Lagrangian Perturbation Diffusion Steering: Latent Reinforcement Learning for Generative Policies
Pith reviewed 2026-06-28 17:17 UTC · model grok-4.3
The pith
A compact perturbation learned in the noise space of a frozen generative policy and optimized with a Lagrangian trust-region objective improves downstream task performance while preserving the latent prior.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LP-DS improves a frozen generative policy by learning a compact noise-space perturbation optimized via a Lagrangian trust-region objective, which increases downstream value while constraining deviation from the latent prior.
What carries the argument
Lagrangian Perturbation Diffusion Steering (LP-DS): optimizes a compact perturbation in the noise space of a frozen generative policy using a Lagrangian trust-region objective to steer decoded actions toward higher task value.
If this is right
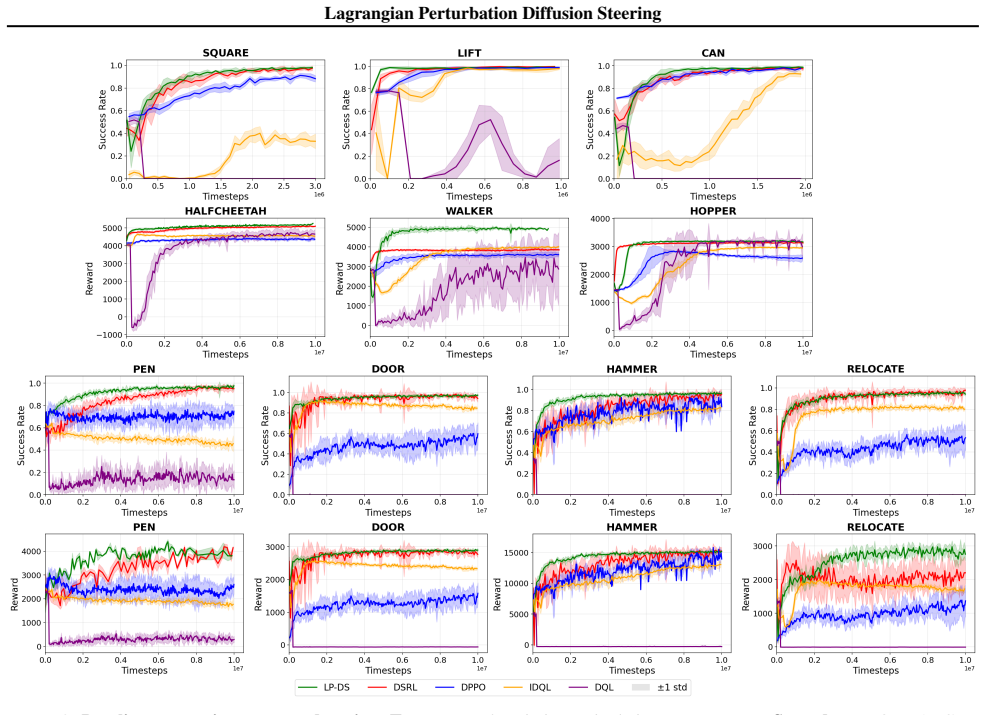
- Raises sample efficiency and success rates on RoboMimic manipulation tasks
- Delivers return improvements of up to 25 percent over prior baselines on OpenAI Gym locomotion and Adroit dexterous manipulation
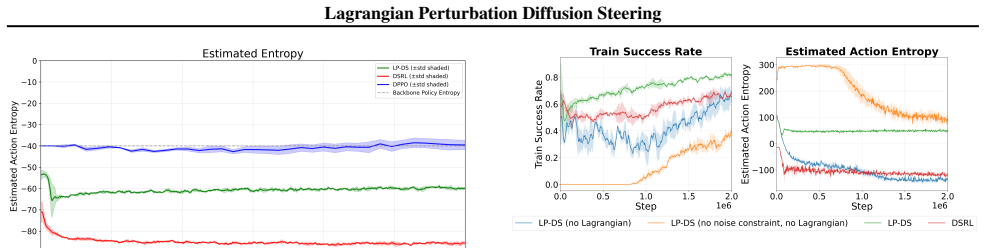
- Maintains higher action-space entropy than unconstrained noise-space steering
- Extends to flow-matching backbones, large vision-language-action models, and physical Franka robot deployment
Where Pith is reading between the lines
- The frozen-decoder approach may allow more frequent adaptation of large generative policies under limited compute
- Noise-space steering could serve as a template for adapting other sequential generative models without full retraining
- The method's entropy preservation may help retain exploration capacity when fine-tuning policies on new tasks
Load-bearing premise
Optimizing a perturbation in the noise space will lead to improved task performance without causing instabilities in the decoded actions or excessive deviation from the prior distribution.
