When Does Routing Become Interpretable? Causal Probes on Block Attention Residuals
Pith reviewed 2026-06-27 07:07 UTC · model grok-4.3
The pith
Architectural exposure of routing is necessary but not sufficient for mechanistic interpretation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
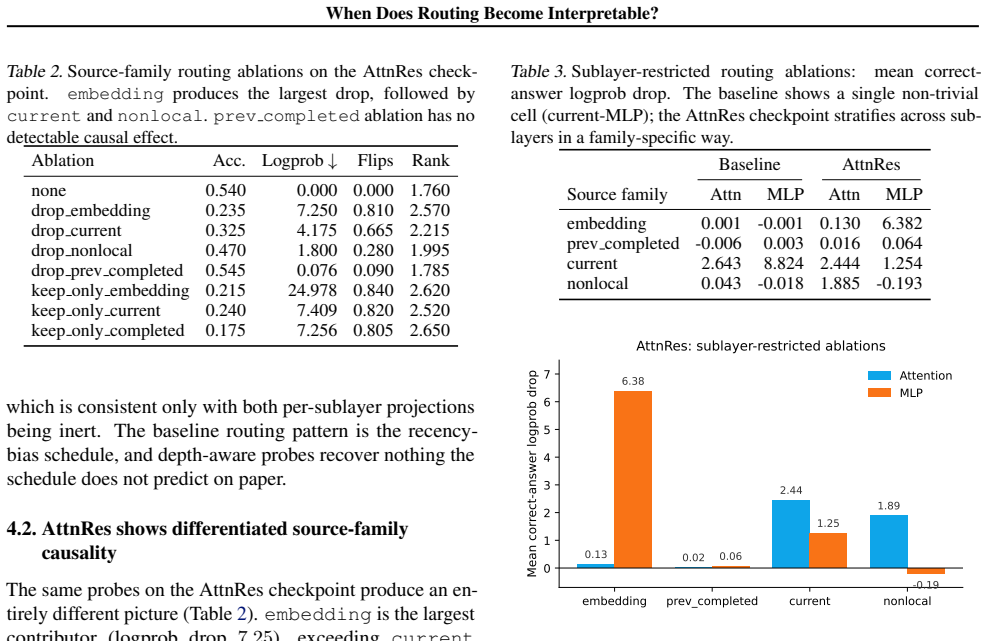
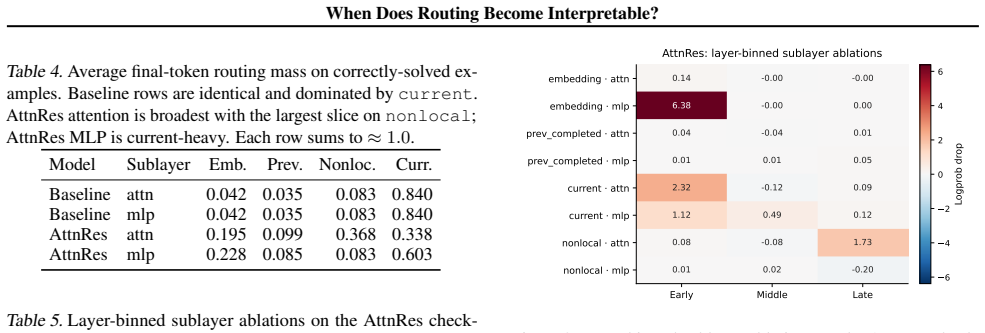
Block Attention Residuals replace fixed additive residuals with a learned softmax over earlier depth-source representations, surfacing routing as an inspectable tensor. Under matched interventions the wrapped baseline reproduces its analytic content-independent schedule, while the trained checkpoint exhibits stratified routing motifs. In both sublayers the slice carrying the largest routing mass is not the slice with the largest causal contribution, and one source family carries appreciable mass yet produces no detectable causal role.
What carries the argument
Block Attention Residuals, which turn fixed residuals into a learned softmax over prior depth sources so that routing becomes an explicit tensor in the forward pass.
If this is right
- Structured depth routing motifs appear only when routing participates in training rather than being imposed at inference.
- Routing mass and causal importance dissociate, so the largest mass slice need not be the largest causal contributor.
