MedTS-TTT: Test-Time Training for Medical Time Series Classification
Pith reviewed 2026-06-26 14:27 UTC · model grok-4.3
The pith
MedTS-TTT adapts medical time series models to new subjects via single-step test-time training on unlabeled samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
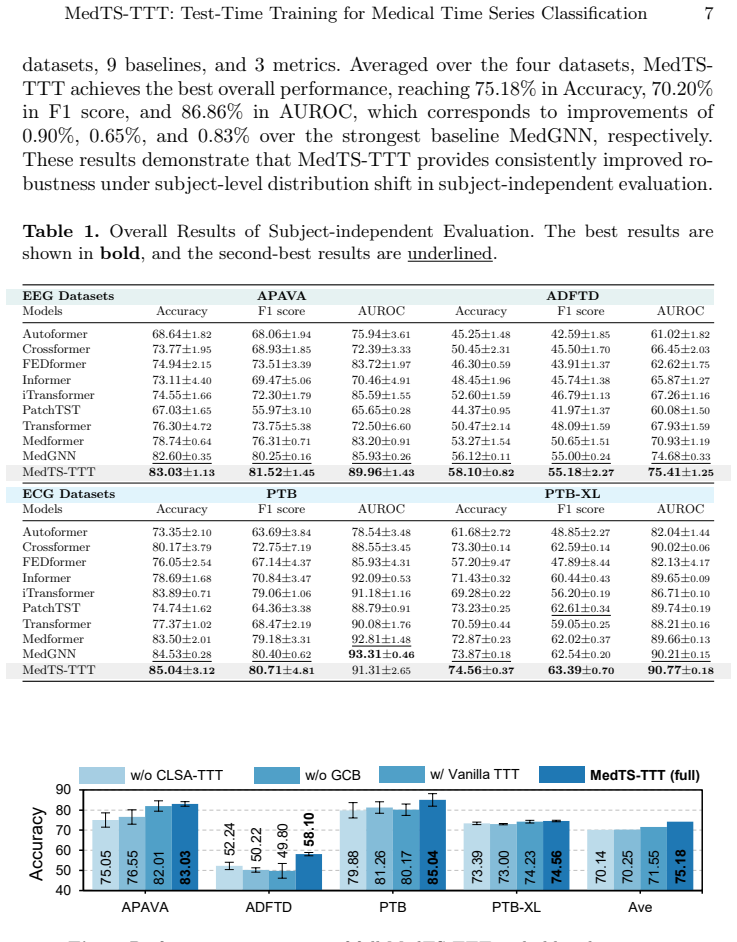
MedTS-TTT is built upon Closed-Loop Self-Alignment Test-Time Training (CLSA-TTT) and a Gated Convolutional Backbone (GCB). CLSA-TTT constructs a token-level self-supervised target and performs a single-step fast-weight update for intra-layer closed-loop alignment, enabling rapid sample-wise adaptation without iterative inner-loop optimization. GCB combines CLSA-TTT-based fast adaptation and token-level fusion with a gated convolutional branch to balance local dynamic modeling and information-flow control. On 4 public datasets (2 EEG and 2 ECG) with subject-independent splits, MedTS-TTT achieves 11 top-1 rankings out of 12 evaluations across 9 baselines and 3 metrics.
What carries the argument
CLSA-TTT, which constructs a token-level self-supervised target and performs a single-step fast-weight update for intra-layer closed-loop alignment
Load-bearing premise
That the token-level self-supervised target constructed by CLSA-TTT combined with a single-step fast-weight update produces effective adaptation for subject-level shifts in medical time series without needing iterative optimization or target-batch statistics.
What would settle it
On a new subject-independent EEG or ECG dataset, if MedTS-TTT shows no accuracy gain over a non-adaptive baseline or requires more than one update step to reach competitive performance, the central claim would be falsified.
