CRAFT: Conflict-Resolved Aggregation for Federated Training
Pith reviewed 2026-05-21 05:44 UTC · model grok-4.3
The pith
CRAFT resolves conflicting client updates in federated learning by finding the global update closest to a reference direction while enforcing conflict-free alignment constraints through projection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CRAFT formulates the aggregation step as a constrained optimization problem that finds the update minimizing distance to a reference direction subject to conflict-free alignment constraints, derives a closed-form solution for it, applies layer-wise adaptation, and provides theoretical guarantees that this promotes common-descent structure while mitigating conflicts via projection geometry, leading to better global models with reduced disparity on heterogeneous data.
What carries the argument
The projection onto the intersection of conflict-free half-spaces closest to a reference direction, solved via closed-form expression with layer-wise adaptation.
Load-bearing premise
A suitable reference direction exists and the projection can enforce the alignment constraints without losing essential information from the client updates.
What would settle it
If experiments on the heterogeneous benchmarks show that CRAFT does not improve global model accuracy or fails to reduce performance disparity across clients compared to baselines, the central empirical claim would be falsified.
Figures








read the original abstract
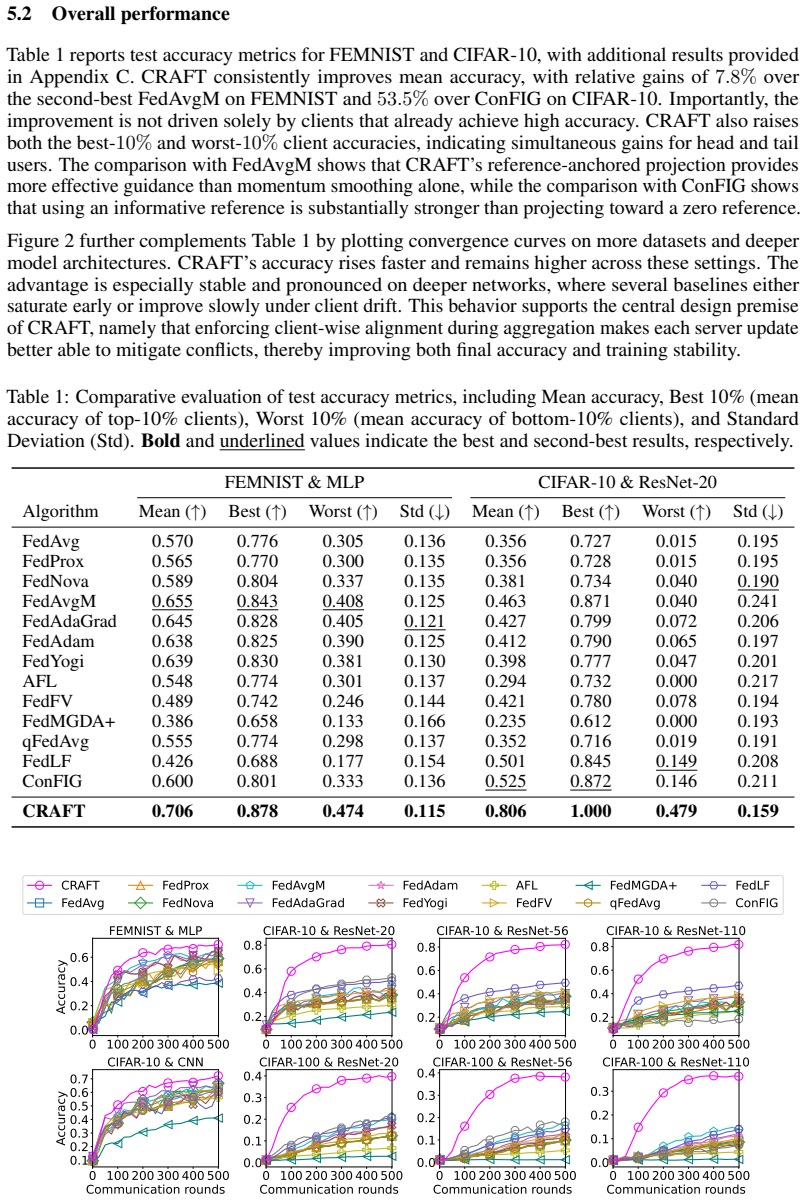
The aggregation of conflicting client updates remains a fundamental bottleneck in federated learning (FL) under heterogeneous data distributions. Naive averaging can produce a global update that improves the global objective while conflicting with specific clients, causing degradation for those clients. In this work, we propose CRAFT (Conflict-Resolved Aggregation for Federated Training), a new aggregation framework that treats the global update as a geometric correction problem. We formulate aggregation as finding the update closest to a reference direction while satisfying conflict-free alignment constraints. We derive a closed-form expression for the constrained optimization problem, avoiding the computational overhead of iterative solvers. Furthermore, we use a layer-wise adaptation to address conflicts at varying feature granularities. We provide a theoretical analysis showing that CRAFT promotes a common-descent structure and mitigates conflicts through its projection geometry. Extensive experiments on heterogeneous benchmarks demonstrate that CRAFT improves the accuracy of the global model while reducing performance disparity across clients compared with state-of-the-art baselines. The source code for CRAFT is available at https://github.com/tum-pbs/CRAFT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CRAFT, a new aggregation framework for federated learning under heterogeneous data. It formulates the global update as the solution to a constrained optimization problem: find the update closest to a reference direction while satisfying conflict-free alignment constraints (inner-product non-negativity with client updates). The authors claim a closed-form solution to this problem that avoids iterative solvers, introduce layer-wise adaptation for conflicts at different feature granularities, provide a theoretical analysis that CRAFT promotes common-descent structure via its projection geometry, and report experimental gains in global accuracy and reduced client disparity on heterogeneous benchmarks. Source code is released.