- Some source families carry routing mass yet show no measurable causal role when ablated.
- Descriptive summaries of exposed routing tensors remain candidate hypotheses until confirmed by causal intervention.
Where Pith is reading between the lines
- Interpretability pipelines that expose internal flows should treat observational summaries as starting points for causal experiments rather than endpoints.
- The same mass-versus-causality gap may appear in other exposed transformer components once they are made directly readable.
- Training curricula could be modified to encourage alignment between routing mass and causal impact.
- The same probe design could be applied to other model families to test whether training is required for any interpretable routing structure to emerge.
Load-bearing premise
The deterministic recency-bias schedule wrapped around the vanilla Qwen3 serves as a valid content-independent routing baseline that can be directly contrasted with the trained checkpoint under the same interventions.
What would settle it
Finding that the trained Block AttnRes checkpoint exhibits no localized motifs or that routing mass perfectly tracks causal importance under the same ablation interventions used on the baseline.
Figures


read the original abstract
Block Attention Residuals (Block AttnRes) by replace fixed additive residuals with a learned softmax over earlier depth-source representations, surfacing cross-layer routing as an inspectable tensor in the forward pass. This is a tempting interpretability target: information flow normally inferred indirectly is now directly observable. We ask whether such exposure suffices for mechanistic interpretation. We probe two same-scale ($0.6$B) Block AttnRes checkpoints under identical routing-ablation interventions: a vanilla Qwen3 inference-wrapped through a deterministic recency-bias schedule that the codebase admits as a routing-equivalent loading path, and a Block AttnRes Qwen3 trained from scratch with routing as part of optimisation. The wrapped baseline's routing weights are content-independent and reproduce the schedule's analytic prediction. The trained AttnRes checkpoint instead exhibits three localised routing motifs: an embedding-source pathway through early-layer MLP, a current-state pathway through early-layer attention and MLP, and an older-history pathway through late-layer attention. Beyond this stratification, we find a sharp dissociation between average routing mass and causal importance: in both sublayers, the largest mass slice is not the largest causal contribution, and one source family carries appreciable mass with no detectable causal role under intervention. Architectural exposure of routing is therefore necessary but not sufficient for mechanistic interpretation: structured depth routing emerges only when routing has been part of training, and even then, descriptive routing summaries should be treated as candidate hypotheses to be tested by causal interventions, not as evidence of mechanism in their own right.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Block Attention Residuals (Block AttnRes) to replace fixed additive residuals with a learned softmax over earlier depth-source representations, exposing cross-layer routing as an inspectable tensor. It performs controlled routing-ablation interventions on two same-scale (0.6B) models: an inference-wrapped vanilla Qwen3 using a deterministic recency-bias schedule (content-independent baseline) and a Block AttnRes Qwen3 trained from scratch with routing optimized. The trained checkpoint exhibits three localized routing motifs (embedding-source via early MLP, current-state via early attention/MLP, older-history via late attention) and a dissociation between average routing mass and causal importance under intervention, while the baseline does not. The conclusion is that architectural exposure of routing is necessary but not sufficient for mechanistic interpretation; structured routing emerges only when optimized during training, and descriptive summaries require causal testing.
Significance. If the result holds after addressing the baseline confound, the work is significant for mechanistic interpretability research. It supplies concrete evidence that exposing routing tensors does not automatically yield interpretable mechanisms, that training is required for structured motifs to appear, and that mass-based summaries must be validated causally rather than taken as evidence. The emphasis on intervention-based testing over description is a useful methodological contribution that could temper over-interpretation of routing visualizations in transformer variants.
major comments (1)
- [Abstract] Abstract and introduction: The central claim that 'structured depth routing emerges only when routing has been part of training' rests on the contrast between the inference-wrapped pre-trained vanilla Qwen3 and the from-scratch trained Block AttnRes checkpoint. These differ simultaneously in (a) whether routing parameters were optimized and (b) the full pre-training history and initialization of the base representations. No control is described that holds the base model fixed while varying only the routing optimization, so the observed stratification and mass-causal dissociation cannot be attributed solely to the presence of trained routing. A same-base-model ablation (e.g., fine-tuning the vanilla checkpoint with routing parameters) would be required to isolate the factor.
minor comments (2)
- The abstract and methods description omit details on statistical tests used to establish qualitative differences between the two models, exact implementation of the routing-ablation interventions, and any exclusion criteria for source families.
