From Reasoning Traces to Reusable Modules: Understanding Compositional Generalization in Language Model Reasoning
Pith reviewed 2026-06-27 01:10 UTC · model grok-4.3
The pith
SFT supplies compound reasoning traces that embed atomic modules, while RL decomposes them to enable recombination on new problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
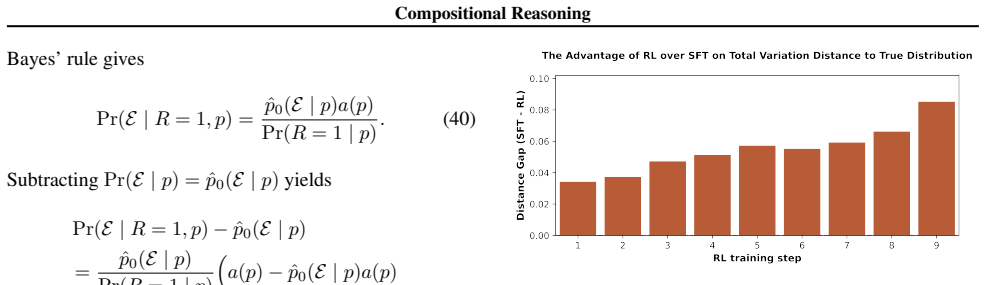
Within the hierarchical latent selection model, reasoning traces are produced by a cascade of discrete latent variables that choose reusable atomic modules consisting of local skills and routing mechanisms; SFT supplies the raw material by generating compound traces that embed these modules, and RL decomposes the traces to recover the latent modules, thereby enabling compositional generalization to new configurations.
What carries the argument
The hierarchical latent selection model, in which discrete latent variables successively select skills and routing mechanisms to generate each reasoning trace.
If this is right
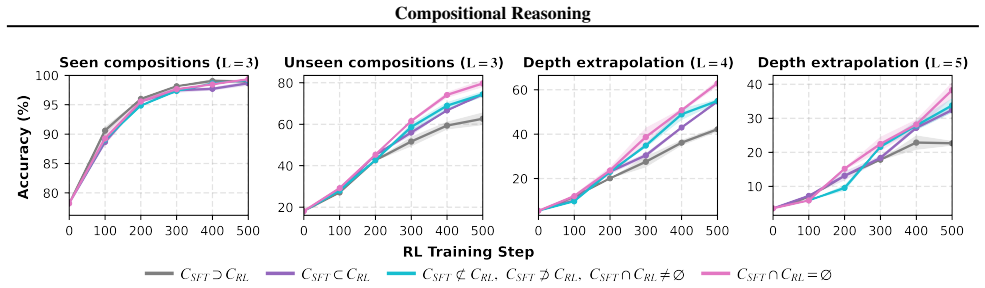
- RL extracts atomic modules from the compound traces supplied by SFT and recombines them to solve new problem configurations.
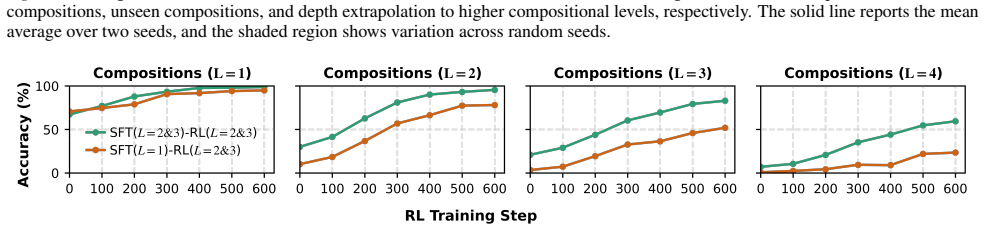
- Training on compound traces produces stronger generalization than training on isolated atomic modules.
- An effective protocol has SFT ensure coverage of all atomic modules through compositional traces while RL targets novel compositions outside the SFT support.
Where Pith is reading between the lines
- If the decomposition view is correct, SFT data collection should prioritize breadth of module combinations rather than single-skill examples.
- The same separation of roles may apply to other post-training stages such as preference tuning or synthetic data generation.
- Failures of compositional generalization in current models could be diagnosed by checking whether RL has successfully isolated the latent routing mechanisms.
Load-bearing premise
Real LLM reasoning traces are produced by a cascade of discrete latent selection variables that pick reusable atomic modules in the exact way the model formalizes.
