On the Relationship Between Activation Outliers and Feature Death in Sparse Autoencoders
Pith reviewed 2026-06-28 23:32 UTC · model grok-4.3
The pith
Activation outliers in neural network layers cause many sparse autoencoder features to die at initialization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
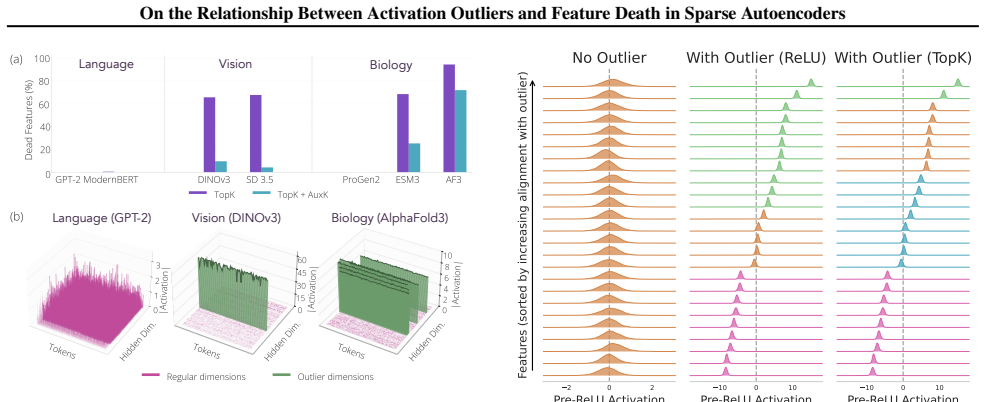
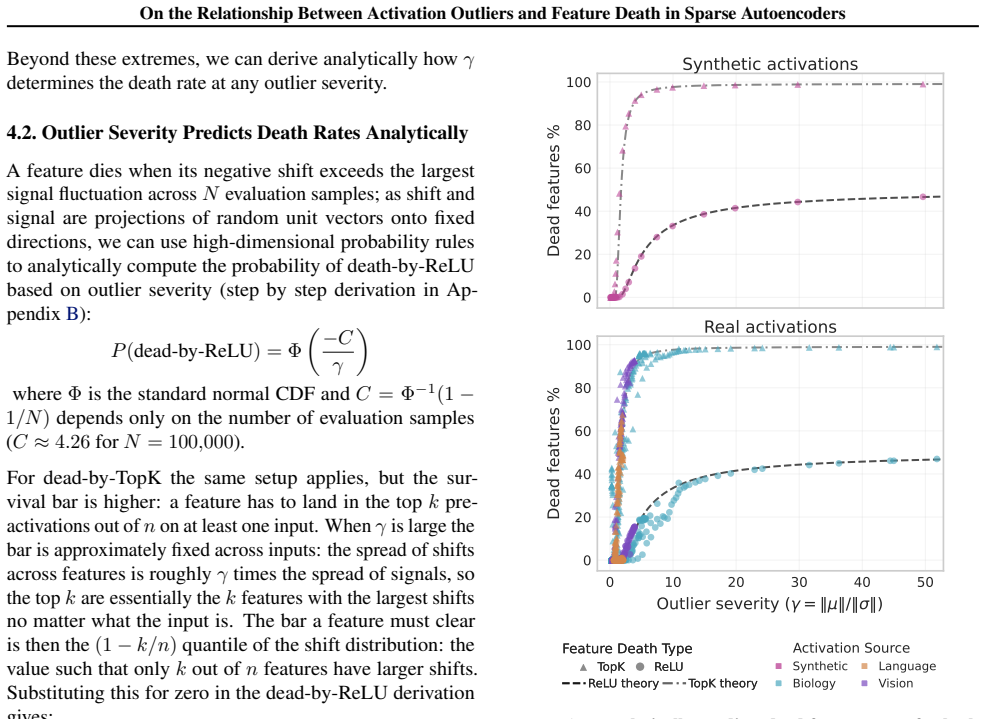
Dimension-level activation outliers cause feature death in SAEs because they shift pre-activations at initialization: features anti-aligned with the activation mean receive permanently negative pre-activations and never fire. Outlier severity gamma equals the norm of the mean divided by the norm of the standard deviation, and this value predicts initial death rates with high Spearman correlation across 454 model-layer combinations. Mean-centering eliminates the death.
What carries the argument
The outlier severity measure gamma = ||mu|| / ||sigma||, which quantifies how much the activation mean dominates per-token variation and drives the pre-activation shift.
Load-bearing premise
The assumption that the initialization-time pre-activation shift from outliers is the primary cause of the observed feature death rates rather than other training dynamics.
What would settle it
Finding a model-layer combination where gamma does not correlate with death rates, or where mean-centering fails to reduce death despite high gamma.