What would settle it
An experiment in which the learned perturbations produce decoded actions that yield lower success rates, lower entropy, or measurable deviation from the original policy's output distribution on the same benchmarks.
Figures


read the original abstract
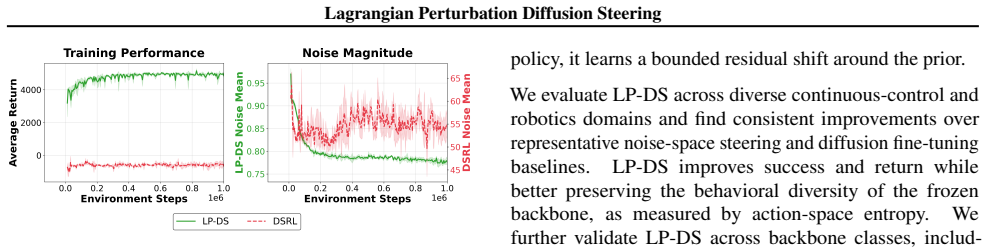
Behavior cloning with high-capacity generative policies achieves strong imitation performance, but is often limited by demonstration coverage and distribution shift. Direct reinforcement learning fine-tuning can improve performance, but updating large action decoders is frequently unstable and sample inefficient. We propose Lagrangian Perturbation Diffusion Steering (LP-DS), a lightweight adaptation method that improves a frozen generative policy by learning a compact noise-space perturbation before decoding. LP-DS optimizes this perturbation with a Lagrangian trust-region objective, improving downstream value while constraining deviation from the latent prior. Across RoboMimic manipulation, OpenAI Gym locomotion, and Adroit dexterous manipulation benchmarks, LP-DS improves sample efficiency, success, and return while maintaining higher action-space entropy than unconstrained noise-space steering, with return improvements of up to 25% over prior baselines. Additional evaluations with flow-matching backbones, a large vision-language-action model, and physical Franka deployment show that LP-DS is not limited to compact diffusion policies or simulated benchmarks. Project page: https://sites.google.com/view/lp-ds/home.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Lagrangian Perturbation Diffusion Steering (LP-DS), a lightweight adaptation technique for frozen generative policies. It learns a compact perturbation in the noise space of a pre-trained diffusion (or flow-matching) policy and optimizes this perturbation via a Lagrangian trust-region objective that trades off downstream task value against deviation from the latent prior. Empirical results are reported on RoboMimic manipulation, OpenAI Gym locomotion, Adroit dexterous tasks, a large vision-language-action model, and physical Franka deployment, claiming gains in sample efficiency, success rate, and return (up to 25 % over baselines) while preserving higher action-space entropy than unconstrained steering.
Significance. If the empirical claims hold under rigorous verification, the method offers a practical route to improve generative policies without the instability and sample cost of full decoder fine-tuning. The breadth of evaluation (simulation, flow-matching backbones, VLA models, and real-robot deployment) and the explicit entropy comparison are positive features that could influence latent-space RL practice.
major comments (2)
- [Abstract, §3] Abstract and §3: the central empirical claim of 'return improvements of up to 25 % over prior baselines' is presented without any reported implementation details, baseline definitions, number of random seeds, error bars, or statistical tests. Because the soundness of the contribution rests entirely on these quantitative results, the absence of this information prevents verification that the reported gains are robust or correctly attributed to LP-DS.
