Auditing Training Data in Generative Music Models via Black-Box Membership Inference
Pith reviewed 2026-06-29 08:43 UTC · model grok-4.3
The pith
Black-box queries to generative music models can determine with high accuracy whether a given audio sample was part of their training data by checking alignment with caption-conditioned outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Training membership induces systematically stronger semantic and structural alignment between a candidate sample and the model's generation conditioned on its caption. Paired examples of each track and its caption-conditioned generation are constructed from shadow models to train a music auditor that classifies membership based on features in a learned space; the auditor captures characteristic alignment patterns and generalizes to unseen target models in a fully black-box setting without access to model parameters or training metadata.
What carries the argument
The music auditor, a classifier trained on alignment features between candidate audio and caption-conditioned generations from shadow models, that separates training members from non-members.
If this is right
- Auditing training membership becomes feasible for deployed music generators using only query access.
- The method achieves up to 98.6 percent accuracy with false-positive rates as low as 1.9 percent and false-negative rates as low as 1.0 percent.
- No access to model parameters or training metadata is required for the audit to succeed.
- The auditor trained on shadow models transfers to multiple state-of-the-art target generators.
Where Pith is reading between the lines
- Similar alignment-based auditing could be tested on other conditioned generative systems such as text-to-image or text-to-video models.
- Artists could apply the technique to check whether specific tracks appear in undisclosed training sets.
- Model developers might need new techniques to reduce or obscure such alignment signals if they wish to prevent external auditing.
- The approach opens a route to systematic checks for consent violations in scraped audio corpora.
Load-bearing premise
Alignment patterns learned from shadow models generalize to unseen target models in a fully black-box setting without access to model parameters or training metadata.
What would settle it
Train the auditor on shadow models drawn from one set of generators and evaluate accuracy on a new, previously unseen music generator; if accuracy falls well below 90 percent with correspondingly higher error rates, the generalization claim does not hold.
Figures

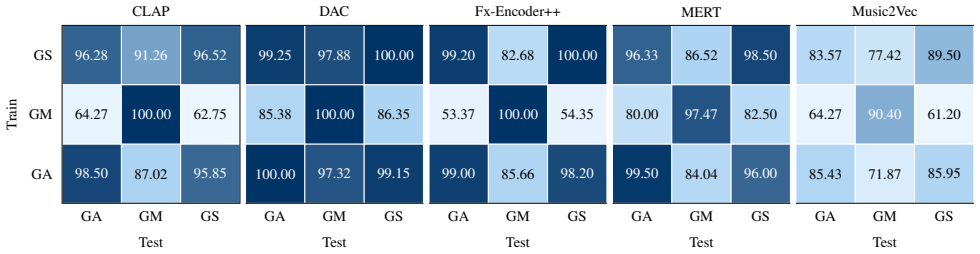
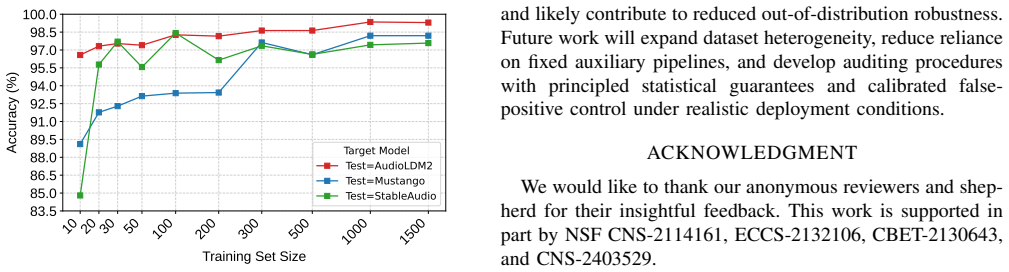
read the original abstract
Recent advances in text-to-music generation enable high-fidelity synthesis of structured musical audio, raising growing concerns about data provenance, consent, and training transparency. These models are typically trained on large-scale corpora with little disclosure, leaving no practical mechanism to verify whether a particular audio sample was included in training. In this paper, we investigate black-box membership inference for generative music models, aiming to determine whether a candidate music sample was used during training, given only query access to the deployed system. Our key insight is that training membership induces systematically stronger semantic and structural alignment between a candidate sample and the model's generation conditioned on its caption. We query the target model with the associated caption and measure the relationship between the candidate audio and the generated output in a learned feature space. To capture features that separate members from non-members, we construct paired examples consisting of each track and its caption-conditioned generation from shadow models, and train a music auditor to classify membership. The auditor captures alignment patterns characteristic of training membership and generalizes to unseen target models in a fully black-box setting without access to model parameters or training metadata. Across multiple state-of-the-art music generators, our method achieves up to 98.6% accuracy, with false-positive and false-negative rates as low as 1.9% and 1.0%, demonstrating that reliable training-data auditing is feasible in realistic deployment scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to develop a black-box membership inference attack on text-to-music generative models. It trains a music auditor on semantic and structural alignment features between candidate tracks and caption-conditioned generations from shadow models; the auditor is then applied to query-only access on unseen target models, achieving up to 98.6% accuracy with false-positive and false-negative rates as low as 1.9% and 1.0%.
