A Full-Pipeline Framework for Evaluating Membership Inference Attacks in Machine Learning
Pith reviewed 2026-06-29 09:18 UTC · model grok-4.3
The pith
A new framework evaluates membership inference attacks across the full machine learning pipeline using standardized threat models and metrics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a full-pipeline evaluation framework can systematically characterize privacy risks in machine learning by rigorously testing state-of-the-art membership inference attacks across diverse data, architecture, algorithm, and post-training configurations, under two formalized threat models and with three complementary metrics that account for different operational costs, ultimately distilling results into guidelines and providing an auditing toolkit.
What carries the argument
The full-pipeline evaluation framework that standardizes two threat models for adapting existing MIAs and deploys balanced accuracy plus thresholded metrics to measure privacy leakage across data preparation through post-training stages.
If this is right
- The effectiveness of particular MIA methodologies varies significantly depending on the assumed threat model.
- Attack efficacy is highly sensitive to the choice of evaluation metric in asymmetric cost scenarios.
- Distilled guidelines enable practitioners to select appropriate attacks and metrics for specific deployment contexts.
- The provided auditing toolkit supports systematic privacy assessments spanning the full pipeline.
Where Pith is reading between the lines
- The framework could guide the selection of pipeline stages to harden against privacy leakage in production systems.
- It may support evaluation of defenses or unlearning methods by providing consistent benchmarks across threat models.
- Emphasis on low-FPR metrics points toward applications in domains where false alarms carry high costs, such as medical data.
Load-bearing premise
Adapting existing MIAs to the two standardized threat models produces equitable benchmarks without altering their core behavior, while the framework inherently captures diverse operational contexts.
What would settle it
Finding that attack performance rankings and success rates stay essentially unchanged when switching between the two threat models or across the three metrics on the same set of pipeline configurations would undermine the sensitivity result.