- [§4] §4 (method): the Lagrangian trust-region objective is described at a high level but no explicit formulation (e.g., the precise form of the constraint, how the multiplier is updated, or the trust-region radius schedule) is supplied. Without this, it is impossible to assess whether the constraint is enforced before or after decoding and whether the reported entropy preservation follows from the formulation or from post-hoc tuning.
minor comments (2)
- The project page URL is given but no link to code, hyperparameters, or evaluation scripts is provided in the manuscript; reproducibility would be strengthened by including these.
- [§3] Notation for the noise-space perturbation and the latent prior should be introduced with explicit symbols and dimensions in the method section rather than left implicit.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3: the central empirical claim of 'return improvements of up to 25 % over prior baselines' is presented without any reported implementation details, baseline definitions, number of random seeds, error bars, or statistical tests. Because the soundness of the contribution rests entirely on these quantitative results, the absence of this information prevents verification that the reported gains are robust or correctly attributed to LP-DS.
Authors: The experimental section (§4) and appendix already specify the baselines (BC, RL fine-tuning, unconstrained steering), 5 random seeds per task, error bars as mean±std, and paired t-tests for significance; the 25% figure is the maximum per-task improvement with full per-task tables provided. To improve verifiability we will add a short clause in the abstract directing readers to the evaluation protocol in §4. revision: partial
-
Referee: [§4] §4 (method): the Lagrangian trust-region objective is described at a high level but no explicit formulation (e.g., the precise form of the constraint, how the multiplier is updated, or the trust-region radius schedule) is supplied. Without this, it is impossible to assess whether the constraint is enforced before or after decoding and whether the reported entropy preservation follows from the formulation or from post-hoc tuning.
Authors: We agree the formulation should be stated explicitly. The revised §3 will include the exact constrained objective, the dual ascent rule for the multiplier, the linear trust-region radius schedule, and a statement that the constraint operates in latent noise space before decoding (which directly yields the observed entropy preservation). Pseudocode will also be added. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper introduces LP-DS as an algorithmic adaptation technique that learns a compact noise-space perturbation for a frozen generative policy, optimized via a Lagrangian trust-region objective. No derivation chain, uniqueness theorem, or first-principles prediction is claimed; the contribution consists of an optimization procedure whose performance is assessed empirically across benchmarks. The method does not reduce any reported outcome to a fitted parameter or self-citation by construction, rendering the central claims self-contained as an empirical proposal.
Axiom & Free-Parameter Ledger
free parameters (1)
- trust region size or Lagrangian multiplier
axioms (1)
- domain assumption Perturbations in the diffusion noise space can be optimized to improve downstream value while remaining close to the original policy prior.
Reference graph
Works this paper leans on
-
[1]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
URL https://arxiv.org/abs/2204.01691. Ajay, A., Du, Y ., Gupta, A., Tenenbaum, J., Jaakkola, T., and Agrawal, P. Is conditional generative modeling all you need for decision-making?,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Is Conditional Generative Modeling all you need for Decision-Making?
