Halving the cost of QROM
Pith reviewed 2026-05-21 01:05 UTC · model grok-4.3
The pith
Switching to SelectCopy and adding qubit-constrained tweaks halves the dominant Toffoli cost of dirty-qubit QROM for practical b.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We first present an optimization to reduce this cost to 2N/λ + 2b(λ - 1) + 2λ-6 by replacing the SelectSwap architecture with SelectCopy. We then provide a further optimization for the qubit-constrained regime where the Toffoli cost is typically ∼2N/λ, and reduce it to ∼(1+1/b)N/λ, cutting the cost by approximately 50% and effectively matching the performance of clean-qubit QROM using dirty qubits for practical values of b. Lastly, we provide a parametric family of methods that allow the interpolation of the prefactor of the N/λ term from 2 to (1+1/b) to obtain the best cost for different qubit availability regimes.
What carries the argument
The SelectCopy circuit that replaces SelectSwap, together with a qubit-constrained rewrite that changes the leading coefficient of the N/λ term from 2 to (1 + 1/b).
If this is right
- With bλ dirty qubits the Toffoli cost of QROM drops to 2N/λ + 2b(λ-1) + 2λ-6.
- In the qubit-limited regime the leading term becomes approximately (1 + 1/b)N/λ instead of 2N/λ.
- Dirty-qubit QROM now reaches performance comparable to clean-qubit QROM for typical values of b.
- A continuous family of circuits lets the leading prefactor be set anywhere from 2 down to (1 + 1/b) by trading extra dirty qubits.
Where Pith is reading between the lines
- Algorithms whose runtime is dominated by many table-lookup calls could see their overall resource estimates reduced by roughly the same factor.
- The same circuit ideas may extend to other coherent memory-access patterns that currently rely on SelectSwap networks.
- Near-term hardware experiments with modest N and b could directly verify the claimed gate counts and expose any compilation overheads the asymptotic formulas omit.
Load-bearing premise
The SelectCopy construction and the qubit-constrained rewrite incur no hidden Toffoli or qubit overheads beyond the formulas stated.
What would settle it
Implement the SelectCopy circuit for small concrete values of N, b, and λ and count the actual number of Toffolis required; the count should match the claimed expression without extra gates.
Figures


read the original abstract
Table lookup, often referred to as quantum read only memory (QROM), is one of the most widely used subroutines in quantum algorithms, and constitutes the majority share of algorithmic overheads in most practical applications of quantum computers. It involves the coherent loading of $N$ bitstrings of length $b$ in superposition, and naively has a non-Clifford cost of $N$ Toffolis. It is known that given access to $b\, \lambda$ dirty qubits, one can reduce the Toffoli cost of QROM to $2\frac{N}{\lambda} + 4b(\lambda - 1)$. In this work, we first present an optimization to reduce this cost to $2\frac{N}{\lambda} + 2b(\lambda - 1) + 2\lambda-6$ by replacing the ``SelectSwap" architecture with ``SelectCopy". We then provide a further optimization for the qubit-constrained regime where the Toffoli cost is typically $\sim 2\frac{N}{\lambda}$, and reduce it to $\sim (1+\frac{1}{b})\frac{N}{\lambda}$, cutting the cost by approximately $50\%$ and effectively matching the performance of clean-qubit QROM using dirty qubits for practical values of $b$. Lastly, we provide a parametric family of methods that allow the interpolation of the prefactor of the $\frac{N}{\lambda} $ term from $2$ to ($\, 1+\frac{1}{b}\,$) to obtain the best cost for different qubit availability regimes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims two optimizations for dirty-qubit QROM table lookup. Replacing SelectSwap with SelectCopy reduces the Toffoli cost from 2N/λ + 4b(λ−1) to 2N/λ + 2b(λ−1) + 2λ−6. In the qubit-constrained regime the cost is further reduced to ∼(1 + 1/b)N/λ (approximately 50 % lower), matching clean-qubit QROM performance for practical b; a parametric family interpolates the leading coefficient between 2 and (1 + 1/b).