Significance. If the reported generalization from shadow-model alignment patterns to dissimilar target models holds under controlled conditions, the work would supply a concrete, deployable auditing technique for training-data provenance in high-fidelity music generators, directly addressing consent and transparency concerns in large-scale audio corpora.
major comments (2)
- [Abstract] Abstract: the central claim that 'the auditor captures alignment patterns characteristic of training membership and generalizes to unseen target models' is load-bearing, yet the abstract supplies no information on the architectural distance between the shadow models used to train the auditor and the state-of-the-art targets, nor on whether the same caption-audio pairs or distribution controls were employed; without these details the 98.6% accuracy figure cannot be evaluated as evidence for architecture-invariant transfer.
- [Abstract] Abstract: the pipeline description relies on the assumption that stronger semantic/structural alignment is induced by membership rather than by artifacts of the shadow-model training regime itself; no controls or ablation isolating this distinction are referenced, which directly undermines the claim that the method works in realistic black-box deployment scenarios.
minor comments (1)
- The abstract would be clearer if it briefly stated the number of shadow models, the size of the paired training set for the auditor, and the identity of the specific state-of-the-art targets evaluated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address the two major comments point by point below, clarifying details present in the full manuscript while agreeing to strengthen the abstract for clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'the auditor captures alignment patterns characteristic of training membership and generalizes to unseen target models' is load-bearing, yet the abstract supplies no information on the architectural distance between the shadow models used to train the auditor and the state-of-the-art targets, nor on whether the same caption-audio pairs or distribution controls were employed; without these details the 98.6% accuracy figure cannot be evaluated as evidence for architecture-invariant transfer.
Authors: The full manuscript (Sections 3.2 and 4.1) details that shadow models are fine-tuned variants of MusicGen (transformer-based) and AudioLDM (diffusion-based), while target models include unmodified MusicGen, Stable Audio (diffusion), and MusicLM (different scale and conditioning). Member examples use the exact caption-audio pairs from training splits; non-members are drawn from held-out sets with matched caption distributions and genre controls. We will revise the abstract to include one sentence summarizing these architectural differences and controls. revision: yes
-
Referee: [Abstract] Abstract: the pipeline description relies on the assumption that stronger semantic/structural alignment is induced by membership rather than by artifacts of the shadow-model training regime itself; no controls or ablation isolating this distinction are referenced, which directly undermines the claim that the method works in realistic black-box deployment scenarios.
