Zero-Shot Quantization for Object Detectors using Off-the-Shelf Generative Models
Pith reviewed 2026-07-01 06:44 UTC · model grok-4.3
The pith
Off-the-shelf generative models can synthesize usable training data for quantizing object detectors to 3-bit precision without real images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
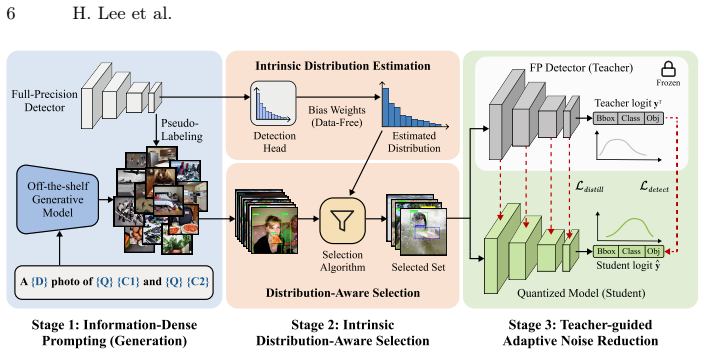
GoodQ constructs synthetic training data from off-the-shelf generative models by applying Information-Dense Prompting to produce multi-instance scenes, Intrinsic Distribution-Aware Selection to reproduce the pretrained class balance, and Teacher-guided Adaptive Noise Reduction to limit pseudo-label noise, thereby enabling effective zero-shot quantization-aware training of object detectors down to W3A3.
What carries the argument
The GoodQ three-step pipeline (Information-Dense Prompting, Intrinsic Distribution-Aware Selection, Teacher-guided Adaptive Noise Reduction) that converts generic generative outputs into a distribution-matched, low-noise synthetic set for quantization-aware training.
If this is right
- Object detectors can be quantized and deployed on edge hardware in settings where the original training images are unavailable for privacy or licensing reasons.
- Quantization to 3-bit weights and activations becomes practical for detection models without requiring custom data synthesis from noise optimization.
- The same prompting-selection-noise-reduction pattern can be reused whenever a generative model must stand in for a missing labeled dataset in quantization tasks.
Where Pith is reading between the lines
- Replacing the generative backbone with newer or domain-specific models could further close the remaining gap to real-data quantization.
- The class-distribution matching step may transfer directly to other zero-shot tasks that rely on synthetic images.
- Extending the prompting strategy to temporal or 3D data could support quantization of video or point-cloud detectors.
Load-bearing premise
Images produced by an off-the-shelf generative model, once prompted and filtered as described, carry statistics close enough to the original training distribution that training on them yields a quantized detector that still works on real test images.
What would settle it
Quantize an object detector with GoodQ synthetic data and measure mAP on the original real validation set; a large gap below both the full-precision model and prior non-generative ZSQ methods would falsify the claim.