URL https: //arxiv.org/abs/2211.15657. Ankile, L., Simeonov, A., Shenfeld, I., and Agrawal, P. Juicer: Data-efficient imitation learning for robotic assem- bly,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
URL https://arxiv.org/abs/ 1606.01540. Chandra, A. L., Nematollahi, I., Huang, C., Welschehold, T., Burgard, W., and Valada, A. Diwa: Diffusion policy adaptation with world models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
DiWA: Diffusion policy adaptation with world models.arXiv preprint arXiv:2508.03645, 2025
URL https:// arxiv.org/abs/2508.03645. Chen, H., Lu, C., Ying, C., Su, H., and Zhu, J. Offline rein- forcement learning via high-fidelity generative behavior modeling,
-
[5]
Chi, C., Xu, Z., Feng, S., Cousineau, E., Du, Y ., Burchfiel, B., Tedrake, R., and Song, S
URL https://arxiv.org/abs/ 2209.14548. Chi, C., Xu, Z., Feng, S., Cousineau, E., Du, Y ., Burchfiel, B., Tedrake, R., and Song, S. Diffusion policy: Visuo- motor policy learning via action diffusion,
-
[6]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
URL https://arxiv.org/abs/2303.04137. Dasari, S., Mees, O., Zhao, S., Srirama, M. K., and Levine, S. The ingredients for robotic diffusion trans- formers,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
arXiv preprint arXiv:2410.10088 , year=
URL https://arxiv.org/abs/ 2410.10088. Eyring, L., Karthik, S., Roth, K., Dosovitskiy, A., and Akata, Z. Reno: Enhancing one-step text-to-image mod- els through reward-based noise optimization,
-
[8]
Eyring, L., Karthik, S., Dosovitskiy, A., Ruiz, N., and Akata, Z
URL https://arxiv.org/abs/2406.04312. Eyring, L., Karthik, S., Dosovitskiy, A., Ruiz, N., and Akata, Z. Noise hypernetworks: Amortizing test-time compute in diffusion models,
-
[9]
Hansen-Estruch, P., Kostrikov, I., Janner, M., Kuba, J
URL https: //arxiv.org/abs/2508.09968. Hansen-Estruch, P., Kostrikov, I., Janner, M., Kuba, J. G., and Levine, S. Idql: Implicit q-learning as an actor- critic method with diffusion policies,
-
[10]
IDQL: Implicit Q-Learning as an Actor-Critic Method with Diffusion Policies
URLhttps: //arxiv.org/abs/2304.10573. Ho, J., Jain, A., and Abbeel, P. Denoising diffusion proba- bilistic models.arXiv preprint arXiv:2006.11239,
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[11]
Imagen Video: High Definition Video Generation with Diffusion Models
