Distilling Safe LLM Systems via Soft Prompts for On Device Settings
Pith reviewed 2026-06-27 17:14 UTC · model grok-4.3
The pith
Soft prompt distillation transfers guard model safety to on-device LLMs more effectively than other efficient methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By training soft prompts using distillation objectives based on total variation distance and KL divergence, safety behaviors from a larger guard model can be transferred into a small set of prompt parameters. This yields better safety versus usefulness trade-offs than LoRA adapters, steering vectors, or direct optimization, across multiple model architectures, with negligible inference overhead.
What carries the argument
Distillation of safety behaviors from guard models into learned soft prompts using total variation and KL divergence losses.
If this is right
- Superior safety-usefulness balance on benchmarks
- Minimal extra memory and compute needed at inference time
- Consistent outperformance over LoRA, steering vectors, and direct methods
- Applicable across various LLM architectures
Where Pith is reading between the lines
- This could allow safe LLM use on consumer hardware without sending data to the cloud
- The method might extend to distilling other behaviors like style or factuality into prompts
- Testing on more diverse user queries could reveal limits not seen in benchmarks
Load-bearing premise
The safety alignment learned in the soft prompts will continue to work for new types of user requests and on model architectures not included in the tests.
What would settle it
An experiment where the soft-prompt model is attacked with novel jailbreak prompts or run on a different base model and shows higher unsafe response rates than a LoRA-based alternative.
Figures


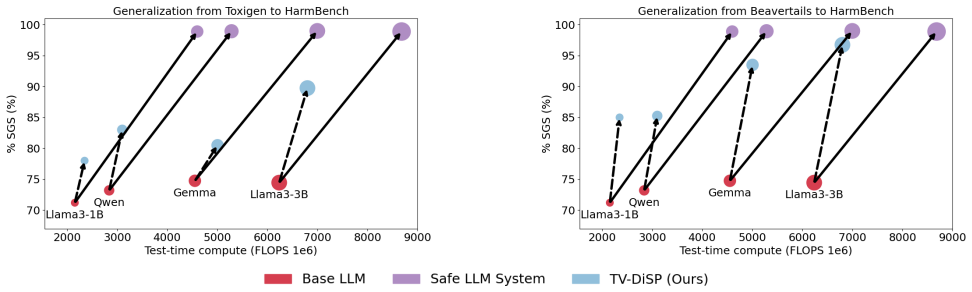
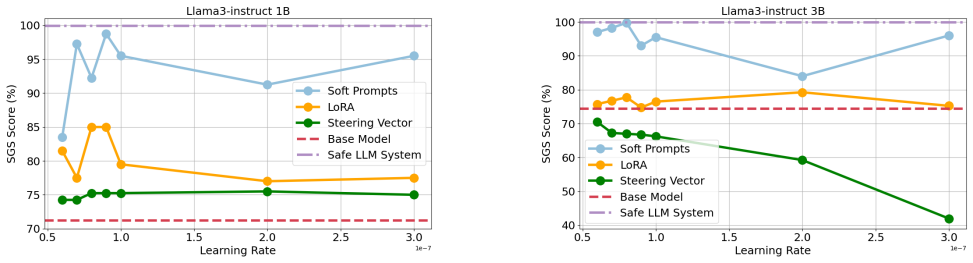
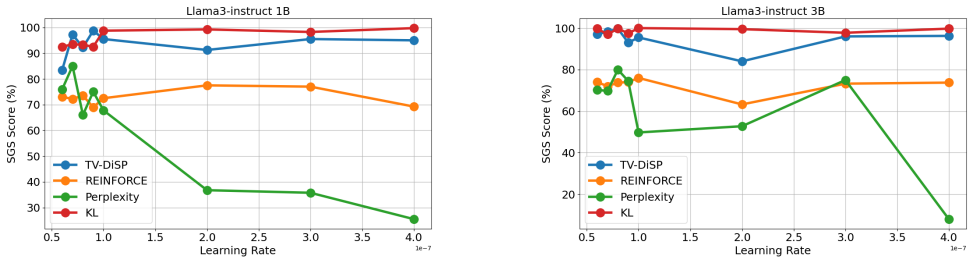
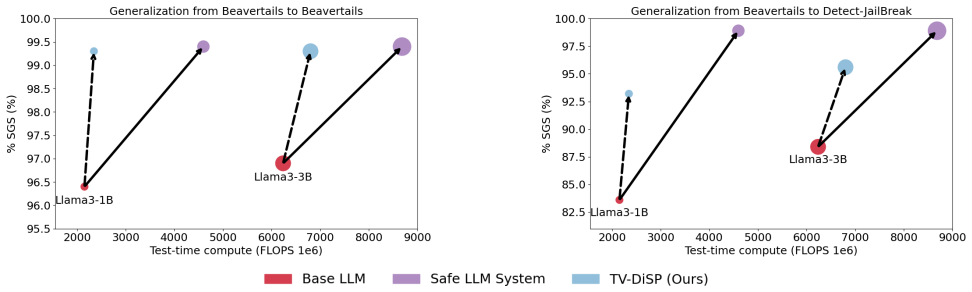
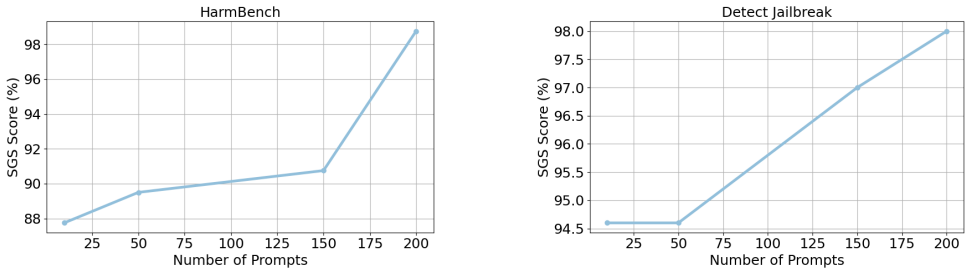




read the original abstract
Deploying safe large language models (LLMs) on resource-constrained edge devices presents a critical challenge: while dual-model systems combining LLMs with guard models provide effective safety guarantees, their substantial memory and computational demands make them prohibitively expensive for on-device deployment. This paper presents a comprehensive study of parameter-efficient safety alignment methods for resource-constrained settings. Through systematic evaluation across multiple LLM architectures, training objectives, and parameter-efficient fine-tuning approaches, we identify that soft prompts combined with distillation-based training consistently outperform