What would settle it
An experiment in which RL applied to SFT-generated compound traces produces no improvement on novel compositions compared with SFT alone, or in which performance remains unchanged when the assumed latent module structure is removed from the training objective.
Figures
















read the original abstract
Post-training pipelines that combine supervised fine-tuning (SFT) with reinforcement learning (RL) have emerged as the key recipe for transforming large language models (LLMs) into robust reasoners. We argue that this combined success is driven by compositional generalization, which we formalize through a hierarchical latent selection model. In this framework, reasoning traces are generated by a cascade of discrete latent selection variables corresponding to reusable atomic modules, including both skills (local operations) and routing mechanisms (how intermediate information is selected, reused, and composed). Within this model, we theoretically show that SFT and RL play asymmetric, complementary roles: SFT supplies the raw module materials in compositional traces, and RL decomposes those traces to identify the latent atomic modules and enable compositional generalization. We design controlled experiments to validate this theory. Our results demonstrate that RL can extract atomic modules from compound traces supplied by SFT and recombine them to solve new configurations. Moreover, we find that training on compound traces yields stronger generalization than training on isolated atomic modules. Finally, we investigate the relationship between SFT and RL data and identify an effective protocol in which SFT ensures coverage of all atomic modules through compositional traces, while RL focuses on novel compositions outside the SFT support to drive exploration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a hierarchical latent selection model in which LLM reasoning traces are generated by cascades of discrete latent selection variables corresponding to reusable atomic modules (skills and routing mechanisms). It derives an asymmetry within this model whereby SFT supplies compositional traces containing the raw module materials while RL decomposes the traces to identify the latent modules and enable compositional generalization. Controlled experiments are presented to show that RL can extract and recombine modules from SFT-supplied compound traces, that training on compound traces outperforms training on isolated modules, and to recommend a protocol in which SFT ensures module coverage and RL targets novel compositions.
Significance. If the hierarchical latent selection model accurately describes the generative process underlying real LLM reasoning traces, the work supplies a theoretical account of why combined SFT+RL pipelines succeed at compositional generalization and yields a concrete protocol for allocating SFT and RL data. The controlled experiments demonstrate internal consistency of the model and the practical value of compound traces. Credit is due for the explicit formalization and the falsifiable protocol recommendation.
major comments (2)
- [Experiments] Experiments section: the controlled experiments generate traces from the hierarchical latent selection model itself rather than from actual LLM forward passes. This validates internal consistency of the derived asymmetry but leaves untested the load-bearing assumption that real reasoning traces are produced by discrete latent cascades of atomic modules and routing variables; without this mapping the protocol recommendation cannot be applied to LLM post-training.
- [Theoretical Analysis] Model definition and theoretical analysis: the asymmetric roles of SFT and RL follow directly from the model construction (SFT supplies traces, RL performs decomposition). The paper should provide either (a) an empirical test on real LLM traces or (b) an explicit discussion of how the central claim would be falsified if the discrete latent structure is absent in practice.
minor comments (2)
- [Abstract] The abstract and introduction should state more explicitly that the hierarchical model is an explanatory device rather than a claim derived from observed LLM data.
- [Model Definition] Notation for the latent selection variables and the decomposition objective could be introduced with a single running example to improve readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments correctly identify that our controlled experiments are synthetic (generated from the model) and that the asymmetry follows from the model definition. We agree these points warrant additional discussion of assumptions and falsifiability. Below we respond point-by-point and indicate planned revisions.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the controlled experiments generate traces from the hierarchical latent selection model itself rather than from actual LLM forward passes. This validates internal consistency of the derived asymmetry but leaves untested the load-bearing assumption that real reasoning traces are produced by discrete latent cascades of atomic modules and routing variables; without this mapping the protocol recommendation cannot be applied to LLM post-training.
Authors: We agree that the experiments use traces sampled from the hierarchical latent selection model rather than real LLM forward passes. This choice was deliberate to isolate the mechanism and demonstrate internal consistency of the SFT/RL asymmetry under the model's assumptions. We acknowledge this leaves the mapping to real LLM traces as an untested hypothesis. In revision we will add a new subsection (likely in the Discussion) that (i) explicitly states the assumption, (ii) outlines how the protocol would be applied if the discrete latent structure holds in practice, and (iii) suggests concrete empirical probes (e.g., activation patching or module extraction on real traces) that could test the mapping. This keeps the paper's scope focused on theory while addressing applicability concerns. revision: partial
-
Referee: [Theoretical Analysis] Model definition and theoretical analysis: the asymmetric roles of SFT and RL follow directly from the model construction (SFT supplies traces, RL performs decomposition). The paper should provide either (a) an empirical test on real LLM traces or (b) an explicit discussion of how the central claim would be falsified if the discrete latent structure is absent in practice.
