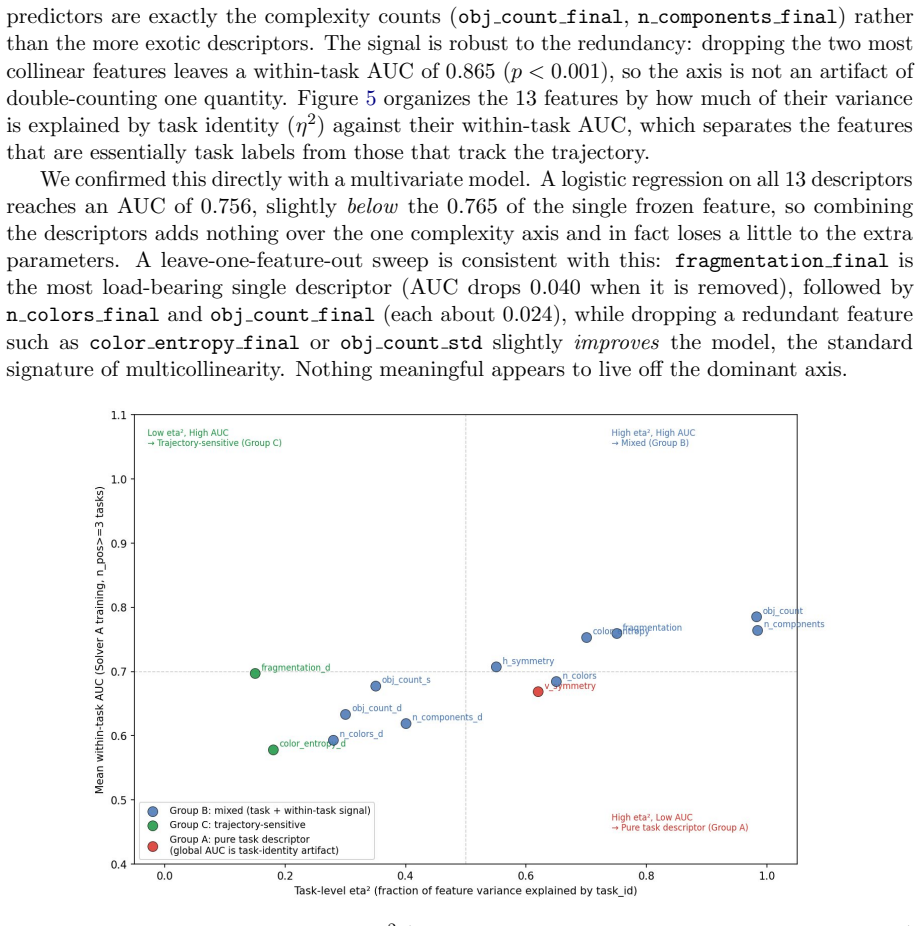
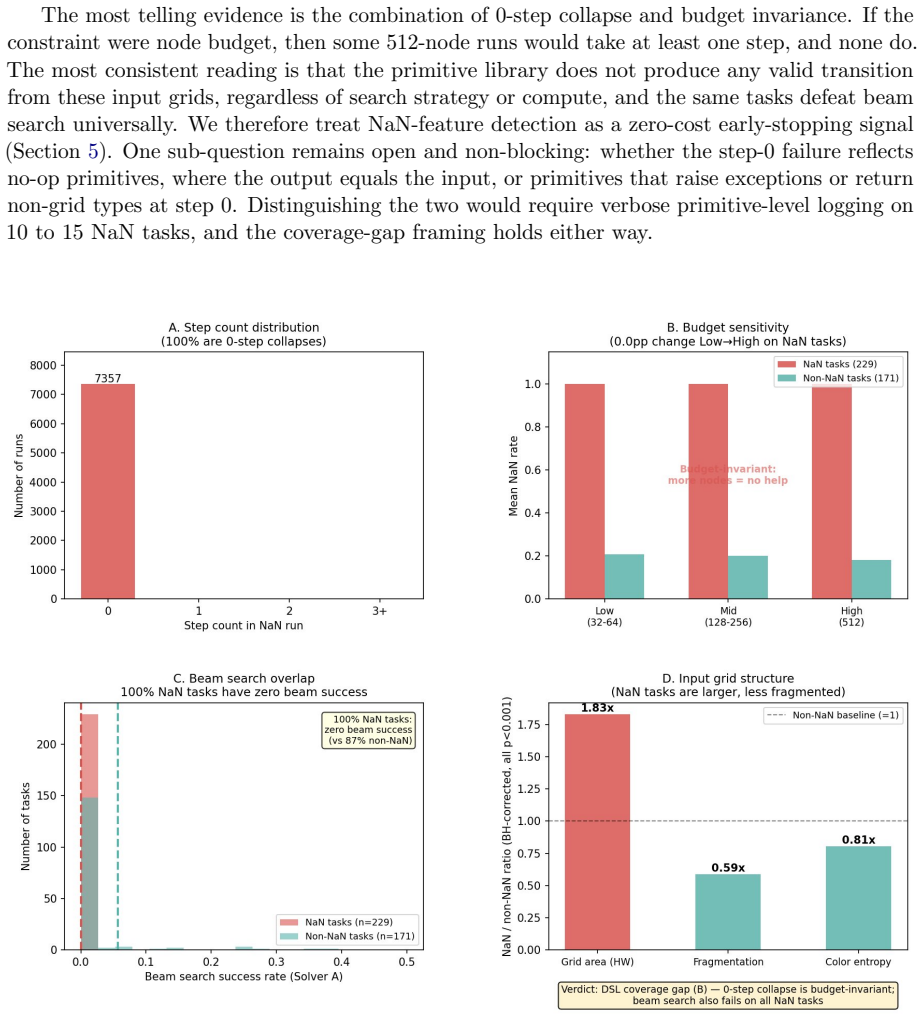
Across 44,800 runs spanning beam search and Stochastic DFS solvers, 400 ARC tasks, and both training and evaluation splits, hand-crafted grid descriptors measured at 50% trajectory completion discriminate successful from failed runs within the same task (mean within-task best-feature AUC = 0.885). Most predictive content lies along a single grid-complexity axis. The result transfers across solvers with cross-solver AUC 0.747-0.762 and remains significant on a pre-registered held-out set of 41 tasks (AUC 0.765 for n_components_final). The signal is not explained by solver capacity and is only weakly coupled to score trajectories.
What carries the argument
Hand-crafted grid descriptors, especially those tracking grid complexity, evaluated at the 50% point of each search trajectory.
If this is right
- Early stopping at 50% completion reduces beam-search compute by 33.6% while retaining 98.9% of solves.
- Degenerate-trajectory detection reduces Stochastic DFS compute by 65.3% with no loss of solutions.
- A feature chosen on one solver architecture predicts success on the other at AUC 0.747-0.762 in every transfer direction.
- On 229 of 400 evaluation tasks the DSL produces no valid transition from the input grid, a failure that is invariant to search budget.
Where Pith is reading between the lines
- If grid complexity is the dominant axis, future solvers could bias search toward trajectories that increase complexity early rather than following uniform expansion.
- The within-task signal implies that success depends on reaching particular structural states, not merely on total search effort or configuration size.
- The same descriptors could be used to rank tasks by intrinsic difficulty before any search begins.
Load-bearing premise
Success and failure labels remain exchangeable under permutation within each task, so the descriptors do not already embed task-specific structure that correlates with baseline success probability.
What would settle it
A new experiment on fresh solvers and tasks in which the within-task AUC of the same descriptors falls to chance level under the label-permutation test.
Figures




read the original abstract
