When does dissipation help neural surrogates learn open quantum dynamics?
Pith reviewed 2026-06-26 07:56 UTC · model grok-4.3
The pith
Dissipation enhances neural ODE learning of open quantum dynamics at moderate strengths and intermediate sizes, though fidelity can reflect trajectory simplification instead of genuine transient capture.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
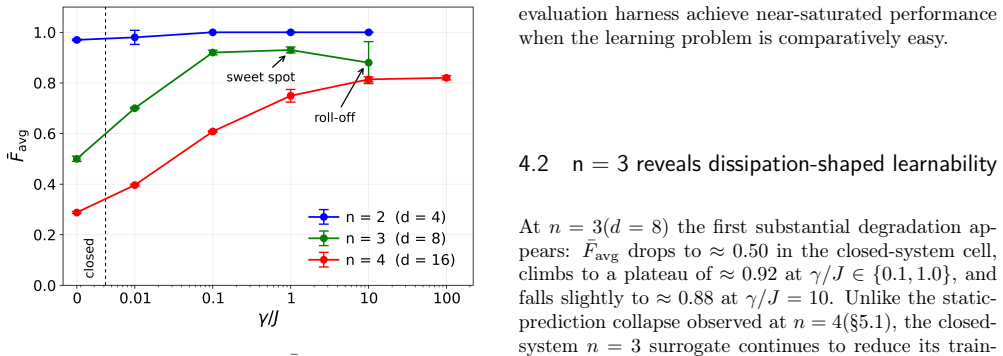
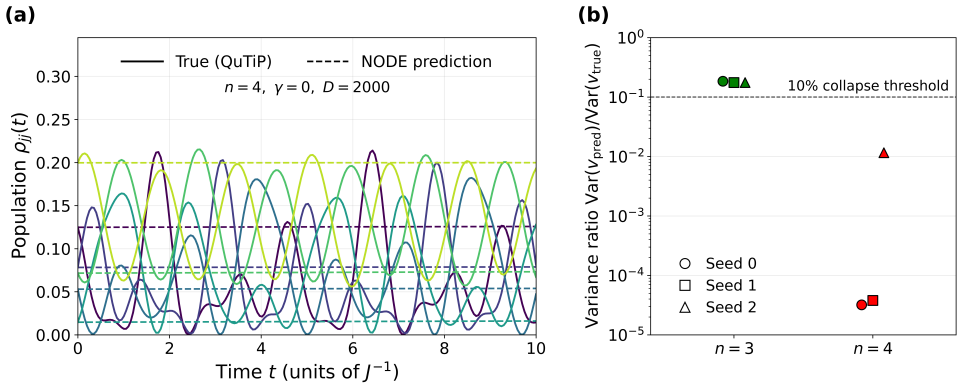
NODE surrogates trained on open Heisenberg XYZ chains show that dissipation reverses the rapid size-induced loss of learnability seen in closed systems, producing high-fidelity rollouts at intermediate qubit counts; at four qubits a fidelity-aware objective recovers rollout structure absent under closed training. Direct comparison with static and steady-state baselines establishes that weak-to-moderate dissipation enables capture of nontrivial transients that substantially outperform trivial predictors, whereas stronger damping increasingly yields high fidelity through simplification to the steady state rather than improved learned dynamics.
What carries the argument
Neural Ordinary Differential Equation surrogates for open Heisenberg XYZ spin chains, benchmarked against static and steady-state predictors to isolate transient dynamical learning from dissipative contraction.
If this is right
- At weak-to-moderate dissipation the surrogate learns nontrivial transient dynamics and substantially outperforms static or steady-state baselines.
- At stronger damping, high fidelity increasingly measures trajectory simplification toward the steady state rather than improved dynamical learning.
- Closed-system training collapses to static prediction at four qubits, but dissipation plus a fidelity-aware objective recovers learnable rollout structure.
- Dissipative contraction and trajectory simplification are distinct effects that peak in different regimes and must be disentangled when evaluating learned quantum-dynamical surrogates.