Significance. If the closed-form derivation is valid and the common-descent property holds without discarding essential update information, CRAFT would address a core practical bottleneck in FL aggregation. The availability of source code at https://github.com/tum-pbs/CRAFT is a positive for reproducibility. The geometric framing and layer-wise adaptation could be useful if the computational advantage over iterative methods is substantiated.
major comments (2)
- [Abstract and §3] Abstract and §3 (formulation): the central claim of a closed-form solution to min ||x - r|| s.t. <x, u_i> >= 0 for multiple client directions u_i is load-bearing. Standard projection onto a polyhedral cone defined by several half-spaces requires either active-set identification or an iterative solver (e.g., dual QP or successive projections). The manuscript must explicitly show the algebraic steps or special structure (e.g., at most one active constraint, or a reference r chosen so the solution collapses to a single hyperplane projection) that yields an exact closed form without iteration or combinatorial search.
- [§4] §4 (theoretical analysis): the claim that the projection geometry promotes a common-descent structure and mitigates conflicts must be supported by the key steps of the proof. In particular, demonstrate that the feasible-set projection does not systematically discard gradient components that are essential for some clients, and clarify how the layer-wise adaptation interacts with the global common-descent guarantee.
minor comments (2)
- [Experiments] Experiments section: provide the precise heterogeneous data partitions, number of clients, and exact baseline implementations so that the reported accuracy and disparity reductions can be reproduced from the released code.
- [Notation and §3] Notation: define the reference direction r explicitly (is it the average update, a previous global model, or chosen per layer?) and state whether the closed-form expression depends on any fitted parameters from prior rounds.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with clarifications drawn directly from the geometric formulation and analysis in the paper. We will revise the manuscript to make the derivations and proofs more explicit as requested.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (formulation): the central claim of a closed-form solution to min ||x - r|| s.t. <x, u_i> >= 0 for multiple client directions u_i is load-bearing. Standard projection onto a polyhedral cone defined by several half-spaces requires either active-set identification or an iterative solver (e.g., dual QP or successive projections). The manuscript must explicitly show the algebraic steps or special structure (e.g., at most one active constraint, or a reference r chosen so the solution collapses to a single hyperplane projection) that yields an exact closed form without iteration or combinatorial search.
Authors: We appreciate the referee's emphasis on rigor for the closed-form claim. The derivation in §3 relies on the specific choice of reference direction r as the normalized average of the client updates, which lies in the interior of the feasible cone when conflicts are mild. This allows the solution to be obtained by first checking the unconstrained projection onto the half-spaces and, when a constraint is violated, subtracting a single scaled term proportional to the most conflicting u_i while renormalizing; the algebra reduces to solving a quadratic equation for the scalar multiplier without combinatorial search over active sets. We will insert the complete step-by-step Lagrange multiplier derivation and the verification that the resulting x satisfies all inner-product constraints in the revised §3. revision: yes
-
Referee: [§4] §4 (theoretical analysis): the claim that the projection geometry promotes a common-descent structure and mitigates conflicts must be supported by the key steps of the proof. In particular, demonstrate that the feasible-set projection does not systematically discard gradient components that are essential for some clients, and clarify how the layer-wise adaptation interacts with the global common-descent guarantee.