Authors: The referee is correct that the asymmetry is a direct consequence of the model construction. We do not claim to have performed (a) an empirical test on real LLM traces; the work is positioned as a formalization supported by controlled experiments. For (b), we will add an explicit falsifiability paragraph: if real reasoning traces lack discrete latent cascades (e.g., if composition occurs via continuous or highly entangled representations), then (i) the predicted SFT/RL division of labor would not hold, (ii) training on compound traces would not outperform isolated modules, and (iii) the recommended protocol would need revision. We will also note observable signatures (modular reuse patterns, routing variables) that could be measured to falsify the model. revision: yes
Circularity Check
No significant circularity; model serves as explanatory formalization with separate controlled validation
full rationale
The paper introduces a hierarchical latent selection model as a framework to formalize how reasoning traces arise from cascades of discrete latent variables for atomic modules and routing. Within this model it derives the asymmetric roles of SFT (supplying traces) versus RL (decomposing to modules). Controlled experiments are then described to validate the theory by demonstrating extraction and recombination. No equations, self-citations, or fitted quantities are quoted that reduce the central claim to a definitional identity or to a prediction forced by the same fit. The derivation chain therefore remains self-contained against external benchmarks rather than circular by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reasoning traces are generated by a cascade of discrete latent selection variables corresponding to reusable atomic modules including skills and routing mechanisms.
invented entities (2)
-
hierarchical latent selection model
no independent evidence
-
atomic modules (skills and routing mechanisms)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2512.07783 , year=
On the interplay of pre-training, mid-training, and rl on reasoning language models , author=. arXiv preprint arXiv:2512.07783 , year=
-
[2]
arXiv preprint arXiv:2502.03373 , year=
Demystifying long chain-of-thought reasoning in llms , author=. arXiv preprint arXiv:2502.03373 , year=
-
[3]
arXiv preprint arXiv:2506.10947 , year=
Spurious rewards: Rethinking training signals in rlvr , author=. arXiv preprint arXiv:2506.10947 , year=
-
[4]
arXiv preprint arXiv:2509.21016 , year=
RL Grokking Recipe: How Does RL Unlock and Transfer New Algorithms in LLMs? , author=. arXiv preprint arXiv:2509.21016 , year=
-
[5]
ArXiv , year=
OpenAI o1 System Card , author=. ArXiv , year=
-
[6]
arXiv preprint arXiv:2501.12948 , year=
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
-
[7]
ArXiv , year=
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author=. ArXiv , year=
-
[8]
Shunyu Yao , title =
-
[9]
2025 , url =
Luke Zettlemoyer , title =. 2025 , url =
2025
-
[10]
ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models
Mingjie Liu and Shizhe Diao and Ximing Lu and Jian Hu and Xin Dong and Yejin Choi and Jan Kautz and Yi Dong , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2505.24864 , eprinttype =. 2505.24864 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.24864 2025
-
[11]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Ganqu Cui and Yuchen Zhang and Jiacheng Chen and Lifan Yuan and Zhi Wang and Yuxin Zuo and Haozhan Li and Yuchen Fan and Huayu Chen and Weize Chen and Zhiyuan Liu and Hao Peng and Lei Bai and Wanli Ouyang and Yu Cheng and Bowen Zhou and Ning Ding , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2505.22617 , eprinttype =. 2505.22617 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.22617 2025
-
[12]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu and Zheng Zhang and Ruofei Zhu and Yufeng Yuan and Xiaochen Zuo and Yu Yue and Tiantian Fan and Gaohong Liu and Lingjun Liu and Xin Liu and Haibin Lin and Zhiqi Lin and Bole Ma and Guangming Sheng and Yuxuan Tong and Chi Zhang and Mofan Zhang and Wang Zhang and Hang Zhu and Jinhua Zhu and Jiaze Chen and Jiangjie Chen and Chengyi Wang and Hongli ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.14476 2025
-
[13]
Lillicrap and Karen Simonyan and Demis Hassabis , title =
David Silver and Thomas Hubert and Julian Schrittwieser and Ioannis Antonoglou and Matthew Lai and Arthur Guez and Marc Lanctot and Laurent Sifre and Dharshan Kumaran and Thore Graepel and Timothy P. Lillicrap and Karen Simonyan and Demis Hassabis , title =. CoRR , volume =. 2017 , url =. 1712.01815 , timestamp =
Pith/arXiv arXiv 2017
-
[14]
David Silver and Aja Huang and Chris J. Maddison and Arthur Guez and Laurent Sifre and George van den Driessche and Julian Schrittwieser and Ioannis Antonoglou and Vedavyas Panneershelvam and Marc Lanctot and Sander Dieleman and Dominik Grewe and John Nham and Nal Kalchbrenner and Ilya Sutskever and Timothy P. Lillicrap and Madeleine Leach and Koray Kavuk...