Where Pith is reading between the lines
- Future surrogate evaluations for open quantum systems will likely need metrics that isolate transient error growth from steady-state convergence.
- Moderate engineered dissipation could serve as a practical tuning knob to improve neural approximation of intermediate-sized open systems.
- The same separation of contraction versus learning effects may appear in other dissipative machine-learning settings beyond spin chains.
Load-bearing premise
That fidelity gains at moderate dissipation indicate capture of genuine transient dynamics rather than partial simplification of trajectories to the steady state.
What would settle it
A calculation showing that, at moderate dissipation, the surrogate's predicted time-dependent observables match the exact transients over a window where the steady-state baseline already deviates, or that ablating the learned dissipation term still reproduces short-time dynamics accurately.
Figures




read the original abstract
Dissipation is usually viewed as an obstacle to predicting quantum dynamics, yet it can also contract trajectories toward steady states and thereby suppress accumulated prediction errors, leaving it unclear whether dissipation ultimately helps or hinders the learnability of open quantum dynamics. We investigate this question using Neural Ordinary Differential Equation (NODE) surrogates for open Heisenberg XYZ spin chains. Closed-system learnability deteriorates rapidly with system size, culminating in a static-prediction collapse at four qubits; dissipation reverses this trend, creating a broad high-fidelity regime at intermediate system sizes, while at four qubits a fidelity-aware objective recovers learnable rollout structure that is absent under closed-system training. Comparison against static and steady-state baselines reveals that dissipation improves performance through two fundamentally different mechanisms: at weak-to-moderate dissipation the surrogate captures nontrivial transient dynamics and substantially outperforms trivial predictors, whereas at stronger damping high fidelity increasingly reflects trajectory simplification toward the steady state rather than improved learned dynamics. These results show that dissipation can enhance the learnability of open quantum dynamics, but that fidelity alone is insufficient to distinguish genuine dynamical learning from steady-state trivialization: dissipative contraction and trajectory simplification are distinct effects that peak in different regimes and should be disentangled when evaluating learned quantum-dynamical surrogates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates whether dissipation helps or hinders learnability of open quantum dynamics using Neural ODE surrogates trained on open Heisenberg XYZ spin chains. It reports that closed-system performance collapses with system size (static prediction at 4 qubits), while dissipation creates a broad high-fidelity regime at intermediate sizes; at 4 qubits a fidelity-aware objective recovers rollout structure absent in closed training. Static and steady-state baselines are used to argue that weak-to-moderate dissipation enables capture of nontrivial transients (outperforming baselines), whereas stronger damping yields fidelity mainly via trajectory simplification toward the steady state. The central conclusion is that dissipation can enhance learnability but fidelity alone cannot distinguish genuine dynamical learning from trivialization, so the two effects must be disentangled.
Significance. If the reported separation of mechanisms holds under tighter controls, the work supplies a concrete demonstration that dissipation is not uniformly detrimental to neural surrogates for open quantum systems and supplies a practical testbed (NODEs on XYZ chains) for evaluating when contraction aids versus trivializes learning. The explicit caveat about fidelity limitations is a strength.
major comments (1)
- [Abstract] Abstract: the claim that static/steady-state baseline comparisons establish capture of nontrivial transients at weak-to-moderate damping is load-bearing for the central thesis, yet the text itself states that contraction and simplification 'must be disentangled' without reporting additional controls (time-averaged predictors, partially damped models, or trajectory-complexity metrics) sufficient to exclude residual simplification contributions to the reported fidelity gains.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on our manuscript. The concern about the sufficiency of the baseline comparisons for separating nontrivial transient learning from trajectory simplification is well-taken, and we address it directly below. We will incorporate additional controls and clarifications in the revised version.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that static/steady-state baseline comparisons establish capture of nontrivial transients at weak-to-moderate damping is load-bearing for the central thesis, yet the text itself states that contraction and simplification 'must be disentangled' without reporting additional controls (time-averaged predictors, partially damped models, or trajectory-complexity metrics) sufficient to exclude residual simplification contributions to the reported fidelity gains.
