Lightweight Vision-Aided Beam Tracking for Cross-Environment mmWave Communications
Pith reviewed 2026-07-02 07:26 UTC · model grok-4.3
The pith
A lightweight vision model predicts current and future mmWave beams from past images across different real-world environments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
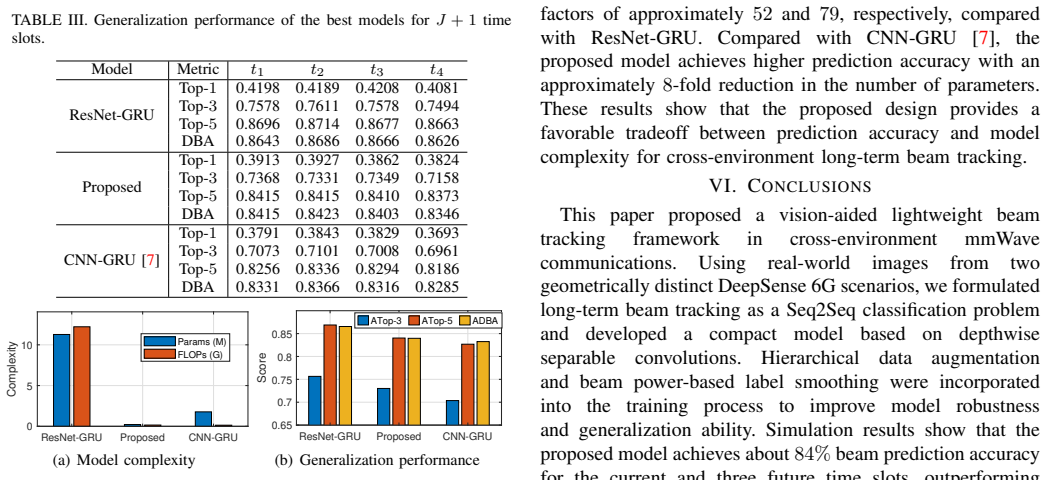
A model based on depthwise separable convolutions, hierarchical data augmentation, and beam power-based label smoothing solves the sequence-to-sequence beam prediction task and delivers up to 84 percent accuracy on current and three future beams across two geometrically distinct real-world scenarios, while using 52 times fewer parameters and 79 times less computation than a high-capacity ResNet.
What carries the argument
Low-complexity vision model built from depthwise separable convolutions that maps past image sequences to current and future beam indices.
If this is right
- Beam management overhead in mmWave systems can be reduced by replacing pilot-based tracking with vision-based sequence prediction.
- The same lightweight architecture can be applied to multi-slot lookahead prediction without retraining for each new deployment site.
- Hierarchical augmentation and power-based label smoothing improve cross-environment generalization for any vision-based wireless task.
- Model size and compute reductions of this magnitude make real-time onboard inference feasible on resource-limited devices.
Where Pith is reading between the lines
- The approach could be tested with video instead of single frames to capture motion cues that further reduce prediction error.
- Combining the vision model with occasional sparse RF measurements might raise accuracy above 84 percent while still keeping overhead low.
- The same sequence-to-sequence formulation might transfer to other sensing modalities such as lidar or radar for beam tracking.
Load-bearing premise
Visual observations from only two geometrically distinct scenarios contain enough information to predict optimal beams reliably in any new environment without extra sensor modalities or site-specific calibration.
What would settle it
Running the trained model on images from a third environment whose geometry produces beam directions uncorrelated with the visual features seen in the training scenarios and observing whether accuracy falls substantially below 84 percent.