-
[15]
OpenAI and Ilge Akkaya and Marcin Andrychowicz and Maciek Chociej and Mateusz Litwin and Bob McGrew and Arthur Petron and Alex Paino and Matthias Plappert and Glenn Powell and Raphael Ribas and Jonas Schneider and Nikolas Tezak and Jerry Tworek and Peter Welinder and Lilian Weng and Qiming Yuan and Wojciech Zaremba and Lei Zhang , title =. CoRR , volume =...
Pith/arXiv arXiv 2019
-
[16]
Psychological Review , volume=
Acquisition of Cognitive Skill , author=. Psychological Review , volume=
-
[17]
Jiayi Pan and Junjie Zhang and Xingyao Wang and Lifan Yuan and Hao Peng and Alane Suhr , title =
-
[18]
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
Weihao Zeng and Yuzhen Huang and Qian Liu and Wei Liu and Keqing He and Zejun Ma and Junxian He , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2503.18892 , eprinttype =. 2503.18892 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.18892 2025
-
[19]
Kakade and Cengiz Pehlevan and Samy Jelassi and Eran Malach , title =
Rosie Zhao and Alexandru Meterez and Sham M. Kakade and Cengiz Pehlevan and Samy Jelassi and Eran Malach , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2504.07912 , eprinttype =. 2504.07912 , timestamp =
-
[20]
COLM , year =
Zichen Liu and Changyu Chen and Wenjun Li and Penghui Qi and Tianyu Pang and Chao Du and Wee Sun Lee and Min Lin , title =. COLM , year =
-
[21]
Cognition , year=
Connectionism and cognitive architecture: A critical analysis , author=. Cognition , year=
-
[22]
Lake and Tomer D
Brenden M. Lake and Tomer D. Ullman and Joshua B. Tenenbaum and Samuel J. Gershman , title =. CoRR , volume =
-
[23]
2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Neural Module Networks , author=. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2016
-
[24]
ArXiv , year=
Learning Composable Chains-of-Thought , author=. ArXiv , year=
-
[25]
Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning
Tian Xie and Zitian Gao and Qingnan Ren and Haoming Luo and Yuqian Hong and Bryan Dai and Joey Zhou and Kai Qiu and Zhirong Wu and Chong Luo , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2502.14768 , eprinttype =. 2502.14768 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.14768 2025
-
[26]
Killian and Mikhail Yurochkin and Zhengzhong Liu and Eric P
Zhoujun Cheng and Shibo Hao and Tianyang Liu and Fan Zhou and Yutao Xie and Feng Yao and Yuexin Bian and Yonghao Zhuang and Nilabjo Dey and Yuheng Zha and Yi Gu and Kun Zhou and Yuqi Wang and Yuan Li and Richard Fan and Jianshu She and Chengqian Gao and Abulhair Saparov and Haonan Li and Taylor W. Killian and Mikhail Yurochkin and Zhengzhong Liu and Eric ...
-
[27]
Fang Wu and Weihao Xuan and Ximing Lu and Za. The Invisible Leash: Why. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2507.14843 , eprinttype =. 2507.14843 , timestamp =
-
[28]
ArXiv , year=
The Llama 3 Herd of Models , author=. ArXiv , year=
-
[29]
ArXiv , year=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. ArXiv , year=
-
[30]
ArXiv , year=
Stream of Search (SoS): Learning to Search in Language , author=. ArXiv , year=
-
[31]
Hwang and Jiangjiang Yang and Ronan Le Bras and Oyvind Tafjord and Christopher Wilhelm and Luca Soldaini and Noah A
Nathan Lambert and Jacob Daniel Morrison and Valentina Pyatkin and Shengyi Huang and Hamish Ivison and Faeze Brahman and Lester James Validad Miranda and Alisa Liu and Nouha Dziri and Xinxi Lyu and Yuling Gu and Saumya Malik and Victoria Graf and Jena D. Hwang and Jiangjiang Yang and Ronan Le Bras and Oyvind Tafjord and Christopher Wilhelm and Luca Soldai...