alternative methods. We introduce distillation frameworks based on total variation and KL divergence that effectively transfer safety behaviors from guard models into learned soft prompts. Our evaluations on various benchmarks demonstrate that this combination achieves superior safety-usefulness trade-offs compared to LoRA adapters, steering vectors, and direct optimization methods, while requiring minimal additional memory and compute at inference time. These findings establish soft prompt distillation as the preferred approach for safety alignment in on-device LLM deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that soft prompts trained via distillation (using total variation and KL divergence objectives) from guard models outperform LoRA adapters, steering vectors, and direct optimization for safety alignment of LLMs in on-device settings. It reports superior safety-usefulness trade-offs on various benchmarks while incurring only minimal additional memory and compute at inference time, positioning soft-prompt distillation as the preferred method over dual-model guard systems.
Significance. If the empirical results hold under broader testing, the approach could meaningfully reduce the resource cost of safe LLM deployment on edge devices by transferring guard-model behaviors into lightweight soft prompts without requiring a second model at inference.
major comments (2)
- [Abstract / Evaluation] The central claim of reliable safety-usefulness trade-offs rests on generalization beyond the evaluated benchmarks, yet the abstract provides no indication that test distributions include adversarial jailbreaks, real-world prompt diversity, or distribution shift to unseen model architectures (as flagged in the stress-test note).
- [Abstract] Soundness is limited because the provided text contains only high-level claims with no quantitative results, error bars, benchmark details, or statistical evidence; without these, it is impossible to verify whether the reported outperformance over baselines is statistically meaningful or reproducible.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments on the manuscript. We address each major comment below and have revised the abstract where it improves clarity on the evaluation scope without altering the paper's core claims.
read point-by-point responses
-
Referee: [Abstract / Evaluation] The central claim of reliable safety-usefulness trade-offs rests on generalization beyond the evaluated benchmarks, yet the abstract provides no indication that test distributions include adversarial jailbreaks, real-world prompt diversity, or distribution shift to unseen model architectures (as flagged in the stress-test note).