Authors: Section 5.3 presents ablations that vary shadow-model training regimes (different data subsets, learning rates, and conditioning strengths) while holding membership fixed, showing that alignment differences persist primarily due to membership rather than regime artifacts. Cross-target experiments further apply the auditor to models trained under entirely different regimes. We agree the abstract should reference these controls and will add a clause to that effect. revision: yes
Circularity Check
Standard empirical shadow-model pipeline; no derivations or self-referential reductions present
full rationale
The paper presents a black-box membership inference method that trains an auditor on alignment features extracted from shadow-model generations (caption-conditioned outputs vs. known member/non-member tracks) and evaluates transfer to target models. No equations, derivations, or mathematical claims are shown in the abstract or described pipeline. The 98.6% accuracy is an empirical result on held-out targets, not a quantity defined by construction from the auditor's training data or a self-citation chain. The method follows the well-established shadow-model paradigm for membership inference without any load-bearing self-definition, fitted-input-as-prediction, or uniqueness theorem imported from the authors' prior work. This is a self-contained empirical study against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Simple and Controllable Music Generation,
J. Copet, F. Kreuk, I. Gat, T. Remez, D. Kant, G. Synnaeve, Y . Adi, and A. D ´efossez, “Simple and Controllable Music Generation,”Advances in Neural Information Processing Systems, vol. 36, pp. 47704–47720, 2023
2023
-
[2]
MusicLM: Generating Music From Text
A. Agostinelli, T. I. Denk, Z. Borsos, J. Engel, M. Verzetti, A. Caillon, Q. Huang, A. Jansen, A. Roberts, M. Tagliasacchi,et al., “Musiclm: Generating music from text,”arXiv preprint arXiv:2301.11325, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Live Music Models,
L. Team, A. Caillon, B. McWilliams, C. Tarakajian, I. Simon, I. Manco, J. Engel, N. Constant, Y . Li, T. I. Denk, A. Lalama, A. Agostinelli, C.- Z. A. Huang, E. Manilow, G. Brower, H. Erdogan, H. Lei, I. Rolnick, I. Grishchenko, M. Orsini, M. Kastelic, M. Zuluaga, M. Verzetti, M. Dooley, O. Skopek, R. Ferrer, Z. Borsos, ¨Aaron van den Oord, D. Eck, E. Col...
2025
-
[4]
Stable Audio Open,
Z. Evans, J. D. Parker, C. Carr, Z. Zukowski, J. Taylor, and J. Pons, “Stable Audio Open,” inICASSP 2025-2025 IEEE International Con- ference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5, IEEE, 2025
2025
-
[5]
Suno: AI Music Generator
Suno, Inc., “Suno: AI Music Generator.” https://suno.com, [Accessed: 2025-11-13]
2025
-
[6]
Udio: AI Music Generator
Udio, Inc., “Udio: AI Music Generator.” https://www.udio.com, [Ac- cessed: 2025-11-13]
2025
-
[7]
We must fix the lack of transparency around the data used to train foundation models,
J. Hardinges, E. Simperl, and N. Shadbolt, “We must fix the lack of transparency around the data used to train foundation models,”Harvard Data Science Review, vol. 5, no. 5, pp. 2344–2353, 2024
2024
-
[8]
Membership inference attacks on machine learning: A survey,
H. Hu, Z. Salcic, L. Sun, G. Dobbie, P. S. Yu, and X. Zhang, “Membership inference attacks on machine learning: A survey,”ACM Computing Surveys (CSUR), vol. 54, no. 11s, pp. 1–37, 2022
2022
-
[9]
Do membership inference attacks work on large language models?, 2024
M. Duan, A. Suri, N. Mireshghallah, S. Min, W. Shi, L. Zettlemoyer, Y . Tsvetkov, Y . Choi, D. Evans, and H. Hajishirzi, “Do membership inference attacks work on large language models?,”arXiv preprint arXiv:2402.07841, 2024
-
[10]
Membership infer- ence attacks against text-to-image generation models,
Y . Wu, N. Yu, Z. Li, M. Backes, and Y . Zhang, “Membership infer- ence attacks against text-to-image generation models,”arXiv preprint arXiv:2210.00968, 2022