Figures


read the original abstract
Medical time series (MedTS) signals such as electroencephalography (EEG) and electrocardiography (ECG) support many clinical applications. However, substantial subject-level heterogeneity often induces subject-level distribution shift, causing a fixed parameter set to generalize poorly to unseen individuals. Compared with domain adaptation methods that often depend on extra adaptation components or target-batch statistics, Test-Time Training (TTT) provides a more practical solution for sequential clinical data by enabling online adaptation from unlabeled test samples. However, many representative TTT methods require iterative inner-loop optimization, increasing test-time overhead. In this paper, we propose MedTS-TTT, a test-time training framework for medical time series modeling. MedTS-TTT is built upon Closed-Loop Self-Alignment Test-Time Training (CLSA-TTT) and a Gated Convolutional Backbone (GCB). CLSA-TTT constructs a token-level self-supervised target and performs a single-step fast-weight update for intra-layer closed-loop alignment, enabling rapid sample-wise adaptation without iterative inner-loop optimization. GCB combines CLSA-TTT-based fast adaptation and token-level fusion with a gated convolutional branch to balance local dynamic modeling and information-flow control. On 4 public datasets (2 EEG and 2 ECG) with subject-independent splits, MedTS-TTT achieves 11 top-1 rankings out of 12 evaluations across 9 baselines and 3 metrics. The code is publicly available at https://github.com/mingzhi-c/MedTS-TTT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MedTS-TTT, a test-time training framework for medical time series classification (EEG/ECG) that extends Closed-Loop Self-Alignment Test-Time Training (CLSA-TTT) with a Gated Convolutional Backbone (GCB). CLSA-TTT constructs a token-level self-supervised target and applies a single-step fast-weight update for intra-layer alignment, enabling sample-wise adaptation without iterative optimization or target-batch statistics. On four public datasets with subject-independent splits, it reports 11 top-1 rankings out of 12 evaluations across nine baselines and three metrics.
Significance. If the empirical rankings hold after verification of the adaptation mechanism, the work provides a practical, low-overhead TTT solution for subject-level distribution shifts in clinical time series, avoiding the overhead of iterative inner-loop methods and extra adaptation components common in domain adaptation. Public code release supports reproducibility.
major comments (2)
- [Abstract and §3] Abstract and §3 (CLSA-TTT description): the central claim that a single-step fast-weight update on the token-level self-supervised target produces effective adaptation for subject-level shifts is load-bearing for attributing the 11/12 top rankings to the TTT mechanism rather than the GCB backbone or training procedure, yet no analysis of update magnitude, gradient norms, or ablation removing the update step is supplied to confirm meaningful parameter movement.
- [Experiments] Experiments section (results table): the reported 11/12 top-1 rankings across 9 baselines and 3 metrics on subject-independent splits lacks error bars, statistical significance tests, or per-subject variance, making it impossible to determine whether the gains are robust or could arise from implementation details of the GCB rather than CLSA-TTT.
minor comments (2)
- [§3] Notation for the fast-weight update and token-level target construction should be formalized with equations to allow exact reproduction.
- [Experiments] Baseline descriptions are referenced but not detailed in the abstract; a table summarizing each baseline's key hyperparameters would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger evidence on the adaptation mechanism and result robustness. We address each major comment below and will incorporate revisions to address the concerns.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (CLSA-TTT description): the central claim that a single-step fast-weight update on the token-level self-supervised target produces effective adaptation for subject-level shifts is load-bearing for attributing the 11/12 top rankings to the TTT mechanism rather than the GCB backbone or training procedure, yet no analysis of update magnitude, gradient norms, or ablation removing the update step is supplied to confirm meaningful parameter movement.
Authors: We agree that the manuscript would benefit from explicit verification that the single-step update induces meaningful adaptation. In the revision we will add: (i) statistics on update magnitudes and gradient norms across layers and samples, and (ii) an ablation that disables the fast-weight update while retaining the GCB backbone and training procedure, allowing direct attribution of gains to CLSA-TTT. revision: yes
-
Referee: [Experiments] Experiments section (results table): the reported 11/12 top-1 rankings across 9 baselines and 3 metrics on subject-independent splits lacks error bars, statistical significance tests, or per-subject variance, making it impossible to determine whether the gains are robust or could arise from implementation details of the GCB rather than CLSA-TTT.