Figures



read the original abstract
Sparse autoencoders (SAEs) decompose neural network activations into interpretable features, but many learned features never activate, a problem called feature death that wastes dictionary capacity and can reintroduce superposition. Death rates vary dramatically between models: near-zero on GPT-2, over 70% on AlphaFold3 with identical configurations. We find that dimension-level activation outliers (dimensions whose mean magnitude is large relative to per-token variation) cause this by shifting pre-activations at initialization based on each feature's alignment with the activation mean. Features anti-aligned with the mean receive permanently negative pre-activations and never fire. We formalize outlier severity as $\gamma = \|\mu\|/\|\sigma\|$; it predicts initial death rates (Spearman $\rho = 0.89$ for dead-by-TopK, $0.82$ for dead-by-ReLU) across 454 model-layer combinations spanning language, vision, protein, and genomic models. Dead features can revive during training, but recovery requires the SAE bias to learn the activation mean, a process that is prohibitively slow at high $\gamma$. Mean-centering (subtracting the activation mean) sidesteps this and eliminates outlier-induced death across all tested models, confirming the mechanism and providing a principled basis for when and why this preprocessing step is necessary.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that feature death in sparse autoencoders arises from dimension-level activation outliers, which induce a pre-activation shift at initialization proportional to each feature's alignment with the activation mean μ. Outlier severity is formalized as γ = ‖μ‖/‖σ‖, which predicts initial death rates via high Spearman correlations (ρ = 0.89 for dead-by-TopK, ρ = 0.82 for dead-by-ReLU) across 454 model-layer combinations spanning language, vision, protein, and genomic models. Mean-centering is shown to eliminate outlier-induced death, while recovery during training is described as slow when γ is large because the SAE bias must learn μ.
Significance. If the central empirical relationships and intervention hold, the result is significant: it supplies a mechanistic account for the large observed variation in SAE death rates across models and a simple, targeted preprocessing remedy. Credit is due for the scale of the study (454 combinations) and the direct causal test via mean-centering, which isolates the proposed initialization-time mechanism from generic training dynamics.
minor comments (3)
- [Methods] The description of the 454 model-layer combinations and any data-exclusion rules should be expanded in the methods section to support full reproducibility of the reported correlations.
- [Results] Error bars or bootstrap confidence intervals on the Spearman ρ values would strengthen the claim that γ is a reliable predictor.
- [Discussion] The statement that recovery is 'prohibitively slow at high γ' would benefit from a quantitative plot or table showing bias-learning time scales versus γ.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work, the recognition of its significance, and the recommendation for minor revision. The scale of the study (454 model-layer combinations) and the direct causal test via mean-centering are indeed central to the contribution, and we are glad these aspects were highlighted.
Circularity Check
No significant circularity
full rationale
The paper's central claims rest on direct empirical measurements (Spearman correlations of γ with death rates across 454 model-layer combinations) and a controlled intervention (mean-centering eliminates death). No load-bearing step reduces by construction to a fitted parameter, self-citation chain, or definitional equivalence; γ is introduced as an explicit ratio of observed statistics, and the reported predictive power is an external correlation rather than a tautology. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Standard random initialization of SAE encoder weights and biases without prior mean adjustment.
- domain assumption Activation statistics (mean μ and per-dimension variation σ) are stable properties of the source model layers.
Reference graph
Works this paper leans on
-
[1]
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
URL https://transformer-circuits. pub/2025/january-update. Cornman, A., West-Roberts, J., Camargo, A. P., Roux, S., Beracochea, M., Mirdita, M., Ovchinnikov, S., and Hwang, Y . The omg dataset: An open metagenomic corpus for mixed-modality genomic language modeling. bioRxiv, pp. 2024–08, 2024. Dettmers, T., Lewis, M., Belkada, Y ., and Zettlemoyer, L. LLM...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Jermyn, A
URL https://openreview.net/forum? id=F76bwRSLeK. Jermyn, A. and Templeton, A. Ghost grads: An improve- ment on resampling.Transformer Circuits Thread,
-
[3]
URL https://transformer-circuits. pub/2024/jan-update/index.html# dict-learning-resampling. Joseph, S., Suresh, P., Goldfarb, E., Hufe, L., Gandelsman, Y ., Graham, R., Bzdok, D., Samek, W., and Richards, B. A. Steering CLIP’s vision transformer with sparse au- toencoders, 2025. URL https://arxiv.org/abs/ 2504.08729. Karvonen, A., Rager, C., Lin, J., Tigg...
-
[4]
URL https://openreview.net/forum? id=DaNnkQJSQf. Qiu, Z., Huang, Z., Wen, K., Jin, P., Zheng, B., Zhou, Y ., Huang, H., Wang, Z., Li, X., Zhang, H., et al. A unified view of attention and residual sinks: Outlier-driven rescal- ing is essential for transformer training.arXiv preprint arXiv:2601.22966, 2026. Radford, A., Wu, J., Child, R., Luan, D., Amodei,...
-
[5]
URL http://arxiv.org/abs/2511. 13981. arXiv:2511.13981 [cs]. Sim´eoni, O., V o, H. V ., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V ., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al. DINOv3.arXiv preprint arXiv:2508.10104, 2025. Simon, E. and Zou, J. Interplm: discovering interpretable features in protein language models via sparse aut...
-
[6]
Its projection onto any fixed vector is approximately Gaussian (Appendix B.1)
Each feature’s encoder weight wi is a random unit vector. Its projection onto any fixed vector is approximately Gaussian (Appendix B.1)
-
[7]
Use this to decompose the pre-activation zi(x) =s i +r i(x) into a data-independentshift si =w i ·µ and a data-dependentsignalr i(x) =w i ·(x−µ), both with Gaussian distributions parameterized byµandσ
-
[8]
For each death pathway (dead-by-ReLU and dead-by-TopK), find the shift threshold below which no sample can rescue the feature
-
[9]
Assumptions.The key assumption: for a fixed encoder weight wi, the signal wi ·(x−µ) is approximately Gaussian over the data distribution
Compute the fraction of features whose shift falls below this threshold; the dead-by-TopK extension follows the same approach with a different threshold. Assumptions.The key assumption: for a fixed encoder weight wi, the signal wi ·(x−µ) is approximately Gaussian over the data distribution. This holds when activations are not too heavy-tailed; heavier-tai...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.