Authors: The paper's experimental section evaluates across multiple LLM architectures using benchmarks that explicitly include adversarial jailbreaks and diverse real-world-style prompts. The stress-test note acknowledges that results on completely unseen architectures represent a limitation rather than a full guarantee. We have revised the abstract to explicitly note the inclusion of adversarial testing and the range of benchmarks and architectures evaluated, while avoiding overstatement of generalization. revision: partial
-
Referee: [Abstract] Soundness is limited because the provided text contains only high-level claims with no quantitative results, error bars, benchmark details, or statistical evidence; without these, it is impossible to verify whether the reported outperformance over baselines is statistically meaningful or reproducible.
Authors: Abstracts are designed as concise overviews and standard practice in the field omits detailed statistics to meet length constraints. The full manuscript (Sections 4–5 and associated tables) reports quantitative results with means, standard deviations across multiple runs, benchmark specifications, and direct comparisons to LoRA, steering vectors, and direct optimization, enabling verification of statistical meaningfulness and reproducibility. revision: no
Circularity Check
No circularity: purely empirical evaluation with no derivation chain
full rationale
The paper is an empirical study comparing soft-prompt distillation (via total variation and KL) against LoRA, steering vectors, and direct optimization on safety-usefulness benchmarks. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation load-bearing uniqueness theorems appear in the provided text or abstract. All claims rest on reported benchmark results rather than any reduction of outputs to inputs by construction. Generalization to unseen distributions is a validity concern, not a circularity issue. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[3]
The malicious use of artificial intelligence: Forecasting
Miles Brundage, Shahar Avin, Jack Clark, Helen Toner, Peter Eckersley, Ben Garfinkel, Allan Dafoe, Paul Scharre, Thomas Zeitzoff, Bobby Filar, et al. The malicious use of artificial intelligence: Forecasting. Prevention, and Mitigation, 20, 2018
2018
-
[6]
Information theory: coding theorems for discrete memoryless systems
Imre Csisz \'a r and J \'a nos K \"o rner. Information theory: coding theorems for discrete memoryless systems. Cambridge University Press, 2011
2011
-
[7]
Qlora: Efficient finetuning of quantized llms
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms. Advances in neural information processing systems, 36: 0 10088--10115, 2023
2023
-
[10]
Figstep: Jailbreaking large vision-language models via typographic visual prompts
Yichen Gong, Delong Ran, Jinyuan Liu, Conglei Wang, Tianshuo Cong, Anyu Wang, Sisi Duan, and Xiaoyun Wang. Figstep: Jailbreaking large vision-language models via typographic visual prompts. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 23951--23959, 2025
2025
-
[13]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. ICLR, 1 0 (2): 0 3, 2022
2022
-
[15]
Beavertails: Towards improved safety alignment of llm via a human-preference dataset
Jiaming Ji, Mickel Liu, Josef Dai, Xuehai Pan, Chi Zhang, Ce Bian, Boyuan Chen, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. Beavertails: Towards improved safety alignment of llm via a human-preference dataset. Advances in Neural Information Processing Systems, 36: 0 24678--24704, 2023
2023
-
[18]
Li, Ann-Kathrin Dombrowski, Shashwat Goel, Long Phan, Gabriel Mukobi, Nathan Helm-Burger, Rassin Lababidi, Lennart Justen, Andrew B
Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D. Li, Ann-Kathrin Dombrowski, Shashwat Goel, Long Phan, Gabriel Mukobi, Nathan Helm-Burger, Rassin Lababidi, Lennart Justen, Andrew B. Liu, Michael Chen, Isabelle Barrass, Oliver Zhang, Xiaoyuan Zhu, Rishub Tamirisa, Bhrugu Bharathi, Adam Khoja, Zhenqi Zhao, Ariel ...