Figures



read the original abstract
Sensing-aided beam tracking is a promising approach to reduce the overhead for millimeter-wave beam management. However, real-world application remains challenging due to rapid channel variations and substantial environmental differences across deployment scenarios. Developing low-complexity sensing assisted approaches that generalize to diverse environments can alleviate the problem. With this motivation, this paper proposes a lightweight vision-aided model for cross-environment beam tracking. The task is formulated as a sequence-to-sequence classification problem, where the model jointly predicts the current and future optimal beams from past visual observations. We develop a low-complexity model based on depthwise separable convolutions and introduce hierarchical data augmentation and beam power-based label smoothing to improve robustness and generalization. Experimental results on real-world images from two geometrically distinct DeepSense 6G scenarios show that the proposed strategies consistently improve cross-environment beam prediction accuracy up to 84% across the current and three future time slots, outperforming the state-of-the-art solution. Notably, this performance is achieved while reducing the number of model parameters and computational complexity by factors of approximately 52 and 79, respectively, compared with the high-capacity ResNet baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a lightweight vision-aided beam tracking model for mmWave communications that generalizes across environments. It formulates beam prediction as a sequence-to-sequence classification task using past visual observations to predict current and future optimal beams. The model employs depthwise separable convolutions for low complexity, along with hierarchical data augmentation and beam power-based label smoothing for improved robustness. Experiments on real-world images from two geometrically distinct DeepSense 6G scenarios report up to 84% accuracy across current and three future time slots, outperforming a high-capacity ResNet baseline while reducing parameters by ~52x and computational complexity by ~79x.
Significance. If the results hold under more extensive validation, the work could advance practical deployment of sensing-aided beam management in mmWave systems by demonstrating a low-complexity approach that maintains performance across different environments. Strengths include the use of real-world data from the DeepSense 6G dataset and explicit focus on model efficiency through separable convolutions and parameter reduction relative to ResNet.
major comments (2)
- [Experimental results (as described in abstract)] The central cross-environment generalization claim is evaluated using only two geometrically distinct scenarios from DeepSense 6G. For the reported 84% accuracy and outperformance of the ResNet baseline to establish robustness across diverse environments, these two cases must adequately represent the distribution of environmental variations in visual-to-beam mappings; the manuscript does not provide analysis showing that performance would hold under further changes in scene geometry or visual conditions.
- [Abstract and experimental evaluation] The abstract reports quantitative gains (84% accuracy, 52x/79x efficiency improvements) from real-data experiments but provides no error bars, statistical tests, full training details, or ablation studies on the proposed augmentation and label smoothing components. This makes it difficult to verify whether the gains are robust or sensitive to post-hoc choices in the two-scenario setup.
minor comments (2)
- [Method description] Clarify the exact definition of 'hierarchical data augmentation' and how it differs from standard techniques, including any hyperparameters involved.
- [Results figures] Ensure all figures showing beam prediction accuracy include confidence intervals or variance across runs to support the quantitative claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with clarifications and proposed revisions where feasible, while maintaining focus on the substance of the concerns regarding evaluation scope and reporting rigor.
read point-by-point responses
-
Referee: [Experimental results (as described in abstract)] The central cross-environment generalization claim is evaluated using only two geometrically distinct scenarios from DeepSense 6G. For the reported 84% accuracy and outperformance of the ResNet baseline to establish robustness across diverse environments, these two cases must adequately represent the distribution of environmental variations in visual-to-beam mappings; the manuscript does not provide analysis showing that performance would hold under further changes in scene geometry or visual conditions.
Authors: We agree that two scenarios provide only limited evidence for broad cross-environment robustness. The DeepSense 6G scenarios were selected specifically for their geometric differences, and the proposed model with separable convolutions, hierarchical augmentation, and label smoothing demonstrates consistent gains over the ResNet baseline in this setup. In revision, we will add an explicit limitations discussion section addressing the scope of the evaluation and the challenges of representing all possible visual-to-beam variations. We cannot provide additional empirical analysis on further scene changes, as we are restricted to the two publicly available scenarios in the dataset. revision: partial
-
Referee: [Abstract and experimental evaluation] The abstract reports quantitative gains (84% accuracy, 52x/79x efficiency improvements) from real-data experiments but provides no error bars, statistical tests, full training details, or ablation studies on the proposed augmentation and label smoothing components. This makes it difficult to verify whether the gains are robust or sensitive to post-hoc choices in the two-scenario setup.