We ask whether structural properties of intermediate grid states predict whether a symbolic ARC-AGI solver will succeed, framed as a test of conditional mutual information I(X;Y|task) > 0. Across 44,800 runs spanning two architecturally distinct solvers (beam search and Stochastic DFS), 400 ARC tasks, 28 configurations per solver, and both training and evaluation splits, hand-crafted grid descriptors measured at 50% trajectory completion discriminate successful from failed runs within the same task (mean within-task best-feature AUC = 0.885, p < 0.001 under within-task label permutation). Most predictive content lies along a single grid-complexity axis. The result generalizes across solver architectures: a feature selected on one solver predicts success on the other with AUC 0.747-0.762 in all four transfer directions (p < 0.001, leakage controlled). On a pre-registered held-out set of 41 reliable tasks, the frozen feature n_components_final achieves AUC = 0.765 (95% CI [0.717, 0.810], p < 0.001), robust under task-clustered bootstrap resampling and cross-solver task collapsing. The signal is not explained by solver capacity (configuration-residualized AUC = 0.927 and 0.896 for beam search and SDFS, p < 0.001) and is only weakly coupled to score trajectories (R^2 approximately 0). Early stopping at 50% completion reduces beam-search compute by 33.6% while retaining 98.9% of solves; degenerate-trajectory detection reduces SDFS compute by 65.3% with no solve loss. Finally, on 229 of 400 evaluation tasks the DSL primitive library produces no valid transition from the input grid. This 0-step collapse is invariant to search budget and universally failed by beam search, indicating a DSL coverage limitation rather than a search-budget effect.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that hand-crafted structural grid descriptors measured at 50% trajectory completion predict within-task solver success on ARC-AGI (mean best-feature AUC 0.885), with the signal lying primarily along a grid-complexity axis. The result is reported to generalize across two solvers (beam search and SDFS) in all transfer directions (AUC 0.747-0.762), to hold on a pre-registered held-out set of 41 tasks (frozen n_components_final feature AUC 0.765 under task-clustered bootstrap), to survive capacity residualization (AUCs 0.927/0.896), and to enable early stopping that reduces compute by 33.6-65.3% with negligible solve loss. The central framing is a test of I(X;Y|task) > 0 on 44,800 runs.