-
[11]
Ts-ramia: Membership inference attacks for symbolic music generation models,
Y . Liu, P. Zhang, Z. Li, K. Zhang, S. He, Y . Li, K. Xu, S. Li,et al., “Ts-ramia: Membership inference attacks for symbolic music generation models,” in1st International Workshop on Emerging AI Technologies for Music, 2026
2026
-
[12]
Membership inference attack against music diffusion models via generative manifold perturbation,
Y . Liu, P. Zhang, R. Sang, Z. Li, Y . Tan, Y . Cai, and S. Li, “Membership inference attack against music diffusion models via generative manifold perturbation,”arXiv preprint arXiv:2602.01645, 2026
-
[13]
Assessing the effectiveness of membership inference on generative music,
K. Chow, O. Samiullah, V . Sridhar, and H. Zhang, “Assessing the effectiveness of membership inference on generative music,”arXiv preprint arXiv:2512.21762, 2025
-
[14]
Membership and dataset in- ference attacks on large audio generative models,
J. Proboszcz, P. Kochanski, K. Korszun, D. Crisostomi, G. Strano, E. Rodol `a, K. Deja, and J. Dubinski, “Membership and dataset in- ference attacks on large audio generative models,”arXiv preprint arXiv:2512.09654, 2025
-
[15]
Understanding and mitigating copying in diffusion models,
G. Somepalli, V . Singla, M. Goldblum, J. Geiping, and T. Goldstein, “Understanding and mitigating copying in diffusion models,”Advances in Neural Information Processing Systems, vol. 36, pp. 47783–47803, 2023
2023
-
[16]
Extracting training data from diffusion models,
N. Carlini, J. Hayes, M. Nasr, M. Jagielski, V . Sehwag, F. Tram `er, B. Balle, D. Ippolito, and E. Wallace, “Extracting training data from diffusion models,”arXiv preprint arXiv:2301.13188, 2023
-
[17]
Audioldm 2: Learning holistic audio generation with self-supervised pretraining,
H. Liu, Y . Yuan, X. Liu, X. Mei, Q. Kong, Q. Tian, Y . Wang, W. Wang, Y . Wang, and M. D. Plumbley, “Audioldm 2: Learning holistic audio generation with self-supervised pretraining,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 2871–2883, 2024
2024
-
[18]
Mustango: Toward controllable text-to-music generation,
J. Melechovsky, Z. Guo, D. Ghosal, N. Majumder, D. Herremans, and S. Poria, “Mustango: Toward controllable text-to-music generation,” in Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 8293–8316, 2024
2024
-
[19]
A hierar- chical latent vector model for learning long-term structure in music,
A. Roberts, J. Engel, C. Raffel, C. Hawthorne, and D. Eck, “A hierar- chical latent vector model for learning long-term structure in music,” in International conference on machine learning, pp. 4364–4373, PMLR, 2018
2018
-
[20]
Musegan: Multi-track sequential generative adversarial networks for symbolic music generation and accompaniment,
H.-W. Dong, W.-Y . Hsiao, L.-C. Yang, and Y .-H. Yang, “Musegan: Multi-track sequential generative adversarial networks for symbolic music generation and accompaniment,” inProceedings of the AAAI conference on artificial intelligence, vol. 32, 2018
2018
-
[21]
Riffusion: Stable Diffusion for Real-time Music Generation
S. Forsgren and H. Martiros, “Riffusion: Stable Diffusion for Real-time Music Generation.” https://riffusion.com/about, 2022
2022
-
[22]
Joint audio and symbolic conditioning for temporally controlled text-to-music generation,
O. Tal, A. Ziv, I. Gat, F. Kreuk, and Y . Adi, “Joint audio and symbolic conditioning for temporally controlled text-to-music generation,”arXiv preprint arXiv:2406.10970, 2024
-
[23]
White-box vs black-box: Bayes optimal strategies for membership inference,
A. Sablayrolles, M. Douze, C. Schmid, Y . Ollivier, and H. J ´egou, “White-box vs black-box: Bayes optimal strategies for membership inference,” inInternational Conference on Machine Learning, pp. 5558– 5567, PMLR, 2019
2019
-
[24]
A general framework for data- use auditing of ml models,