Figures



read the original abstract
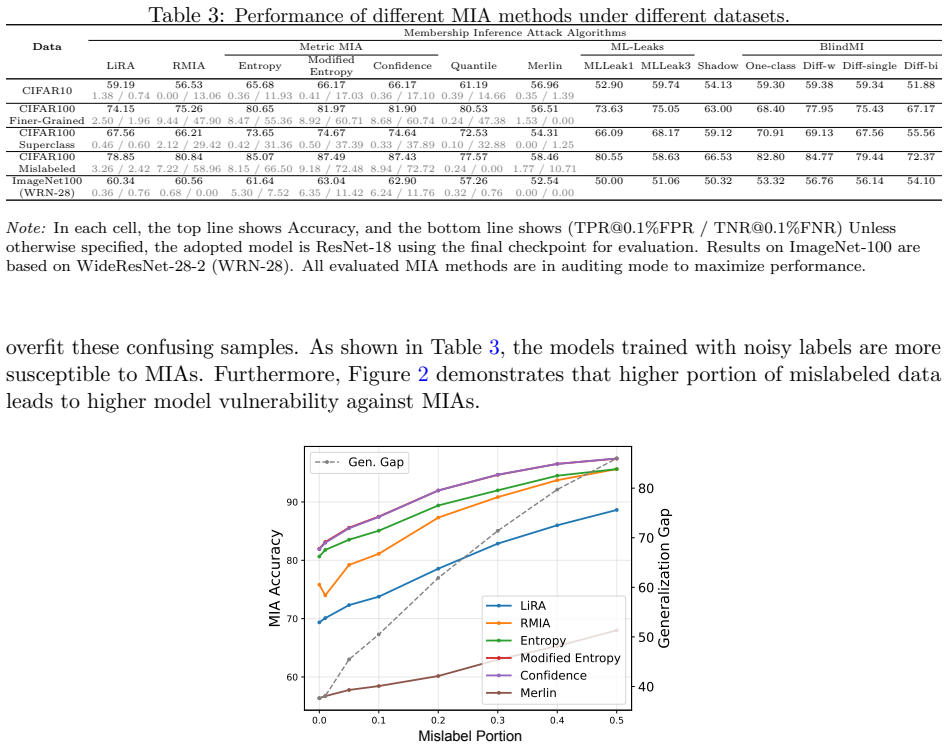
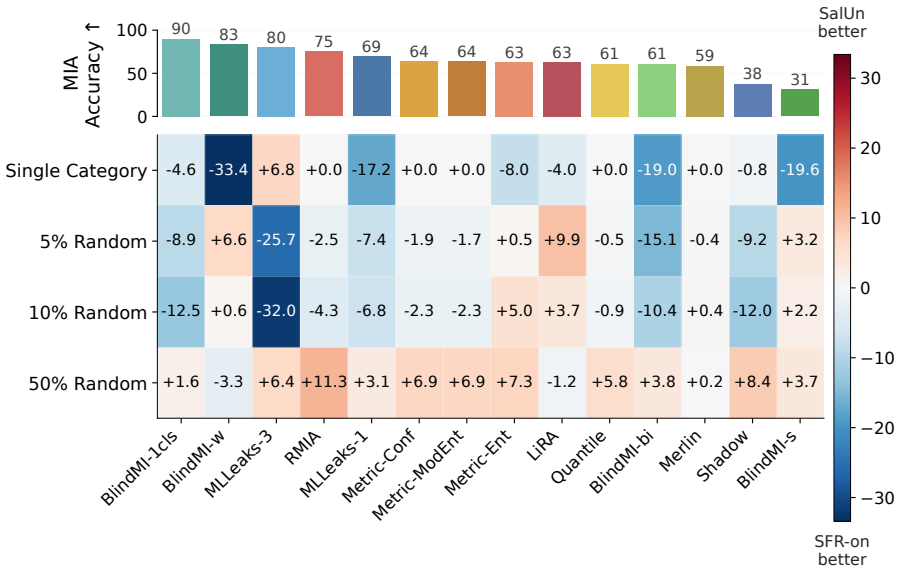
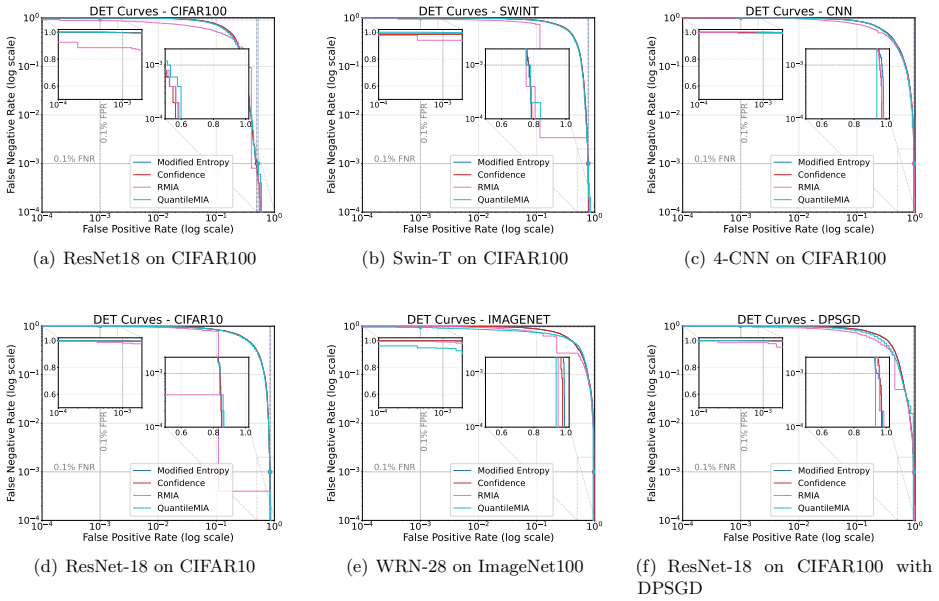
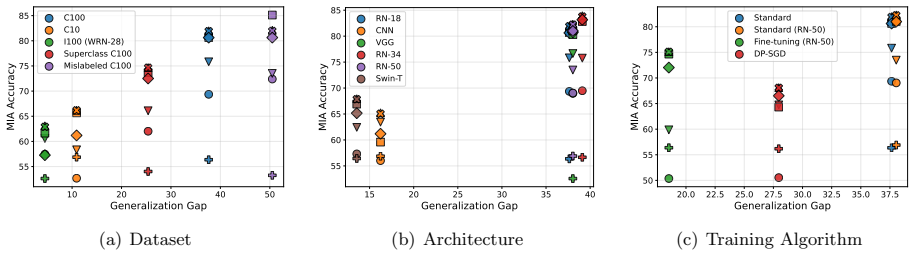
While Membership Inference Attacks (MIAs) are the prevailing method for identifying training data, their application has expanded into privacy auditing and machine unlearning. Nevertheless, the field lacks a systematic framework for evaluating how different contexts affect MIA efficacy. Without such a characterization, practitioners risk deploying algorithms that perform well on benchmarks but become statistically irrelevant when faced with the nuances of specific, real-world datasets. To bridge this gap and provide actionable insights, we introduce a comprehensive evaluation framework that systematically characterizes privacy risks across the entire machine learning pipeline, spanning data, architectures, algorithms, and post-training modules. Designed to inherently capture diverse operational contexts, our framework rigorously evaluates state-of-the-art MIAs across a broad spectrum of training configurations. To account for varying misclassification costs in real-world deployments, we employ three complementary metrics: Balanced Accuracy for symmetric costs, alongside TPR at low FPR (or TNR at low FNR) for asymmetric scenarios where false alarms or missed detections are strictly penalized. Furthermore, recognizing that existing MIAs assume divergent adversary capabilities, we formalize two standardized threat models and adapt these attacks into corresponding variants to ensure an equitable benchmark. Extensive empirical evaluations demonstrate that the efficacy of specific MIA methodologies is highly sensitive to the assumed threat models and chosen evaluation metrics. Ultimately, we distill these findings into actionable guidelines and provide a ready-to-use auditing toolkit, empowering practitioners to conduct better privacy assessments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a comprehensive evaluation framework for Membership Inference Attacks (MIAs) that systematically characterizes privacy risks across the full ML pipeline (data, architectures, algorithms, post-training modules). It formalizes two standardized