Authors: We acknowledge that the current presentation lacks sufficient statistical details and component-wise analysis. The full manuscript includes some training hyperparameters, but to address the concern we will revise the abstract and experimental section to report error bars from multiple runs, add pairwise statistical significance tests against the baseline, expand training details, and include ablation studies on hierarchical augmentation and power-based label smoothing (moved to an appendix for brevity). These changes will better substantiate the reported gains. revision: yes
- Empirical analysis demonstrating that performance holds under further changes in scene geometry or visual conditions beyond the two available DeepSense 6G scenarios
Circularity Check
No circularity; empirical accuracy measured on held-out real data
full rationale
The paper formulates beam tracking as a sequence-to-sequence classification task and reports experimental accuracy (up to 84%) on held-out images from two DeepSense 6G scenarios. These metrics are obtained by evaluating the trained model on separate test data, not by algebraic reduction of any equation to its own fitted inputs or by self-citation chains that substitute for independent verification. No self-definitional steps, fitted-input predictions, or ansatz smuggling appear in the described approach or abstract. The limited number of scenarios affects generalization strength but does not create circularity in the reported results.
Axiom & Free-Parameter Ledger
free parameters (1)
- CNN weights and training hyperparameters
axioms (1)
- domain assumption Visual observations contain sufficient information to predict optimal beams
Reference graph
Works this paper leans on
-
[1]
Beam training and tracking in mmwave communication: A survey,
W. Yi, W. Zhiqing, and F. Zhiyong, “Beam training and tracking in mmwave communication: A survey,” China Commun. , vol. 21, no. 6, pp. 1–22, 2024
2024
-
[2]
Knowledge distillation for collaborative learning in distributed communications and sensing,
N. T. Nguyen, M. Ma, N. Shlezinger, J. Choi, Y . C. Eldar, A. L. Swindlehurst, and M. Juntti, “Knowledge distillation for collaborative learning in distributed communications and sensing,” IEEE Commun. Mag., 2026 (Early Access)
2026
-
[3]
AI/ML for beam management in 5G-advanced: A standardization perspective,
Q. Xue, J. Guo, B. Zhou, Y . Xu, Z. Li, and S. Ma, “AI/ML for beam management in 5G-advanced: A standardization perspective,” IEEE V eh. Technol. Mag., vol. 19, no. 4, pp. 64–72, 2024
2024
-
[4]
Position-aided beam prediction in the real world: How useful GPS locations actually are?
J. Morais, A. Bchboodi, H. Pezeshki, and A. Alkhateeb, “Position-aided beam prediction in the real world: How useful GPS locations actually are?” in Proc. IEEE Int. Conf. Commun. , 2023
2023
-
[5]
Radar aided 6G beam prediction: Deep learning algorithms and real-world demonstration,
U. Demirhan and A. Alkhateeb, “Radar aided 6G beam prediction: Deep learning algorithms and real-world demonstration,” in Proc. IEEE Wireless Commun. and Networking Conf. , 2022
2022
-
[6]
Computer vision aided beam tracking in a real-world millimeter wave deployment,
S. Jiang and A. Alkhateeb, “Computer vision aided beam tracking in a real-world millimeter wave deployment,” 2022
2022
-
[7]
Attention-enhanced learning for sensing-assisted long-term beam tracking in mmWave communications,
M. Ma, N. T. Nguyen, N. Shlezinger, Y . C. Eldar, and M. Juntti, “Attention-enhanced learning for sensing-assisted long-term beam tracking in mmWave communications,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Processing , 2026
2026
-
[8]
Knowledge Distillation for Sensing-Assisted Long-Term Beam Tracking in mmWave Communications
M. Ma, N. T. Nguyen, N. Shlezinger, Y . C. Eldar, A. L. Swindlehurst, and M. Juntti, “Knowledge distillation for sensing-assisted long- term beam tracking in mmWave communications,” arXiv preprint arXiv:2509.11419, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Environment semantic communication: Enabling distributed sensing aided networks,