Significance. If the claimed circuit constructions incur no hidden non-Clifford or ancilla overhead, the work would meaningfully lower the dominant cost of a ubiquitous primitive in quantum algorithms. The ability to approach clean-qubit performance with only dirty qubits and the provision of a tunable family are practically useful strengths.
major comments (1)
- [Abstract] Abstract and the qubit-constrained optimization: the headline reduction to ∼(1 + 1/b)N/λ is load-bearing for the 50 % saving and the claim of matching clean-qubit QROM. The manuscript must explicitly demonstrate that the SelectCopy construction and the subsequent optimization introduce neither extra Toffoli gates nor additional dirty-qubit management costs beyond the stated formulas; without a full resource count or circuit diagram this central claim remains unverified.
minor comments (1)
- [Abstract] The abstract states explicit cost formulas but does not indicate the range of b and λ for which the ∼50 % reduction is observed; a short numerical example or plot would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for identifying the need to strengthen the verification of our central claims. We address the major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract and the qubit-constrained optimization: the headline reduction to ∼(1 + 1/b)N/λ is load-bearing for the 50 % saving and the claim of matching clean-qubit QROM. The manuscript must explicitly demonstrate that the SelectCopy construction and the subsequent optimization introduce neither extra Toffoli gates nor additional dirty-qubit management costs beyond the stated formulas; without a full resource count or circuit diagram this central claim remains unverified.
Authors: We agree that explicit verification is necessary for the qubit-constrained optimization. The manuscript derives the SelectCopy cost 2N/λ + 2b(λ−1) + 2λ−6 by replacing the SelectSwap block with a copy-based construction that reuses the same dirty-qubit pool without additional non-Clifford operations; the subsequent qubit-constrained regime then folds the remaining b(λ−1) term into the leading coefficient by amortizing the per-block overhead across multiple parallel lookups when dirty-qubit count is the binding constraint, yielding the (1 + 1/b) prefactor. To make this fully verifiable, the revised manuscript will include (i) a complete resource-count table enumerating Toffoli, CNOT, and dirty-qubit usage for the original, SelectCopy, and optimized constructions at representative (N, b, λ) values, and (ii) an explicit circuit diagram for the qubit-constrained block showing the data-flow and confirming that no extra Toffolis or hidden ancilla management costs appear beyond the stated formulas. These additions will directly substantiate the headline reduction and the matching to clean-qubit performance for practical b. revision: yes
Circularity Check
No significant circularity; optimizations derived from explicit new circuit constructions
full rationale
The paper introduces SelectCopy as a replacement for SelectSwap and a qubit-constrained regime optimization, deriving the reduced Toffoli costs (2N/λ + 2b(λ-1) + 2λ-6, then ~ (1+1/b)N/λ) directly from the new architectural descriptions and gate counts. These steps rely on explicit circuit compositions rather than parameter fitting, self-referential definitions, or load-bearing self-citations. The initial known bound (2N/λ + 4b(λ-1)) is cited as prior art, but the claimed improvements are independent constructions that do not reduce to it by definition. The work is self-contained with verifiable circuit-level claims against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- λ
- b
axioms (2)
- domain assumption Toffoli gates are the dominant non-Clifford resource and all other gates are free or negligible.
- domain assumption Dirty qubits incur no additional error-correction overhead beyond the stated Toffoli count.
Reference graph
Works this paper leans on
-
[4]
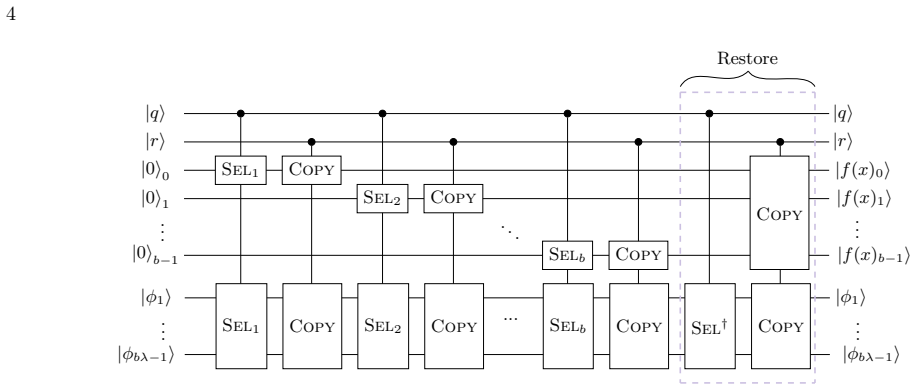
Load allf(q, r) values forr= 0, ..., λ−1 in the ancillary registers based on the state of the|q⟩register
-
[5]
Swap ther th b-qubit ancilla register with the zeroth one based on the state of the|r⟩register
-
[6]
Copy the value of the zeroth register into a clean register
-
[7]
Swap ther th register with the zeroth one based on the state of the|r⟩register
-
[8]
Unload allf(q, r) values forr= 0, ..., λ−1 in the ancillary registers based on the state of the|q⟩register. This was the approach proposed in [11] with Toffoli cost 2 N λ + 4bλusingbλdirty ancilla qubits. This was slightly refined in [1] to achieve Toffoli cost 2 N λ + 4b(λ−1) and dirty ancilla counts ofb(λ−1). We now present our first improvement over th...