threat models, adapts prior MIAs into variants for equitable benchmarking, employs three complementary metrics (Balanced Accuracy for symmetric costs; TPR at low FPR or TNR at low FNR for asymmetric costs), demonstrates via empirical evaluations that MIA efficacy is highly sensitive to threat models and metrics, and distills findings into actionable guidelines plus a ready-to-use auditing toolkit.
Significance. If the central assumption that adapted MIAs preserve original attack behavior holds, the framework could provide a valuable standardized tool for privacy auditing and unlearning evaluation, addressing the lack of systematic context-aware assessment in the field. The multi-metric approach and toolkit are practical strengths that could improve real-world applicability.
major comments (1)
- [Methods (threat model formalization and MIA adaptation)] The section on formalizing the two threat models and adapting existing MIAs (described as standardizing adversary capabilities to produce equitable benchmarks) provides no explicit equivalence verification between original and adapted attack variants (e.g., no comparison of decision boundaries, feature usage, or statistical properties). This assumption is load-bearing for the claim that efficacy differences reflect genuine sensitivity to threat models rather than artifacts of the adaptation process.
minor comments (1)
- [Abstract] The abstract states that the framework 'inherently capture[s] diverse operational contexts' but does not specify how this is enforced in the pipeline design or evaluation protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to the major comment on the equivalence verification of adapted MIAs and outline the planned revisions.
read point-by-point responses
-
Referee: [Methods (threat model formalization and MIA adaptation)] The section on formalizing the two threat models and adapting existing MIAs (described as standardizing adversary capabilities to produce equitable benchmarks) provides no explicit equivalence verification between original and adapted attack variants (e.g., no comparison of decision boundaries, feature usage, or statistical properties). This assumption is load-bearing for the claim that efficacy differences reflect genuine sensitivity to threat models rather than artifacts of the adaptation process.