2024
-
[19]
Awq: Activation-aware weight quantization for on-device llm compression and acceleration
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for on-device llm compression and acceleration. Proceedings of Machine Learning and Systems, 6: 0 87--100, 2024
2024
-
[23]
Llama 2 responsible use guide
Meta. Llama 2 responsible use guide. 2024. URL https://ai.meta.com/static-resource/responsible-use-guide/
2024
-
[25]
Steering llama 2 via contrastive activation addition, 2024
Nina Panickssery, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Matt Turner. Steering llama 2 via contrastive activation addition, 2024. URL https://arxiv. org/abs/2312.06681
Pith/arXiv arXiv 2024
-
[26]
Lecture notes on information theory
Yury Polyanskiy and Yihong Wu. Lecture notes on information theory. Lecture Notes for ECE563 (UIUC) and, 6 0 (2012-2016): 0 7, 2014
2012
-
[27]
Empirical guidelines for deploying llms onto resource-constrained edge devices
Ruiyang Qin, Dancheng Liu, Chenhui Xu, Zheyu Yan, Zhaoxuan Tan, Zhenge Jia, Amir Nassereldine, Jiajie Li, Meng Jiang, Ahmed Abbasi, et al. Empirical guidelines for deploying llms onto resource-constrained edge devices. ACM Transactions on Design Automation of Electronic Systems, 2024
2024
-
[29]
``Do Anything Now'': Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models
Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, and Yang Zhang. ``Do Anything Now'': Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models . In ACM SIGSAC Conference on Computer and Communications Security (CCS) . ACM, 2024
2024
-
[31]
Activation addition: Steering language models without optimization
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J Vazquez, Ulisse Mini, and Monte MacDiarmid. Activation addition: Steering language models without optimization. arXiv e-prints, pages arXiv--2308, 2023
2023
-
[34]
Soft prompt recovers compressed llms, transferably
Zhaozhuo Xu, Zirui Liu, Beidi Chen, Shaochen Zhong, Yuxin Tang, Jue WANG, Kaixiong Zhou, Xia Hu, and Anshumali Shrivastava. Soft prompt recovers compressed llms, transferably. In Forty-first International Conference on Machine Learning, 2024 a . URL https://openreview.net/forum?id=muBJPCIqZT
2024
-
[35]
A Comprehensive Study of Jailbreak Attack versus Defense for Large Language Models , 2024 b
Zihao Xu, Yi Liu, Gelei Deng, Yuekang Li, and Stjepan Picek. A Comprehensive Study of Jailbreak Attack versus Defense for Large Language Models , 2024 b
2024
-
[36]
Prompt-driven llm safeguarding via directed representation optimization
Chujie Zheng, Fan Yin, Hao Zhou, Fandong Meng, Jie Zhou, Kai-Wei Chang, Minlie Huang, and Nanyun Peng. Prompt-driven llm safeguarding via directed representation optimization. CoRR, 2024
2024
-
[37]
Instruction-following evaluation for large language models, 2023
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models, 2023. URL https://arxiv.org/abs/2311.07911
Pith/arXiv arXiv 2023
-
[40]
Forty-first International Conference on Machine Learning , year=
Soft Prompt Recovers Compressed LLMs, Transferably , author=. Forty-first International Conference on Machine Learning , year=
-
[41]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[42]
Prevention, and Mitigation , volume=
The Malicious Use of Artificial Intelligence: Forecasting , author=. Prevention, and Mitigation , volume=
-
[43]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
A holistic approach to undesired content detection in the real world , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[44]
arXiv preprint arXiv:2312.06674 , year=
Llama guard: Llm-based input-output safeguard for human-ai conversations , author=. arXiv preprint arXiv:2312.06674 , year=
-
[45]
arXiv preprint arXiv:2412.07724 , year=
Granite guardian , author=. arXiv preprint arXiv:2412.07724 , year=
-
[46]
arXiv preprint arXiv:2309.16609 , year=
Qwen technical report , author=. arXiv preprint arXiv:2309.16609 , year=
-
[47]
arXiv preprint arXiv:2408.00118 , year=
Gemma 2: Improving open language models at a practical size , author=. arXiv preprint arXiv:2408.00118 , year=
-
[48]
arXiv preprint arXiv:2404.09932 , year=
Foundational challenges in assuring alignment and safety of large language models , author=. arXiv preprint arXiv:2404.09932 , year=
-
[49]
ACM Transactions on Design Automation of Electronic Systems , year=
Empirical guidelines for deploying llms onto resource-constrained edge devices , author=. ACM Transactions on Design Automation of Electronic Systems , year=
-
[50]
Proceedings of Machine Learning and Systems , volume=