-
[32]
ArXiv , year=
RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment , author=. ArXiv , year=
-
[33]
ArXiv , year=
Spurious Rewards: Rethinking Training Signals in RLVR , author=. ArXiv , year=
-
[34]
ArXiv , year=
The Unreasonable Effectiveness of Entropy Minimization in LLM Reasoning , author=. ArXiv , year=
-
[35]
2025 , url=
Mirage or Method? How Model-Task Alignment Induces Divergent RL Conclusions , author=. 2025 , url=
2025
-
[36]
Oriol Vinyals and Igor Babuschkin and Wojciech M. Czarnecki and Micha. Grandmaster level in StarCraft. Nat. , volume =. 2019 , url =. doi:10.1038/S41586-019-1724-Z , timestamp =
-
[37]
The Knowledge Engineering Review , volume=
Pre-training with non-expert human demonstration for deep reinforcement learning , author=. The Knowledge Engineering Review , volume=. 2019 , publisher=
2019
-
[38]
Proceedings of the AAAI conference on artificial intelligence , volume=
Encoding human domain knowledge to warm start reinforcement learning , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[39]
arXiv preprint arXiv:2506.02355 , year=
Rewarding the Unlikely: Lifting GRPO Beyond Distribution Sharpening , author=. arXiv preprint arXiv:2506.02355 , year=
-
[40]
arXiv preprint arXiv:2506.14245 , year=
Reinforcement Learning with Verifiable Rewards Implicitly Incentivizes Correct Reasoning in Base LLMs , author=. arXiv preprint arXiv:2506.14245 , year=
-
[41]
arXiv preprint arXiv:2506.01347 , year=
The surprising effectiveness of negative reinforcement in LLM reasoning , author=. arXiv preprint arXiv:2506.01347 , year=
-
[42]
arXiv preprint arXiv:2507.10532 , year=
Reasoning or memorization? unreliable results of reinforcement learning due to data contamination , author=. arXiv preprint arXiv:2507.10532 , year=
-
[43]
arXiv preprint arXiv:2504.20571 , year=
Reinforcement learning for reasoning in large language models with one training example , author=. arXiv preprint arXiv:2504.20571 , year=
-
[44]
arXiv preprint arXiv:2502.01456 , year=
Process reinforcement through implicit rewards , author=. arXiv preprint arXiv:2502.01456 , year=
-
[45]
arXiv preprint arXiv:2505.11770 , year=
Internal Causal Mechanisms Robustly Predict Language Model Out-of-Distribution Behaviors , author=. arXiv preprint arXiv:2505.11770 , year=
-
[46]
arXiv preprint arXiv:2505.13742 , year=
Understanding Task Representations in Neural Networks via Bayesian Ablation , author=. arXiv preprint arXiv:2505.13742 , year=
-
[47]
arXiv preprint arXiv:2505.14352 , year=
Towards eliciting latent knowledge from LLMs with mechanistic interpretability , author=. arXiv preprint arXiv:2505.14352 , year=
-
[48]
2025 , eprint=
UFT: Unifying Supervised and Reinforcement Fine-Tuning , author=. 2025 , eprint=
2025
-
[49]
arXiv preprint arXiv:2505.13417 , year=
AdaptThink: Reasoning Models Can Learn When to Think , author=. arXiv preprint arXiv:2505.13417 , year=
-
[50]
arXiv preprint arXiv:2505.12629 , year=
Enhancing Latent Computation in Transformers with Latent Tokens , author=. arXiv preprint arXiv:2505.12629 , year=
-
[51]
arXiv preprint arXiv:2505.13898 , year=
Do Language Models Use Their Depth Efficiently? , author=. arXiv preprint arXiv:2505.13898 , year=
-
[52]
arXiv preprint arXiv:2505.13775 , year=
Beyond Semantics: The Unreasonable Effectiveness of Reasonless Intermediate Tokens , author=. arXiv preprint arXiv:2505.13775 , year=
-
[53]
arXiv preprint arXiv:2403.09629 , year=
Quiet-star: Language models can teach themselves to think before speaking , author=. arXiv preprint arXiv:2403.09629 , year=
-
[54]
2022 , url=
Show Your Work: Scratchpads for Intermediate Computation with Language Models , author=. 2022 , url=
2022
-
[55]
arXiv preprint arXiv:2405.08644 , year=
Thinking tokens for language modeling , author=. arXiv preprint arXiv:2405.08644 , year=
-
[56]
R0-FoMo:Robustness of Few-shot and Zero-shot Learning in Large Foundation Models , year=