Authors: We agree that an explicit verification of equivalence between the original and adapted MIA variants is necessary to support our claims that efficacy differences reflect sensitivity to threat models. The current manuscript does not provide such verification. In the revised version, we will add a new subsection (or appendix) with quantitative comparisons, including decision boundaries via ROC curves and score distributions, feature usage via correlation or importance analysis, and statistical properties via distribution tests (e.g., KS statistic) on attack scores. These checks will be performed on representative datasets and models from our experiments to confirm that adaptations preserve core attack behavior. revision: yes
Circularity Check
No circularity: new framework introduction is self-contained
full rationale
The paper introduces a new evaluation framework for MIAs across the ML pipeline, formalizes two threat models, adapts existing attacks for equitable benchmarking, and reports empirical results with three metrics. No equations, fitted parameters, or derivations are present that reduce to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The adaptation of attacks is presented as a methodological standardization step without any claim that it preserves properties by definition or that results are forced by prior self-work. The central claim (framework enables systematic characterization) is independent content, not a renaming or self-definition. This matches the default case of a methodological contribution with no circularity signal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep learning with differential privacy
Martin Abadi, Andy Chu, Ian Goodfellow, H Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. Deep learning with differential privacy. InProceedings of the 2016 ACM SIGSAC conference on computer and communications security, pages 308–318, 2016
2016
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023. 17
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Scalable membership inference attacks via quantile regression.Advances in Neural Information Processing Systems, 36, 2024
Martin Bertran, Shuai Tang, Aaron Roth, Michael Kearns, Jamie H Morgenstern, and Steven Z Wu. Scalable membership inference attacks via quantile regression.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[4]
Membership inference attacks from first principles
Nicholas Carlini, Steve Chien, Milad Nasr, Shuang Song, Andreas Terzis, and Florian Tramer. Membership inference attacks from first principles. In2022 IEEE Symposium on Security and Privacy (SP), pages 1897–1914. IEEE, 2022
1914
-
[5]
BERT: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Confer- ence of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186. Associatio...
2019
-
[6]
Salun: Empowering machine unlearning via gradient-based weight saliency in both image classification and generation
Chongyu Fan, Jiancheng Liu, Yihua Zhang, Eric Wong, Dennis Wei, and Sijia Liu. Salun: Empowering machine unlearning via gradient-based weight saliency in both image classification and generation. InInternational Conference on Learning Representations, 2023
2023
-
[7]
Salun: Empowering machine unlearning via gradient-based weight saliency in both image classification and generation
Chongyu Fan, Jiancheng Liu, Yihua Zhang, Eric Wong, Dennis Wei, and Sijia Liu. Salun: Empowering machine unlearning via gradient-based weight saliency in both image classification and generation. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[8]
Explaining and harnessing adver- sarial examples
Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adver- sarial examples. InInternational Conference on Learning Representations, 2015
2015
-
[9]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[10]
Unified gradient-based machine unlearning with remain geometry enhancement
Zhehao Huang, Xinwen Cheng, JingHao Zheng, Haoran Wang, Zhengbao He, Tao Li, and Xiaolin Huang. Unified gradient-based machine unlearning with remain geometry enhancement. arXiv preprint arXiv:2409.19732, 2024
-
[11]
Bo Hui, Yuchen Yang, Haolin Yuan, Philippe Burlina, Neil Zhenqiang Gong, and Yinzhi Cao. Practical blind membership inference attack via differential comparisons.arXiv preprint arXiv:2101.01341, 2021
-
[12]
Revisiting membership inference under realistic assumptions.arXiv preprint arXiv:2005.10881, 2020
Bargav Jayaraman, Lingxiao Wang, Katherine Knipmeyer, Quanquan Gu, and David Evans. Revisiting membership inference under realistic assumptions.arXiv preprint arXiv:2005.10881, 2020
-
[13]
Learning multiple layers of features from tiny images
Alex Krizhevsky et al. Learning multiple layers of features from tiny images. 2009
2009
-
[14]
Imagenet classification with deep convolutional neural networks.Advances in neural information processing systems, 25, 2012
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks.Advances in neural information processing systems, 25, 2012
2012
-
[15]
{ML-Doctor}: Holistic risk assessment of inference attacks against machine learning models