Authors: We agree that the proof in §4 would benefit from expanded key steps. The common-descent guarantee follows from the fact that the projection operator is the Euclidean projection onto the intersection of half-spaces, which by construction ensures <x, u_i> >= 0 for every client update u_i; under standard smoothness assumptions this implies that the global update produces non-positive directional derivatives for all local objectives. The projection does not discard essential components because it minimizes ||x - r||_2 subject to the constraints, thereby retaining the largest possible component of the reference direction r (itself an average) while enforcing feasibility; any discarded component is exactly the minimal correction needed to restore non-negativity. Layer-wise adaptation applies the same projection independently per layer, and the global guarantee holds because the concatenated update satisfies the alignment constraints layer by layer, with the overall descent property following from additivity of the inner products across layers. We will add these explicit lemmas and the layer-wise interaction argument to the revised §4. revision: yes
Circularity Check
No circularity: derivation self-contained via new geometric formulation
full rationale
The paper introduces a novel constrained optimization for client-update aggregation, formulates it as a projection onto conflict-free half-spaces, and claims a closed-form solution plus layer-wise adaptation. No quoted equations or text reduce this closed form to a fitted parameter, prior self-citation, or self-defined quantity; the reference direction and alignment constraints are presented as external modeling choices rather than outputs of the same derivation. The theoretical common-descent argument and experiments are therefore independent of the core algebraic step.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A reference direction can be chosen such that the closest feasible update satisfies conflict-free alignment for all clients
- ad hoc to paper Layer-wise application of the projection is sufficient to address conflicts at different feature granularities
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formulate aggregation as finding the update closest to a reference direction while satisfying conflict-free alignment constraints ⟨g, g_i⟩ > 0 ... gt = ĝt + U† (ρ - U ĝt)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
theoretical analysis showing that CRAFT promotes a common-descent structure and mitigates conflicts through its projection geometry
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Leaf: A benchmark for federated settings,
Sebastian Caldas, Sai Meher Karthik Duddu, Peter Wu, Tian Li, Jakub Koneˇcný, H. Brendan McMahan, Virginia Smith, and Ameet Talwalkar. LEAF: A benchmark for federated settings. arXiv preprint arXiv:1812.01097, 2018
-
[2]
Exploiting shared representations for personalized federated learning
Liam Collins, Hamed Hassani, Aryan Mokhtari, and Sanjay Shakkottai. Exploiting shared representations for personalized federated learning. InProceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 2089–2099. PMLR, 18–24 Jul 2021
work page 2089
-
[3]
Personalized federated learning with theoretical guarantees: A model-agnostic meta-learning approach
Alireza Fallah, Aryan Mokhtari, and Asuman Ozdaglar. Personalized federated learning with theoretical guarantees: A model-agnostic meta-learning approach. InAdvances in Neural Information Processing Systems, volume 33, pages 3557–3568. Curran Associates, Inc., 2020
work page 2020
-
[4]
Orthogonal gradient descent for continual learning
Mehrdad Farajtabar, Navid Azizan, Alex Mott, and Ang Li. Orthogonal gradient descent for continual learning. InProceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, volume 108 ofProceedings of Machine Learning Research, pages 3762–3773. PMLR, 26–28 Aug 2020
work page 2020
-
[5]
Deep residual learning for im- age recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for im- age recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, June 2016
work page 2016
-
[6]
Measuring the Effects of Non-Identical Data Distribution for Federated Visual Classification
Tzu-Ming Harry Hsu, Hang Qi, and Matthew Brown. Measuring the effects of non-identical data distribution for federated visual classification.arXiv preprint arXiv:1909.06335, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[7]
Zeou Hu, Kiarash Shaloudegi, Guojun Zhang, and Yaoliang Yu. Federated learning meets multi-objective optimization.IEEE Transactions on Network Science and Engineering, 9(4): 2039–2051, 2022
work page 2039
-
[8]
Dual cone gradient descent for training physics- informed neural networks
Youngsik Hwang and Dong-Young Lim. Dual cone gradient descent for training physics- informed neural networks. InAdvances in Neural Information Processing Systems, volume 37, pages 98563–98595. Curran Associates, Inc., 2024
work page 2024
-
[9]
Peter Kairouz, H. Brendan McMahan, et al. Advances and open problems in federated learning. Foundations and Trends® in Machine Learning, 14(1–2):1–210, 2021
work page 2021
-
[10]
Learning multiple layers of features from tiny images
Alex Krizhevsky and Geoffrey Hinton. Learning multiple layers of features from tiny images. Technical report, University of Toronto, Toronto, Ontario, 2009
work page 2009
-
[11]
Federated optimization in heterogeneous networks