URL https: //arxiv.org/abs/2210.02303. Jia, X., Blessing, D., Jiang, X., Reuss, M., Donat, A., Li- outikov, R., and Neumann, G. Towards diverse behaviors: A benchmark for imitation learning with human demon- strations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
URL https://arxiv.org/abs/ 2402.14606. Kang, B., Ma, X., Du, C., Pang, T., and Yan, S. Efficient diffusion policies for offline reinforcement learning,
-
[13]
10 Lagrangian Perturbation Diffusion Steering Kostrikov, I., Nair, A., and Levine, S
URLhttps://arxiv.org/abs/2305.20081. 10 Lagrangian Perturbation Diffusion Steering Kostrikov, I., Nair, A., and Levine, S. Offline reinforcement learning with implicit q-learning,
-
[14]
Offline Reinforcement Learning with Implicit Q-Learning
URL https: //arxiv.org/abs/2110.06169. Kozachenko, L. F. and Leonenko, N. N. Sample estimate of the entropy of a random vector.Problems of Information Transmission, 23(2):95–101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Flow Matching for Generative Modeling
URL https://arxiv.org/ abs/2210.02747. Liu, B., Zhu, Y ., Gao, C., Feng, Y ., Liu, Q., Zhu, Y ., and Stone, P. Libero: Benchmarking knowledge transfer for lifelong robot learning,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
URL https://arxiv. org/abs/2306.03310. Liu, X., Gong, C., and Liu, Q. Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
URL https://arxiv. org/abs/2209.03003. Mandlekar, A., Xu, D., Wong, J., Nasiriany, S., Wang, C., Kulkarni, R., Fei-Fei, L., Savarese, S., Zhu, Y ., and Mart´ın-Mart´ın, R. What matters in learning from of- fline human demonstrations for robot manipulation. In Conference on Robot Learning (CoRL),
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
URLhttps://arxiv.org/abs/2503.14734. Park, S., Li, Q., and Levine, S. Flow q-learning,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Flow q-learning.arXiv preprint arXiv:2502.02538,
URL https://arxiv.org/abs/2502.02538. Pearce, T., Rashid, T., Kanervisto, A., Bignell, D., Sun, M., Georgescu, R., Macua, S. V ., Tan, S. Z., Momennejad, I., Hofmann, K., and Devlin, S. Imitating human behaviour with diffusion models,
-
[20]
URL https://arxiv. org/abs/2301.10677. Rajeswaran, A., Kumar, V ., Gupta, A., Vezzani, G., Schul- man, J., Todorov, E., and Levine, S. Learning complex dexterous manipulation with deep reinforcement learning and demonstrations.arXiv preprint arXiv:1709.10087,
-
[21]
Diffusion Policy Policy Optimization