Authors: We agree that the distinction between dissipative contraction (which suppresses error accumulation while preserving dynamical structure) and trajectory simplification (which reduces the effective complexity of the target) is central, and that the abstract claim relies on the baselines demonstrating capture of nontrivial transients. The static baseline implements a constant prediction of the initial state for all times, while the steady-state baseline implements a constant prediction of the long-time equilibrium; outperforming both at weak-to-moderate damping therefore indicates that the NODE is reproducing time-dependent features absent from either trivial predictor. That said, we acknowledge that these two baselines alone do not fully exclude the possibility that some fraction of the fidelity improvement arises from a partial reduction in trajectory variance rather than from learning the underlying Liouvillian. In the revision we will add two further controls: (i) a time-averaged predictor that outputs the trajectory mean at every time step, and (ii) a trajectory-complexity metric (integrated state variance and a simple entropy measure of the Bloch-vector evolution) plotted against dissipation strength. These will be presented in a new supplementary figure and discussed in the main text to quantify how much of the performance gain is explained by simplification versus genuine dynamical learning. We do not expect these additions to change the qualitative conclusion that dissipation can enhance learnability, but they will make the separation of mechanisms more rigorous. revision: yes
Circularity Check
No circularity: empirical results rest on independent baselines and measured fidelities
full rationale
The paper reports an empirical study of NODE surrogates on open Heisenberg chains, with performance quantified via direct comparison to static and steady-state predictors that are defined independently of the trained model. No equation or claim reduces a reported prediction to a fitted parameter by construction, no self-citation supplies a load-bearing uniqueness theorem, and the abstract explicitly distinguishes the two mechanisms without tautological redefinition. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Completely positive dynamical semigroups of n-level systems
V. Gorini, A. Kossakowski, and E. C. G. Sudar- shan. “Completely positive dynamical semigroups of n-level systems”. J. Math. Phys.17, 821– 825 (1976)
1976
-
[2]
On the generators of quantum dy- namical semigroups
G. Lindblad. “On the generators of quantum dy- namical semigroups”. Commun. Math. Phys.48, 119–130 (1976)
1976
-
[3]
The theory of open quantum systems
H. P. Breuer and F. Petruccione. “The theory of open quantum systems”. Oxford University Press. (2007)
2007
-
[4]
A short introduction to the lindblad master equation
D. Manzano. “A short introduction to the lindblad master equation”. AIP Adv.10, 025106 (2020)
2020
-
[5]
The density-matrix renormaliza- tion group in the age of matrix product states
U. Schollwöck. “The density-matrix renormaliza- tion group in the age of matrix product states”. Ann. Phys. (N. Y.)326, 96–192 (2011)
2011
-
[6]
Matrix product density operators: Simulation of finite-temperature and dissipative systems
F. Verstraete, J. J. García-Ripoll, and J. I. Cirac. “Matrix product density operators: Simulation of finite-temperature and dissipative systems”. Phys. Rev. Lett.93, 207204 (2004)
2004
-
[7]
Neural Ordinary Differential Equations
R. T. Q. Chen, Y. Rubanova, J. Bettencourt, and D. Duvenaud. “Neural ordinary differen- tial equations”. Adv. Neural Inf. Process. Syst. (NeurIPS)31(2018). arXiv:1806.07366
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