- Notation for the learned softmax in Block AttnRes and the precise form of the deterministic recency-bias schedule should be stated explicitly (e.g., as an equation) rather than described only in prose.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The identified confound between routing optimization and pre-training history is a valid concern that limits causal attribution. We will revise the abstract, introduction, and discussion to qualify the central claim, explicitly note the limitation, and frame the results as evidence that structured motifs appear under joint optimization of routing parameters rather than under a fixed schedule alone.
read point-by-point responses
-
Referee: [Abstract] Abstract and introduction: The central claim that 'structured depth routing emerges only when routing has been part of training' rests on the contrast between the inference-wrapped pre-trained vanilla Qwen3 and the from-scratch trained Block AttnRes checkpoint. These differ simultaneously in (a) whether routing parameters were optimized and (b) the full pre-training history and initialization of the base representations. No control is described that holds the base model fixed while varying only the routing optimization, so the observed stratification and mass-causal dissociation cannot be attributed solely to the presence of trained routing. A same-base-model ablation (e.g., fine-tuning the vanilla checkpoint with routing parameters) would be required to isolate the factor.
Authors: We agree that the current design confounds the presence of optimized routing parameters with differences in base-model pre-training and initialization. The baseline was selected because it supplies a deterministic, content-independent routing schedule that the Qwen3 codebase already supports as a loading path, thereby providing a non-learned reference on the original pre-trained representations. Nevertheless, this does not isolate the effect of routing optimization from the training history of the representations themselves. A same-base-model control (fine-tuning the vanilla checkpoint after inserting routing parameters) would be the cleanest isolation. We will therefore revise the abstract and introduction to replace the stronger phrasing with a qualified statement: structured routing motifs and the mass-causal dissociation appear when routing is optimized end-to-end, in contrast to a fixed schedule on pre-trained representations. We will also add an explicit limitations paragraph acknowledging that training history may contribute to the observed differences. revision: partial
Circularity Check
No significant circularity; claims rest on independent empirical interventions
full rationale
The paper presents no derivation chain involving equations, fitted parameters renamed as predictions, or self-citations that bear the central load. Its claims derive from direct comparisons of routing-ablation interventions on two checkpoints (wrapped vanilla Qwen3 vs. trained Block AttnRes), with routing tensors observed and causally tested in the forward pass. These contrasts are externally falsifiable via the reported interventions and do not reduce to self-definitional quantities or ansatzes imported from prior author work. The analysis is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The wrapped baseline's routing weights are content-independent and reproduce the analytic schedule prediction.
Reference graph
Works this paper leans on
-
[1]
On Layer Normalization in the Transformer Architecture , journal =
Ruibin Xiong and Yunchang Yang and Di He and Kai Zheng and Shuxin Zheng and Chen Xing and Huishuai Zhang and Yanyan Lan and Liwei Wang and Tie. On Layer Normalization in the Transformer Architecture , journal =. 2020 , url =. 2002.04745 , timestamp =
-
[2]
arXiv preprint arXiv:2407.02646 , year =
A Practical Review of Mechanistic Interpretability for Transformer-Based Language Models , author =. arXiv preprint arXiv:2407.02646 , year =
-
[3]
Proceedings of the 37th International Conference on Machine Learning (ICML) , year =
On Layer Normalization in the Transformer Architecture , author =. Proceedings of the 37th International Conference on Machine Learning (ICML) , year =
-
[4]
Locating and Editing Factual Associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , booktitle =. Locating and Editing Factual Associations in
-
[5]
2026 , url=
Attention Residuals , author=. 2026 , url=
2026
-
[6]
Deep Residual Learning for Image Recognition
Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun , title =. CoRR , volume =. 2015 , url =. 1512.03385 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[7]
ArXiv , year=
SiameseNorm: Breaking the Barrier to Reconciling Pre/Post-Norm , author=. ArXiv , year=
-
[8]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[9]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[10]
M. J. Kearns , title =
-
[11]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[12]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[13]
Suppressed for Anonymity , author=
-
[14]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[15]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.