Think before you speak: Training Language Models With Pause Tokens , author=. R0-FoMo:Robustness of Few-shot and Zero-shot Learning in Large Foundation Models , year=
-
[57]
Advances in Neural Information Processing Systems , volume=
Training chain-of-thought via latent-variable inference , author=. Advances in Neural Information Processing Systems , volume=
-
[58]
arXiv preprint arXiv:2503.18866 , year=
Reasoning to learn from latent thoughts , author=. arXiv preprint arXiv:2503.18866 , year=
-
[59]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Think or Not? Selective Reasoning via Reinforcement Learning for Vision-Language Models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[60]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Adareasoner: Adaptive reasoning enables more flexible thinking , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[61]
arXiv preprint arXiv:2505.11756 , year=
Feature Hedging: Correlated Features Break Narrow Sparse Autoencoders , author=. arXiv preprint arXiv:2505.11756 , year=
-
[62]
2025 , eprint=
Reinforcing General Reasoning without Verifiers , author=. 2025 , eprint=
2025
-
[63]
arXiv preprint arXiv:2503.19618 , year=
Learning to chain-of-thought with Jensen's evidence lower bound , author=. arXiv preprint arXiv:2503.19618 , year=
-
[64]
arXiv preprint arXiv:2502.09297 , year=
When do neural networks learn world models? , author=. arXiv preprint arXiv:2502.09297 , year=
-
[65]
arXiv preprint arXiv:2505.15134 , year=
The Unreasonable Effectiveness of Entropy Minimization in LLM Reasoning , author=. arXiv preprint arXiv:2505.15134 , year=
-
[66]
2025 , eprint=
Maximizing Confidence Alone Improves Reasoning , author=. 2025 , eprint=
2025
-
[67]
2025 , eprint=
Test-Time Learning for Large Language Models , author=. 2025 , eprint=
2025
-
[68]
arXiv preprint arXiv:2504.09597 , year=
Understanding llm behaviors via compression: Data generation, knowledge acquisition and scaling laws , author=. arXiv preprint arXiv:2504.09597 , year=
-
[69]
arXiv preprint arXiv:2505.18404 , year=
Thought calibration: Efficient and confident test-time scaling , author=. arXiv preprint arXiv:2505.18404 , year=
-
[70]
arXiv preprint arXiv:2505.18373 , year=
Next-token pretraining implies in-context learning , author=. arXiv preprint arXiv:2505.18373 , year=
-
[71]
arXiv preprint arXiv:2505.13379 , year=
Thinkless: Llm learns when to think , author=. arXiv preprint arXiv:2505.13379 , year=
-
[72]
arXiv preprint arXiv:2505.21444 , year=
Can Large Reasoning Models Self-Train? , author=. arXiv preprint arXiv:2505.21444 , year=
-
[73]
arXiv preprint arXiv:2505.17697 , year=
Activation Control for Efficiently Eliciting Long Chain-of-thought Ability of Language Models , author=. arXiv preprint arXiv:2505.17697 , year=
-
[74]
arXiv preprint arXiv:2505.16400 , year=
AceReason-Nemotron: Advancing Math and Code Reasoning through Reinforcement Learning , author=. arXiv preprint arXiv:2505.16400 , year=
-
[75]
2025 , eprint=
Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning , author=. 2025 , eprint=
2025
-
[76]
2025 , eprint=
Incentivizing LLMs to Self-Verify Their Answers , author=. 2025 , eprint=
2025
-
[77]
arXiv preprint arXiv:2504.13837 , year=
Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? , author=. arXiv preprint arXiv:2504.13837 , year=
-
[78]
arXiv preprint arXiv:2505.12392 , year=
SLOT: Sample-specific Language Model Optimization at Test-time , author=. arXiv preprint arXiv:2505.12392 , year=
-
[79]
arXiv preprint arXiv:2505.11711 , year=
Reinforcement Learning Finetunes Small Subnetworks in Large Language Models , author=. arXiv preprint arXiv:2505.11711 , year=
-
[80]
arXiv preprint arXiv:2502.12118 , year=
Scaling test-time compute without verification or rl is suboptimal , author=. arXiv preprint arXiv:2502.12118 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.