-
[9]
D. W. Berry, C. Gidney, M. Motta, J. R. McClean, and R. Babbush, Qubitization of arbitrary basis quantum chemistry leveraging sparsity and low rank factorization, Quantum3, 208 (2019)
work page 2019
-
[10]
V. von Burg, G. H. Low, T. H¨ aner, D. S. Steiger, M. Reiher, M. Roetteler, and M. Troyer, Quantum computing enhanced computational catalysis, Physical Review Research3, 033055 (2021)
work page 2021
-
[11]
J. Lee, D. W. Berry, C. Gidney, W. J. Huggins, J. R. McClean, N. Wiebe, and R. Babbush, Even more efficient quantum computations of chemistry through tensor hypercontraction, PRX quantum2, 030305 (2021)
work page 2021
-
[12]
G. H. Low and I. L. Chuang, Optimal hamiltonian simulation by quantum signal processing, Physical review letters118, 010501 (2017)
work page 2017
-
[13]
G. H. Low and I. L. Chuang, Hamiltonian simulation by qubitization, Quantum3, 163 (2019)
work page 2019
-
[14]
D. Motlagh and N. Wiebe, Generalized quantum signal processing, PRX Quantum5, 020368 (2024)
work page 2024
-
[15]
D. W. Berry, D. Motlagh, G. Pantaleoni, and N. Wiebe, Doubling the efficiency of hamiltonian simulation via generalized quantum signal processing, Physical Review A110, 012612 (2024)
work page 2024
-
[16]
R. Babbush, C. Gidney, D. W. Berry, N. Wiebe, J. McClean, A. Paler, A. Fowler, and H. Neven, Encoding electronic spectra in quantum circuits with linear t complexity, Physical Review X8, 041015 (2018)
work page 2018
-
[17]
S. Fomichev, K. Hejazi, M. S. Zini, M. Kiser, J. Fraxanet, P. A. M. Casares, A. Delgado, J. Huh, A.-C. Voigt, J. E. Mueller, et al., Initial state preparation for quantum chemistry on quantum computers, PRX Quantum5, 040339 (2024)
work page 2024
-
[18]
F. Rupprecht and S. W¨ olk, Sparse quantum state preparation with improved toffoli cost, arXiv preprint arXiv:2601.09388 (2026)
-
[19]
G. H. Low, V. Kliuchnikov, and L. Schaeffer, Trading t gates for dirty qubits in state preparation and unitary synthesis, Quantum8, 1375 (2024)
work page 2024
-
[20]
G. Alonso-Linaje, U. Azad, J. Soni, J. Smalley, L. Lapworth, and J. M. Arrazola, Quantum compilation framework for data loading, arXiv preprint arXiv:2512.05183 (2025)