Z. Huang, N. Z. Gong, and M. K. Reiter, “A general framework for data- use auditing of ml models,” inProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, pp. 1300–1314, 2024
2024
-
[25]
Instance-level data-use auditing of visual ml models,
Z. Huang, N. Z. Gong, and M. K. Reiter, “Instance-level data-use auditing of visual ml models,”arXiv preprint arXiv:2503.22413, 2025
-
[26]
Genai confessions: Black-box membership inference for generative image models,
M. Bohacek and H. Farid, “Genai confessions: Black-box membership inference for generative image models,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 321–330, 2025
2025
-
[27]
J. Zhu and L. Wang, “Auditing data provenance in real-world text-to- image diffusion models for privacy and copyright protection,”arXiv preprint arXiv:2506.11434, 2025
-
[28]
Text-to-audio generation using instruction-tuned LLM and latent diffusion model,
G. Deepanway, M. Navonil, M. Ambuj, and P. Soujanya, “Text-to-audio generation using instruction-tuned llm and latent diffusion model,”arXiv preprint arXiv:2304.13731, 2023
-
[29]
FMA: A Dataset For Music Analysis
M. Defferrard, K. Benzi, P. Vandergheynst, and X. Bresson, “Fma: A dataset for music analysis,”arXiv preprint arXiv:1612.01840, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[30]
Language models are unsupervised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever,et al., “Language models are unsupervised multitask learners,”OpenAI blog, vol. 1, no. 8, p. 9, 2019
2019
-
[31]
Music flamingo: Scaling music understanding in audio language models,
S. Ghosh, A. Goel, L. Koroshinadze, S.-g. Lee, Z. Kong, J. F. Santos, R. Duraiswami, D. Manocha, W. Ping, M. Shoeybi,et al., “Music flamingo: Scaling music understanding in audio language models,”arXiv preprint arXiv:2511.10289, 2025
-
[32]
Jam: A tiny flow-based song generator with fine-grained controllability and aesthetic alignment,
R. Liu, C.-Y . Hung, N. Majumder, T. Gautreaux, A. A. Bagherzadeh, C. Li, D. Herremans, and S. Poria, “Jam: A tiny flow-based song generator with fine-grained controllability and aesthetic alignment,” arXiv preprint arXiv:2507.20880, 2025
-
[33]
Yue: Scaling open foundation models for long- form music generation,
R. Yuan, H. Lin, S. Guo, G. Zhang, J. Pan, Y . Zang, H. Liu, Y . Liang, W. Ma, X. Du,et al., “Yue: Scaling open foundation models for long- form music generation,”arXiv preprint arXiv:2503.08638, 2025
-
[34]
Mert: Acoustic music understanding model with large-scale self-supervised training,
L. Yizhi, R. Yuan, G. Zhang, Y . Ma, X. Chen, H. Yin, C. Xiao, C. Lin, A. Ragni, E. Benetos,et al., “Mert: Acoustic music understanding model with large-scale self-supervised training,” inThe Twelfth International Conference on Learning Representations, 2023
2023
-
[35]
Y . Li, R. Yuan, G. Zhang, Y . Ma, C. Lin, X. Chen, A. Ragni, H. Yin, Z. Hu, H. He,et al., “Map-music2vec: A simple and effective baseline for self-supervised music audio representation learning,”arXiv preprint arXiv:2212.02508, 2022
-
[36]
High- fidelity audio compression with improved rvqgan,
R. Kumar, P. Seetharaman, A. Luebs, I. Kumar, and K. Kumar, “High- fidelity audio compression with improved rvqgan,”Advances in Neural Information Processing Systems, vol. 36, pp. 27980–27993, 2023
2023
-
[37]
Fx-encoder++: Extracting instrument-wise audio effects representations from mixtures,
Y .-T. Yeh, J. Koo, M. A. Mart´ınez-Ram´ırez, W.-H. Liao, Y .-H. Yang, and Y . Mitsufuji, “Fx-encoder++: Extracting instrument-wise audio effects representations from mixtures,”arXiv preprint arXiv:2507.02273, 2025
-
[38]
Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation,
Y . Wu, K. Chen, T. Zhang, Y . Hui, T. Berg-Kirkpatrick, and S. Dubnov, “Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation,” inICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5, IEEE, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.