Significance. If the empirical correlation holds after addressing the statistical concern below, the work provides large-scale evidence that intermediate grid structure carries predictive information about solver success conditional on task identity, independent of capacity and weakly related to score trajectories. Strengths include the scale, pre-registered held-out evaluation, cross-solver transfer, capacity residualization, and practical early-stopping results. These elements support the claim that structural descriptors can discriminate success/failure within tasks.
major comments (1)
- [within-task label permutation test (methods and results on primary AUC claim)] The primary significance claim (mean within-task AUC = 0.885, p < 0.001) rests on the within-task label permutation test. This test is valid only under exchangeability of success/failure labels within each task under the null. With 28 configurations per solver, success probability is configuration-dependent and the descriptors are measured on configuration-specific trajectories, so the observed labels are not exchangeable; the permutation distribution therefore does not correctly calibrate type-I error. The configuration-residualized AUCs address linear dependence but do not restore exchangeability for the permutation procedure itself. The held-out result uses task-clustered bootstrap rather than within-task permutation, leaving the main within-task significance result dependent on the questionable test.
minor comments (1)
- [abstract and results on score-trajectory coupling] The abstract states that the signal is 'only weakly coupled to score trajectories (R^2 approximately 0)' but does not report the exact R^2 value or the regression specification used; adding this detail would strengthen the claim that the descriptors capture information beyond trajectory scoring.
Simulated Author's Rebuttal
We appreciate the referee's insightful comment on the statistical validity of the permutation test. We address this point below and agree that a revision is warranted.
read point-by-point responses
-
Referee: The primary significance claim (mean within-task AUC = 0.885, p < 0.001) rests on the within-task label permutation test. This test is valid only under exchangeability of success/failure labels within each task under the null. With 28 configurations per solver, success probability is configuration-dependent and the descriptors are measured on configuration-specific trajectories, so the observed labels are not exchangeable; the permutation distribution therefore does not correctly calibrate type-I error. The configuration-residualized AUCs address linear dependence but do not restore exchangeability for the permutation procedure itself. The held-out result uses task-clustered bootstrap rather than within-task permutation, leaving the main within-task significance result dependent on the questionable test.
Authors: We agree with the referee that the within-task label permutation test relies on an exchangeability assumption that is likely violated here, as success probabilities differ across the 28 configurations and the descriptors are computed on configuration-specific trajectories. This means the p < 0.001 may not accurately reflect type-I error control. We will revise the manuscript to de-emphasize or remove the permutation-based p-value for the primary within-task AUC claim. The pre-registered held-out evaluation on 41 tasks uses task-clustered bootstrap, which avoids this issue and yields AUC 0.765 with 95% CI [0.717, 0.810]. We will highlight this and the cross-solver transfer results (AUC 0.747-0.762) as the primary evidence for I(X;Y|task) > 0. The capacity residualization and early-stopping results remain unaffected. This constitutes a partial revision focused on statistical reporting. revision: partial
Circularity Check
No circularity: empirical within-task discrimination reported directly from data
full rationale
The paper presents an empirical measurement of association between hand-crafted grid descriptors (measured at 50% trajectory) and solver success/failure labels within each task, quantified via AUC and a within-task permutation test. No derivation chain reduces a claimed result to its own inputs by construction; there are no fitted parameters renamed as predictions, no self-citations invoked as load-bearing uniqueness theorems, and no ansatz or renaming of known results. The central statistic (mean AUC 0.885) is computed directly on the observed trajectories and labels across independent solver runs. The permutation test is a standard non-parametric procedure whose validity is a separate statistical question, not a circularity issue under the enumerated patterns. The result is therefore self-contained against external benchmarks and receives score 0.
Axiom & Free-Parameter Ledger
free parameters (2)
- 50% trajectory completion measurement point
- n_components_final feature
axioms (2)
- domain assumption Within-task label permutation test assumes exchangeability of success labels under the null of no conditional mutual information.
- standard math Grid descriptors are deterministic functions of the current grid state.
Reference graph
Works this paper leans on
-
[1]
Augustus Odena, Kensen Shi, David Bieber, Rishabh Singh, Charles Sutton, and Hanjun Dai. BUSTLE: Bottom-up program synthesis through learning-guided exploration.arXiv preprint arXiv:2007.14381, 2020
-
[2]
Solim LeGris, Wai Keen Vong, Brenden M. Lake, and Todd M. Gureckis. H-ARC: A robust estimate of human performance on the Abstraction and Reasoning Corpus benchmark.arXiv preprint arXiv:2409.01374, 2024
-
[3]
The ConceptARC benchmark: Evaluating understanding and generalization in the ARC domain.Transactions on Machine Learning Research, 2023
Arseny Moskvichev, Victor Vikram Odouard, and Melanie Mitchell. The ConceptARC benchmark: Evaluating understanding and generalization in the ARC domain.Transactions on Machine Learning Research, 2023. 19
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.