-
[21]
K. Kottmann, D. Wierichs, G. Alonso-Linaje, and N. Killoran, Parameter-optimal unitary synthesis with flag decomposi- tions, arXiv preprint arXiv:2603.20376 (2026)
-
[22]
D. Jennings, M. Lostaglio, R. B. Lowrie, S. Pallister, and A. T. Sornborger, The cost of solving linear differential equations on a quantum computer: fast-forwarding to explicit resource counts, Quantum8, 1553 (2024)
work page 2024
-
[23]
M. Pocrnic, P. D. Johnson, A. Katabarwa, and N. Wiebe, Constant-factor improvements in quantum algorithms for linear differential equations, arXiv preprint arXiv:2506.20760 (2025)
-
[24]
J. Penuel, A. Katabarwa, P. D. Johnson, P. Kuklinski, B. Rempfer, C. Farquhar, Y. Cao, and M. C. Garrett, Detailed assessment of calculating drag force with quantum computers: Explicit time-evolution precludes exponential advantage for nonlinear differential equations, arXiv preprint arXiv:2406.06323 (2024)
- [25]
-
[26]
A. M. Dalzell, A shortcut to an optimal quantum linear system solver, arXiv preprint arXiv:2406.12086 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
D. Jennings, M. Lostaglio, S. Pallister, A. T. Sornborger, and Y. Suba¸ sı, Randomized adiabatic quantum linear solver algorithm with optimal complexity scaling and detailed running costs, PRX Quantum6, 040373 (2025)
work page 2025
-
[28]
PennyLane: Automatic differentiation of hybrid quantum-classical computations
V. Bergholm, J. Izaac, M. Schuld, C. Gogolin, S. Ahmed, V. Ajith, M. S. Alam, G. Alonso-Linaje, B. Akash- Narayanan, A. Asadi,et al., Pennylane: Automatic differentiation of hybrid quantum-classical computations, arXiv preprint arXiv:1811.04968 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[29]
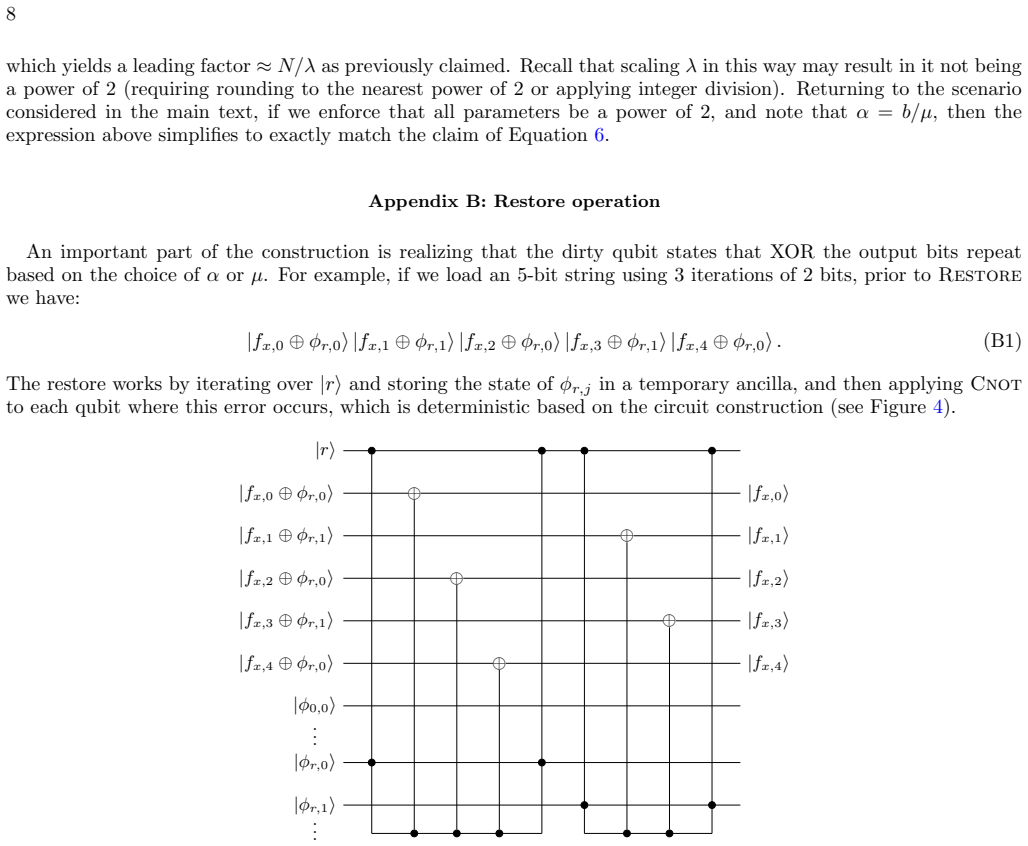
P. Mukhopadhyay, A. Gheorghiu, and H. Krovi, Improved quantum circuits for division, arXiv preprint arXiv:2603.18110 (2026). 7 Appendix A: Non-power of 2 bit-length Letµbe the number of bits loaded in each of theαgroups/iterations. In more general applications of this algorithm, the problem parameters will not be powers of 2. In this section we lift the p...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.