On neural differential equations
P. Kidger. “On neural differential equations”. PhD thesis. University of Oxford. (2022)
2022
-
[9]
Latent ODEs for Irregularly-Sampled Time Series
Y. Rubanova, R. T. Q. Chen, and D. K. Duve- naud. “Latent ordinary differential equations for irregularly-sampled time series”. Adv. Neural Inf. Process. Syst.32(2019). arXiv:1907.03907
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[10]
Learning quantum dynamics with latent neural ordinary differential equations
M. Choi, D. Flam-Shepherd, T. H. Kyaw, and A. Aspuru-Guzik. “Learning quantum dynamics with latent neural ordinary differential equations”. Phys. Rev. A105, 042403 (2022)
2022
-
[11]
Learningquantumdissipation by the neural ordinary differential equation
L.ChenandY.Wu. “Learningquantumdissipation by the neural ordinary differential equation”. Phys. Rev. A106, 022201 (2022)
2022
-
[12]
Solving the quan- tum many-body problem with artificial neural net- works
G. Carleo and M. Troyer. “Solving the quan- tum many-body problem with artificial neural net- works”. Science355, 602–606 (2017)
2017
-
[13]
Neural-network quan- tum state tomography
G. Torlai, G. Mazzola, J. Carrasquilla, M. Troyer, R. Melko, and G. Carleo. “Neural-network quan- tum state tomography”. Nat. Phys.14, 447– 450 (2018)
2018
-
[14]
Netket: A machine learning toolkit for many-body quantum systems
G. Carleo, K. Choo, D. Hofmann, J. E. T. Smith, T. Westerhout, F. Alet, E. J. Davis, S. Efthymiou, I. Glasser, S. H. Lin, M. Mauri, G. Mazzola, C. B. 12 Mendl, E.vanNieuwenburg, O.O’Reilly, H.Théve- niaut, G. Torlai, F. Vicentini, and A. Wietek. “Netket: A machine learning toolkit for many-body quantum systems”. SoftwareX10, 100311 (2019)
2019
-
[15]
Neural-network approach to dissipative quantum many-body dy- namics
M. J. Hartmann and G. Carleo. “Neural-network approach to dissipative quantum many-body dy- namics”. Phys. Rev. Lett.122, 250502 (2019)
2019
-
[16]
Variational quantum monte carlo method with a neural-network ansatz for open quantum systems
A. Nagy and V. Savona. “Variational quantum monte carlo method with a neural-network ansatz for open quantum systems”. Phys. Rev. Lett.122, 250501 (2019)
2019
-
[17]
Variational neural-network ansatz for steady states in open quantum systems
F. Vicentini, A. Biella, N. Regnault, and C. Ciuti. “Variational neural-network ansatz for steady states in open quantum systems”. Phys. Rev. Lett. 122, 250503 (2019)
2019
-
[18]
Constructing neu- ral stationary states for open quantum many-body systems
N. Yoshioka and R. Hamazaki. “Constructing neu- ral stationary states for open quantum many-body systems”. Phys. Rev. B99, 214306 (2019)
2019
-
[19]
Time- dependent variational principle for open quantum systemswithartificialneuralnetworks
M. Reh, M. Schmitt, and M. Gärttner. “Time- dependent variational principle for open quantum systemswithartificialneuralnetworks”. Phys.Rev. Lett.127, 230501 (2021)
2021
-
[20]
Quantum computing in the nisq era and beyond
J. Preskill. “Quantum computing in the nisq era and beyond”. Quantum2, 79 (2018)
2018
-
[21]
Noisy intermediate-scale quantum algo- rithms
K. Bharti, A. Cervera-Lierta, T. H. Kyaw, T. Haug, S. Alperin-Lea, A. Anand, M. Deg- roote, H. Heimonen, J. S. Kottmann, T. Menke, W. K. Mok, S. Sim, L. C. Kwek, and A. Aspuru- Guzik. “Noisy intermediate-scale quantum algo- rithms”. Rev. Mod. Phys.94, 015004 (2022)
2022
-
[22]
Robust classification using contractive hamiltonian neural odes
M.Zakwan, L.Xu, andG.Ferrari-Trecate. “Robust classification using contractive hamiltonian neural odes”. IEEE Control Syst. Lett.7, 145–150 (2023)
2023
-
[23]
Qutip: An open-source python framework for the dynam- ics of open quantum systems