URL https://arxiv.org/abs/2409.00588. Samuel, D., Ben-Ari, R., Raviv, S., Darshan, N., and Chechik, G. Generating images of rare concepts us- ing pre-trained diffusion models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Singh, A., Liu, H., Zhou, G., Yu, A., Rhinehart, N., and Levine, S
URL https: //arxiv.org/abs/2304.14530. Singh, A., Liu, H., Zhou, G., Yu, A., Rhinehart, N., and Levine, S. Parrot: Data-driven behavioral priors for re- inforcement learning,
-
[23]
URL https://arxiv. org/abs/2011.10024. Song, J., Meng, C., and Ermon, S. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502,
-
[24]
Denoising Diffusion Implicit Models
URLhttps://arxiv.org/abs/2010.02502. Sridhar, A., Shah, D., Glossop, C., and Levine, S. Nomad: Goal masked diffusion policies for navigation and ex- ploration,
work page internal anchor Pith review Pith/arXiv arXiv 2010
- [25]
-
[26]
URL https:// arxiv.org/abs/2502.06999. Wagenmaker, A., Nakamoto, M., Zhang, Y ., Park, S., Yagoub, W., Nagabandi, A., Gupta, A., and Levine, S. Steering your diffusion policy with latent space reinforce- ment learning,
-
[27]
Steering Your Diffusion Policy with Latent Space Reinforcement Learning
URL https://arxiv.org/ abs/2506.15799. Wang, Z., Hunt, J. J., and Zhou, M. Diffusion policies as an expressive policy class for offline reinforcement learning,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning
URL https://arxiv.org/abs/ 2208.06193. 11 Lagrangian Perturbation Diffusion Steering Ze, Y ., Zhang, G., Zhang, K., Hu, C., Wang, M., and Xu, H. 3d diffusion policy: Generalizable visuomotor pol- icy learning via simple 3d representations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations
URL https://arxiv.org/abs/2403.03954. 12 Lagrangian Perturbation Diffusion Steering A. Additional Experimental Details A.1. Common Experimental Settings For fair comparison, we adopt the same environments, eval- uation protocols, network architectures, optimizer settings, and training schedules as the DSRL baseline. Unless oth- erwise specified, all hyper...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
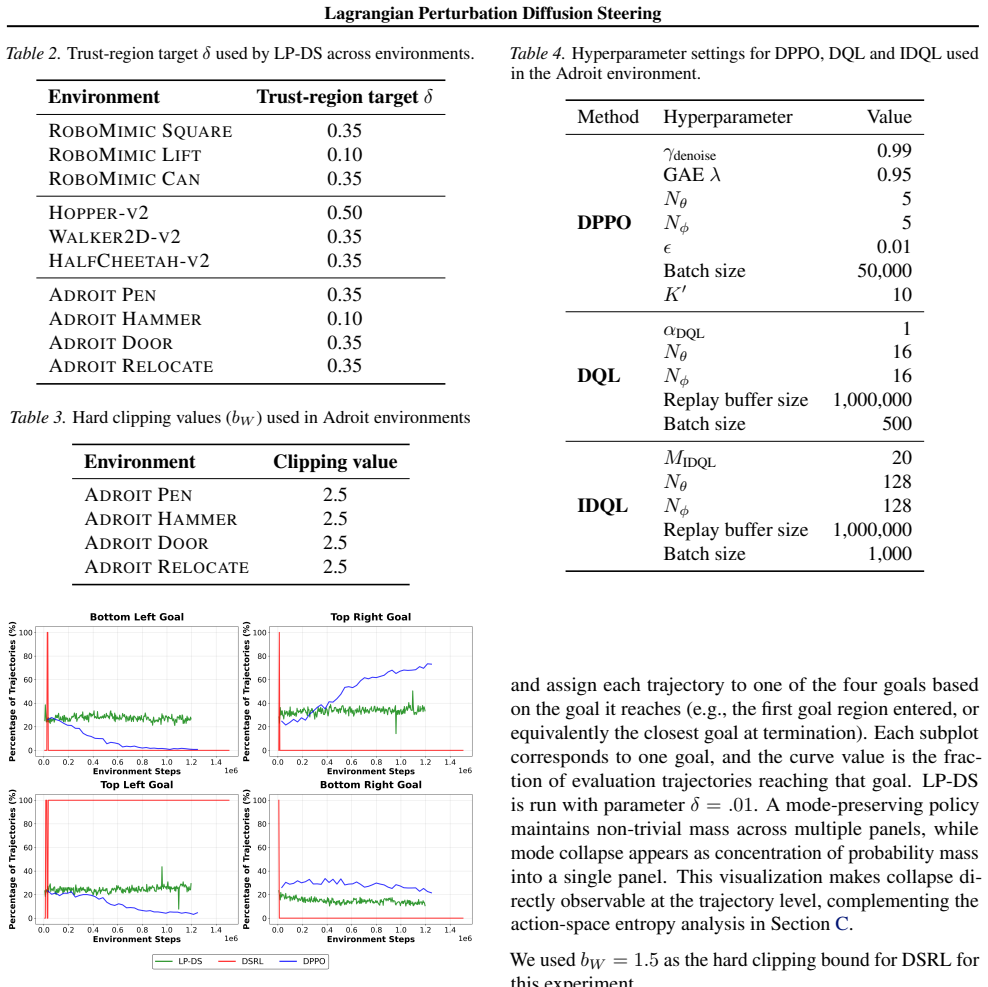
Transitions follow st+1 = clip(st + 0.5 clip(at,−1,1),−2,2) with a horizon of 20 steps. The reward is shaped by the distance to the nearest goal, with a sparse bonus upon entering a goal region: rt = −min g∈G ∥st −g∥2+10I[min g∈G ∥st −g∥2 <0.2] , where G={(±1,±1)}are four corner goals. To obtain a multimodal behavioral prior, we generate an offline datase...