Tian Li, Anit Kumar Sahu, Manzil Zaheer, Maziar Sanjabi, Ameet Talwalkar, and Virginia Smith. Federated optimization in heterogeneous networks. InProceedings of Machine Learning and Systems, volume 2, pages 429–450, 2020
work page 2020
-
[12]
Fair resource allocation in federated learning
Tian Li, Maziar Sanjabi, Ahmad Beirami, and Virginia Smith. Fair resource allocation in federated learning. InInternational Conference on Learning Representations, 2020
work page 2020
-
[13]
Ditto: Fair and robust federated learning through personalization
Tian Li, Shengyuan Hu, Ahmad Beirami, and Virginia Smith. Ditto: Fair and robust federated learning through personalization. InProceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 6357–
-
[14]
PMLR, 18–24 Jul 2021
work page 2021
-
[15]
On the convergence of FedAvg on Non-IID data
Xiang Li, Kaixuan Huang, Wenhao Yang, Shusen Wang, and Zhihua Zhang. On the convergence of FedAvg on Non-IID data. InInternational Conference on Learning Representations, 2020. 10
work page 2020
-
[16]
ConFIG: Towards conflict-free training of physics informed neural networks
Qiang Liu, Mengyu Chu, and Nils Thuerey. ConFIG: Towards conflict-free training of physics informed neural networks. InInternational Conference on Learning Representations, pages 59531–59566, 2025
work page 2025
-
[17]
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas
H. Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. InProceedings of the 20th International Conference on Artificial Intelligence and Statistics, volume 54 of Proceedings of Machine Learning Research, pages 1273–1282. PMLR, 20–22 Apr 2017
work page 2017
-
[18]
Mehryar Mohri, Gary Sivek, and Ananda Theertha Suresh. Agnostic federated learning. InProceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 4615–4625. PMLR, 09–15 Jun 2019
work page 2019
- [19]
-
[20]
FedMDFG: Federated learning with multi-gradient descent and fair guidance
Zibin Pan, Shuyi Wang, Chi Li, Haijin Wang, Xiaoying Tang, and Junhua Zhao. FedMDFG: Federated learning with multi-gradient descent and fair guidance. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 9364–9371, 2023
work page 2023
-
[21]
FedLF: Layer-wise fair federated learning
Zibin Pan, Chi Li, Fangchen Yu, Shuyi Wang, Haijin Wang, Xiaoying Tang, and Junhua Zhao. FedLF: Layer-wise fair federated learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 14527–14535, 2024
work page 2024
-
[22]
Boris T Polyak. Some methods of speeding up the convergence of iteration methods.USSR Computational Mathematics and Mathematical Physics, 4(5):1–17, 1964
work page 1964
-
[23]
Sashank J. Reddi, Zachary Charles, Manzil Zaheer, Zachary Garrett, Keith Rush, Jakub Koneˇcný, Sanjiv Kumar, and H. Brendan McMahan. Adaptive federated optimization. InInternational Conference on Learning Representations, 2021
work page 2021
-
[24]
Learning to learn without forgetting by maximizing transfer and minimizing interference
Matthew Riemer, Ignacio Cases, Robert Ajemian, Miao Liu, Irina Rish, Yuhai Tu, and Ger- ald Tesauro. Learning to learn without forgetting by maximizing transfer and minimizing interference. InInternational Conference on Learning Representations, 2019
work page 2019
-
[25]
On the importance of initialization and momentum in deep learning
Ilya Sutskever, James Martens, George Dahl, and Geoffrey Hinton. On the importance of initialization and momentum in deep learning. InProceedings of the 30th International Confer- ence on Machine Learning, volume 28 ofProceedings of Machine Learning Research, pages 1139–1147, Atlanta, Georgia, USA, 17–19 Jun 2013. PMLR
work page 2013
-
[26]
Dinh, Nguyen Tran, and Josh Nguyen
Canh T. Dinh, Nguyen Tran, and Josh Nguyen. Personalized federated learning with moreau envelopes. InAdvances in Neural Information Processing Systems, volume 33, pages 21394– 21405. Curran Associates, Inc., 2020
work page 2020
-
[27]
Jianyu Wang, Qinghua Liu, Hao Liang, Gauri Joshi, and H. Vincent Poor. Tackling the objective inconsistency problem in heterogeneous federated optimization. InAdvances in Neural Information Processing Systems, volume 33, pages 7611–7623. Curran Associates, Inc., 2020
work page 2020
-
[28]
Federated learning with fair averaging
Zheng Wang, Xiaoliang Fan, Jianzhong Qi, Chenglu Wen, Cheng Wang, and Rongshan Yu. Federated learning with fair averaging. InProceedings of the Thirtieth International Joint Conference on Artificial Intelligence, pages 1615–1623, 2021
work page 2021
-
[29]
Hao Yu, Sen Yang, and Shenghuo Zhu. Parallel restarted SGD with faster convergence and less communication: Demystifying why model averaging works for deep learning. InProceedings of the AAAI conference on artificial intelligence, volume 33, pages 5693–5700, 2019
work page 2019
-
[30]
Gradient surgery for multi-task learning
Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. Gradient surgery for multi-task learning. InAdvances in Neural Information Processing Systems, volume 33, pages 5824–5836. Curran Associates, Inc., 2020
work page 2020
-
[31]
FedALA: Adaptive local aggregation for personalized federated learning
Jianqing Zhang, Yang Hua, Hao Wang, Tao Song, Zhengui Xue, Ruhui Ma, and Haibing Guan. FedALA: Adaptive local aggregation for personalized federated learning. InProceedings of the AAAI conference on artificial intelligence, volume 37, pages 11237–11244, 2023. 11 Appendix This appendix provides details about CRAFT on the following topics: • Appendix A: Tec...