Figures



read the original abstract
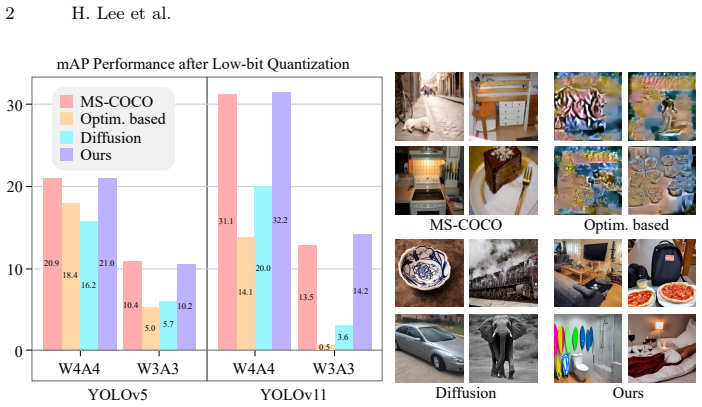
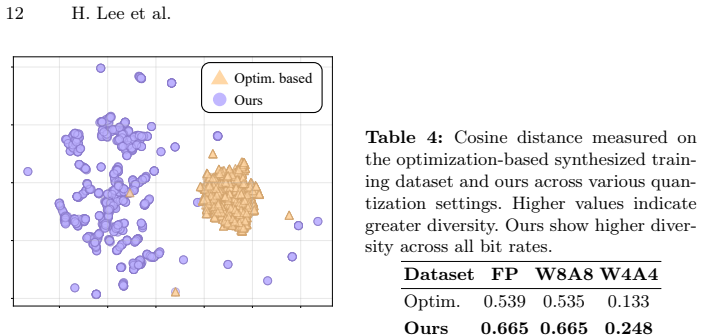
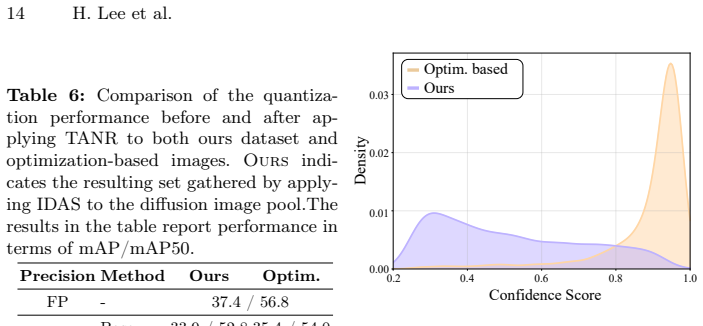
With an increasing number of Object Detection (OD) models being deployed on edge devices, Zero-Shot Quantization for OD (ZSQ-OD) aims to quantize these models when access to the original training data is prohibited. Existing research on Zero-Shot Quantization-Aware Training (QAT) for OD synthesizes training sets through noise optimization. However, this approach struggles to maintain performance in low-bit regions. In this paper, we introduce GoodQ (Generative off-the-shelf models for object detector Quantization), a QAT pipeline that utilizes off-the-shelf generative models to construct a training set. We first identify three challenges that arise when introducing a generative model to the ZSQ-OD task: 1) each image contains dense information with multiple instances, 2) the class-wise distribution in the original dataset is imbalanced, and 3) the pseudo-labels assigned to the generated images can potentially act as noisy signals during QAT. GoodQ addresses these challenges by 1) introducing an Information-Dense Prompting strategy to generate multi-instance images, 2) applying Intrinsic Distribution-Aware Selection to match the pretrained class distribution, and 3) employing Teacher-guided Adaptive Noise Reduction to mitigate noise arising from the QAT process. Our framework achieves state-of-the-art performance in low-bit ZSQ (W4A4) and extends quantization to extreme bit-widths (W3A3). Furthermore, we conduct an extensive analysis to uncover the underlying factors contributing to the efficacy of GoodQ.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GoodQ, a zero-shot quantization-aware training (QAT) pipeline for object detectors that synthesizes training data using off-the-shelf generative models instead of noise optimization. It identifies three challenges (dense multi-instance content per image, class imbalance in the original distribution, and noisy pseudo-labels) and proposes three targeted components—Information-Dense Prompting, Intrinsic Distribution-Aware Selection, and Teacher-guided Adaptive Noise Reduction—to address them. The central empirical claim is state-of-the-art performance at W4A4 bit-widths with extension to W3A3, backed by ablations and analysis of contributing factors.
Significance. If the reported gains hold under the described experimental protocol, the work offers a practical route to quantize object detectors without access to the original training set, which is relevant for privacy and regulatory constraints on edge deployment. Replacing noise-optimization baselines with generative-model synthesis, together with the three challenge-specific fixes and accompanying ablations, constitutes a clear methodological step beyond prior ZSQ-OD literature.
minor comments (2)
- The experimental section should explicitly name the off-the-shelf generative model (including version and fine-tuning status) and the precise prompting templates used, to support reproducibility of the Information-Dense Prompting step.
- Table captions and axis labels in the ablation figures would benefit from additional text clarifying which metric (mAP@0.5, mAP@0.5:0.95, etc.) is plotted and which baseline each bar corresponds to.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the work's significance for privacy-sensitive quantization, and recommendation of minor revision. The referee's description of GoodQ, its three challenges, and the proposed components accurately captures the manuscript.