1987
-
[31]
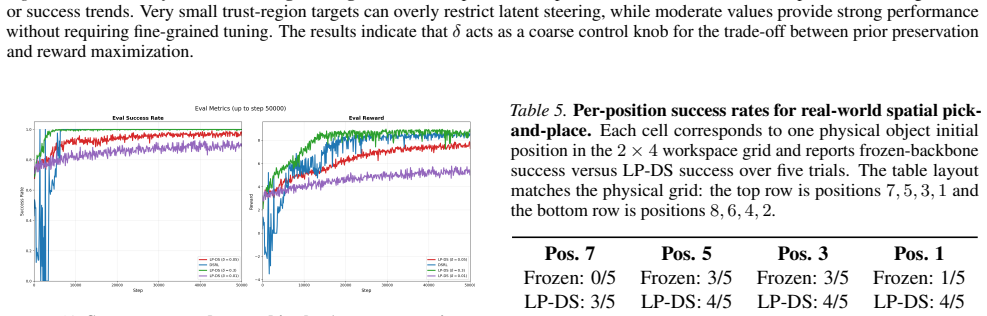
Figure 12 shows the effect of different trust-region targets
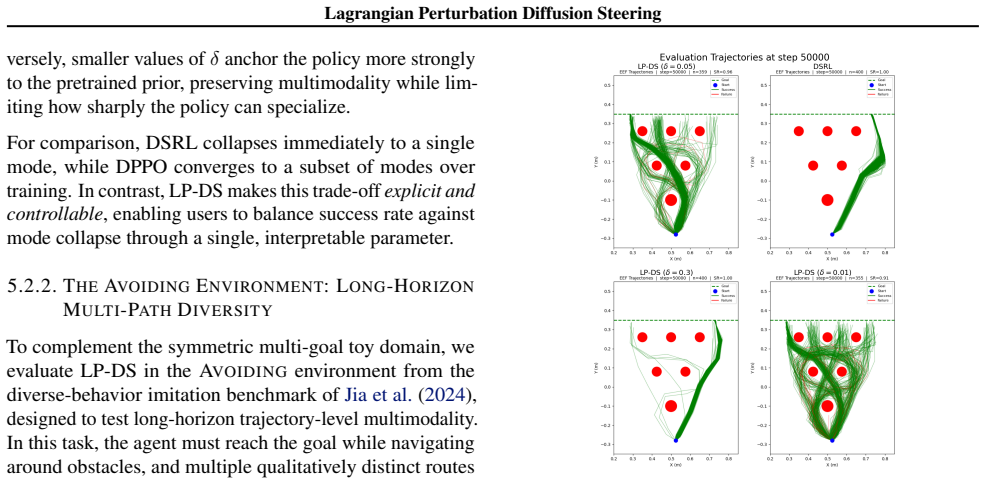
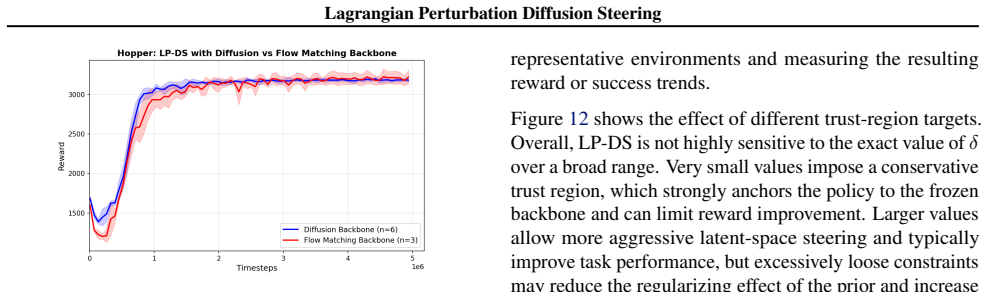
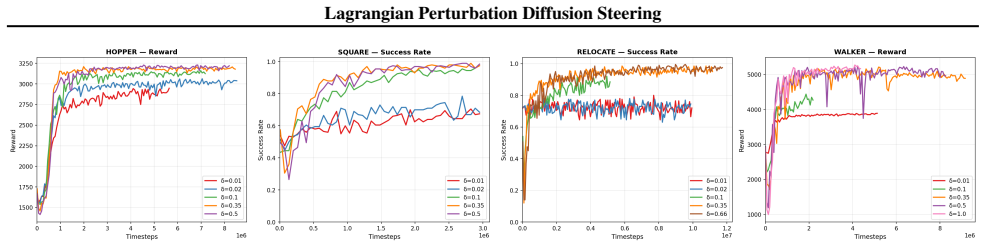
Here, we study how sensitive the method is to this choice by sweeping δ across representative environments and measuring the resulting reward or success trends. Figure 12 shows the effect of different trust-region targets. Overall, LP-DS is not highly sensitive to the exact value ofδ over a broad range. Very small values impose a conservative trust region...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.