work page 2023
-
[32]
We manually set the minimum number of samples per client to 20
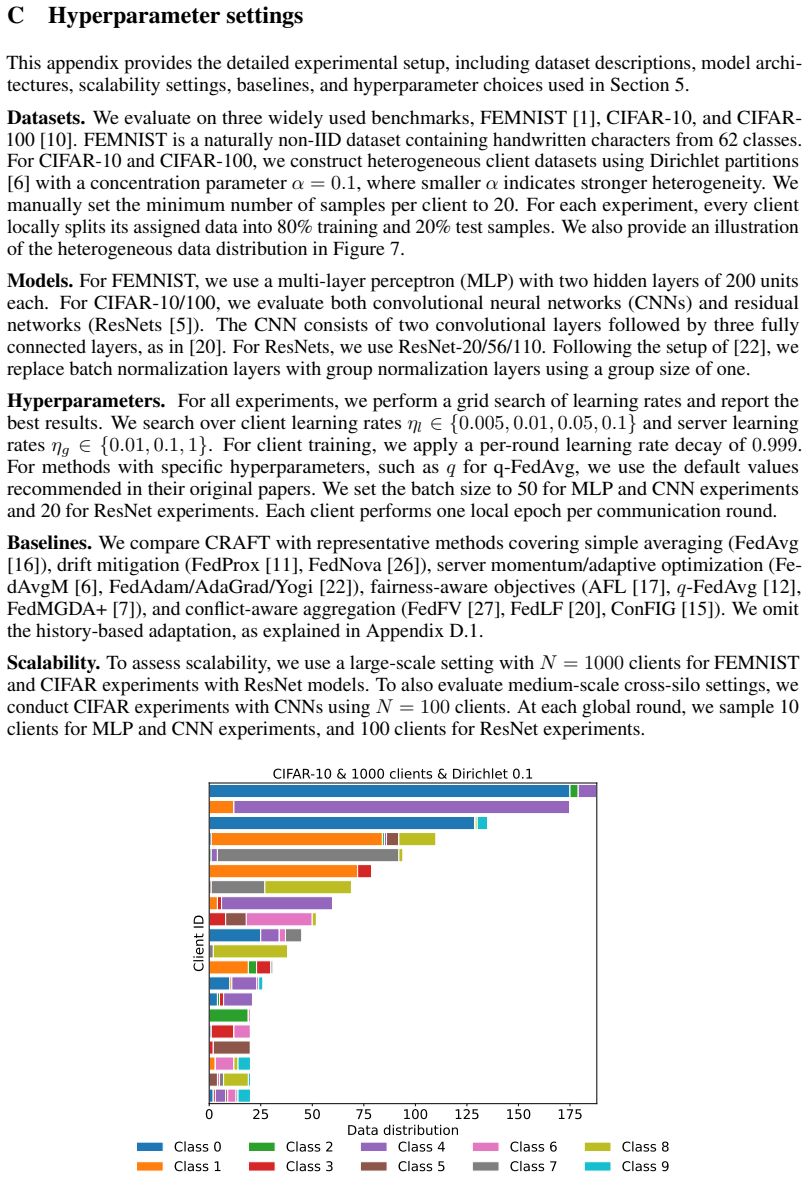
with a concentration parameter α= 0.1 , where smaller α indicates stronger heterogeneity. We manually set the minimum number of samples per client to 20. For each experiment, every client locally splits its assigned data into 80% training and 20% test samples. We also provide an illustration of the heterogeneous data distribution in Figure 7. Models.For F...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.