Circularity Check
No significant circularity; empirical pipeline with independent experimental validation
full rationale
The paper describes an empirical QAT pipeline (GoodQ) that uses off-the-shelf generative models plus three explicitly proposed techniques (Information-Dense Prompting, Intrinsic Distribution-Aware Selection, Teacher-guided Adaptive Noise Reduction) to synthesize data for low-bit object-detector quantization. The central claims are performance numbers on W4A4/W3A3 regimes, justified by ablations and comparisons rather than any closed-form derivation. No equation reduces a claimed prediction to a fitted parameter by construction, no uniqueness theorem is imported from the authors' prior work, and no ansatz is smuggled via self-citation. The method is presented as a practical engineering solution whose efficacy is measured externally against baselines; the derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Bai, J., Yang, Y., Chu, H., Wang, H., Liu, Z., Chen, R., He, X., Mu, L., Cai, C., Hu, H.: Robustness-guided image synthesis for data-free quantization. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 10971–10979 (2024)
2024
-
[2]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops (June 2020)
Bhalgat, Y., Lee, J., Nagel, M., Blankevoort, T., Kwak, N.: Lsq+: Improving low- bit quantization through learnable offsets and better initialization. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops (June 2020)
2020
-
[3]
In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition
Cai, Y., Yao, Z., Dong, Z., Gholami, A., Mahoney, M.W., Keutzer, K.: Zeroq: A novel zero shot quantization framework. In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition. pp. 13169–13178 (2020)
2020
-
[4]
Advances in Neural Information Process- ing Systems34, 14835–14847 (2021)
Choi, K., Hong, D., Park, N., Kim, Y., Lee, J.: Qimera: Data-free quantization with synthetic boundary supporting samples. Advances in Neural Information Process- ing Systems34, 14835–14847 (2021)
2021
-
[5]
In: Proceedings of the AAAI Conference on Artificial Intelli- gence
Choi, K., Lee, H., Kwon, D., Park, S., Kim, K., Park, N., Choi, J., Lee, J.: Mimiq: Low-bit data-free quantization of vision transformers with encouraging inter-head attention similarity. In: Proceedings of the AAAI Conference on Artificial Intelli- gence. vol. 39, pp. 16037–16045 (2025)
2025
-
[6]
Esser, S.K., McKinstry, J.L., Bablani, D., Appuswamy, R., Modha, D.S.: Learned step size quantization. arXiv preprint arXiv:1902.08153 (2019)
-
[7]
Everingham, M., Gool, L.V., Williams, C.K.I., Winn, J., Zisserman, A.: The pascal visual object classes (voc) challenge (2010)
2010
-
[8]
Frank,L.,Davis,J.:Whatmakesagooddatasetforknowledgedistillation?In:Pro- ceedings of the Computer Vision and Pattern Recognition Conference. pp. 23755– 23764 (2025)
2025
-
[9]
In: Proceedings of the IEEE international conference on computer vision
He, K., Gkioxari, G., Dollár, P., Girshick, R.: Mask r-cnn. In: Proceedings of the IEEE international conference on computer vision. pp. 2961–2969 (2017)
2017
-
[10]
Jocher, G., Rizwan, M.: Ultralytics datasets: Homeobjects-3k detection dataset (May 2025),https://docs.ultralytics.com/datasets/detect/homeobjects- 3k/
2025
-
[11]
What is yolov5: A deep look into the internal features of the popular object detector,
Khanam, R., Hussain, M.: What is yolov5: A deep look into the internal features of the popular object detector. arXiv preprint arXiv:2407.20892 (2024)
-
[12]
YOLOv11: An Overview of the Key Architectural Enhancements
Khanam, R., Hussain, M.: Yolov11: An overview of the key architectural enhance- ments. arXiv preprint arXiv:2410.17725 (2024) 16 H. Lee et al
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
arXiv preprint arXiv:1911.12491 (2019)
Kim, J., Bhalgat, Y., Lee, J., Patel, C., Kwak, N.: Qkd: Quantization-aware knowl- edge distillation. arXiv preprint arXiv:1911.12491 (2019)
-
[14]
In: The Thirteenth International Conference on Learning Rep- resentations (2025)