J. R. Johansson, P. D. Nation, and F. Nori. “Qutip: An open-source python framework for the dynam- ics of open quantum systems”. Comput. Phys. Commun.183, 1760–1772 (2012)
2012
-
[24]
Qutip 2: A python framework for the dynamics of open quantum systems
J. R. Johansson, P. D. Nation, and F. Nori. “Qutip 2: A python framework for the dynamics of open quantum systems”. Comput. Phys. Commun.184, 1234–1240 (2013)
2013
-
[25]
Qutip 5: The quantum toolbox in python
N.Lambert, E.Giguère, P.Menczel, B.Li, P.Hopf, G. Suárez, M. Gali, J. Lishman, R. Gadhvi, R. Agarwal, A. Galicia, N. Shammah, P. Nation, J. R. Johansson, S. Ahmed, S. Cross, A. Pitchford, and F. Nori. “Qutip 5: The quantum toolbox in python”. Phys. Rep.1153, 1–62 (2026)
2026
-
[26]
Positive- definite parametrization of mixed quantum states with deep neural networks
F. Vicentini, R. Rossi, and G. Carleo. “Positive- definite parametrization of mixed quantum states with deep neural networks” (2022). arXiv:2206.13488
-
[27]
One- dimensional magnetism
H.-J. Mikeska and A. K. Kolezhuk. “One- dimensional magnetism”. In U. Schollwöck, J. Richter, D. J. J. Farnell, and R. F. Bishop, edi- tors, Quantum Magnetism. Volume 645 of Lecture Notes in Physics, pages 1–83. Springer, Berlin, Hei- delberg (2004)
2004
-
[28]
The “transition probability
A. Uhlmann. “The “transition probability” in the state space of a∗-algebra”. Rep. Math. Phys.9, 273–279 (1976)
1976
-
[29]
Fidelity for mixed quantum states
R. Jozsa. “Fidelity for mixed quantum states”. J. Mod. Opt.41, 2315–2323 (1994)
1994
-
[30]
Quantum compu- tation and quantum information: 10th anniversary edition
M. A. Nielsen and I. L. Chuang. “Quantum compu- tation and quantum information: 10th anniversary edition”. Cambridge University Press. (2010)
2010
-
[31]
Efficient method for computing the maximum- likelihood quantum state from measurements with additive gaussian noise
J. A. Smolin, J. M. Gambetta, and G. Smith. “Efficient method for computing the maximum- likelihood quantum state from measurements with additive gaussian noise”. Phys. Rev. Lett.108, 070502 (2012)
2012
-
[32]
A family of em- bedded runge-kutta formulae
J. R. Dormand and P. J. Prince. “A family of em- bedded runge-kutta formulae”. J. Comput. Appl. Math.6, 19–26 (1980)
1980
-
[33]
Sigmoid- weighted linear units for neural network function approximation in reinforcement learning
S. Elfwing, E. Uchibe, and K. Doya. “Sigmoid- weighted linear units for neural network function approximation in reinforcement learning”. Neural Netw.107, 3–11 (2018)
2018
-
[34]
Searching for Activation Functions
P. Ramachandran, B. Zoph, and Q. V. Le. “Search- ing for activation functions”. 6th International Conference on Learning Representations (ICLR), Workshop Track (2017). arXiv:1710.05941
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[35]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. L. Ba. “Adam: A method for stochastic optimization”. 3rd International Confer- ence on Learning Representations (ICLR) (2014). arXiv:1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[36]
S. Massaroli, M. Poli, J. Park, A. Yamashita, and H. Asama. “Dissecting neural odes”. Adv. Neural Inf. Process. Syst.33, 3952–3963 (2020). arXiv:2002.08071
-
[37]
Re- current equilibrium networks: Flexible dynamic models with guaranteed stability and robust- ness
M. Revay, R. Wang, and I. R. Manchester. “Re- current equilibrium networks: Flexible dynamic models with guaranteed stability and robust- ness”. IEEE Trans. Automat. Contr.69, 2855– 2870 (2024)
2024
-
[38]
Latent space purifica- tion via neural density operators
G. Torlai and R. G. Melko. “Latent space purifica- tion via neural density operators”. Phys. Rev. Lett. 120, 240503 (2018). 13
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.