Authors: We acknowledge that the current table does not report variability or significance. In the revised manuscript we will rerun all experiments with multiple random seeds, report mean ± standard deviation, and include statistical significance tests (e.g., paired t-tests) against the strongest baselines. Per-subject performance breakdowns will also be added to the supplement. revision: yes
Circularity Check
No circularity: empirical extension of prior TTT without reductive derivations
full rationale
The paper presents MedTS-TTT as a practical extension of existing Test-Time Training methods (specifically CLSA-TTT) combined with a Gated Convolutional Backbone for medical time series. No equations, derivations, or first-principles predictions appear in the provided text. Central claims rest on experimental top-1 rankings across public datasets and baselines rather than any fitted parameter or self-citation that reduces the result to its inputs by construction. The work is self-contained as an applied method with external empirical validation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Biomedizinische Technik/Biomedical Engineering40(Ergänzungsband 1), 317–318 (1995)
Bousseljot, R.D., Kreiseler, D., Schnabel, A.: Nutzung der EKG-signaldatenbank CARDIODAT der PTB über das internet. Biomedizinische Technik/Biomedical Engineering40(Ergänzungsband 1), 317–318 (1995)
1995
-
[2]
IEEE Journal of Biomedical and Health Informatics27(11), 5216–5224 (2023)
Chang, H., Liu, B., Zong, Y., Lu, C., Wang, X.: EEG-based Parkinson’s disease recognition via attention-based sparse graph convolutional neural network. IEEE Journal of Biomedical and Health Informatics27(11), 5216–5224 (2023)
2023
-
[3]
Physiological Measurement27(11), 1091–1106 (2006)
Escudero,J.,Abásolo,D.,Hornero,R.,Espino,P.,López,M.:Analysisofelectroen- cephalograms inAlzheimer’s disease patients with multiscale entropy. Physiological Measurement27(11), 1091–1106 (2006)
2006
-
[4]
In: Proceedings of the ACM on Web Conference 2025
Fan,W.,Fei,J.,Guo,D.,Yi,K.,Song,X.,Xiang,H.,Ye,H.,Li,M.:Towardsmulti- resolution spatiotemporal graph learning for medical time series classification. In: Proceedings of the ACM on Web Conference 2025. pp. 5054–5064. ACM (2025)
2025
-
[5]
In: Advances in Neural Information Processing Systems
Gandelsman, Y., Sun, Y., Chen, X., Efros, A.A.: Test-time training with masked autoencoders. In: Advances in Neural Information Processing Systems. vol. 35, pp. 29374–29385 (2022)
2022
-
[6]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Han, D., Li, Y., Li, T., Cao, Z., Wang, Z., Song, J., Cheng, Y., Zheng, B., Huang, G.: ViT3: Unlocking test-time training in vision. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 51–61 (2026), oral presentation
2026
-
[7]
Nature Medicine25(1), 65–69 (2019)
Hannun, A.Y., Rajpurkar, P., Haghpanahi, M., Tison, G.H., Bourn, C., Turakhia, M.P., Ng, A.Y.: Cardiologist-level arrhythmia detection and classification in am- bulatory electrocardiograms using a deep neural network. Nature Medicine25(1), 65–69 (2019)
2019
-
[8]
Physical and Engineering Sciences in Medicine47(3), 1037–1050 (2024)
Kachare, P., Puri, D., Sangle, S.B., Al-Shourbaji, I., Jabbari, A., Kirner, R., Alameen, A., Migdady, H., Abualigah, L.: Lcadnet: a novel light CNN architecture for EEG-based Alzheimer disease detection. Physical and Engineering Sciences in Medicine47(3), 1037–1050 (2024)
2024
-
[9]
Scientific Reports15(1), 7817 (2025)
Kim, D., Lee, K.R., Lim, D.S., Lee, K.H., Lee, J.S., Kim, D.Y., Sohn, C.B.: A novel hybrid CNN-transformer model for arrhythmia detection without R-peak identification using Stockwell transform. Scientific Reports15(1), 7817 (2025)
2025
-
[10]
Biomedical Signal Processing and Control91, 105872 (2024) 10 M
Li, J., Li, X., Mao, Y., Yao, J., Gao, J., Liu, X.: Classification of Parkinson’s disease EEG signals using 2D-MDAGTS model and multi-scale fuzzy entropy. Biomedical Signal Processing and Control91, 105872 (2024) 10 M. Chen et al
2024
-
[11]
In: International Conference on Learning Representations (2024)
Liu, Y., Hu, T., Zhang, H., Wu, H., Wang, S., Ma, L., Long, M.: iTransformer: Inverted transformers are effective for time series forecasting. In: International Conference on Learning Representations (2024)
2024
-
[12]