S. Imran, G. Charan, and A. Alkhateeb, “Environment semantic communication: Enabling distributed sensing aided networks,” vol. 5, pp. 7767–7786, 2024
2024
-
[10]
Lidar aided wireless networks-beam prediction for 5G,
D. Marasinghe, N. Jayaweera, N. Rajatheva, S. Hakola, T. Koskela, O. Tervo, J. Karjalainen, E. Tiirola, and J. Hulkkonen, “Lidar aided wireless networks-beam prediction for 5G,” in Proc. IEEE V eh. Technol. Conf., 2022
2022
-
[11]
Knowledge Distillation for Lightweight Multimodal Sensing-Aided mmWave Beam Tracking
M. Ma, I. Welgamage, A. Alkhateeb, A. L. Swindlehurst, M. Juntti, and N. T. Nguyen, “Knowledge distillation for lightweight multimodal sensing-aided mmWave beam tracking,” arXiv preprint arXiv:2604.16708, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Advancing ultra-reliable 6G: Transformer and semantic localization empowered robust beamforming in millimeter-wave communications,
A. D. Raha, K. Kim, A. Adhikary, M. Gain, Z. Han, and C. S. Hong, “Advancing ultra-reliable 6G: Transformer and semantic localization empowered robust beamforming in millimeter-wave communications,” IEEE Trans. V eh. Technol., 2025
2025
-
[13]
Harnessing multimodal sensing for multi-user beamforming in mmWave systems,
K. Patel and R. W. Heath, “Harnessing multimodal sensing for multi-user beamforming in mmWave systems,” IEEE Trans. Wireless Commun., vol. 23, no. 12, pp. 18 725–18 739, 2024
2024
-
[14]
Sensing-assisted high reliable communication: A transformer- based beamforming approach,
Y . Cui, J. Nie, X. Cao, T. Y u, J. Zou, J. Mu, and X. Jing, “Sensing-assisted high reliable communication: A transformer- based beamforming approach,” IEEE J. Sel. Topics Signal Process. , vol. 18, no. 5, pp. 782–795, 2024
2024
-
[15]
Advancing multi- modal beam prediction with cross-modal feature enhancement and dynamic fusion mechanism,
Q. Zhu, Y . Wang, W. Li, H. Huang, and G. Gui, “Advancing multi- modal beam prediction with cross-modal feature enhancement and dynamic fusion mechanism,” IEEE Trans. Commun. , vol. 73, no. 9, pp. 7931–7940, 2025
2025
-
[16]
Lidar aided future beam prediction in real-world millimeter wave V2I communications,
S. Jiang, G. Charan, and A. Alkhateeb, “Lidar aided future beam prediction in real-world millimeter wave V2I communications,” IEEE Wireless Commun. Lett. , vol. 12, no. 2, pp. 212–216, 2023
2023
-
[17]
Millimeter wave V2V beam tracking using radar: Algorithms and real-world demonstration,
H. Luo, U. Demirhan, and A. Alkhateeb, “Millimeter wave V2V beam tracking using radar: Algorithms and real-world demonstration,” in Proc. European Sign. Proc. Conf. , 2023
2023
-
[18]
Deepsense 6G: A large-scale real-world multi-modal sensing and communication dataset,
A. Alkhateeb, G. Charan, T. Osman, A. Hredzak, J. Morais, U. Demirhan, and N. Srinivas, “Deepsense 6G: A large-scale real-world multi-modal sensing and communication dataset,” IEEE Commun. Mag. , vol. 61, no. 9, pp. 122–128, 2023
2023
-
[19]
Mobilenetv2: Inverted residuals and linear bottlenecks,
M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “Mobilenetv2: Inverted residuals and linear bottlenecks,” in Proc. IEEE Conf. on Comp. Vision & Pattern Rec. , 2018, pp. 4510–4520
2018
-
[20]
mixup: Beyond Empirical Risk Minimization
H. Zhang, M. Cisse, Y . N. Dauphin, and D. Lopez-Paz, “mixup: Beyond empirical risk minimization,” arXiv preprint arXiv:1710.09412 , 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Rethinking the inception architecture for computer vision,
C. Szegedy, V . V anhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the inception architecture for computer vision,” in Proc. IEEE Conf. on Comp. Vision & Pattern Rec. , 2016, pp. 2818–2826
2016
-
[22]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. IEEE Conf. on Comp. Vision & Pattern Rec., 2016, pp. 770–778
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.