Awq: Activation-aware weight quantization for on-device llm compression and acceleration , author=. Proceedings of Machine Learning and Systems , volume=
-
[51]
arXiv preprint arXiv:2411.17713 , year=
Llama Guard 3-1B-INT4: Compact and Efficient Safeguard for Human-AI Conversations , author=. arXiv preprint arXiv:2411.17713 , year=
-
[52]
Lecture Notes for ECE563 (UIUC) and , volume=
Lecture notes on information theory , author=. Lecture Notes for ECE563 (UIUC) and , volume=. 2014 , publisher=
2014
-
[53]
arXiv preprint arXiv:2204.05862 , year=
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
-
[54]
Llama 2 responsible use guide , author=
-
[55]
arXiv preprint arXiv:2402.15911 , year=
Prp: Propagating universal perturbations to attack large language model guard-rails , author=. arXiv preprint arXiv:2402.15911 , year=
-
[56]
arXiv preprint arXiv:2009.03300 , year=
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
Pith/arXiv arXiv 2009
-
[57]
arXiv preprint arXiv:2310.04451 , year=
Autodan: Generating stealthy jailbreak prompts on aligned large language models , author=. arXiv preprint arXiv:2310.04451 , year=
-
[58]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Figstep: Jailbreaking large vision-language models via typographic visual prompts , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[59]
arXiv preprint arXiv:2307.15043 , year=
Universal and transferable adversarial attacks on aligned language models , author=. arXiv preprint arXiv:2307.15043 , year=
-
[60]
arXiv preprint arXiv:2402.04249 , year=
Harmbench: A standardized evaluation framework for automated red teaming and robust refusal , author=. arXiv preprint arXiv:2402.04249 , year=
-
[61]
arXiv preprint arXiv:2404.01318 , year=
Jailbreakbench: An open robustness benchmark for jailbreaking large language models , author=. arXiv preprint arXiv:2404.01318 , year=
-
[62]
arXiv preprint arXiv:2203.09509 , year=
Toxigen: A large-scale machine-generated dataset for adversarial and implicit hate speech detection , author=. arXiv preprint arXiv:2203.09509 , year=
-
[63]
arXiv preprint arXiv:2310.12773 , year=
Safe rlhf: Safe reinforcement learning from human feedback , author=. arXiv preprint arXiv:2310.12773 , year=
-
[64]
arXiv preprint arXiv:2405.07863 , year=
Rlhf workflow: From reward modeling to online rlhf , author=. arXiv preprint arXiv:2405.07863 , year=
-
[65]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[66]
Advances in neural information processing systems , volume=
Qlora: Efficient finetuning of quantized llms , author=. Advances in neural information processing systems , volume=
-
[68]
arXiv e-prints , pages=
Activation addition: Steering language models without optimization , author=. arXiv e-prints , pages=
-
[69]
Steering llama 2 via contrastive activation addition, 2024 , author=
2024
-
[70]
arXiv preprint arXiv:2311.09433 , year=
Trojan activation attack: Red-teaming large language models using activation steering for safety-alignment , author=. arXiv preprint arXiv:2311.09433 , year=
-
[71]
Advances in Neural Information Processing Systems , volume=
Beavertails: Towards improved safety alignment of llm via a human-preference dataset , author=. Advances in Neural Information Processing Systems , volume=
-
[72]
2011 , publisher=
Information theory: coding theorems for discrete memoryless systems , author=. 2011 , publisher=
2011
-
[73]
Xinyue Shen and Zeyuan Chen and Michael Backes and Yun Shen and Yang Zhang , title =
-
[74]
2024 , eprint =
Zihao Xu and Yi Liu and Gelei Deng and Yuekang Li and Stjepan Picek , title =. 2024 , eprint =
2024
-
[75]
2024 , eprint=
The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning , author=. 2024 , eprint=
2024
-
[76]
2017 , eprint=
Adam: A Method for Stochastic Optimization , author=. 2017 , eprint=
2017
-
[77]
arXiv preprint arXiv:2310.13345 , year=
An llm can fool itself: A prompt-based adversarial attack , author=. arXiv preprint arXiv:2310.13345 , year=
-
[78]
arXiv preprint arXiv:1707.06347 , year=
Proximal Policy Optimization Algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[79]
arXiv preprint arXiv:1412.6980 , year=
Adam: A Method for Stochastic Optimization , author=. arXiv preprint arXiv:1412.6980 , year=
-
[80]
CoRR , year=
Prompt-driven llm safeguarding via directed representation optimization , author=. CoRR , year=
-
[81]
Improving alignment and robustness with circuit breakers, 2024 , author=. URL https://arxiv. org/abs/2406.04313 , volume=
arXiv 2024
-
[82]
2023 , eprint=
Instruction-Following Evaluation for Large Language Models , author=. 2023 , eprint=
2023
-
[83]
arXiv preprint arXiv:2110.14168 , year=
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.