Miltiadous, A., Tzimourta, K.D., Afrantou, T., Ioannidis, P., Grigoriadis, N., Tsa- likakis, D.G., Angelidis, P., Tsipouras, M.G., Glavas, E., Giannakeas, N., Tzallas, A.T.: A dataset of EEG recordings from: Alzheimer’s disease, Frontotemporal de- mentia and healthy subjects (2024)
2024
-
[13]
In: International Conference on Learning Representations (2023)
Nie, Y., Nguyen, N.H., Sinthong, P., Kalagnanam, J.: A time series is worth 64 words: Long-term forecasting with transformers. In: International Conference on Learning Representations (2023)
2023
-
[14]
Proceedings of Machine Learning Research, vol
Sun, Y., Li, X., Dalal, K., Xu, J., Vikram, A., Zhang, G., Dubois, Y., Chen, X., Wang, X., Koyejo, S., Hashimoto, T., Guestrin, C.: Learning to (learn at test time): RNNswithexpressivehiddenstates.In:Proceedingsofthe42ndInternationalCon- ference on Machine Learning. Proceedings of Machine Learning Research, vol. 267, pp. 57503–57522. PMLR (2025)
2025
-
[15]
In: 2020 42nd Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC)
Tadesse, G.A., Javed, H., Weldemariam, K., Zhu, T.: A spectral-longitudinal model for detection of heart attack from 12-lead electrocardiogram waveforms. In: 2020 42nd Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). pp. 6009–6012 (2020)
2020
-
[16]
In: Advances in Neural Information Processing Systems
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems. vol. 30, pp. 5998–6008 (2017)
2017
-
[17]
Scientific Data7(1), 154 (2020)
Wagner, P., Strodthoff, N., Bousseljot, R.D., Kreiseler, D., Lunze, F.I., Samek, W., Schaeffter, T.: PTB-XL, a large publicly available electrocardiography dataset. Scientific Data7(1), 154 (2020)
2020
-
[18]
In: Advances in Neural Information Processing Systems
Wang, Y., Huang, N., Li, T., Yan, Y., Zhang, X.: Medformer: A multi-granularity patching transformer for medical time-series classification. In: Advances in Neural Information Processing Systems. vol. 37, pp. 36314–36341 (2024)
2024
-
[19]
In: Advances in Neural Informa- tion Processing Systems
Wu, H., Xu, J., Wang, J., Long, M.: Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. In: Advances in Neural Informa- tion Processing Systems. vol. 34, pp. 22419–22430 (2021)
2021
-
[20]
Proceedings of the AAAI Conference on Artificial Intelligence40(33), 27791–27799 (2026)
Ye, J., Zhang, W., Li, Z., Li, J., Tsung, F.: Medspaformer: A transferable trans- former with multi-granularity token sparsification for medical time series classi- fication. Proceedings of the AAAI Conference on Artificial Intelligence40(33), 27791–27799 (2026)
2026
-
[21]
Applied Sciences9(16), 3328 (2019)
Zhang, Y., Li, J.: Application of heartbeat-attention mechanism for detection of myocardial infarction using 12-lead ECG records. Applied Sciences9(16), 3328 (2019)
2019
-
[22]
In: International Conference on Learning Representations (2023)
Zhang, Y., Yan, J.: Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting. In: International Conference on Learning Representations (2023)
2023
-
[23]
Proceedings of the AAAI Conference on Artificial Intelligence35(12), 11106–11115 (2021)
Zhou, H., Zhang, S., Peng, J., Zhang, S., Li, J., Xiong, H., Zhang, W.: Informer: Beyond efficient transformer for long sequence time-series forecasting. Proceedings of the AAAI Conference on Artificial Intelligence35(12), 11106–11115 (2021)
2021
-
[24]
In: Proceedings of the 39th International Conference on Machine Learning
Zhou, T., Ma, Z., Wen, Q., Wang, X., Sun, L., Jin, R.: FEDformer: Frequency enhanced decomposed transformer for long-term series forecasting. In: Proceedings of the 39th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 162, pp. 27268–27286. PMLR (2022)
2022
-
[25]
Proceedings of the AAAI Conference on Artificial Intelligence39(13), 14529–14537 (2025) MedTS-TTT: Test-Time Training for Medical Time Series Classification 11
Zhou, Y., Zhao, S., Wang, J., Jiang, H., Li, S., Luo, B., Li, T., Pan, G.: Personalized sleep staging leveraging source-free unsupervised domain adaptation. Proceedings of the AAAI Conference on Artificial Intelligence39(13), 14529–14537 (2025) MedTS-TTT: Test-Time Training for Medical Time Series Classification 11
2025
-
[26]
Biomedical Signal Processing and Control114, 109321 (2026)
Zini, S., Barbera, T., Bianco, S., Napoletano, P.: Alzheimer’s disease classification from EEG using a multiscale temporal deep network. Biomedical Signal Processing and Control114, 109321 (2026)
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.