Yugeng Liu, Rui Wen, Xinlei He, Ahmed Salem, Zhikun Zhang, Michael Backes, Emiliano De Cristofaro, Mario Fritz, and Yang Zhang. {ML-Doctor}: Holistic risk assessment of inference attacks against machine learning models. In31st USENIX Security Symposium (USENIX Security 22), pages 4525–4542, 2022. 18
2022
-
[16]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. InProceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021
2021
-
[17]
Quantifying privacy risks of masked language models using membership inference attacks
Fatemehsadat Mireshghallah, Kartik Goyal, Archit Uniyal, Taylor Berg-Kirkpatrick, and Reza Shokri. Quantifying privacy risks of masked language models using membership inference attacks. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 8332–8347, 2022
2022
-
[18]
A survey on membership inference attacks and defenses in machine learning.Journal of Information and Intelligence, 2024
Jun Niu, Peng Liu, Xiaoyan Zhu, Kuo Shen, Yuecong Wang, Haotian Chi, Yulong Shen, Xiaohong Jiang, Jianfeng Ma, and Yuqing Zhang. A survey on membership inference attacks and defenses in machine learning.Journal of Information and Intelligence, 2024
2024
-
[19]
Comparing different membership inference attacks with a comprehensive benchmark.IEEE Transactions on Information Forensics and Security, 2025
Jun Niu, Xiaoyan Zhu, Moxuan Zeng, Ge Zhang, Qingyang Zhao, Chunhui Huang, Yangming Zhang, Suyu An, Yangzhong Wang, Xinghui Yue, et al. Comparing different membership inference attacks with a comprehensive benchmark.IEEE Transactions on Information Forensics and Security, 2025
2025
-
[20]
Berg, and Li Fei-Fei
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. ImageNet Large Scale Visual Recognition Challenge.International Journal of Computer Vision (IJCV), 115(3):211–252, 2015
2015
-
[21]
Ahmed Salem, Yang Zhang, Mathias Humbert, Pascal Berrang, Mario Fritz, and Michael Backes. Ml-leaks: Model and data independent membership inference attacks and defenses on machine learning models.arXiv preprint arXiv:1806.01246, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[22]
Detecting Pretraining Data from Large Language Models
Weijia Shi, Anirudh Ajith, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, and Luke Zettlemoyer. Detecting pretraining data from large language models.arXiv preprint arXiv:2310.16789, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Membership inference attacks against machine learning models
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership inference attacks against machine learning models. In2017 IEEE symposium on security and privacy (SP), pages 3–18. IEEE, 2017
2017
-
[24]
Very deep convolutional networks for large-scale image recogni- tion
K Simonyan and A Zisserman. Very deep convolutional networks for large-scale image recogni- tion. In3rd International Conference on Learning Representations (ICLR 2015). Computational and Biological Learning Society, 2015
2015
-
[25]
Systematic evaluation of privacy risks of machine learning models
Liwei Song and Prateek Mittal. Systematic evaluation of privacy risks of machine learning models. In30th USENIX Security Symposium (USENIX Security 21), pages 2615–2632, 2021
2021
-
[26]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[27]
Membership inference attacks as privacy tools: Reliability, disparity and ensemble
Zhiqi Wang, Chengyu Zhang, Yuetian Chen, Nathalie Baracaldo, Swanand R Kadhe, and Lei Yu. Membership inference attacks as privacy tools: Reliability, disparity and ensemble. In Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, pages 1724–1738, 2025. 19
2025
-
[28]
Privacy risk in machine learning: Analyzing the connection to overfitting
Samuel Yeom, Irene Giacomelli, Matt Fredrikson, and Somesh Jha. Privacy risk in machine learning: Analyzing the connection to overfitting. In2018 IEEE 31st computer security foundations symposium (CSF), pages 268–282. IEEE, 2018
2018
-
[29]
Wide residual networks
Sergey Zagoruyko and Nikos Komodakis. Wide residual networks. InBritish Machine Vision Conference 2016. British Machine Vision Association, 2016
2016
-
[30]
Low-cost high-power membership inference attacks
Sajjad Zarifzadeh, Philippe Liu, and Reza Shokri. Low-cost high-power membership inference attacks. InForty-first International Conference on Machine Learning, 2024
2024
-
[31]
Understanding deep learning requires rethinking generalization
Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. Understanding deep learning requires rethinking generalization. InInternational Conference on Learning Representations, 2017
2017
-
[32]
Visual interpretability for deep learning: a survey
Quan-shi Zhang and Song-Chun Zhu. Visual interpretability for deep learning: a survey. Frontiers of Information Technology & Electronic Engineering, 19(1):27–39, 2018
2018
-
[33]
Deep leakage from gradients.Advances in neural information processing systems, 32, 2019
Ligeng Zhu, Zhijian Liu, and Song Han. Deep leakage from gradients.Advances in neural information processing systems, 32, 2019. A Additional Experimental Results A.1 Performance of Target Model in the Experiments To indicate the overfitting degree of different settings, we summarize the performance of different model architectures and the performance of m...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.