Kim, M., Kim, J., Kang, U.: Synq: Accurate zero-shot quantization by synthesis- aware fine-tuning. In: The Thirteenth International Conference on Learning Rep- resentations (2025)
2025
-
[15]
Li, C., Chen, X., Wang, J., Zhao, K., Chen, J.: Task-specific zero-shot quantization- awaretrainingforobjectdetection.In:ProceedingsoftheIEEE/CVFInternational Conference on Computer Vision. pp. 22868–22878 (2025)
2025
-
[16]
In: Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition
Li, H., Wu, X., Lv, F., Liao, D., Li, T.H., Zhang, Y., Han, B., Tan, M.: Hard sample matters a lot in zero-shot quantization. In: Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition. pp. 24417–24426 (2023)
2023
-
[17]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, R., Wang, Y., Liang, F., Qin, H., Yan, J., Fan, R.: Fully quantized network for object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2810–2819 (2019)
2019
-
[18]
arXiv preprint arXiv:2602.18861 (2026)
Li, S., Karmann, M., Urfalioglu, O.: Joint post-training quantization of vi- sion transformers with learned prompt-guided data generation. arXiv preprint arXiv:2602.18861 (2026)
-
[19]
Advances in neural information processing systems33, 21002–21012 (2020)
Li, X., Wang, W., Wu, L., Chen, S., Hu, X., Li, J., Tang, J., Yang, J.: General- ized focal loss: Learning qualified and distributed bounding boxes for dense object detection. Advances in neural information processing systems33, 21002–21012 (2020)
2020
-
[20]
In: European Conference on Computer Vision
Li, Y., Kim, Y., Lee, D., Kundu, S., Panda, P.: Genq: Quantization in low data regimes with generative synthetic data. In: European Conference on Computer Vision. pp. 216–235. Springer (2024)
2024
-
[21]
In: European conference on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014)
2014
-
[22]
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer:Hierarchicalvisiontransformerusingshiftedwindows.In:Proceedings of the IEEE/CVF international conference on computer vision. pp. 10012–10022 (2021)
2021
-
[23]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
McInnes, L., Healy, J., Melville, J.: Umap: Uniform manifold approximation and projection for dimension reduction. arXiv preprint arXiv:1802.03426 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[24]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops
Park, J., Lee, C., Choi, Y., Park, S., Hong, D., Choi, J.: Enhancing generaliza- tion in data-free quantization via mixup-class prompting. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops. pp. 4002–4011 (October 2025)
2025
-
[25]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[26]
In: European Conference on Computer Vision
Ramachandran,A.,Kundu,S.,Krishna,T.:Clamp-vit:Contrastivedata-freelearn- ing for adaptive post-training quantization of vits. In: European Conference on Computer Vision. pp. 307–325. Springer (2024)
2024
-
[27]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: Unified, real-time object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 779–788 (2016)
2016
-
[28]
In: European conference on computer vision
Xu, S., Li, H., Zhuang, B., Liu, J., Cao, J., Liang, C., Tan, M.: Generative low- bitwidth data free quantization. In: European conference on computer vision. pp. 1–17. Springer (2020) Generativeoff-the-shelf models forobjectdetectorQuantization 17
2020
-
[29]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhao, K., Zhuang, Z., Zhang, M., Guo, C., Shu, Y., Yang, B.: Enhancing diversity for data-free quantization. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 20969–20978 (2025)
2025
-
[30]
A photo of many cars and a few person
Zhong, Y., Lin, M., Nan, G., Liu, J., Zhang, B., Tian, Y., Ji, R.: Intraq: Learning synthetic images with intra-class heterogeneity for zero-shot network quantization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12339–12348 (2022) 18 H. Lee et al. A Details on Prompts A.1 Prompt Template for Information-Dense...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.